
unilm
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Stars: 19617

The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
README:
We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on Foundation Models (aka large-scale pre-trained models) and General AI, NLP, MT, Speech, Document AI and Multimodal AI, please send your resume to [email protected].
TorchScale - A Library of Foundation Architectures (repo)
Fundamental research to develop new architectures for foundation models and AI, focusing on modeling generality and capability, as well as training stability and efficiency.
Stability - DeepNet: scaling Transformers to 1,000 Layers and beyond
Generality - Foundation Transformers (Magneto): towards true general-purpose modeling across tasks and modalities (including language, vision, speech, and multimodal)
Capability - A Length-Extrapolatable Transformer
Efficiency & Transferability - X-MoE: scalable & finetunable sparse Mixture-of-Experts (MoE)
BitNet: 1-bit Transformers for Large Language Models
RetNet: Retentive Network: A Successor to Transformer for Large Language Models
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Kosmos-2.5: A Multimodal Literate Model
Kosmos-2: Grounding Multimodal Large Language Models to the World
Kosmos-1: A Multimodal Large Language Model (MLLM)
MetaLM: Language Models are General-Purpose Interfaces
The Big Convergence - Large-scale self-supervised pre-training across tasks (predictive and generative), languages (100+ languages), and modalities (language, image, audio, layout/format + language, vision + language, audio + language, etc.)
UniLM: unified pre-training for language understanding and generation
InfoXLM/XLM-E: multilingual/cross-lingual pre-trained models for 100+ languages
DeltaLM/mT6: encoder-decoder pre-training for language generation and translation for 100+ languages
MiniLM: small and fast pre-trained models for language understanding and generation
AdaLM: domain, language, and task adaptation of pre-trained models
EdgeLM(
NEW): small pre-trained models on edge/client devices
SimLM (
NEW): large-scale pre-training for similarity matching
E5 (
NEW): text embeddings
MiniLLM (
NEW): Knowledge Distillation of Large Language Models
BEiT/BEiT-2: generative self-supervised pre-training for vision / BERT Pre-Training of Image Transformers
DiT: self-supervised pre-training for Document Image Transformers
TextDiffuser/TextDiffuser-2 (
NEW): Diffusion Models as Text Painters
WavLM: speech pre-training for full stack tasks
VALL-E: a neural codec language model for TTS
LayoutLM/LayoutLMv2/LayoutLMv3: multimodal (text + layout/format + image) Document Foundation Model for Document AI (e.g. scanned documents, PDF, etc.)
LayoutXLM: multimodal (text + layout/format + image) Document Foundation Model for multilingual Document AI
MarkupLM: markup language model pre-training for visually-rich document understanding
XDoc: unified pre-training for cross-format document understanding
UniSpeech: unified pre-training for self-supervised learning and supervised learning for ASR
UniSpeech-SAT: universal speech representation learning with speaker-aware pre-training
SpeechT5: encoder-decoder pre-training for spoken language processing
SpeechLM: Enhanced Speech Pre-Training with Unpaired Textual Data
VLMo: Unified vision-language pre-training
VL-BEiT (
NEW): Generative Vision-Language Pre-training - evolution of BEiT to multimodal
BEiT-3 (
NEW): a general-purpose multimodal foundation model, and a major milestone of The Big Convergence of Large-scale Pre-training Across Tasks, Languages, and Modalities.
s2s-ft: sequence-to-sequence fine-tuning toolkit
Aggressive Decoding (
NEW): lossless and efficient sequence-to-sequence decoding algorithm
TrOCR: transformer-based OCR w/ pre-trained models
LayoutReader: pre-training of text and layout for reading order detection
XLM-T: multilingual NMT w/ pretrained cross-lingual encoders
LLMOps (repo)
General technology for enabling AI capabilities w/ LLMs and MLLMs.
- December, 2023: LongNet and LongViT released
- [Model Release] Dec, 2023: TextDiffuser-2 models, code and demo.
- Sep, 2023: Kosmos-2.5 - a multimodal literate model for machine reading of text-intensive images.
- [Model Release] May, 2023: TextDiffuser models and code.
- [Model Release] March, 2023: BEiT-3 pretrained models and code.
- March, 2023: Kosmos-1 - a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot).
- January, 2023: VALL-E a language modeling approach for text to speech synthesis (TTS), which achieves state-of-the-art zero-shot TTS performance. See https://aka.ms/valle for demos of our work.
- [Model Release] January, 2023: E5 - Text Embeddings by Weakly-Supervised Contrastive Pre-training.
- November, 2022: TorchScale 0.1.1 was released!
- November, 2022: TrOCR was accepted by AAAI 2023.
- [Model Release] November, 2022: XDoc BASE models for cross-format document understanding.
- [Model Release] September, 2022: TrOCR BASE and LARGE models for Scene Text Recognition (STR).
- [Model Release] September, 2022: BEiT v2 code and pretrained models.
- August, 2022: BEiT-3 - a general-purpose multimodal foundation model, which achieves state-of-the-art transfer performance on both vision and vision-language tasks
- July, 2022: SimLM - Large-scale self-supervised pre-training for similarity matching
- June, 2022: DiT and LayoutLMv3 were accepted by ACM Multimedia 2022.
- June, 2022: MetaLM - Language models are general-purpose interfaces to foundation models (language/multilingual, vision, speech, and multimodal)
- June, 2022: VL-BEiT - bidirectional multimodal Transformer learned from scratch with one unified pretraining task, one shared backbone, and one-stage training, supporting both vision and vision-language tasks.
- [Model Release] June, 2022: LayoutLMv3 Chinese - Chinese version of LayoutLMv3
- [Code Release] May, 2022: Aggressive Decoding - Lossless Speedup for Seq2seq Generation
- April, 2022: Transformers at Scale = DeepNet + X-MoE
- [Model Release] April, 2022: LayoutLMv3 - Pre-training for Document AI with Unified Text and Image Masking
- [Model Release] March, 2022: EdgeFormer - Parameter-efficient Transformer for On-device Seq2seq Generation
- [Model Release] March, 2022: DiT - Self-supervised Document Image Transformer. Demos: Document Layout Analysis, Document Image Classification
- January, 2022: BEiT was accepted by ICLR 2022 as Oral presentation (54 out of 3391).
- [Model Release] December 16th, 2021: TrOCR small models for handwritten and printed texts, with 3x inference speedup.
- November 24th, 2021: VLMo as the new SOTA on the VQA Challenge
- November, 2021: Multilingual translation at scale: 10000 language pairs and beyond
- [Model Release] November, 2021: MarkupLM - Pre-training for text and markup language (e.g. HTML/XML)
- [Model Release] November, 2021: VLMo - Unified vision-language pre-training w/ BEiT
- October, 2021: WavLM Large achieves state-of-the-art performance on the SUPERB benchmark
- [Model Release] October, 2021: WavLM - Large-scale self-supervised pre-trained models for speech.
- [Model Release] October 2021: TrOCR is on HuggingFace
- September 28th, 2021: T-ULRv5 (aka XLM-E/InfoXLM) as the SOTA on the XTREME leaderboard. // Blog
- [Model Release] September, 2021: LayoutLM-cased are on HuggingFace
- [Model Release] September, 2021: TrOCR - Transformer-based OCR w/ pre-trained BEiT and RoBERTa models.
- August 2021: LayoutLMv2 and LayoutXLM are on HuggingFace
- [Model Release] August, 2021: LayoutReader - Built with LayoutLM to improve general reading order detection.
- [Model Release] August, 2021: DeltaLM - Encoder-decoder pre-training for language generation and translation.
- August 2021: BEiT is on HuggingFace
- [Model Release] July, 2021: BEiT - Towards BERT moment for CV
- [Model Release] June, 2021: LayoutLMv2, LayoutXLM, MiniLMv2, and AdaLM.
- May, 2021: LayoutLMv2, InfoXLMv2, MiniLMv2, UniLMv3, and AdaLM were accepted by ACL 2021.
- April, 2021: LayoutXLM is coming by extending the LayoutLM into multilingual support! A multilingual form understanding benchmark XFUND is also introduced, which includes forms with human labeled key-value pairs in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese).
- March, 2021: InfoXLM was accepted by NAACL 2021.
- December 29th, 2020: LayoutLMv2 is coming with the new SOTA on a wide variety of document AI tasks, including DocVQA and SROIE leaderboard.
- October 8th, 2020: T-ULRv2 (aka InfoXLM) as the SOTA on the XTREME leaderboard. // Blog
- September, 2020: MiniLM was accepted by NeurIPS 2020.
- July 16, 2020: InfoXLM (Multilingual UniLM) arXiv
- June, 2020: UniLMv2 was accepted by ICML 2020; LayoutLM was accepted by KDD 2020.
- April 5, 2020: Multilingual MiniLM released!
- September, 2019: UniLMv1 was accepted by NeurIPS 2019.
This project is licensed under the license found in the LICENSE file in the root directory of this source tree. Portions of the source code are based on the transformers project.
Microsoft Open Source Code of Conduct
For help or issues using the pre-trained models, please submit a GitHub issue.
For other communications, please contact Furu Wei ([email protected]).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for unilm
Similar Open Source Tools
unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
Fueling-Ambitions-Via-Book-Discoveries
Fueling-Ambitions-Via-Book-Discoveries is an Advanced Machine Learning & AI Course designed for students, professionals, and AI researchers. The course integrates rigorous theoretical foundations with practical coding exercises, ensuring learners develop a deep understanding of AI algorithms and their applications in finance, healthcare, robotics, NLP, cybersecurity, and more. Inspired by MIT, Stanford, and Harvard’s AI programs, it combines academic research rigor with industry-standard practices used by AI engineers at companies like Google, OpenAI, Facebook AI, DeepMind, and Tesla. Learners can learn 50+ AI techniques from top Machine Learning & Deep Learning books, code from scratch with real-world datasets, projects, and case studies, and focus on ML Engineering & AI Deployment using Django & Streamlit. The course also offers industry-relevant projects to build a strong AI portfolio.
MedLLMsPracticalGuide
This repository serves as a practical guide for Medical Large Language Models (Medical LLMs) and provides resources, surveys, and tools for building, fine-tuning, and utilizing LLMs in the medical domain. It covers a wide range of topics including pre-training, fine-tuning, downstream biomedical tasks, clinical applications, challenges, future directions, and more. The repository aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs.
Wegent
Wegent is an open-source AI-native operating system designed to define, organize, and run intelligent agent teams. It offers various core features such as a chat agent with multi-model support, conversation history, group chat, attachment parsing, follow-up mode, error correction mode, long-term memory, sandbox execution, and extensions. Additionally, Wegent includes a code agent for cloud-based code execution, AI feed for task triggers, AI knowledge for document management, and AI device for running tasks locally. The platform is highly extensible, allowing for custom agents, agent creation wizard, organization management, collaboration modes, skill support, MCP tools, execution engines, YAML config, and an API for easy integration with other systems.
gen-ai-experiments
Gen-AI-Experiments is a structured collection of Jupyter notebooks and AI experiments designed to guide users through various AI tools, frameworks, and models. It offers valuable resources for both beginners and experienced practitioners, covering topics such as AI agents, model testing, RAG systems, real-world applications, and open-source tools. The repository includes folders with curated libraries, AI agents, experiments, LLM testing, open-source libraries, RAG experiments, and educhain experiments, each focusing on different aspects of AI development and application.
RSTGameTranslation
RSTGameTranslation is a tool designed for translating game text into multiple languages efficiently. It provides a user-friendly interface for game developers to easily manage and localize their game content. With RSTGameTranslation, developers can streamline the translation process, ensuring consistency and accuracy across different language versions of their games. The tool supports various file formats commonly used in game development, making it versatile and adaptable to different project requirements. Whether you are working on a small indie game or a large-scale production, RSTGameTranslation can help you reach a global audience by making localization a seamless and hassle-free experience.
J.A.R.V.I.S.2.0
J.A.R.V.I.S. 2.0 is an AI-powered assistant designed for voice commands, capable of tasks like providing weather reports, summarizing news, sending emails, and more. It features voice activation, speech recognition, AI responses, and handles multiple tasks including email sending, weather reports, news reading, image generation, database functions, phone call automation, AI-based task execution, website & application automation, and knowledge-based interactions. The assistant also includes timeout handling, automatic input processing, and the ability to call multiple functions simultaneously. It requires Python 3.9 or later and specific API keys for weather, news, email, and AI access. The tool integrates Gemini AI for function execution and Ollama as a fallback mechanism. It utilizes a RAG-based knowledge system and ADB integration for phone automation. Future enhancements include deeper mobile integration, advanced AI-driven automation, improved NLP-based command execution, and multi-modal interactions.

univer
Univer is an isomorphic full-stack framework designed for creating and editing spreadsheets, documents, and slides across web and server. It is highly extensible, high-performance, and can be embedded into applications. Univer offers a wide range of features including formulas, conditional formatting, data validation, collaborative editing, printing, import & export, and more. It supports multiple languages and provides a distraction-free editing experience with a clean interface. Univer is suitable for data analysts, software developers, project managers, content creators, and educators.
oneclick-subtitles-generator
A comprehensive web application for auto-subtitling videos and audio, translating SRT files, generating AI narration with voice cloning, creating background images, and rendering professional subtitled videos. Designed for content creators, educators, and general users who need high-quality subtitle generation and video production capabilities.
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.

AI-LLM-ML-CS-Quant-Readings
AI-LLM-ML-CS-Quant-Readings is a repository dedicated to taking notes on Artificial Intelligence, Large Language Models, Machine Learning, Computer Science, and Quantitative Finance. It contains a wide range of resources, including theory, applications, conferences, essentials, foundations, system design, computer systems, finance, and job interview questions. The repository covers topics such as AI systems, multi-agent systems, deep learning theory and applications, system design interviews, C++ design patterns, high-frequency finance, algorithmic trading, stochastic volatility modeling, and quantitative investing. It is a comprehensive collection of materials for individuals interested in these fields.
claude-code-plugins-plus-skills
Claude Code Skills & Plugins Hub is a comprehensive marketplace for agent skills and plugins, offering 1537 production-ready agent skills and 270 total plugins. It provides a learning lab with guides, diagrams, and examples for building production agent workflows. The package manager CLI allows users to discover, install, and manage plugins from their terminal, with features like searching, listing, installing, updating, and validating plugins. The marketplace is not on GitHub Marketplace and does not support built-in monetization. It is community-driven, actively maintained, and focuses on quality over quantity, aiming to be the definitive resource for Claude Code plugins.
AI-on-the-edge-device
AI-on-the-edge-device is a project that enables users to digitize analog water, gas, power, and other meters using an ESP32 board with a supported camera. It integrates Tensorflow Lite for AI processing, offers a small and affordable device with integrated camera and illumination, provides a web interface for administration and control, supports Homeassistant, Influx DB, MQTT, and REST API. The device captures meter images, extracts Regions of Interest (ROIs), runs them through AI for digitization, and allows users to send data to MQTT, InfluxDb, or access it via REST API. The project also includes 3D-printable housing options and tools for logfile management.
ClashRoyaleBuildABot
Clash Royale Build-A-Bot is a project that allows users to build their own bot to play Clash Royale. It provides an advanced state generator that accurately returns detailed information using cutting-edge technologies. The project includes tutorials for setting up the environment, building a basic bot, and understanding state generation. It also offers updates such as replacing YOLOv5 with YOLOv8 unit model and enhancing performance features like placement and elixir management. The future roadmap includes plans to label more images of diverse cards, add a tracking layer for unit predictions, publish tutorials on Q-learning and imitation learning, release the YOLOv5 training notebook, implement chest opening and card upgrading features, and create a leaderboard for the best bots developed with this repository.
timeline-studio
Timeline Studio is a next-generation professional video editor with AI integration that automates content creation for social media. It combines the power of desktop applications with the convenience of web interfaces. With 257 AI tools, GPU acceleration, plugin system, multi-language interface, and local processing, Timeline Studio offers complete video production automation. Users can create videos for various social media platforms like TikTok, YouTube, Vimeo, Telegram, and Instagram with optimized versions. The tool saves time, understands trends, provides professional quality, and allows for easy feature extension through plugins. Timeline Studio is open source, transparent, and offers significant time savings and quality improvements for video editing tasks.
For similar tasks

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.
unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
searchGPT
searchGPT is an open-source project that aims to build a search engine based on Large Language Model (LLM) technology to provide natural language answers. It supports web search with real-time results, file content search, and semantic search from sources like the Internet. The tool integrates LLM technologies such as OpenAI and GooseAI, and offers an easy-to-use frontend user interface. The project is designed to provide grounded answers by referencing real-time factual information, addressing the limitations of LLM's training data. Contributions, especially from frontend developers, are welcome under the MIT License.
LLMs-at-DoD
This repository contains tutorials for using Large Language Models (LLMs) in the U.S. Department of Defense. The tutorials utilize open-source frameworks and LLMs, allowing users to run them in their own cloud environments. The repository is maintained by the Defense Digital Service and welcomes contributions from users.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
For similar jobs
Awesome_Mamba
Awesome Mamba is a curated collection of groundbreaking research papers and articles on Mamba Architecture, a pioneering framework in deep learning known for its selective state spaces and efficiency in processing complex data structures. The repository offers a comprehensive exploration of Mamba architecture through categorized research papers covering various domains like visual recognition, speech processing, remote sensing, video processing, activity recognition, image enhancement, medical imaging, reinforcement learning, natural language processing, 3D recognition, multi-modal understanding, time series analysis, graph neural networks, point cloud analysis, and tabular data handling.
unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
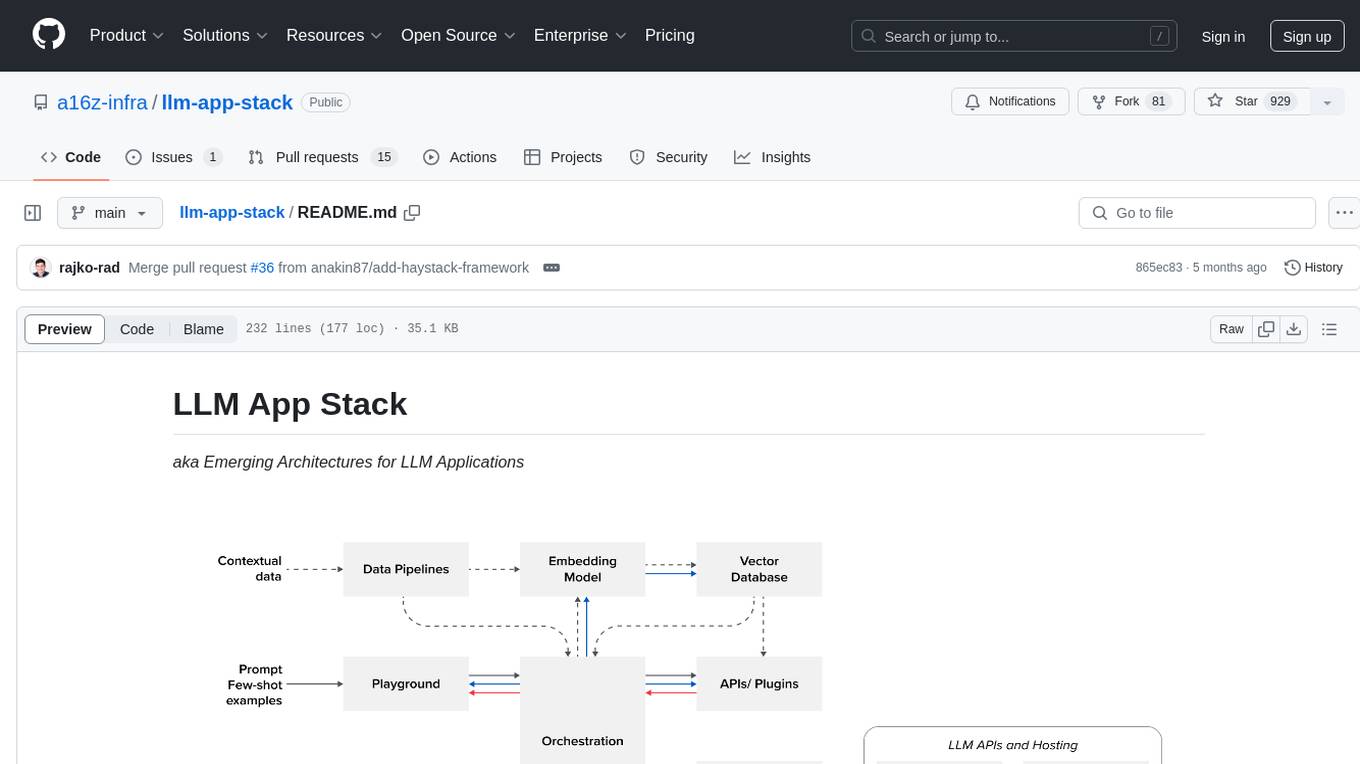
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

Awesome-LLMs-on-device
Welcome to the ultimate hub for on-device Large Language Models (LLMs)! This repository is your go-to resource for all things related to LLMs designed for on-device deployment. Whether you're a seasoned researcher, an innovative developer, or an enthusiastic learner, this comprehensive collection of cutting-edge knowledge is your gateway to understanding, leveraging, and contributing to the exciting world of on-device LLMs.
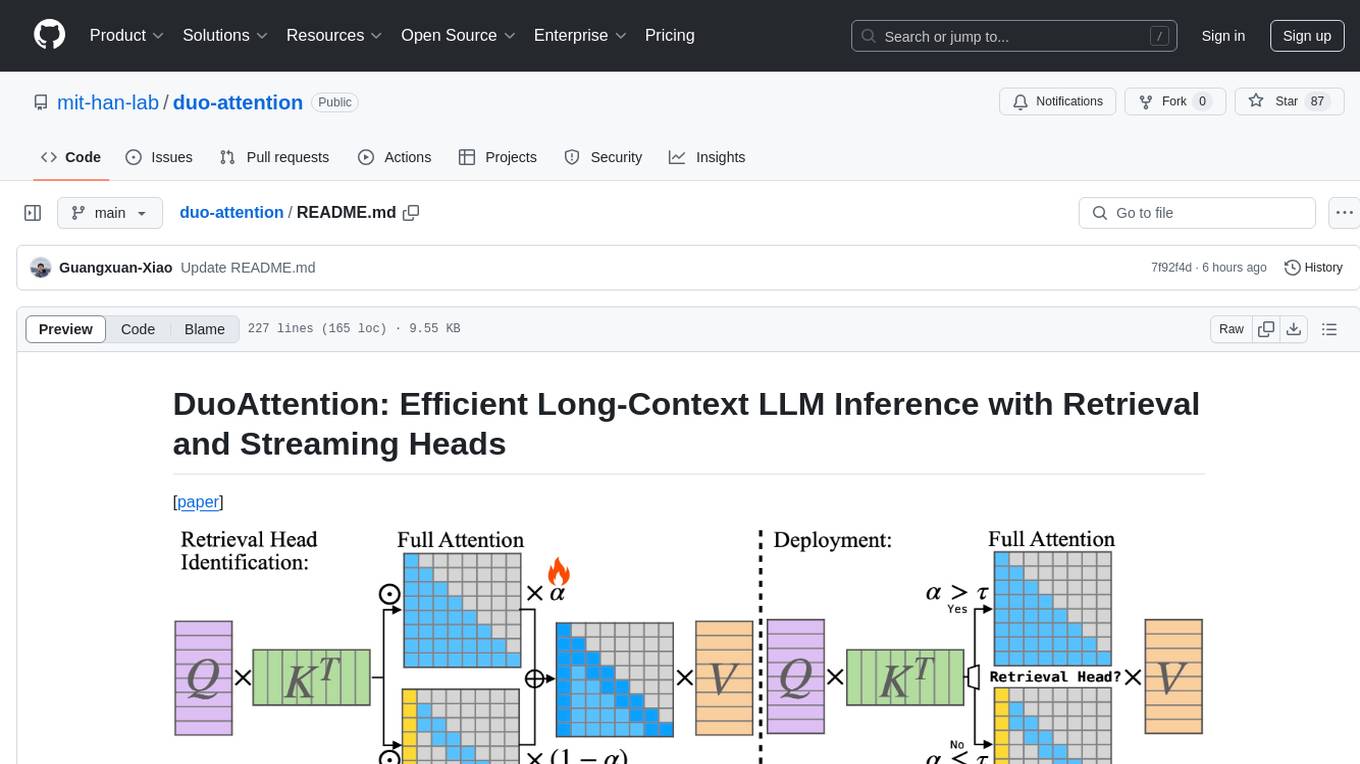
duo-attention
DuoAttention is a framework designed to optimize long-context large language models (LLMs) by reducing memory and latency during inference without compromising their long-context abilities. It introduces a concept of Retrieval Heads and Streaming Heads to efficiently manage attention across tokens. By applying a full Key and Value (KV) cache to retrieval heads and a lightweight, constant-length KV cache to streaming heads, DuoAttention achieves significant reductions in memory usage and decoding time for LLMs. The framework uses an optimization-based algorithm with synthetic data to accurately identify retrieval heads, enabling efficient inference with minimal accuracy loss compared to full attention. DuoAttention also supports quantization techniques for further memory optimization, allowing for decoding of up to 3.3 million tokens on a single GPU.
llm_note
LLM notes repository contains detailed analysis on transformer models, language model compression, inference and deployment, high-performance computing, and system optimization methods. It includes discussions on various algorithms, frameworks, and performance analysis related to large language models and high-performance computing. The repository serves as a comprehensive resource for understanding and optimizing language models and computing systems.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.