
3FS
A high-performance distributed file system designed to address the challenges of AI training and inference workloads.
Stars: 8178
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
README:
![]()
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed to address the challenges of AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features and benefits of 3FS include:
-
Performance and Usability
- Disaggregated Architecture Combines the throughput of thousands of SSDs and the network bandwidth of hundreds of storage nodes, enabling applications to access storage resource in a locality-oblivious manner.
- Strong Consistency Implements Chain Replication with Apportioned Queries (CRAQ) for strong consistency, making application code simple and easy to reason about.
- File Interfaces Develops stateless metadata services backed by a transactional key-value store (e.g., FoundationDB). The file interface is well known and used everywhere. There is no need to learn a new storage API.
-
Diverse Workloads
- Data Preparation Organizes outputs of data analytics pipelines into hierarchical directory structures and manages a large volume of intermediate outputs efficiently.
- Dataloaders Eliminates the need for prefetching or shuffling datasets by enabling random access to training samples across compute nodes.
- Checkpointing Supports high-throughput parallel checkpointing for large-scale training.
- KVCache for Inference Provides a cost-effective alternative to DRAM-based caching, offering high throughput and significantly larger capacity.
The following figure demonstrates the throughput of read stress test on a large 3FS cluster. This cluster consists of 180 storage nodes, each equipped with 2×200Gbps InfiniBand NICs and sixteen 14TiB NVMe SSDs. Approximately 500+ client nodes were used for the read stress test, with each client node configured with 1x200Gbps InfiniBand NIC. The final aggregate read throughput reached approximately 6.6 TiB/s with background traffic from training jobs.

To benchmark 3FS, please use our fio engine for USRBIO.
We evaluated smallpond using the GraySort benchmark, which measures sort performance on large-scale datasets. Our implementation adopts a two-phase approach: (1) partitioning data via shuffle using the prefix bits of keys, and (2) in-partition sorting. Both phases read/write data from/to 3FS.
The test cluster comprised 25 storage nodes (2 NUMA domains/node, 1 storage service/NUMA, 2×400Gbps NICs/node) and 50 compute nodes (2 NUMA domains, 192 physical cores, 2.2 TiB RAM, and 1×200 Gbps NIC/node). Sorting 110.5 TiB of data across 8,192 partitions completed in 30 minutes and 14 seconds, achieving an average throughput of 3.66 TiB/min.


KVCache is a technique used to optimize the LLM inference process. It avoids redundant computations by caching the key and value vectors of previous tokens in the decoder layers. The top figure demonstrates the read throughput of all KVCache clients (1×400Gbps NIC/node), highlighting both peak and average values, with peak throughput reaching up to 40 GiB/s. The bottom figure presents the IOPS of removing ops from garbage collection (GC) during the same time period.


Clone 3FS repository from GitHub:
git clone https://github.com/deepseek-ai/3fs
When deepseek-ai/3fs has been cloned to a local file system, run the
following commands to check out the submodules:
cd 3fs
git submodule update --init --recursive
./patches/apply.shInstall dependencies:
# for Ubuntu 20.04.
apt install cmake libuv1-dev liblz4-dev liblzma-dev libdouble-conversion-dev libdwarf-dev libunwind-dev \
libaio-dev libgflags-dev libgoogle-glog-dev libgtest-dev libgmock-dev clang-format-14 clang-14 clang-tidy-14 lld-14 \
libgoogle-perftools-dev google-perftools libssl-dev libclang-rt-14-dev gcc-10 g++-10 libboost1.71-all-dev
# for Ubuntu 22.04.
apt install cmake libuv1-dev liblz4-dev liblzma-dev libdouble-conversion-dev libdwarf-dev libunwind-dev \
libaio-dev libgflags-dev libgoogle-glog-dev libgtest-dev libgmock-dev clang-format-14 clang-14 clang-tidy-14 lld-14 \
libgoogle-perftools-dev google-perftools libssl-dev gcc-12 g++-12 libboost-all-dev
# for openEuler 2403sp1
yum install cmake libuv-devel lz4-devel xz-devel double-conversion-devel libdwarf-devel libunwind-devel \
libaio-devel gflags-devel glog-devel gtest-devel gmock-devel clang-tools-extra clang lld \
gperftools-devel gperftools openssl-devel gcc gcc-c++ boost-develInstall other build prerequisites:
-
libfuse3.16.1 or newer version - FoundationDB 7.1 or newer version
- Rust toolchain: minimal 1.75.0, recommended 1.85.0 or newer version (latest stable version)
Build 3FS in build folder:
cmake -S . -B build -DCMAKE_CXX_COMPILER=clang++-14 -DCMAKE_C_COMPILER=clang-14 -DCMAKE_BUILD_TYPE=RelWithDebInfo -DCMAKE_EXPORT_COMPILE_COMMANDS=ON
cmake --build build -j 32
Follow instructions in setup guide to run a test cluster.
Please visit https://github.com/deepseek-ai/3fs/issues to report issues.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for 3FS
Similar Open Source Tools
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
RAGLAB
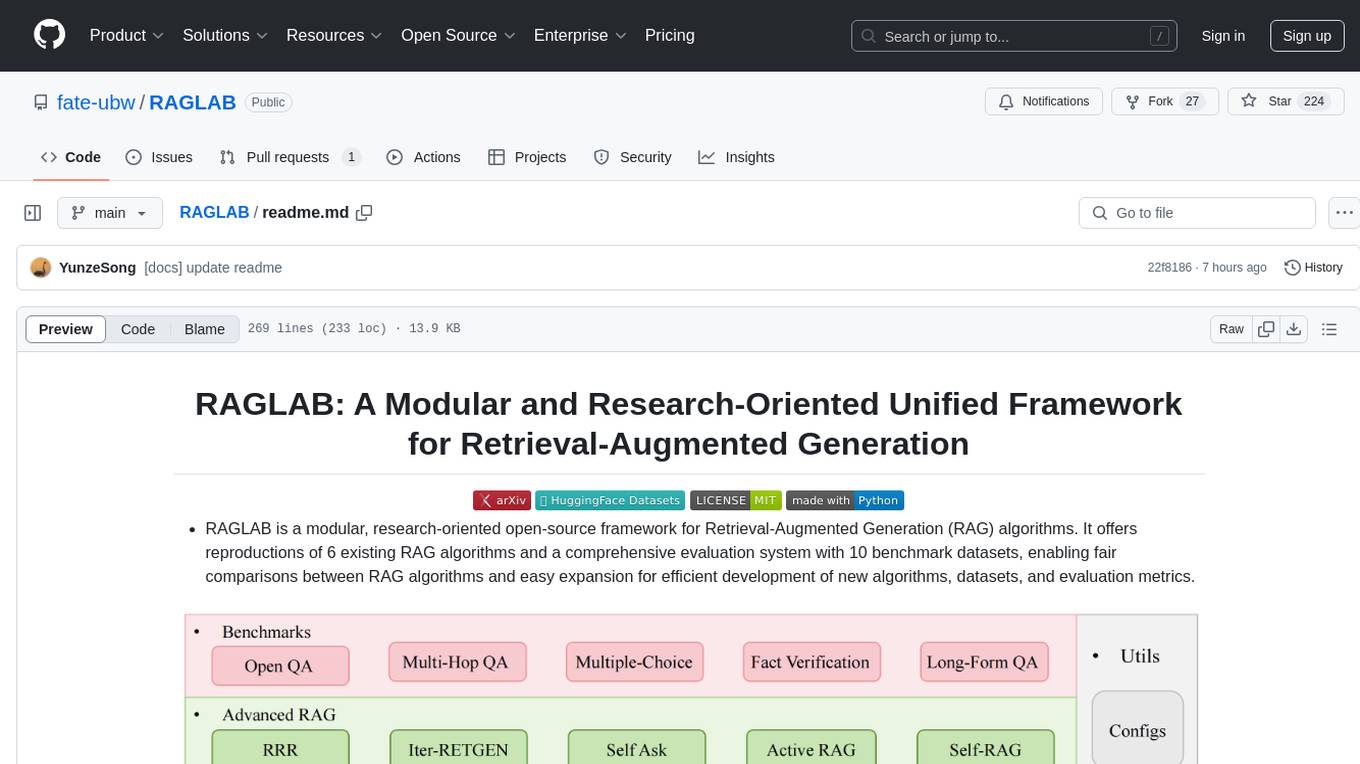
RAGLAB is a modular, research-oriented open-source framework for Retrieval-Augmented Generation (RAG) algorithms. It offers reproductions of 6 existing RAG algorithms and a comprehensive evaluation system with 10 benchmark datasets, enabling fair comparisons between RAG algorithms and easy expansion for efficient development of new algorithms, datasets, and evaluation metrics. The framework supports the entire RAG pipeline, provides advanced algorithm implementations, fair comparison platform, efficient retriever client, versatile generator support, and flexible instruction lab. It also includes features like Interact Mode for quick understanding of algorithms and Evaluation Mode for reproducing paper results and scientific research.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.

cosmos-rl
Cosmos-RL is a flexible and scalable Reinforcement Learning framework specialized for Physical AI applications. It provides a toolchain for large scale RL training workload with features like parallelism, asynchronous processing, low-precision training support, and a single-controller architecture. The system architecture includes Tensor Parallelism, Sequence Parallelism, Context Parallelism, FSDP Parallelism, and Pipeline Parallelism. It also utilizes a messaging system for coordinating policy and rollout replicas, along with dynamic NCCL Process Groups for fault-tolerant and elastic large-scale RL training.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package designed for state-of-the-art timeseries forecasting using deep learning architectures. It offers a high-level API and leverages PyTorch Lightning for efficient training on GPU or CPU with automatic logging. The package aims to simplify timeseries forecasting tasks by providing a flexible API for professionals and user-friendly defaults for beginners. It includes features such as a timeseries dataset class for handling data transformations, missing values, and subsampling, various neural network architectures optimized for real-world deployment, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. Built on pytorch-lightning, it supports training on CPUs, single GPUs, and multiple GPUs out-of-the-box.
DotRecast
DotRecast is a C# port of Recast & Detour, a navigation library used in many AAA and indie games and engines. It provides automatic navmesh generation, fast turnaround times, detailed customization options, and is dependency-free. Recast Navigation is divided into multiple modules, each contained in its own folder: - DotRecast.Core: Core utils - DotRecast.Recast: Navmesh generation - DotRecast.Detour: Runtime loading of navmesh data, pathfinding, navmesh queries - DotRecast.Detour.TileCache: Navmesh streaming. Useful for large levels and open-world games - DotRecast.Detour.Crowd: Agent movement, collision avoidance, and crowd simulation - DotRecast.Detour.Dynamic: Robust support for dynamic nav meshes combining pre-built voxels with dynamic objects which can be freely added and removed - DotRecast.Detour.Extras: Simple tool to import navmeshes created with A* Pathfinding Project - DotRecast.Recast.Toolset: All modules - DotRecast.Recast.Demo: Standalone, comprehensive demo app showcasing all aspects of Recast & Detour's functionality - Tests: Unit tests Recast constructs a navmesh through a multi-step mesh rasterization process: 1. First Recast rasterizes the input triangle meshes into voxels. 2. Voxels in areas where agents would not be able to move are filtered and removed. 3. The walkable areas described by the voxel grid are then divided into sets of polygonal regions. 4. The navigation polygons are generated by re-triangulating the generated polygonal regions into a navmesh. You can use Recast to build a single navmesh, or a tiled navmesh. Single meshes are suitable for many simple, static cases and are easy to work with. Tiled navmeshes are more complex to work with but better support larger, more dynamic environments. Tiled meshes enable advanced Detour features like re-baking, hierarchical path-planning, and navmesh data-streaming.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.

pytorch-forecasting
PyTorch Forecasting is a PyTorch-based package for time series forecasting with state-of-the-art network architectures. It offers a high-level API for training networks on pandas data frames and utilizes PyTorch Lightning for scalable training on GPUs and CPUs. The package aims to simplify time series forecasting with neural networks by providing a flexible API for professionals and default settings for beginners. It includes a timeseries dataset class, base model class, multiple neural network architectures, multi-horizon timeseries metrics, and hyperparameter tuning with optuna. PyTorch Forecasting is built on pytorch-lightning for easy training on various hardware configurations.
Atom
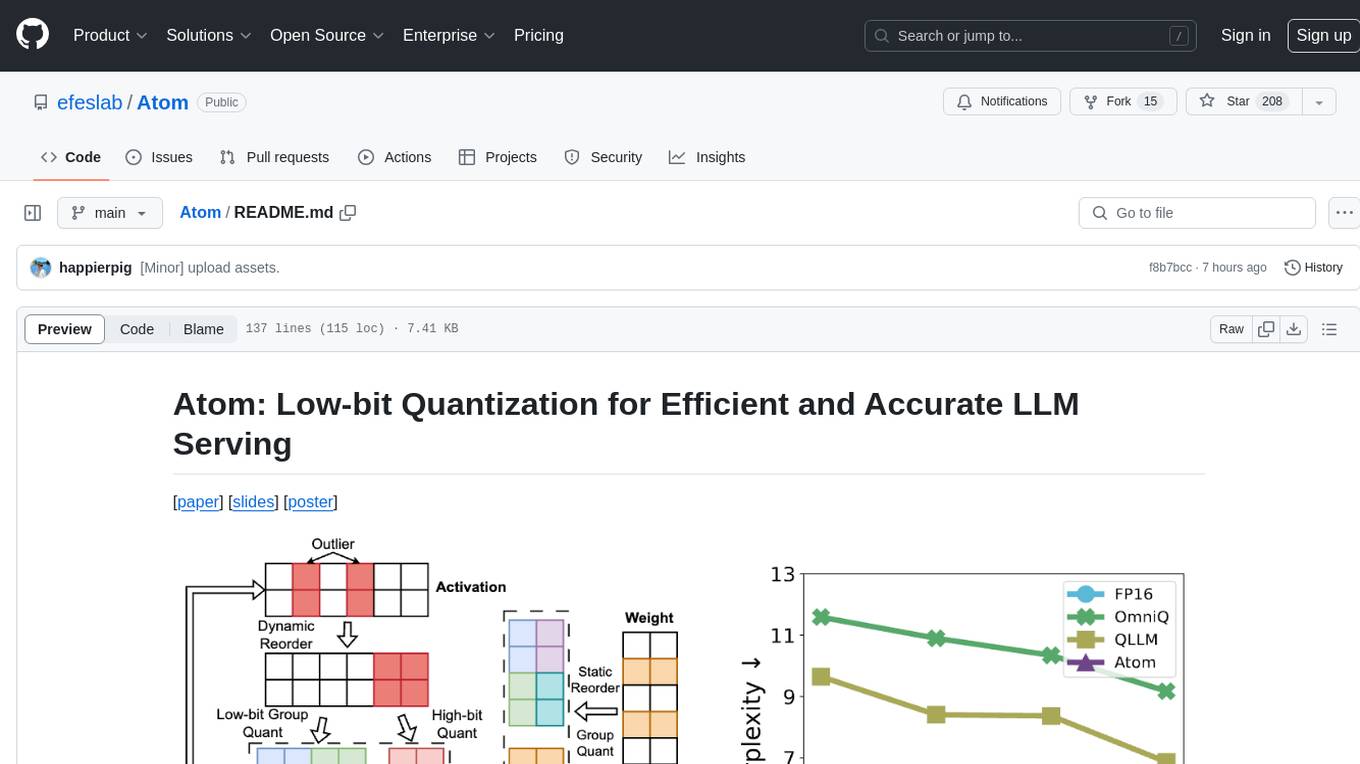
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
ten_framework
TEN Framework, short for Transformative Extensions Network, is the world's first real-time multimodal AI agent framework. It offers native support for high-performance, real-time multimodal interactions, supports multiple languages and platforms, enables edge-cloud integration, provides flexibility beyond model limitations, and allows for real-time agent state management. The framework facilitates the development of complex AI applications that transcend the limitations of large models by offering a drag-and-drop programming approach. It is suitable for scenarios like simultaneous interpretation, speech-to-text conversion, multilingual chat rooms, audio interaction, and audio-visual interaction.
tidb.ai
TiDB.AI is a conversational search RAG (Retrieval-Augmented Generation) app based on TiDB Serverless Vector Storage. It provides an out-of-the-box and embeddable QA robot experience based on knowledge from official and documentation sites. The platform features a Perplexity-style Conversational Search page with an advanced built-in website crawler for comprehensive coverage. Users can integrate an embeddable JavaScript snippet into their website for instant responses to product-related queries. The tech stack includes Next.js, TypeScript, Tailwind CSS, shadcn/ui for design, TiDB for database storage, Kysely for SQL query building, NextAuth.js for authentication, Vercel for deployments, and LlamaIndex for the RAG framework. TiDB.AI is open-source under the Apache License, Version 2.0.
contracts
AXONE Smart Contracts repository hosts Smart Contracts for the AXONE network, compatible with any Cosmos blockchains using the CosmWasm framework. It includes storage, sovereignty, and resource management oriented Smart Contracts. Each contract has different functionalities and maturity stages, with detailed tech documentation and emojis indicating maturity levels. The repository provides tools for building, testing, deploying, and interacting with Smart Contracts, along with guidelines for contributing and community engagement.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
uccl
UCCL is a command-line utility tool designed to simplify the process of converting Unix-style file paths to Windows-style file paths and vice versa. It provides a convenient way for developers and system administrators to handle file path conversions without the need for manual adjustments. With UCCL, users can easily convert file paths between different operating systems, making it a valuable tool for cross-platform development and file management tasks.
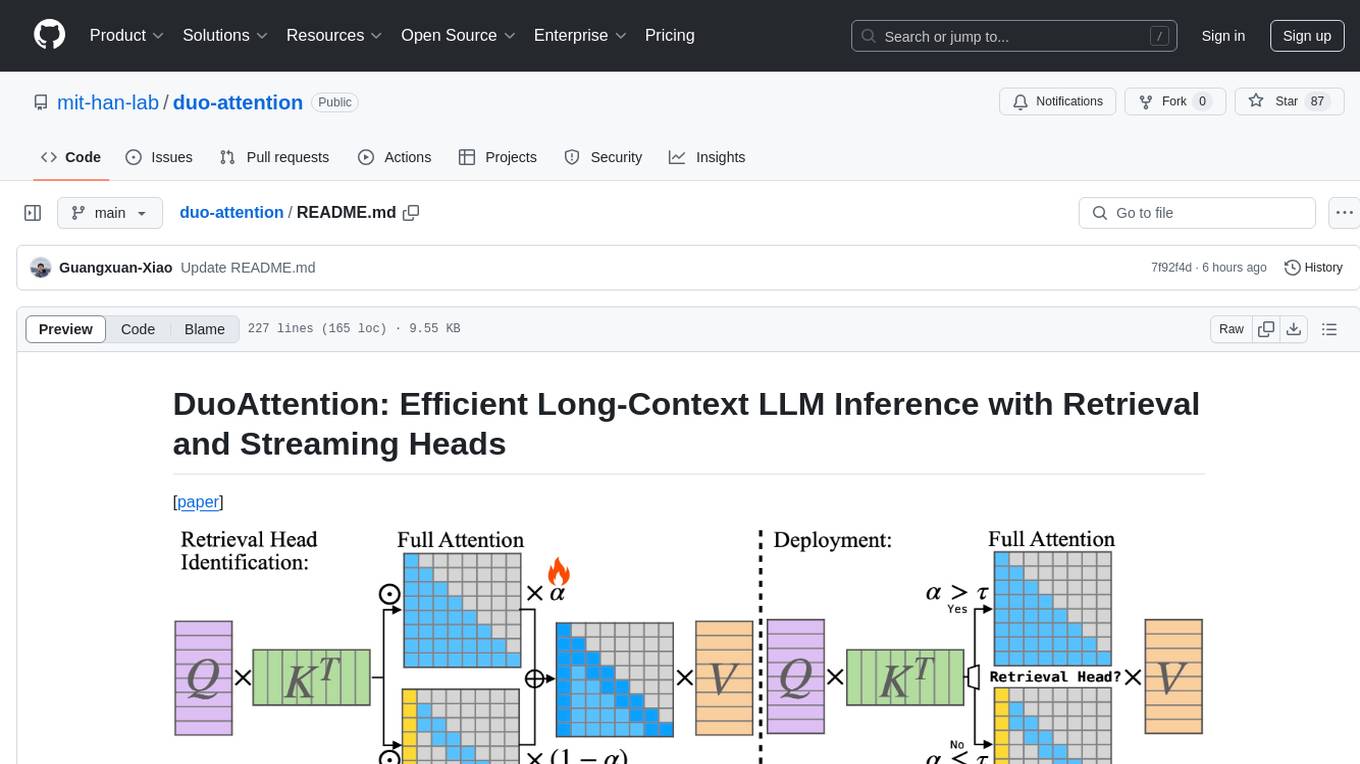
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
For similar tasks
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
For similar jobs
beta9
Beta9 is an open-source platform for running scalable serverless GPU workloads across cloud providers. It allows users to scale out workloads to thousands of GPU or CPU containers, achieve ultrafast cold-start for custom ML models, automatically scale to zero to pay for only what is used, utilize flexible distributed storage, distribute workloads across multiple cloud providers, and easily deploy task queues and functions using simple Python abstractions. The platform is designed for launching remote serverless containers quickly, featuring a custom, lazy loading image format backed by S3/FUSE, a fast redis-based container scheduling engine, content-addressed storage for caching images and files, and a custom runc container runtime.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
genai-factory
GenAI Factory is a collection of end-to-end blueprints to deploy generative AI infrastructures in Google Cloud Platform (GCP), following security best practices. It embraces Infrastructure as Code (IaC) best practices, implements infrastructure in Terraform, and follows the least-privilege principle. The tool is compatible with Cloud Foundation Fabric FAST project-factory and application templates, allowing users to deploy various AI applications and systems on GCP.
flux-aio
Flux All-In-One is a lightweight distribution optimized for running the GitOps Toolkit controllers as a single deployable unit on Kubernetes clusters. It is designed for bare clusters, edge clusters, clusters with restricted communication, clusters with egress via proxies, and serverless clusters. The distribution follows semver versioning and provides documentation for specifications, installation, upgrade, OCI sync configuration, Git sync configuration, and multi-tenancy configuration. Users can deploy Flux using Timoni CLI and a Timoni Bundle file, fine-tune installation options, sync from public Git repositories, bootstrap repositories, and uninstall Flux without affecting reconciled workloads.
paddler
Paddler is an open-source load balancer and reverse proxy designed specifically for optimizing servers running llama.cpp. It overcomes typical load balancing challenges by maintaining a stateful load balancer that is aware of each server's available slots, ensuring efficient request distribution. Paddler also supports dynamic addition or removal of servers, enabling integration with autoscaling tools.
DaoCloud-docs
DaoCloud Enterprise 5.0 Documentation provides detailed information on using DaoCloud, a Certified Kubernetes Service Provider. The documentation covers current and legacy versions, workflow control using GitOps, and instructions for opening a PR and previewing changes locally. It also includes naming conventions, writing tips, references, and acknowledgments to contributors. Users can find guidelines on writing, contributing, and translating pages, along with using tools like MkDocs, Docker, and Poetry for managing the documentation.
ztncui-aio
This repository contains a Docker image with ZeroTier One and ztncui to set up a standalone ZeroTier network controller with a web user interface. It provides features like Golang auto-mkworld for generating a planet file, supports local persistent storage configuration, and includes a public file server. Users can build the Docker image, set up the container with specific environment variables, and manage the ZeroTier network controller through the web interface.
devops-gpt
DevOpsGPT is a revolutionary tool designed to streamline your workflow and empower you to build systems and automate tasks with ease. Tired of spending hours on repetitive DevOps tasks? DevOpsGPT is here to help! Whether you're setting up infrastructure, speeding up deployments, or tackling any other DevOps challenge, our app can make your life easier and more productive. With DevOpsGPT, you can expect faster task completion, simplified workflows, and increased efficiency. Ready to experience the DevOpsGPT difference? Visit our website, sign in or create an account, start exploring the features, and share your feedback to help us improve. DevOpsGPT will become an essential tool in your DevOps toolkit.