
qgate-model
ML/AI meta-model, used in MLRun/Iguazio/Nuclio, see qgate-sln-
Stars: 322
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.
README:



The machine learning meta-model with synthetic data (useful for MLOps/feature store), is independent of machine learning solutions (definition in json, data in csv/parquet).

The meta-model is suitable for:
- compare capabilities and functions of machine learning solutions (as part of RFP/X and SWOT analysis)
- independent test new versions of machine learning solutions (with aim to keep quality in time)
- unit, sanity, smoke, system, integration, regression, function, acceptance, performance, shadow, ... tests
- external test coverage (in case, that internal test coverage is not available or weak)
- etc.
Note: You can see real usage of this meta-model in e.g. project qgate-sln-mlrun for testing MLRun/Iguazio solution.
The solution contains this simple structure:
-
00-high-level
- The high-level view to the meta-model for better understanding
-
01-model
- The definition contains 01-projects, 02-feature sets, 03-feature vectors, 04-pipelines, 05-ml models, etc.
-
02-data
- The synthetic data for meta-model in CSV/GZ and parquet formats for party, contact, relation, account, transaction, event, communication, etc.
- You can also generate your own dataset with requested size (see samples
./02-data/03-size-10k.sh,./02-data/04-size-50k.sh, etc. and descriptionpython main.py generate --help)
-
03-test
- The information for test simplification e.g. feature vector vs on/off-line data, test/data hints, etc.
Addition details, see structure and see rules
The supported sources/targets for realization (✅ done, ✔ in-progress, ❌ planned), see
the definition /spec/targets/ in projects (see specification in JSON files):
- ✅ Redis, ✅ MySQL, ✅ Postgres, ✅ Kafka
- ✅ Pandas, ✅ Parquet, ✅ CSV
The object relations for key objects in meta-model, plus splitting these objects in packages (01-model/01-project, 01-model/02-feature-set, 02-data, etc.).

The basic feature sets and relations between them.

The derived feature sets and relations between them.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for qgate-model
Similar Open Source Tools
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.

langtest
LangTest is a comprehensive evaluation library for custom LLM and NLP models. It aims to deliver safe and effective language models by providing tools to test model quality, augment training data, and support popular NLP frameworks. LangTest comes with benchmark datasets to challenge and enhance language models, ensuring peak performance in various linguistic tasks. The tool offers more than 60 distinct types of tests with just one line of code, covering aspects like robustness, bias, representation, fairness, and accuracy. It supports testing LLMS for question answering, toxicity, clinical tests, legal support, factuality, sycophancy, and summarization.

FuseAI
FuseAI is a repository that focuses on knowledge fusion of large language models. It includes FuseChat, a state-of-the-art 7B LLM on MT-Bench, and FuseLLM, which surpasses Llama-2-7B by fusing three open-source foundation LLMs. The repository provides tech reports, releases, and datasets for FuseChat and FuseLLM, showcasing their performance and advancements in the field of chat models and large language models.

cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.
SEED-Bench
SEED-Bench is a comprehensive benchmark for evaluating the performance of multimodal large language models (LLMs) on a wide range of tasks that require both text and image understanding. It consists of two versions: SEED-Bench-1 and SEED-Bench-2. SEED-Bench-1 focuses on evaluating the spatial and temporal understanding of LLMs, while SEED-Bench-2 extends the evaluation to include text and image generation tasks. Both versions of SEED-Bench provide a diverse set of tasks that cover different aspects of multimodal understanding, making it a valuable tool for researchers and practitioners working on LLMs.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.

xaitk-saliency
The `xaitk-saliency` package is an open source Explainable AI (XAI) framework for visual saliency algorithm interfaces and implementations, designed for analytics and autonomy applications. It provides saliency algorithms for various image understanding tasks such as image classification, image similarity, object detection, and reinforcement learning. The toolkit targets data scientists and developers who aim to incorporate visual saliency explanations into their workflow or product, offering both direct accessibility for experimentation and modular integration into systems and applications through Strategy and Adapter patterns. The package includes documentation, examples, and a demonstration tool for visual saliency generation in a user-interface.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.

lightllm
LightLLM is a Python-based LLM (Large Language Model) inference and serving framework known for its lightweight design, scalability, and high-speed performance. It offers features like tri-process asynchronous collaboration, Nopad for efficient attention operations, dynamic batch scheduling, FlashAttention integration, tensor parallelism, Token Attention for zero memory waste, and Int8KV Cache. The tool supports various models like BLOOM, LLaMA, StarCoder, Qwen-7b, ChatGLM2-6b, Baichuan-7b, Baichuan2-7b, Baichuan2-13b, InternLM-7b, Yi-34b, Qwen-VL, Llava-7b, Mixtral, Stablelm, and MiniCPM. Users can deploy and query models using the provided server launch commands and interact with multimodal models like QWen-VL and Llava using specific queries and images.
SWE-agent
SWE-agent is a tool that turns language models (e.g. GPT-4) into software engineering agents capable of fixing bugs and issues in real GitHub repositories. It achieves state-of-the-art performance on the full test set by resolving 12.29% of issues. The tool is built and maintained by researchers from Princeton University. SWE-agent provides a command line tool and a graphical web interface for developers to interact with. It introduces an Agent-Computer Interface (ACI) to facilitate browsing, viewing, editing, and executing code files within repositories. The tool includes features such as a linter for syntax checking, a specialized file viewer, and a full-directory string searching command to enhance the agent's capabilities. SWE-agent aims to improve prompt engineering and ACI design to enhance the performance of language models in software engineering tasks.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.
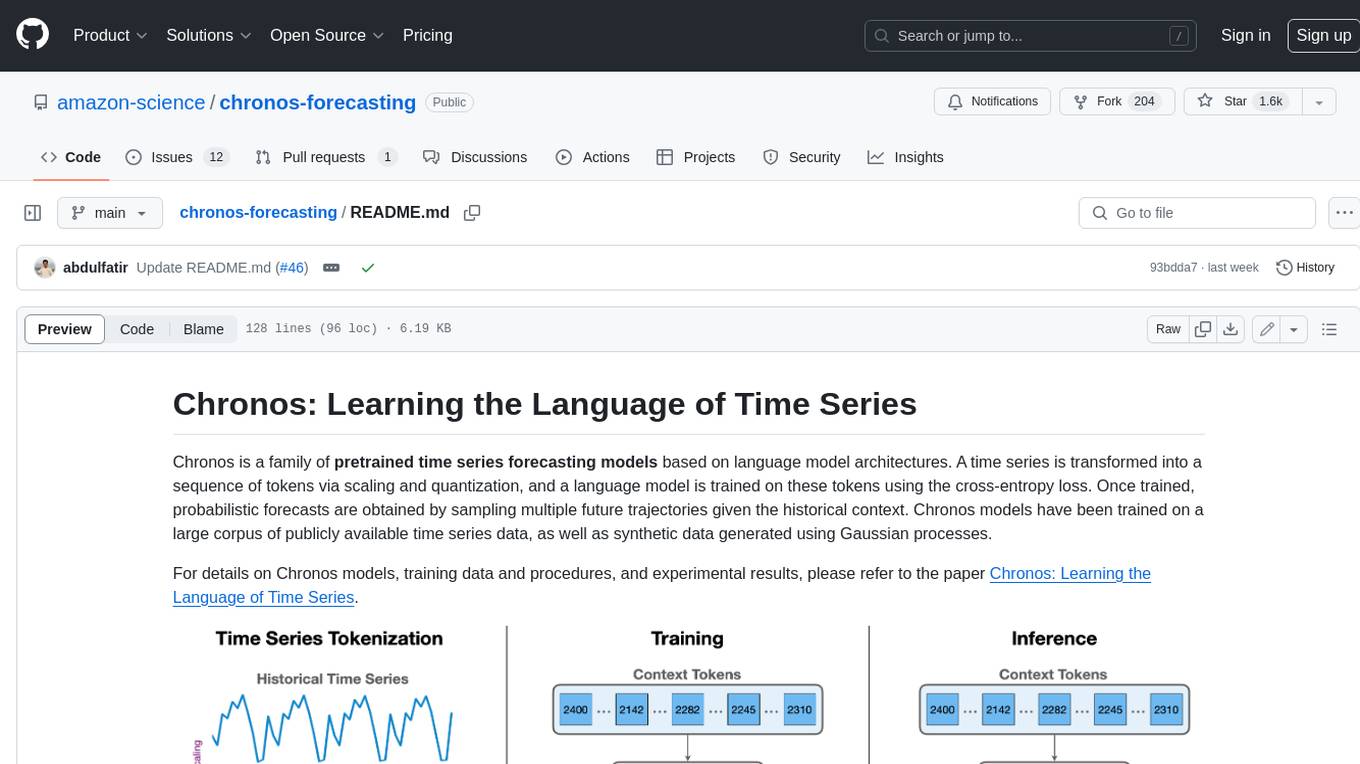
chronos-forecasting
Chronos is a family of pretrained time series forecasting models based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
forms-flow-ai
formsflow.ai is a Free, Open-Source, Low Code Development Platform for rapidly building powerful business applications. It combines leading Open-Source applications including form.io forms, Camunda’s workflow engine, Keycloak’s security, and Redash’s data analytics into a seamless, integrated platform. Check out the installation documentation for installation instructions and features documentation to explore features and capabilities in detail.

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
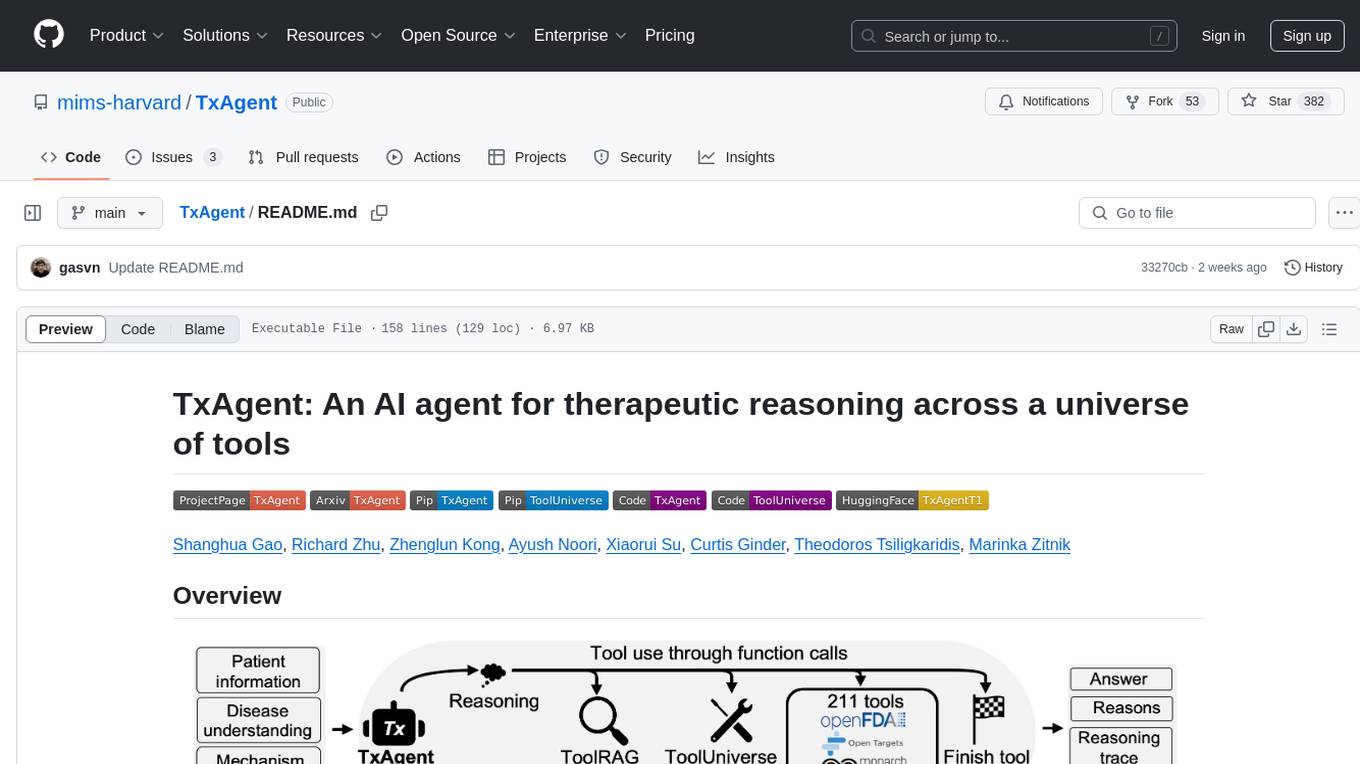
TxAgent
TxAgent is an AI agent designed for precision therapeutics, leveraging multi-step reasoning and real-time biomedical knowledge retrieval across a toolbox of 211 tools. It evaluates drug interactions, contraindications, and tailors treatment strategies to individual patient characteristics. TxAgent outperforms leading models across various drug reasoning tasks and personalized treatment scenarios, ensuring treatment recommendations align with clinical guidelines and real-world evidence.
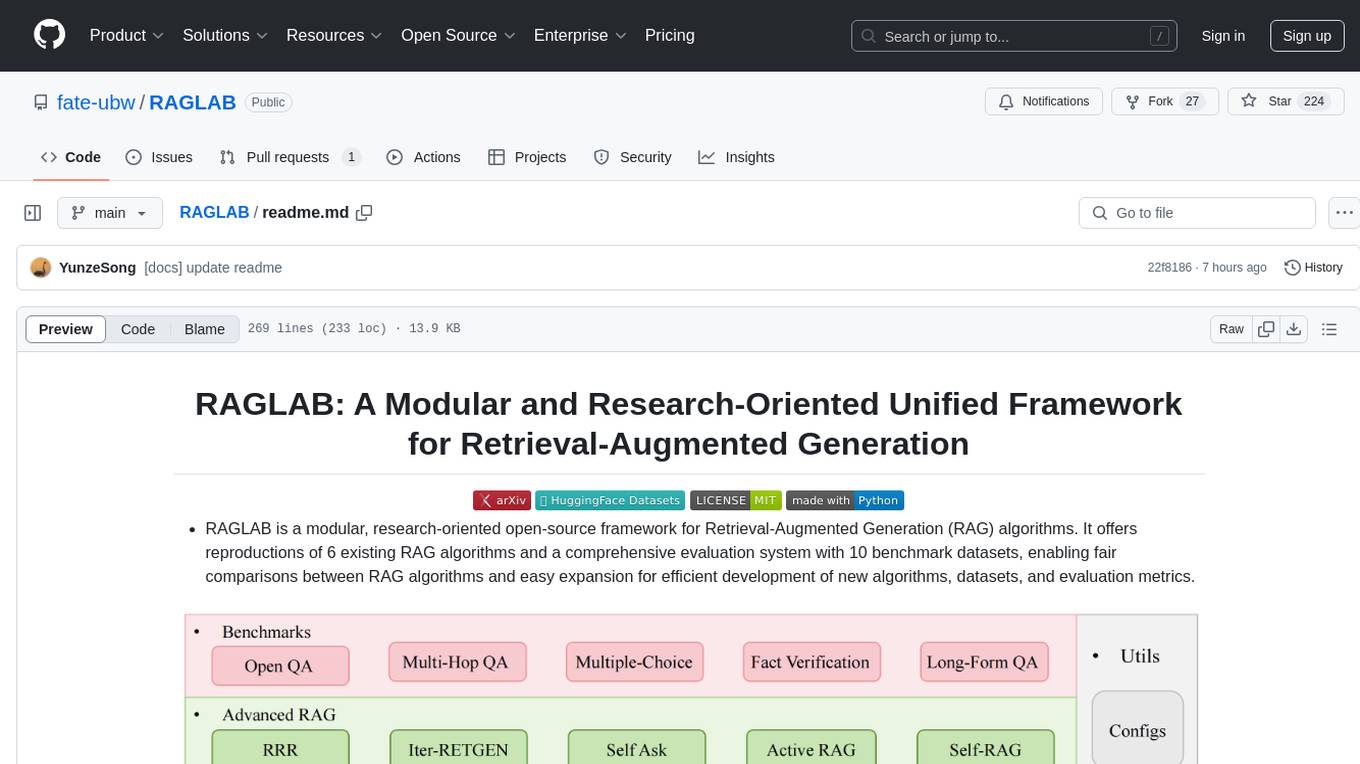
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.
For similar tasks
qgate-model
QGate-Model is a machine learning meta-model with synthetic data, designed for MLOps and feature store. It is independent of machine learning solutions, with definitions in JSON and data in CSV/parquet formats. This meta-model is useful for comparing capabilities and functions of machine learning solutions, independently testing new versions of machine learning solutions, and conducting various types of tests (unit, sanity, smoke, system, regression, function, acceptance, performance, shadow, etc.). It can also be used for external test coverage when internal test coverage is not available or weak.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
LLM4IR-Survey
LLM4IR-Survey is a collection of papers related to large language models for information retrieval, organized according to the survey paper 'Large Language Models for Information Retrieval: A Survey'. It covers various aspects such as query rewriting, retrievers, rerankers, readers, search agents, and more, providing insights into the integration of large language models with information retrieval systems.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.
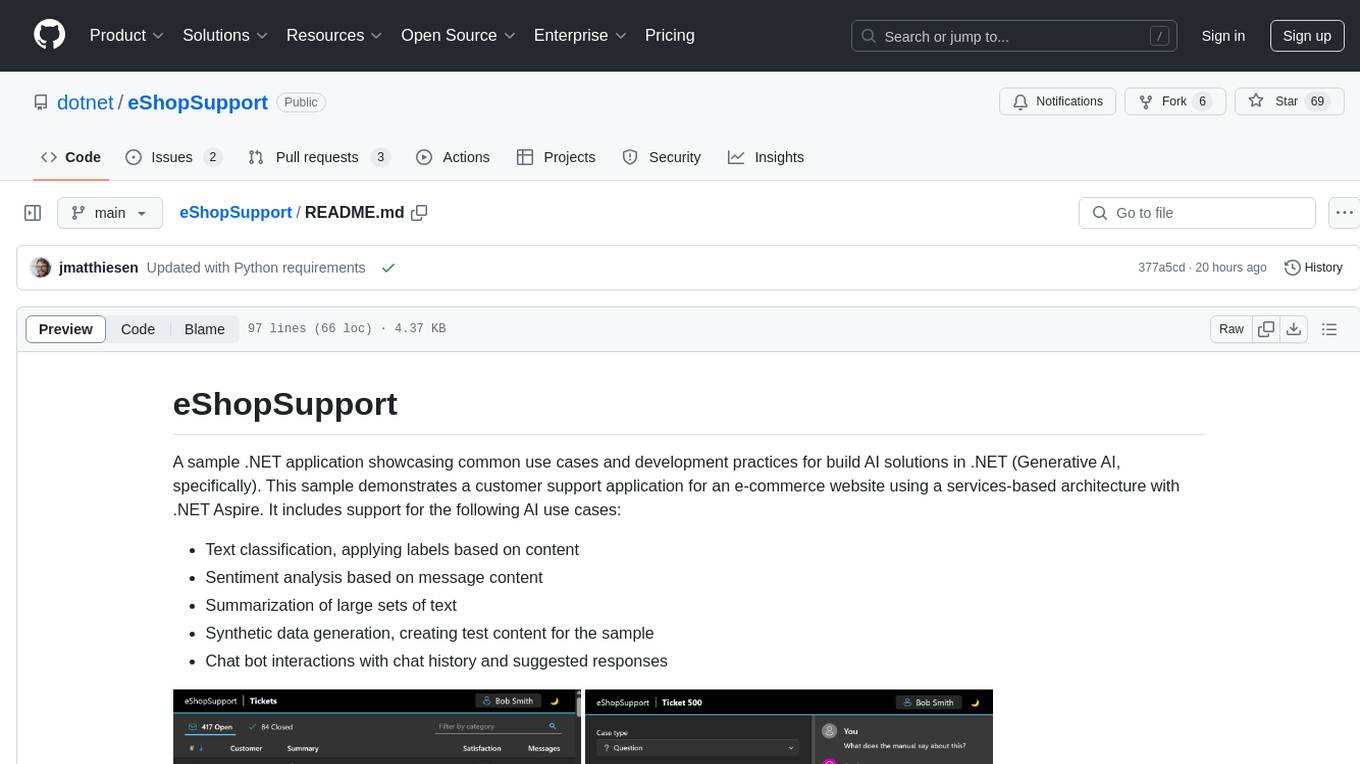
eShopSupport
eShopSupport is a sample .NET application showcasing common use cases and development practices for building AI solutions in .NET, specifically Generative AI. It demonstrates a customer support application for an e-commerce website using a services-based architecture with .NET Aspire. The application includes support for text classification, sentiment analysis, text summarization, synthetic data generation, and chat bot interactions. It also showcases development practices such as developing solutions locally, evaluating AI responses, leveraging Python projects, and deploying applications to the Cloud.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.

Kiln
Kiln is an intuitive tool for fine-tuning LLM models, generating synthetic data, and collaborating on datasets. It offers desktop apps for Windows, MacOS, and Linux, zero-code fine-tuning for various models, interactive data generation, and Git-based version control. Users can easily collaborate with QA, PM, and subject matter experts, generate auto-prompts, and work with a wide range of models and providers. The tool is open-source, privacy-first, and supports structured data tasks in JSON format. Kiln is free to use and helps build high-quality AI products with datasets, facilitates collaboration between technical and non-technical teams, allows comparison of models and techniques without code, ensures structured data integrity, and prioritizes user privacy.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.