
duo-attention
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Stars: 57
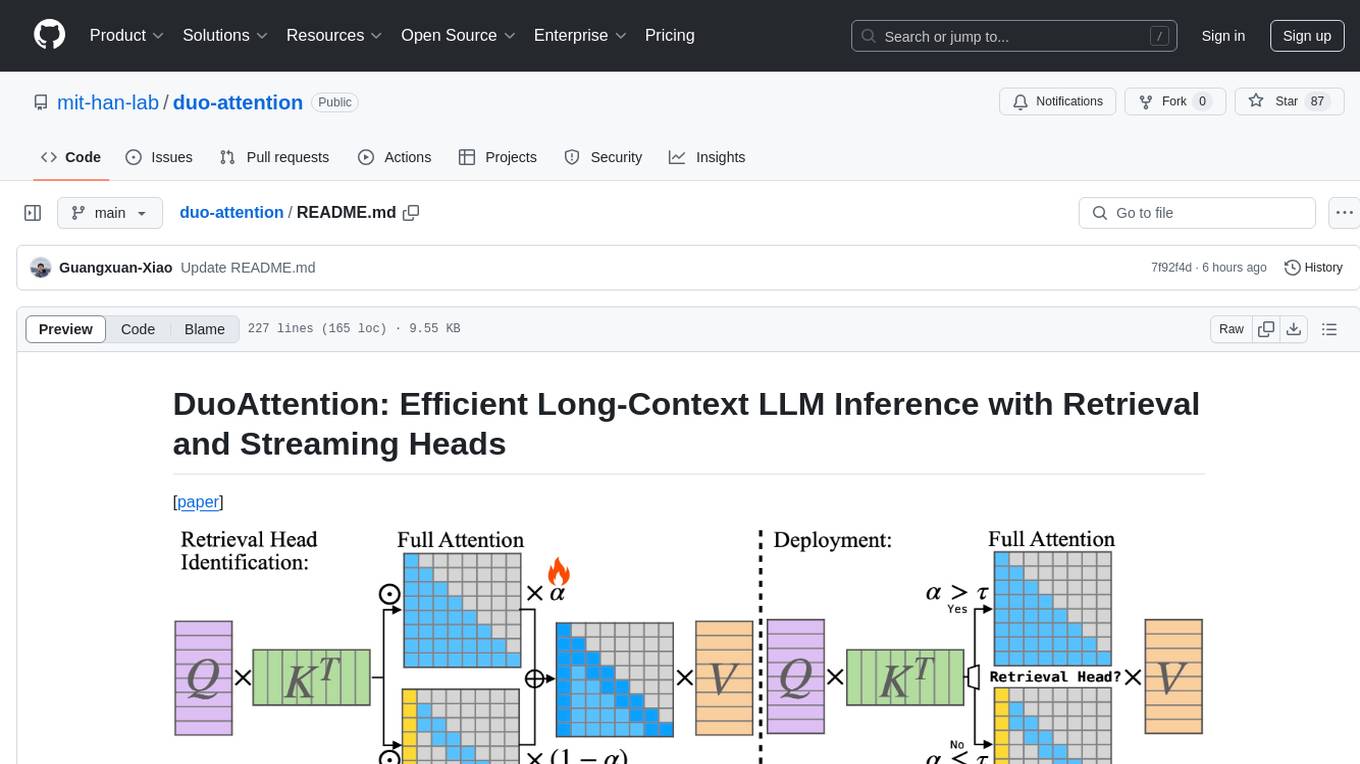
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
README:
[paper]


https://github.com/user-attachments/assets/b372882b-bf14-4c89-a610-22724d91a415
We significantly reduce both pre-filling and decoding memory and latency for long-context LLMs without sacrificing their long-context abilities.
Deploying long-context large language models (LLMs) is essential but poses significant computational and memory challenges. Caching all Key and Value (KV) states across all attention heads consumes substantial memory. Existing KV cache pruning methods either damage the long-context capabilities of LLMs or offer only limited efficiency improvements. In this paper, we identify that only a fraction of attention heads, a.k.a, Retrieval Heads, are critical for processing long contexts and require full attention across all tokens. In contrast, all other heads, which primarily focus on recent tokens and attention sinks, referred to as Streaming Heads, do not require full attention. Based on this insight, we introduce DuoAttention, a framework that only applies a full KV cache to retrieval heads while using a light-weight, constant-length KV cache for streaming heads, which reduces both LLM's decoding and pre-filling memory and latency without compromising its long-context abilities. DuoAttention uses a lightweight, optimization-based algorithm with synthetic data to identify retrieval heads accurately. Our method significantly reduces long-context inference memory by up to 2.55x for MHA and 1.67x for GQA models while speeding up decoding by up to 2.18x and 1.50x and accelerating pre-filling by up to 1.73x and 1.63x for MHA and GQA models, respectively, with minimal accuracy loss compared to full attention. Notably, combined with quantization, DuoAttention enables Llama-3-8B decoding with 3.3 million context length on a single A100 GPU.
conda create -yn duo python=3.10
conda activate duo
conda install -y git
conda install -y nvidia/label/cuda-12.4.0::cuda-toolkit
conda install -y nvidia::cuda-cudart-dev
conda install -y pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
pip install transformers accelerate sentencepiece datasets wandb accelerate sentencepiece datasets wandb zstandard matplotlib huggingface_hub
pip install tensor_parallel
pip install ninja packaging
pip install flash-attn --no-build-isolation
# LongBench evaluation
pip install seaborn rouge_score einops pandas
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.4/
# Install DuoAttention
pip install -e .
# Install Block Sparse Streaming Attention
git clone [email protected]:mit-han-lab/Block-Sparse-Attention.git
cd Block-Sparse-Attention
python setup.py installconda create -yn duo_demo python=3.10
conda activate duo_demo
# Install DuoAttention
pip install -e .
conda install -y git
conda install -y nvidia/label/cuda-12.4.0::cuda-toolkit
conda install -y nvidia::cuda-cudart-dev
# Install QServe
git clone [email protected]:mit-han-lab/qserve.git
cd qserve
pip install -e .
pip install ninja packaging
pip install flash-attn==2.4.1 --no-build-isolation
cd kernels
python setup.py install
# Install FlashInfer
pip install flashinfer -i https://flashinfer.ai/whl/cu121/torch2.3/
pip install tensor_parallelTo download the dataset:
mkdir -p datasets
cd datasets
wget https://huggingface.co/datasets/togethercomputer/Long-Data-Collections/resolve/main/fine-tune/booksum.jsonl.zstTo download models supported by DuoAttention:
mkdir -p models
cd models
# Models that DuoAttention currently supports for evaluation
huggingface-cli download togethercomputer/Llama-2-7B-32K-Instruct --local-dir Llama-2-7B-32K-Instruct
huggingface-cli download gradientai/Llama-3-8B-Instruct-Gradient-1048k --local-dir Llama-3-8B-Instruct-Gradient-1048k
huggingface-cli download gradientai/Llama-3-8B-Instruct-Gradient-4194k --local-dir Llama-3-8B-Instruct-Gradient-4194k
huggingface-cli download mistralai/Mistral-7B-Instruct-v0.2 --local-dir Mistral-7B-Instruct-v0.2
huggingface-cli download mistralai/Mistral-7B-Instruct-v0.3 --local-dir Mistral-7B-Instruct-v0.3
# W8A8KV4 models using SmoothQuant and QServe for demo purposes
huggingface-cli download mit-han-lab/Llama-3-8B-Instruct-Gradient-1048k-w8a8kv4-per-channel --local-dir Llama-3-8B-Instruct-Gradient-1048k-w8a8kv4-per-channel
huggingface-cli download mit-han-lab/Llama-3-8B-Instruct-Gradient-4194k-w8a8kv4-per-channel --local-dir Llama-3-8B-Instruct-Gradient-4194k-w8a8kv4-per-channelWe offer a simple one-click patch to enable DuoAttention optimization on HuggingFace models, including Llama and Mistral. Pretrained retrieval head patterns for five long-context models are available in the attn_patterns directory: Llama-2-7B-32K-Instruct, Llama-3-8B-Instruct-Gradient-1048k, Llama-3-8B-Instruct-Gradient-4194k, Mistral-7B-Instruct-v0.2, and Mistral-7B-Instruct-v0.3. If you'd like to train your own retrieval head patterns, you can use the training script provided in the scripts directory. Below is an example of how to enable DuoAttention on the Llama-3-8B-Instruct-Gradient-1048k model.
from duo_attn.utils import load_attn_pattern, sparsify_attention_heads
from duo_attn.patch import enable_duo_attention_eval
import transformers
import torch
# Load the model
model = transformers.AutoModelForCausalLM.from_pretrained(
"models/Llama-3-8B-Instruct-Gradient-1048k",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
attn_implementation="eager",
)
# Load the attention pattern
attn_heads, sink_size, recent_size = load_attn_pattern(
"attn_patterns/Llama-3-8B-Instruct-Gradient-1048k/lr=0.02-reg=0.05-ctx=1000_32000-multi_passkey10"
)
# Sparsify attention heads
attn_heads, sparsity = sparsify_attention_heads(attn_heads, sparsity=0.5)
# Enable DuoAttention
enable_duo_attention_eval(
model,
attn_heads,
num_recent_tokens=64,
num_sink_tokens=256,
)
# Move model to GPU
model = model.cuda()
# Ready for inference!After setting up the environment, you can run the following script to execute the W4A8KV4 with DuoAttention demo on the Llama-3-8B-Instruct-Gradient-4194k model. The demo is designed to run on a single A100 GPU and supports a context length of up to 3.3 million tokens.
bash scripts/run_demo.shAfter preparing the dataset and models, you can run the training script to identify the retrieval heads. For the models we evaluated, the corresponding attention patterns are available in the attn_patterns directory.
bash scripts/run_train.shDuoAttention provides comparable accuracy as full attention on the Needle-in-a-Haystack benchmark using 25% full attention ratio on the MHA model and 50% full attention ratio on the GQA model.
bash scripts/run_niah.sh
bash scripts/run_longbench.shDuoAttention provides better KV budget and accuracy trade-off on LongBench benchmarks.

bash scripts/run_efficiency.sh- Per-token decoding latency and memory usage of DuoAttention compared to full attention across varying context sizes. DuoAttention uses a 25% retrieval head ratio for Llama-2-7B (MHA) and 50% for Llama-3-8B (GQA). DuoAttention achieves up to 2.45× memory reduction for MHA and 1.65× for GQA models, along with up to 2.13× latency reduction for MHA and 1.5× for GQA models. These reductions approach the inverse of the retrieval head ratios as context length increases. Out-of-memory (OOM) results are linearly extrapolated from measured data.

- Pre-filling latency and memory usage of DuoAttention compared to full attention across varying pre-filling chunk sizes. DuoAttention uses a 25% retrieval head ratio for Llama-2-7B (MHA), pre-filling a context of 100K tokens, and a 50% ratio for Llama-3-8B (GQA), pre-filling a context of 320K tokens. As the pre-filling chunk size decreases, DuoAttention achieves up to 1.73× latency reduction for MHA and 1.63× for GQA models, with memory reductions up to 2.38× for MHA and 1.53× for GQA models.

- DuoAttention’s decoding memory and latency vs. KV budget with a fixed context length. Memory and latency are reduced linearly when the ratio of retrieval heads is reduced. DuoAttention achieves up to 2.55× memory reduction for MHA and 1.67× for GQA models, along with up to 2.18× latency reduction for MHA and 1.50× for GQA models.

- Combined with 8-bit weight and 4-bit KV cache quantization, DuoAttention can accommodate 3.3 million tokens on a single A100-80G GPU for the Llama-3-8B model.

If you find DuoAttention useful or relevant to your project and research, please kindly cite our paper:
@article{xiao2024duo,
title={DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads},
author={Xiao, Guangxuan and Tang, Jiaming and Zuo, Jingwei and Guo, Junxian and Yang, Shang and Tang, Haotian and Fu, Yao and Han, Song},
journal={arXiv},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for duo-attention
Similar Open Source Tools
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.

aimo-progress-prize
This repository contains the training and inference code needed to replicate the winning solution to the AI Mathematical Olympiad - Progress Prize 1. It consists of fine-tuning DeepSeekMath-Base 7B, high-quality training datasets, a self-consistency decoding algorithm, and carefully chosen validation sets. The training methodology involves Chain of Thought (CoT) and Tool Integrated Reasoning (TIR) training stages. Two datasets, NuminaMath-CoT and NuminaMath-TIR, were used to fine-tune the models. The models were trained using open-source libraries like TRL, PyTorch, vLLM, and DeepSpeed. Post-training quantization to 8-bit precision was done to improve performance on Kaggle's T4 GPUs. The project structure includes scripts for training, quantization, and inference, along with necessary installation instructions and hardware/software specifications.
Atom
Atom is an accurate low-bit weight-activation quantization algorithm that combines mixed-precision, fine-grained group quantization, dynamic activation quantization, KV-cache quantization, and efficient CUDA kernels co-design. It introduces a low-bit quantization method, Atom, to maximize Large Language Models (LLMs) serving throughput with negligible accuracy loss. The codebase includes evaluation of perplexity and zero-shot accuracy, kernel benchmarking, and end-to-end evaluation. Atom significantly boosts serving throughput by using low-bit operators and reduces memory consumption via low-bit quantization.
rig
Rig is a Rust library designed for building scalable, modular, and user-friendly applications powered by large language models (LLMs). It provides full support for LLM completion and embedding workflows, offers simple yet powerful abstractions for LLM providers like OpenAI and Cohere, as well as vector stores such as MongoDB and in-memory storage. With Rig, users can easily integrate LLMs into their applications with minimal boilerplate code.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.

supallm
Supallm is a Python library for super resolution of images using deep learning techniques. It provides pre-trained models for enhancing image quality by increasing resolution. The library is easy to use and allows users to upscale images with high fidelity and detail. Supallm is suitable for tasks such as enhancing image quality, improving visual appearance, and increasing the resolution of low-quality images. It is a valuable tool for researchers, photographers, graphic designers, and anyone looking to enhance image quality using AI technology.
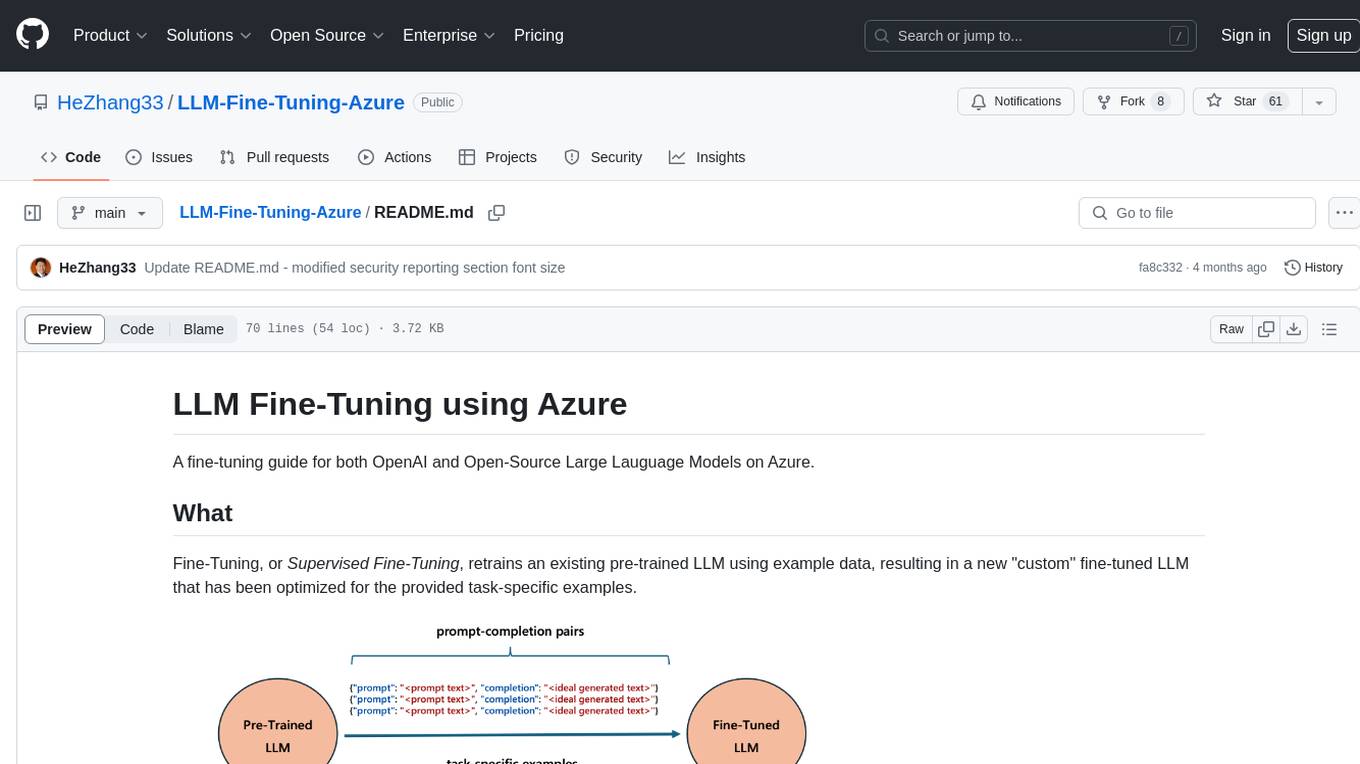
LLM-Fine-Tuning-Azure
A fine-tuning guide for both OpenAI and Open-Source Large Language Models on Azure. Fine-Tuning retrains an existing pre-trained LLM using example data, resulting in a new 'custom' fine-tuned LLM optimized for task-specific examples. Use cases include improving LLM performance on specific tasks and introducing information not well represented by the base LLM model. Suitable for cases where latency is critical, high accuracy is required, and clear evaluation metrics are available. Learning path includes labs for fine-tuning GPT and Llama2 models via Dashboards and Python SDK.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.
archgw
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize AI agents with APIs. It handles tasks related to prompts, including detecting jailbreak attempts, calling backend APIs, routing between LLMs, and managing observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and observability. Users can build fast, observable, and personalized AI agents using Arch to improve speed, security, and personalization of GenAI apps.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

HPT
Hyper-Pretrained Transformers (HPT) is a novel multimodal LLM framework from HyperGAI, trained for vision-language models capable of understanding both textual and visual inputs. The repository contains the open-source implementation of inference code to reproduce the evaluation results of HPT Air on different benchmarks. HPT has achieved competitive results with state-of-the-art models on various multimodal LLM benchmarks. It offers models like HPT 1.5 Air and HPT 1.0 Air, providing efficient solutions for vision-and-language tasks.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
LLM-Drop
LLM-Drop is an official implementation of the paper 'What Matters in Transformers? Not All Attention is Needed'. The tool investigates redundancy in transformer-based Large Language Models (LLMs) by analyzing the architecture of Blocks, Attention layers, and MLP layers. It reveals that dropping certain Attention layers can enhance computational and memory efficiency without compromising performance. The tool provides a pipeline for Block Drop and Layer Drop based on LLaMA-Factory, and implements quantization using AutoAWQ and AutoGPTQ.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
Dispider
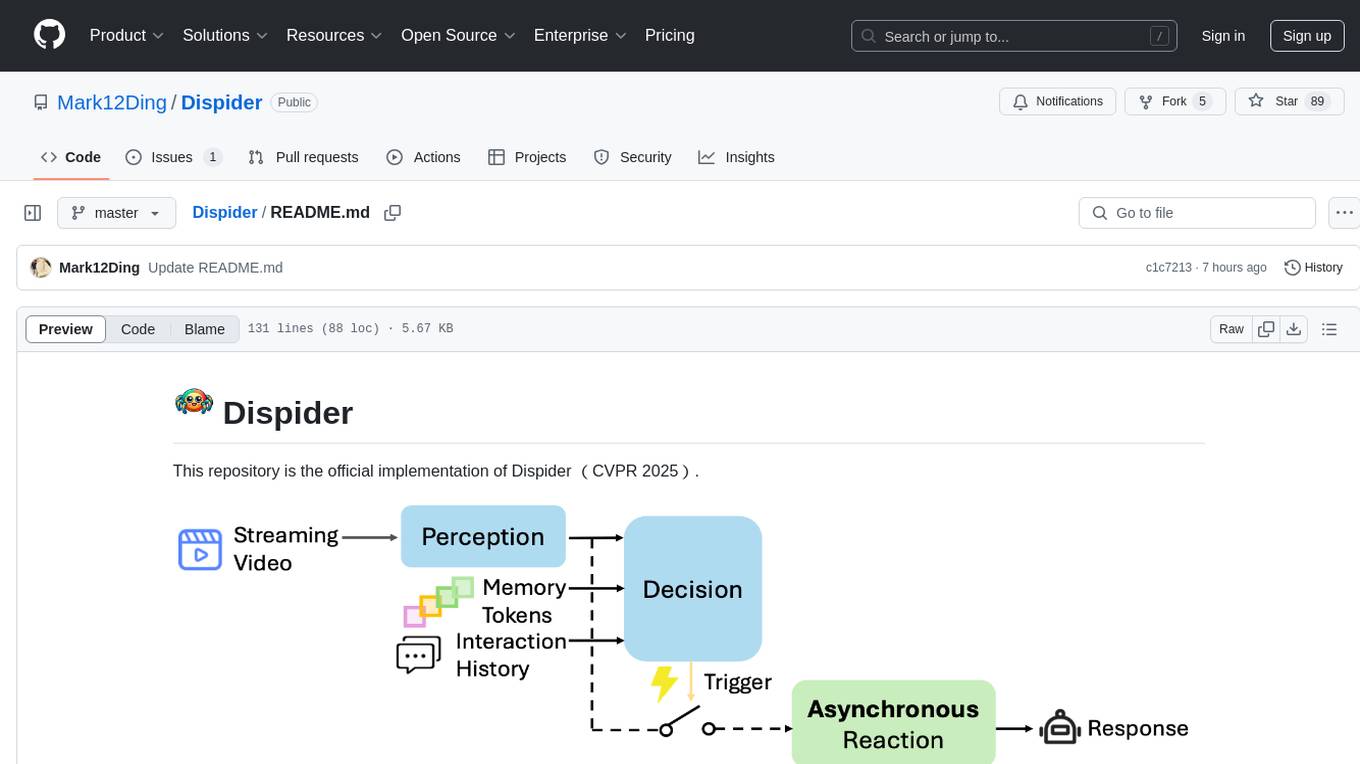
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar tasks
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
edgen
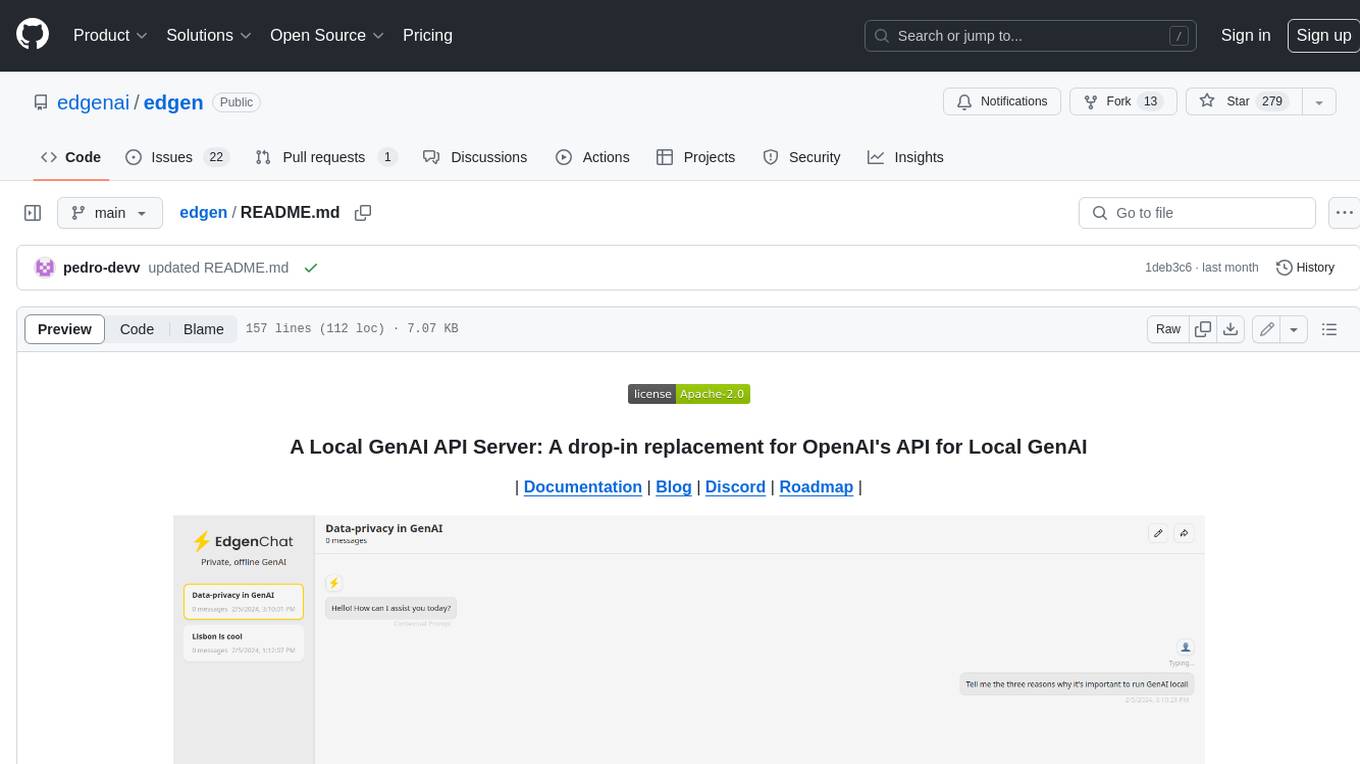
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.

easydist
EasyDist is an automated parallelization system and infrastructure designed for multiple ecosystems. It offers usability by making parallelizing training or inference code effortless with just a single line of change. It ensures ecological compatibility by serving as a centralized source of truth for SPMD rules at the operator-level for various machine learning frameworks. EasyDist decouples auto-parallel algorithms from specific frameworks and IRs, allowing for the development and benchmarking of different auto-parallel algorithms in a flexible manner. The architecture includes MetaOp, MetaIR, and the ShardCombine Algorithm for SPMD sharding rules without manual annotations.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.

ServerlessLLM
ServerlessLLM is a fast, affordable, and easy-to-use library designed for multi-LLM serving, optimized for environments with limited GPU resources. It supports loading various leading LLM inference libraries, achieving fast load times, and reducing model switching overhead. The library facilitates easy deployment via Ray Cluster and Kubernetes, integrates with the OpenAI Query API, and is actively maintained by contributors.
sarathi-serve
Sarathi-Serve is the official OSDI'24 artifact submission for paper #444, focusing on 'Taming Throughput-Latency Tradeoff in LLM Inference'. It is a research prototype built on top of CUDA 12.1, designed to optimize throughput-latency tradeoff in Large Language Models (LLM) inference. The tool provides a Python environment for users to install and reproduce results from the associated experiments. Users can refer to specific folders for individual figures and are encouraged to cite the paper if they use the tool in their work.

aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
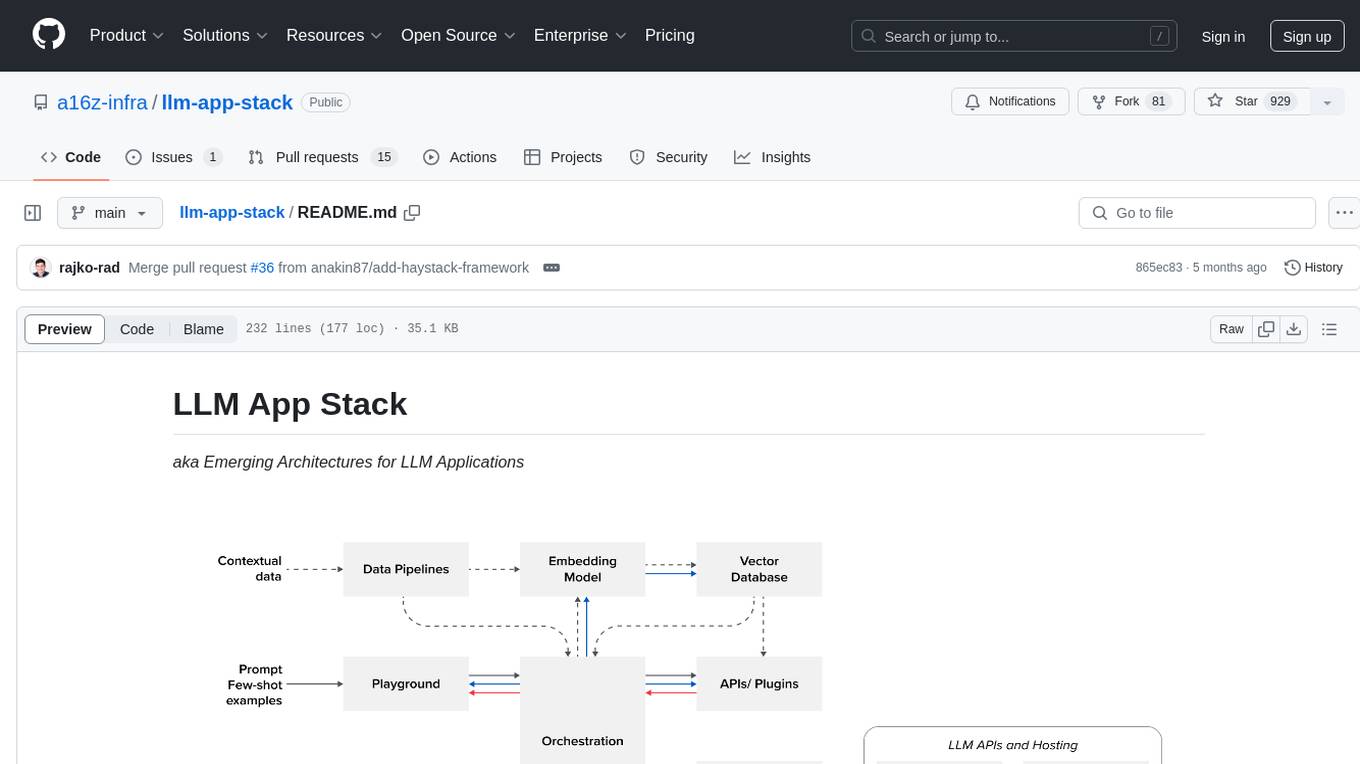
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
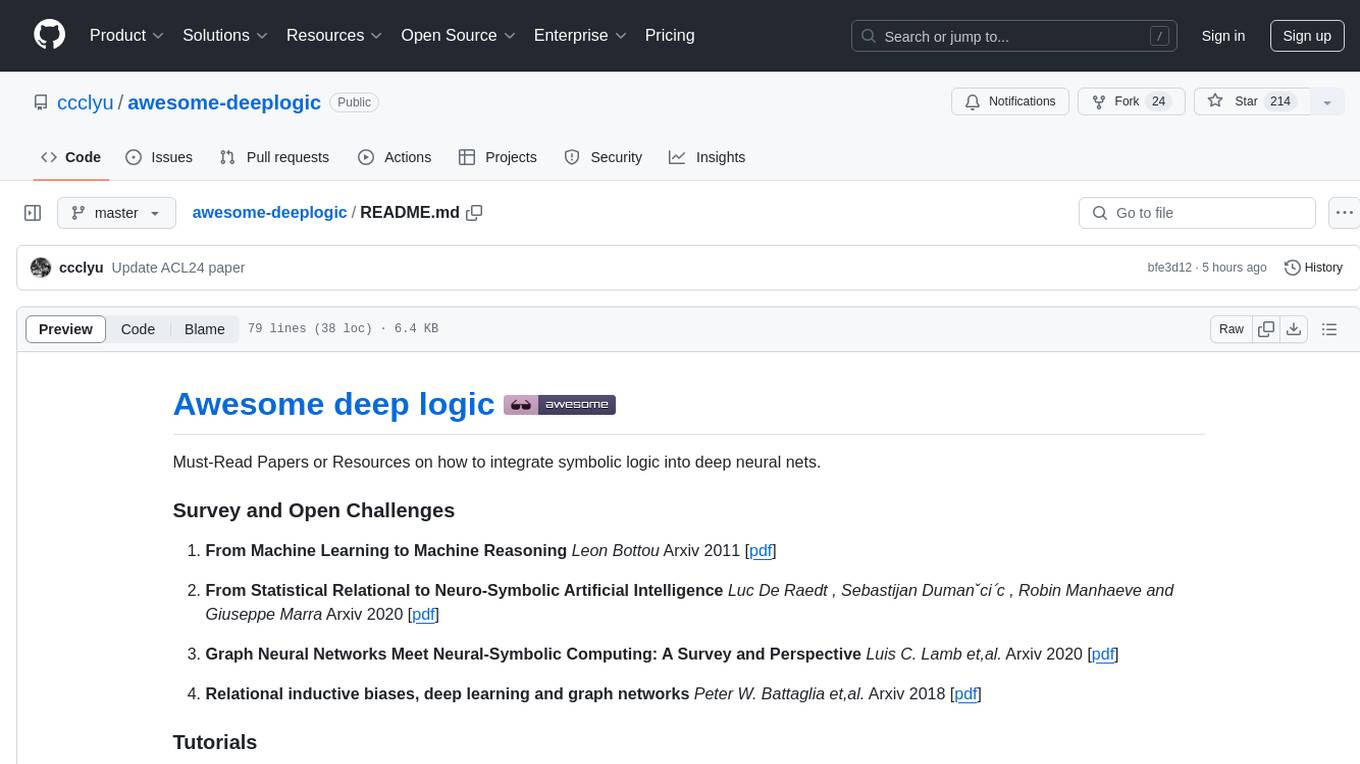
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
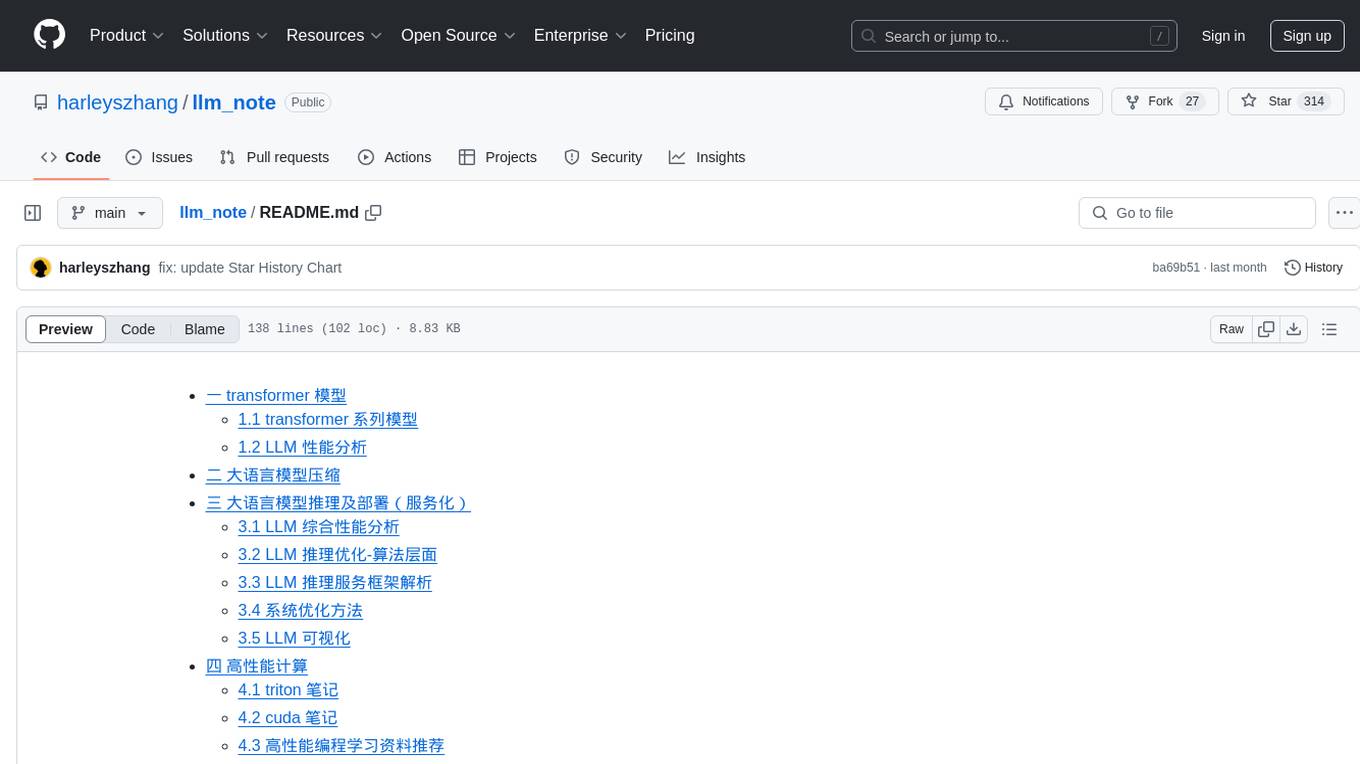
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.