
Awesome-LLMs-on-device
Awesome LLMs on Device: A Comprehensive Survey
Stars: 747

Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
README:

Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
- 📊 Comprehensive overview of on-device LLM evolution with easy-to-understand visualizations
- 🧠 In-depth analysis of groundbreaking architectures and optimization techniques
- 📱 Curated list of state-of-the-art models and frameworks ready for on-device deployment
- 💡 Practical examples and case studies to inspire your next project
- 🔄 Regular updates to keep you at the forefront of rapid advancements in the field
- 🤝 Active community of researchers and practitioners sharing insights and experiences
- Awesome LLMs on Device: A Comprehensive Survey
- Contents
- Tutorials and Learning Resources
- Citation
- Tinyllama: An open-source small language model
arXiv 2024 [Paper] [Github] - MobileVLM V2: Faster and Stronger Baseline for Vision Language Model
arXiv 2024 [Paper] [Github] - MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
arXiv 2024 [Paper] - Octopus series papers
arXiv 2024 [Octopus] [Octopus v2] [Octopus v3] [Octopus v4] [Github] - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
arXiv 2024 [Paper] - AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
arXiv 2023 [Paper] [Github]
- The case for 4-bit precision: k-bit inference scaling laws
ICML 2023 [Paper] - Challenges and applications of large language models
arXiv 2023 [Paper] - MiniLLM: Knowledge distillation of large language models
ICLR 2023 [Paper] [github] - Gptq: Accurate post-training quantization for generative pre-trained transformers
ICLR 2023 [Paper] [Github] - Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale
NeurIPS 2022 [Paper]
- OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
ICML 2024 [Paper] [Github]
- Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
arXiv 2024 [Paper] - Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
arXiv 2024 [Paper] - Exploring post-training quantization in llms from comprehensive study to low rank compensation
AAAI 2024 [Paper] - Matrix compression via randomized low rank and low precision factorization
NeurIPS 2023 [Paper] [Github]
- MNN: A lightweight deep neural network inference engine
2024 [Github] - PowerInfer-2: Fast Large Language Model Inference on a Smartphone
arXiv 2024 [Paper] [Github] - llama.cpp: Lightweight library for Approximate Nearest Neighbors and Maximum Inner Product Search
2023 [Github] - Powerinfer: Fast large language model serving with a consumer-grade gpu
arXiv 2023 [Paper] [Github] - mllm: Fast and lightweight multimodal LLM inference engine for mobile and edge devices
2023 [Github]
| Model | Performance | Computational Efficiency | Memory Requirements |
|---|---|---|---|
| MobileLLM | High accuracy, optimized for sub-billion parameter models | Embedding sharing, grouped-query attention | Reduced model size due to deep and thin structures |
| EdgeShard | Up to 50% latency reduction, 2× throughput improvement | Collaborative edge-cloud computing, optimal shard placement | Distributed model components reduce individual device load |
| LLMCad | Up to 9.3× speedup in token generation | Generate-then-verify, token tree generation | Smaller LLM for token generation, larger LLM for verification |
| Any-Precision LLM | Supports multiple precisions efficiently | Post-training quantization, memory-efficient design | Substantial memory savings with versatile model precisions |
| Breakthrough Memory | Up to 4.5× performance improvement | PIM and PNM technologies enhance memory processing | Enhanced memory bandwidth and capacity |
| MELTing Point | Provides systematic performance evaluation | Analyzes impacts of quantization, efficient model evaluation | Evaluates memory and computational efficiency trade-offs |
| LLMaaS on device | Reduces context switching latency significantly | Stateful execution, fine-grained KV cache compression | Efficient memory management with tolerance-aware compression and swapping |
| LocMoE | Reduces training time per epoch by up to 22.24% | Orthogonal gating weights, locality-based expert regularization | Minimizes communication overhead with group-wise All-to-All and recompute pipeline |
| EdgeMoE | Significant performance improvements on edge devices | Expert-wise bitwidth adaptation, preloading experts | Efficient memory management through expert-by-expert computation reordering |
| JetMoE | Outperforms Llama27B and 13B-Chat with fewer parameters | Reduces inference computation by 70% using sparse activation | 8B total parameters, only 2B activated per input token |
Pangu-$\pi$ Pro |
Neural architecture, parameter initialization, and optimization strategy for billion-level parameter models | Embedding sharing, tokenizer compression | Reduced model size via architecture tweaking |
- AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
arXiv 2024 [Paper] [Github] - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
arXiv 2024 [Paper] [Github]
- EdgeShard: Efficient LLM Inference via Collaborative Edge Computing
arXiv 2024 [Paper] - Llmcad: Fast and scalable on-device large language model inference
arXiv 2023 [Paper]
- The Breakthrough Memory Solutions for Improved Performance on LLM Inference
IEEE Micro 2024 [Paper] - MELTing point: Mobile Evaluation of Language Transformers
arXiv 2024 [Paper] [Github]
- LLM as a system service on mobile devices
arXiv 2024 [Paper] - Locmoe: A low-overhead moe for large language model training
arXiv 2024 [Paper] - Edgemoe: Fast on-device inference of moe-based large language models
arXiv 2023 [Paper]
- Any-Precision LLM: Low-Cost Deployment of Multiple, Different-Sized LLMs
arXiv 2024 [Paper] [Github] - On the viability of using llms for sw/hw co-design: An example in designing cim dnn accelerators
IEEE SOCC 2023 [Paper]
- The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
arXiv 2024 [Paper] - AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
arXiv 2024 [Paper] [Github] - Gptq: Accurate post-training quantization for generative pre-trained transformers
ICLR 2023 [Paper] [Github] - Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale
NeurIPS 2022 [Paper]
- Challenges and applications of large language models
arXiv 2023 [Paper]
- MiniLLM: Knowledge distillation of large language models
ICLR 2024 [Paper]
- Exploring post-training quantization in llms from comprehensive study to low rank compensation
AAAI 2024 [Paper] - Matrix compression via randomized low rank and low precision factorization
NeurIPS 2023 [Paper] [Github]
- llama.cpp: A lightweight library for efficient LLM inference on various hardware with minimal setup. [Github]
- MNN: A blazing fast, lightweight deep learning framework. [Github]
- PowerInfer: A CPU/GPU LLM inference engine leveraging activation locality for device. [Github]
- ExecuTorch: A platform for On-device AI across mobile, embedded and edge for PyTorch. [Github]
- MediaPipe: A suite of tools and libraries, enables quick application of AI and ML techniques. [Github]
- MLC-LLM: A machine learning compiler and high-performance deployment engine for large language models. [Github]
- VLLM: A fast and easy-to-use library for LLM inference and serving. [Github]
- OpenLLM: An open platform for operating large language models (LLMs) in production. [Github]
- The Breakthrough Memory Solutions for Improved Performance on LLM Inference
IEEE Micro 2024 [Paper] - Aquabolt-XL: Samsung HBM2-PIM with in-memory processing for ML accelerators and beyond
IEEE Hot Chips 2021 [Paper]
- Text Generating For Messaging: Gboard smart reply
- Translation: LLMCad
- Meeting Summarizing
- Healthcare application: BioMistral-7B, HuatuoGPT
- Research Support
- Companion Robot
- Disability Support: Octopus v3, Talkback with Gemini Nano
- Autonomous Vehicles: DriveVLM
| Model | Institute | Paper |
|---|---|---|
| Gemini Nano | Gemini: A Family of Highly Capable Multimodal Models | |
| Octopus series model | Nexa AI |
Octopus v2: On-device language model for super agent Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent Octopus v4: Graph of language models Octopus: On-device language model for function calling of software APIs |
| OpenELM and Ferret-v2 | Apple |
OpenELM is a significant large language model integrated within iOS to enhance application functionalities. Ferret-v2 significantly improves upon its predecessor, introducing enhanced visual processing capabilities and an advanced training regimen. |
| Phi series | Microsoft | Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone |
| MiniCPM | Tsinghua University | A GPT-4V Level Multimodal LLM on Your Phone |
| Gemma2-9B | Gemma 2: Improving Open Language Models at a Practical Size | |
| Qwen2-0.5B | Alibaba Group | Qwen Technical Report |
- MIT: TinyML and Efficient Deep Learning Computing
- Harvard: Machine Learning Systems
- Deep Learning AI : Introduction to on-device AI
We believe in the power of community! If you're passionate about on-device AI and want to contribute to this ever-growing knowledge hub, here's how you can get involved:
- Fork the repository
- Create a new branch for your brilliant additions
- Make your updates and push your changes
- Submit a pull request and become part of the on-device LLM movement
If our hub fuels your research or powers your projects, we'd be thrilled if you could cite our paper here:
@article{xu2024device,
title={On-Device Language Models: A Comprehensive Review},
author={Xu, Jiajun and Li, Zhiyuan and Chen, Wei and Wang, Qun and Gao, Xin and Cai, Qi and Ling, Ziyuan},
journal={arXiv preprint arXiv:2409.00088},
year={2024}
}This project is open-source and available under the MIT License. See the LICENSE file for more details.
Don't just read about the future of AI – be part of it. Star this repo, spread the word, and let's push the boundaries of on-device LLMs together! 🚀🌟
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLMs-on-device
Similar Open Source Tools
Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.

parallax
Parallax is a fully decentralized inference engine developed by Gradient. It allows users to build their own AI cluster for model inference across distributed nodes with varying configurations and physical locations. Core features include hosting local LLM on personal devices, cross-platform support, pipeline parallel model sharding, paged KV cache management, continuous batching for Mac, dynamic request scheduling, and routing for high performance. The backend architecture includes P2P communication powered by Lattica, GPU backend powered by SGLang and vLLM, and MAC backend powered by MLX LM.
gorilla
Gorilla is a tool that enables LLMs to use tools by invoking APIs. Given a natural language query, Gorilla comes up with the semantically- and syntactically- correct API to invoke. With Gorilla, you can use LLMs to invoke 1,600+ (and growing) API calls accurately while reducing hallucination. Gorilla also releases APIBench, the largest collection of APIs, curated and easy to be trained on!
SimAI
SimAI is the industry's first full-stack, high-precision simulator for AI large-scale training. It provides detailed modeling and simulation of the entire LLM training process, encompassing framework, collective communication, network layers, and more. This comprehensive approach offers end-to-end performance data, enabling researchers to analyze training process details, evaluate time consumption of AI tasks under specific conditions, and assess performance gains from various algorithmic optimizations.

xllm
xLLM is an efficient LLM inference framework optimized for Chinese AI accelerators, enabling enterprise-grade deployment with enhanced efficiency and reduced cost. It adopts a service-engine decoupled inference architecture, achieving breakthrough efficiency through technologies like elastic scheduling, dynamic PD disaggregation, multi-stream parallel computing, graph fusion optimization, and global KV cache management. xLLM supports deployment of mainstream large models on Chinese AI accelerators, empowering enterprises in scenarios like intelligent customer service, risk control, supply chain optimization, ad recommendation, and more.
Awesome-local-LLM
Awesome-local-LLM is a curated list of platforms, tools, practices, and resources that help run Large Language Models (LLMs) locally. It includes sections on inference platforms, engines, user interfaces, specific models for general purpose, coding, vision, audio, and miscellaneous tasks. The repository also covers tools for coding agents, agent frameworks, retrieval-augmented generation, computer use, browser automation, memory management, testing, evaluation, research, training, and fine-tuning. Additionally, there are tutorials on models, prompt engineering, context engineering, inference, agents, retrieval-augmented generation, and miscellaneous topics, along with a section on communities for LLM enthusiasts.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
awesome-MLSecOps
Awesome MLSecOps is a curated list of open-source tools, resources, and tutorials for MLSecOps (Machine Learning Security Operations). It includes a wide range of security tools and libraries for protecting machine learning models against adversarial attacks, as well as resources for AI security, data anonymization, model security, and more. The repository aims to provide a comprehensive collection of tools and information to help users secure their machine learning systems and infrastructure.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

ERNIE
ERNIE 4.5 is a family of large-scale multimodal models with 10 distinct variants, including Mixture-of-Experts (MoE) models with 47B and 3B active parameters. The models feature a novel heterogeneous modality structure supporting parameter sharing across modalities while allowing dedicated parameters for each individual modality. Trained with optimal efficiency using PaddlePaddle deep learning framework, ERNIE 4.5 models achieve state-of-the-art performance across text and multimodal benchmarks, enhancing multimodal understanding without compromising performance on text-related tasks. The open-source development toolkits for ERNIE 4.5 offer industrial-grade capabilities, resource-efficient training and inference workflows, and multi-hardware compatibility.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.
rai
RAI is a framework designed to bring general multi-agent system capabilities to robots, enhancing human interactivity, flexibility in problem-solving, and out-of-the-box AI features. It supports multi-modalities, incorporates an advanced database for agent memory, provides ROS 2-oriented tooling, and offers a comprehensive task/mission orchestrator. The framework includes features such as voice interaction, customizable robot identity, camera sensor access, reasoning through ROS logs, and integration with LangChain for AI tools. RAI aims to support various AI vendors, improve human-robot interaction, provide an SDK for developers, and offer a user interface for configuration.


lobe-chat
Lobe Chat is an open-source, modern-design ChatGPT/LLMs UI/Framework. Supports speech-synthesis, multi-modal, and extensible ([function call][docs-functionc-call]) plugin system. One-click **FREE** deployment of your private OpenAI ChatGPT/Claude/Gemini/Groq/Ollama chat application.
For similar tasks

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
AIInfra
AIInfra is an open-source project focused on AI infrastructure, specifically targeting large models in distributed clusters, distributed architecture, distributed training, and algorithms related to large models. The project aims to explore and study system design in artificial intelligence and deep learning, with a focus on the hardware and software stack for building AI large model systems. It provides a comprehensive curriculum covering topics such as AI chip principles, communication and storage, AI clusters, large model training, and inference, as well as algorithms for large models. The course is designed for undergraduate and graduate students, as well as professionals working with AI large model systems, to gain a deep understanding of AI computer system architecture and design.
Awesome-LLM-Quantization
Awesome-LLM-Quantization is a curated list of resources related to quantization techniques for Large Language Models (LLMs). Quantization is a crucial step in deploying LLMs on resource-constrained devices, such as mobile phones or edge devices, by reducing the model's size and computational requirements.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.
Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
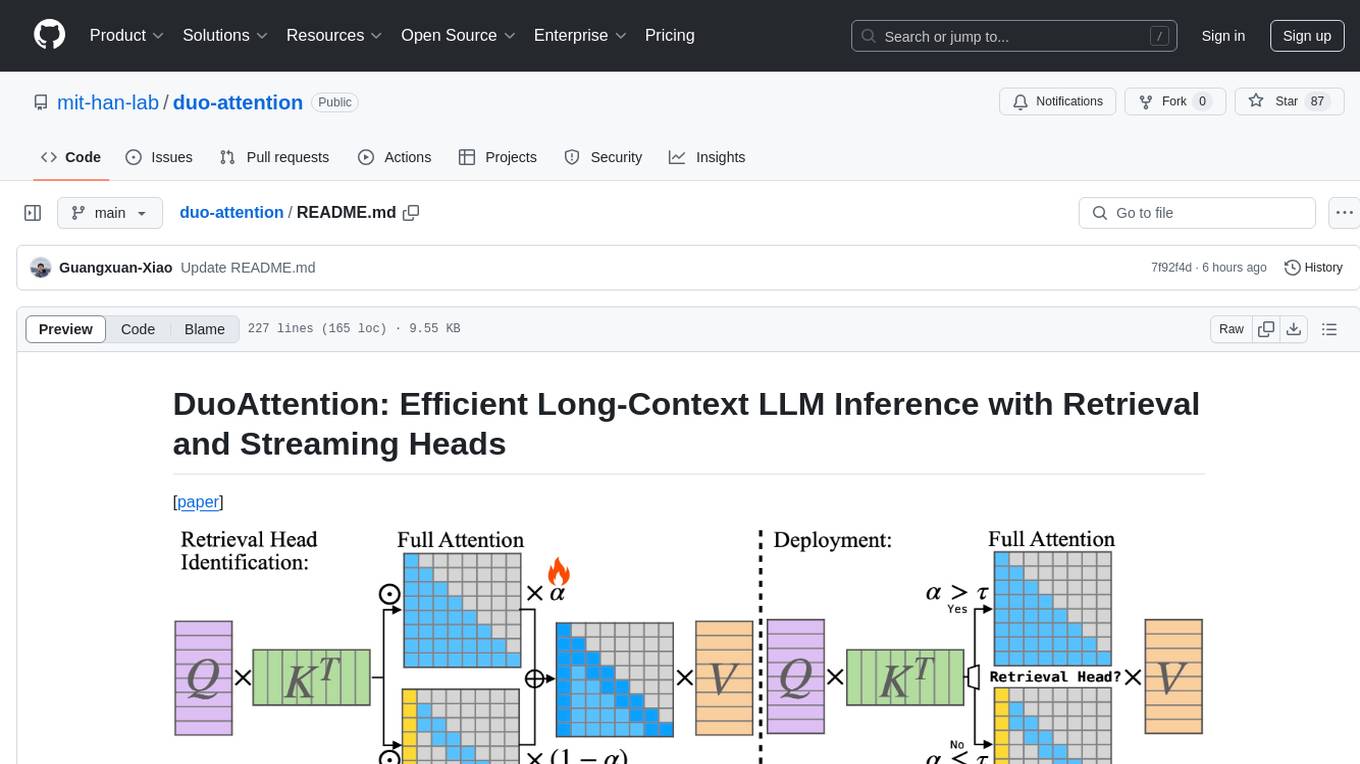
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.