
RAGLAB
[EMNLP 2024: Demo Oral] RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Stars: 232
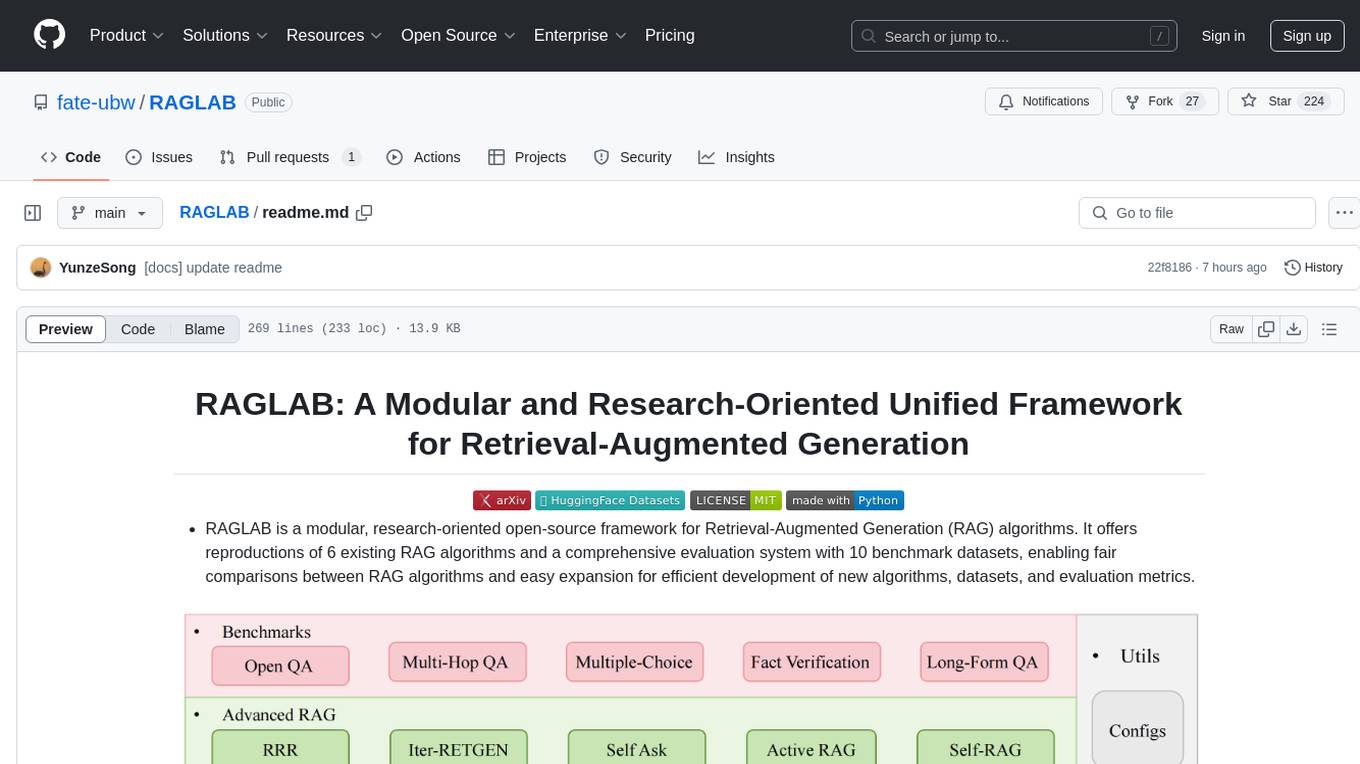
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.
README:
- RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics.

- 2024.10.6: Our paper has been accepted by EMNLP 2024 System Demonstration.🎉 You can find our paper in RAGLAB.
- 2024.9.9: RAGLAB has open-sourced all log files and evaluation files in evaluation results📌
- 2024.8.20: RAGLAB has open-sourced 4 models🤗: llama3-8B-baseline selfrag-llama3-8b llama3-70B-adaptor selfrag-llama3-70B-adaptor
- 2024.8.6: RAGLAB is released🌈.
- Comprehensive RAG Ecosystem: Supports the entire RAG pipeline from data collection and training to auto-evaluation.
- Advanced Algorithm Implementations: Reproduces 6 state-of-the-art RAG algorithms, with an easy-to-extend framework for developing new algorithms.
- Interact Mode & Evaluation Mode: Interact Mode is specifically designed for quickly understanding algorithms. Evaluation Mode is specifically designed for reproducing paper results and scientific research.
- Fair Comparison Platform: Provides benchmark results for 6 algorithms across 5 task types and 10 datasets.
- Efficient Retriever Client: Offers local API for parallel access and caching, with average latency under 1 second.
- Versatile Generator Support: Compatible with 70B+ models, VLLM, and quantization techniques.
- Flexible Instruction Lab: Customizable instruction templates for various RAG scenarios.
- Interesting RAG applications
-
dev environment:pytorch:2.0.1-py3.10-cuda11.8.0-devel-ubuntu22.04
-
git clone RAGLAB
https://github.com/fate-ubw/RAGLAB.git
-
create environment from yml file
cd RAGLAB conda env create -f environment.yml -
install flash-attn, en_core_web_sm, punkt manually
pip install flash-attn==2.2 python -m spacy download en_core_web_sm python -m nltk.downloader punkt
raglab need several models please download them
cd RAGLAB
mkdir model
cd model
mkdir output_models
# retriever model
mkdir colbertv2.0
huggingface-cli download colbert-ir/colbertv2.0 --local-dir colbertv2.0/ --local-dir-use-symlinks False
mkdir contriever-msmarco
huggingface-cli download facebook/contriever-msmarco --local-dir contriever-msmarco/ --local-dir-use-symlinks False
# finetuned generator
# 8B model
mkdir Llama3-8B-baseline
huggingface-cli download RAGLAB/Llama3-8B-baseline --local-dir Llama3-8B-baseline/ --local-dir-use-symlinks False
mkdir selfrag_llama3_8b-epoch_0_1
huggingface-cli download RAGLAB/selfrag_llama3-8B --local-dir selfrag_llama3_8b-epoch_0_1/ --local-dir-use-symlinks False
# 70B model
mkdir Llama3-70B-baseline-adapter
huggingface-cli download RAGLAB/Llama3-70B-baseline-adapter --local-dir Llama3-70B-baseline-adapter/ --local-dir-use-symlinks False
mkdir selfrag_llama3_70B-adapter
huggingface-cli download RAGLAB/selfrag_llama3-70B-adapter --local-dir selfrag_llama3_70B-adapter/ --local-dir-use-symlinks False
mkdir Meta-Llama-3-70B
huggingface-cli download meta-llama/Meta-Llama-3-70B --local-dir Meta-Llama-3-70B/ --local-dir-use-symlinks False
# base model for finetune and LoRA
mkdir Meta-Llama-3-8B
huggingface-cli download meta-llama/Meta-Llama-3-8B --local-dir Meta-Llama-3-8B/ --local-dir-use-symlinks False
# ALCE Metric Models
mkdir gpt2-large
huggingface-cli download openai-community/gpt2-large --local-dir gpt2-large/ --local-dir-use-symlinks False
mkdir roberta-large-squad
huggingface-cli download gaotianyu1350/roberta-large-squad --local-dir roberta-large-squad/ --local-dir-use-symlinks False
mkdir t5_xxl_true_nli_mixture
huggingface-cli download google/t5_xxl_true_nli_mixture --local-dir t5_xxl_true_nli_mixture/ --local-dir-use-symlinks False
# factscore model we use gpt3.5 for evaluation, so no need to download local models
# models from official selfrag repo
mkdir selfrag_llama2_7b
huggingface-cli download selfrag/selfrag_llama2_7b --local-dir selfrag_llama2_7b/ --local-dir-use-symlinks False
# you can download other model as generator from huggingface- If you only need to understand how different algorithms work, the interact mode developed by RAGLAB can meet your needs.
- If you want to reproduce the results from the papers, you need to download all the required data from Hugging Face, including training data, knowledge data, and evaluation data. We have packaged all the data for you, so you just need to download it and it's ready to use.
cd RAGLAB huggingface-cli download RAGLAB/data --local-dir data --repo-type dataset
- Interact Mode is specifically designed for quickly understanding algorithms. In interact mode, you can run various algorithms very quickly, understand the reasoning process of different algorithms, without needing to download any additional data.
- All algorithms integrated in raglab include two modes:
interactandevaluation. The test stage demonstrates ininteractmode, just for demostration and eduction 🤗.
[!NOTE]
- Due to colbert's requirement for absolute paths, you need to modify the index_dbPath and text_dbPath in the config file to use absolute paths.
- Modify the
index_dbPathandtext_dbPathin config file:colbert_server-10samples.yamlindex_dbPath: /your_root_path/RAGLAB/data/retrieval/colbertv2.0_embedding/wiki2023-10samples text_dbPath: /your_root_path/RAGLAB/data/retrieval/colbertv2.0_passages/wiki2023-10samples/enwiki-20230401-10samples.tsv
- run colbert server
cd RAGLAB sh run/colbert_server/colbert_server-10samples.sh
[!NOTE]
- At this point, colbert embedding will prompt that due to path errors, colbert embedding needs to be reprocessed. Please enter
yesand then raglab will automatically help you process the embedding and start the colbert server.
- Now please open another terminal and try to request the colbert server
cd RAGLAB sh run/colbert_server/ask_api.sh- If a result is returned, it means the colbert server has started successfully! 🌈
- run selfrag (short form & adaptive retrieval) interact mode test 10-samples embedding
cd RAGLAB sh run/rag_inference/3-selfrag_reproduction-interact-short_form-adaptive_retrieval.sh - Congratulations!!!Now you have already know how to run raglab 🌈
- In raglab, each algorithm has 10 queries built-in in interact mode which are sampled from different benchmarks
[!NOTE]
- remember download wiki2018 konwledge database and model before runing paper results
- Due to colbert's requirement for absolute paths, you need to modify the
index_dbPathandtext_dbPathin config file and process the wiki2018 embedding database- Modify the paths in the config file
cd RAGLAB/config/colbert_server vim colbert_server.yaml index_dbPath: {your_root_path}/RAGLAB/data/retrieval/colbertv2.0_embedding/wiki2018 text_dbPath: {your_root_path}/RAGLAB/data/retrieval/colbertv2.0_passages/wiki2018/wiki2018.tsv- Modify the absolute paths bound in the wiki2018 embedding source file
vim /data/retrieval/colbertv2.0_embedding/wiki2018/indexes/wiki2018/metadata.json # change root path, other parameters do not need to be modified "collection": "/{your_root_path}/RAGLAB/data/retrieval/colbertv2.0_passages/wiki2018/wiki2018.tsv", "experiment": "/{your_root_path}/RAGLAB/data/retrieval/colbertv2.0_embedding/wiki2018",
- Attention: colbert_server need atleast 60GB ram
cd RAGLAB sh run/colbert_server/colbert_server.sh - open another terminal test your ColBERT server
cd RAGLAB sh run/colbert_server/ask_api.sh - ColBERT server started successfully!!! 🌈
- inference experiments require running hundreds of scripts in parallel, the automatic gpu scheduler needs to be used to automatically allocate GPUs for different bash scripts in Parallel.
- install
simple_gpu_schedulerpip install simple_gpu_scheduler
- run hundreds of experiments in one line 😎
cd RAGLAB simple_gpu_scheduler --gpus 0,1,2,3,4,5,6,7 < auto_gpu_scheduling_scripts/auto_run-llama3_8b-baseline-scripts.txt # Other scripts can be run using the same method
- how to write your_script.txt?
- here is an example
# auto_inference_selfreg-7b.txt sh run/rag_inference/selfrag_reproduction/selfrag_reproduction-evaluation-short_form-PubHealth-adaptive_retrieval-pregiven_passages.sh sh run/rag_inference/selfrag_reproduction/selfrag_reproduction-evaluation-short_form-PubHealth-always_retrieval-pregiven_passages.sh
-
RAGLAB includes 3 classic evaluation methods: accuracy, F1, and EM (Exact Match). These 3 methods are simple to calculate, so they can be computed dynamically during the inference process. However, ALCE and Factscore, two advanced metrics, require the completion of the inference process before evaluation.
-
ALCE: RAGLAB has integrated the ALCE repository into RAGLAB. You only need to set the path for the inference results in the config file.
cd RAGLAB cd run/ALCE/ # Change the path in each sh file for the inference generated files # For example: # python ./ALCE/eval.py --f './data/eval_results/ASQA/{your_input_file_path}.jsonl' \ # --mauve \ # --qa simple_gpu_scheduler --gpus 0,1,2,3,4,5,6,7 < auto_gpu_scheduling_scripts/auto_eval_ALCE.txt
-
The evaluation results will be in the same directory as the input file, with the file name suffix
.score -
Factscore: The Factscore environment requires installation of
torch 1.13.1, which conflicts with the flash-attn version needed in RAGLAB's training and inference modules. Therefore, RAGLAB currently cannot integrate the Factscore environment, so users need to install the Factscore environment separately for evaluation. -
After installing the Factscore environment, please modify the path of the inference results in the bash file
cd RAGLAB/run/Factscore/ # change the path in each sh file for the inference generated files # For example: # python ./FActScore/factscore/factscorer.py \ # --input_path './data/eval_results/Factscore/{your_input_file_path}.jsonl' \ # --model_name "retrieval+ChatGPT"\ # --openai_key ./api_keys.txt \ # --data_dir ./data/retrieval/colbertv2.0_passages/wiki2023 \ # --verbose simple_gpu_scheduler --gpus 0,1,2,3,4,5,6,7 < auto_gpu_scheduling_scripts/auto_eval_Factscore.txt
-
The evaluation results will be in the same directory as the input file, with the file name suffix
_factscore_output.json
[!NOTE]
- During the Factscore evaluation process, we used GPT-3.5 as the evaluation model, so there's no need to download a local model. If you need to use a local model to evaluate Factscore, please refer to Factscore
- If you wish to process the knowledge database yourself, please refer to the following steps. RAGLAB has already uploaded the processed knowledge database to Hugging Face
- document: process_wiki.md
- This section covers the process of training models in RAGLAB. You can either download all pre-trained models from HuggingFace🤗, or use the tutorial below to train from scratch📝.
- All data provides all data necessary for finetuning.
- document: train_docs.md
If you find this repository useful, please cite our work.
@inproceedings{zhang-etal-2024-raglab,
title = "{RAGLAB}: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation",
author = "Zhang, Xuanwang and
Song, Yunze and
Wang, Yidong and
Tang, Shuyun and
others",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = dec,
year = "2024",
publisher = "Association for Computational Linguistics",
}
RAGLAB is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RAGLAB
Similar Open Source Tools
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.

serverless-rag-demo
The serverless-rag-demo repository showcases a solution for building a Retrieval Augmented Generation (RAG) system using Amazon Opensearch Serverless Vector DB, Amazon Bedrock, Llama2 LLM, and Falcon LLM. The solution leverages generative AI powered by large language models to generate domain-specific text outputs by incorporating external data sources. Users can augment prompts with relevant context from documents within a knowledge library, enabling the creation of AI applications without managing vector database infrastructure. The repository provides detailed instructions on deploying the RAG-based solution, including prerequisites, architecture, and step-by-step deployment process using AWS Cloudshell.
BIRD-CRITIC-1
BIRD-CRITIC 1.0 is a SQL benchmark designed to evaluate the capability of large language models (LLMs) in diagnosing and solving user issues within real-world database environments. It comprises 600 tasks for development and 200 held-out out-of-distribution tests across 4 prominent open-source SQL dialects. The benchmark expands beyond simple SELECT queries to cover a wider range of SQL operations, reflecting actual application scenarios. An optimized execution-based evaluation environment is included for rigorous and efficient validation.

cognee
Cognee is an open-source framework designed for creating self-improving deterministic outputs for Large Language Models (LLMs) using graphs, LLMs, and vector retrieval. It provides a platform for AI engineers to enhance their models and generate more accurate results. Users can leverage Cognee to add new information, utilize LLMs for knowledge creation, and query the system for relevant knowledge. The tool supports various LLM providers and offers flexibility in adding different data types, such as text files or directories. Cognee aims to streamline the process of working with LLMs and improving AI models for better performance and efficiency.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.
ai-optimizer
The Oracle AI Optimizer and Toolkit provides a streamlined environment for developers and data scientists to explore Generative Artificial Intelligence (GenAI) and Retrieval-Augmented Generation (RAG) capabilities. It integrates Oracle Database 23ai AI VectorSearch and SelectAI to enhance Large Language Models (LLMs) through RAG.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.
RooFlow
RooFlow is a VS Code extension that enhances AI-assisted development by providing persistent project context and optimized mode interactions. It reduces token consumption and streamlines workflow by integrating Architect, Code, Test, Debug, and Ask modes. The tool simplifies setup, offers real-time updates, and provides clearer instructions through YAML-based rule files. It includes components like Memory Bank, System Prompts, VS Code Integration, and Real-time Updates. Users can install RooFlow by downloading specific files, placing them in the project structure, and running an insert-variables script. They can then start a chat, select a mode, interact with Roo, and use the 'Update Memory Bank' command for synchronization. The Memory Bank structure includes files for active context, decision log, product context, progress tracking, and system patterns. RooFlow features persistent context, real-time updates, mode collaboration, and reduced token consumption.
pipeshub-ai
Pipeshub-ai is a versatile tool for automating data pipelines in AI projects. It provides a user-friendly interface to design, deploy, and monitor complex data workflows, enabling seamless integration of various AI models and data sources. With Pipeshub-ai, users can easily create end-to-end pipelines for tasks such as data preprocessing, model training, and inference, streamlining the AI development process and improving productivity. The tool supports integration with popular AI frameworks and cloud services, making it suitable for both beginners and experienced AI practitioners.
smile
Smile (Statistical Machine Intelligence and Learning Engine) is a comprehensive machine learning, NLP, linear algebra, graph, interpolation, and visualization system in Java and Scala. It covers every aspect of machine learning, including classification, regression, clustering, association rule mining, feature selection, manifold learning, multidimensional scaling, genetic algorithms, missing value imputation, efficient nearest neighbor search, etc. Smile implements major machine learning algorithms and provides interactive shells for Java, Scala, and Kotlin. It supports model serialization, data visualization using SmilePlot and declarative approach, and offers a gallery showcasing various algorithms and visualizations.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
kubewall
kubewall is an open-source, single-binary Kubernetes dashboard with multi-cluster management and AI integration. It provides a simple and rich real-time interface to manage and investigate your clusters. With features like multi-cluster management, AI-powered troubleshooting, real-time monitoring, single-binary deployment, in-depth resource views, browser-based access, search and filter capabilities, privacy by default, port forwarding, live refresh, aggregated pod logs, and clean resource management, kubewall offers a comprehensive solution for Kubernetes cluster management.
For similar tasks
RAGLAB
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.