
LARS
An application for running LLMs locally on your device, with your documents, facilitating detailed citations in generated responses.
Stars: 418

LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
README:
![]()
LARS is an application that enables you to run LLM's (Large Language Models) locally on your device, upload your own documents and engage in conversations wherein the LLM grounds its responses with your uploaded content. This grounding helps increase accuracy and reduce the common issue of AI-generated inaccuracies or "hallucinations." This technique is commonly known as "Retrieval Augmented Generation", or RAG.
There are many desktop applications for running LLMs locally, and LARS aims to be the ultimate open-source RAG-centric LLM application. Towards this end, LARS takes the concept of RAG much further by adding detailed citations to every response, supplying you with specific document names, page numbers, text-highlighting, and images relevant to your question, and even presenting a document reader right within the response window. While all the citations are not always present for every response, the idea is to have at least some combination of citations brought up for every RAG response and that’s generally found to be the case.
- Advanced Citations: The main showcase feature of LARS - LLM-generated responses are appended with detailed citations comprising document names, page numbers, text highlighting and image extraction for any RAG centric responses, with a document reader presented for the user to scroll through the document right within the response window and download highlighted PDFs
- Vast number of supported file-formats:
- PDFs
- Word files: doc, docx, odt, rtf, txt
- Excel files: xls, xlsx, ods, csv
- PowerPoint presentations: ppt, pptx, odp
- Image files: bmp, gif, jpg, png, svg, tiff
- Rich Text Format (RTF)
- HTML files
- Conversion memory: Users can ask follow-up questions, including for prior conversations
- Full chat-history: Users can go back and resume prior conversations
- Users can force enable or disable RAG at any time via Settings
- Users can change the system prompt at any time via Settings
- Drag-and-drop in new LLMs - change LLM's via Settings at any time
- Built-in prompt-templates for the most popular LLMs and then some: Llama3, Llama2, ChatML, Phi3, Command-R, Deepseek Coder, Vicuna and OpenChat-3.5
- Pure llama.cpp backend - No frameworks, no Python-bindings, no abstractions - just pure llama.cpp! Upgrade to newer versions of llama.cpp independent of LARS
- GPU-accelerated inferencing: Nvidia CUDA-accelerated inferencing supported
- Tweak advanced LLM settings - Change LLM temperature, top-k, top-p, min-p, n-keep, set the number of model layers to be offloaded to the GPU, and enable or disable the use of GPUs, all via Settings at any time
- Four embedding models - sentence-transformers/all-mpnet-base-v2, BGE-Base, BGE-Large, OpenAI Text-Ada
- Sources UI - A table is displayed for the selected embedding model detailing the documents that have been uploaded to LARS, including vectorization details such as chunk_size and chunk_overlap
- A reset button is provided to empty and reset the vectorDB
- Three text extraction methods: a purely local text-extraction option and two OCR options via Azure for better accuracy and scanned document support - Azure ComputerVision OCR has an always free-tier
- A custom parser for the Azure AI Document-Intelligence OCR service for enhanced table-data extraction while preventing double-text by accounting for the spatial coordinates of the extracted text
LARS Feature-Demonstration Video
![]()
- LARS - The LLM & Advanced Referencing Solution
- Dependencies
- Installing LARS
- Usage - First Run
- Optional Dependencies
- Troubleshooting Installation Issues
- First Run with llama.cpp
- General User Guide - Post First-Run Steps
- Troubleshooting
- Docker - Deploying Containerized LARS
- Current Development Roadmap
- Support and Donations
-
Python v3.10.x or above: https://www.python.org/downloads/
-
PyTorch:
If you're planning to use your GPU to run LLMs, make sure to install the GPU drivers and CUDA/ROCm toolkits as appropriate for your setup, and only then proceed with PyTorch setup below
Download and install the PyTorch version appropriate for your system: https://pytorch.org/get-started/locally/
-
Clone the repository:
git clone https://github.com/abgulati/LARS cd LARS- If prompted for GitHub authentication, use a Personal Access Token as passwords are deprecated. Also accessible via:
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokens
- If prompted for GitHub authentication, use a Personal Access Token as passwords are deprecated. Also accessible via:
-
Install Python dependencies:
-
Windows via PIP:
pip install -r .\requirements.txt -
Linux via PIP:
pip3 install -r ./requirements.txt -
Note on Azure: Some required Azure libraries are NOT available on the MacOS platform! A separate requirements file is therefore included for MacOS excluding these libraries:
-
MacOS:
pip3 install -r ./requirements_mac.txt
-
-
After installing, run LARS using:
cd web_app python app.py # Use 'python3' on Linux/macOS -
Navigate to
http://localhost:5000/in your browser -
All application directories required by LARS will now be created on disk
-
The HF-Waitress server will automatically start and will download an LLM (Microsoft Phi-3-Mini-Instruct-44) on the first-run, which may take a while depending on your internet connection speed
-
On first-query, an embedding model (all-mpnet-base-v2) will be downloaded from HuggingFace Hub, which should take a brief time
-
On Windows:
-
Download Microsoft Visual Studio Build Tools 2022 from the Official Site - "Tools for Visual Studio"
-
NOTE: When installing the above, make sure to select the following components:
Desktop development with C++ # Then from the "Optional" category on the right, make sure to select the following: MSVC C++ x64/x86 build tools C++ CMake tools for Windows- Refer to the screenshot below:

- If you skipped selecting the above workloads when first installing the Visual Studio Build Tools, simply run the vs_buildTools.exe installer again, click "Modify" and ensure the
Desktop development with C++workload and theMSVC and C++ CMakeOptionals are selected as outlined above
-
-
On Linux (Ubuntu and Debian-based), install the following packages:
- build-essential includes GCC, G++, and make
- libffi-dev for Foreign Function Interface (FFI)
- libssl-dev for SSL support
sudo apt-get update sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake

-
Download from the Official Repo:
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp -
Install CMAKE on Windows from the Official Site
- add to PATH:
C:\Program Files\CMake\bin
- add to PATH:
-
Build llama.cpp with CMAKE:
-
Note: For faster compilation, add the -j argument to run multiple jobs in parallel. For example,
cmake --build build --config Release -j 8will run 8 jobs in parallel. -
Build with CUDA:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86" cmake --build build --config Release- Build without CUDA:
cmake -B build cmake --build build --config Release -
-
If you face issues when attempting to run
CMake -B build, check the extensive CMake Installation Troubleshooting steps below -
Add to PATH:
path_to_cloned_repo\llama.cpp\build\bin\Release -
Verify Installation via the terminal:
llama-server
-
Install Nvidia GPU Drivers
-
Install Nvidia CUDA Toolkit - LARS built and tested with v12.2 and v12.4
-
Verify Installation via the terminal:
nvcc -V nvidia-smi -
CMAKE-CUDA Fix (Very Important!):
Copy all the four files from the following directory:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2\extras\visual_studio_integration\MSBuildExtensionsand Paste them to the following directory:
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\MSBuild\Microsoft\VC\v170\BuildCustomizations
-
This is an optional, but highly recommended dependency - Only PDFs are supported if this setup is not completed
-
Windows:
-
Download from the Official Site
-
Add to PATH, either via:
-
Advanced System Settings -> Environment Variables -> System Variables -> EDIT PATH Variable -> Add the below (change as per your installation location):
C:\Program Files\LibreOffice\program -
Or via PowerShell:
Set PATH=%PATH%;C:\Program Files\LibreOffice\program
-
-
-
Ubuntu & Debian-based Linux - Download from the Official Site or install via terminal:
sudo apt-get update sudo apt-get install -y libreoffice -
Fedora and other RPM-based distros - Download from the Official Site or install via terminal:
sudo dnf update sudo dnf install libreoffice -
MacOS - Download from the Official Site or install via Homebrew:
brew install --cask libreoffice -
Verify Installation:
-
On Windows and MacOS: Run the LibreOffice application
-
On Linux via the terminal:
libreoffice --version
-
-
LARS utilizes the pdf2image Python library to convert each page of a document into an image as required for OCR. This library is essentially a wrapper around the Poppler utility which handles the conversion process.
-
Windows:
-
Download from the Official Repo
-
Add to PATH, either via:
-
Advanced System Settings -> Environment Variables -> System Variables -> EDIT PATH Variable -> Add the below (change as per your installation location):
path_to_installation\poppler_version\Library\bin -
Or via PowerShell:
Set PATH=%PATH%;path_to_installation\poppler_version\Library\bin
-
-
-
Linux:
sudo apt-get update sudo apt-get install -y poppler-utils wget
-
This is an optional dependency - Tesseract-OCR is not actively used in LARS but methods to use it are present in the source code
-
Windows:
-
Download Tesseract-OCR for Windows via UB-Mannheim
-
Add to PATH, either via:
-
Advanced System Settings -> Environment Variables -> System Variables -> EDIT PATH Variable -> Add the below (change as per your installation location):
C:\Program Files\Tesseract-OCR -
Or via PowerShell:
Set PATH=%PATH%;C:\Program Files\Tesseract-OCR
-
-
-
LARS has been built and tested with Python v3.11.x
-
Install Python v3.11.x on Windows:
-
Download v3.11.9 from the Official Site
-
During installation, ensure you check "Add Python 3.11 to PATH" or manually add it later, either via:
-
Advanced System Settings -> Environment Variables -> System Variables -> EDIT PATH Variable -> Add the below (change as per your installation location):
C:\Users\user_name\AppData\Local\Programs\Python\Python311\ -
Or via PowerShell:
Set PATH=%PATH%;C:\Users\user_name\AppData\Local\Programs\Python\Python311
-
-
-
Install Python v3.11.x on Linux (Ubuntu and Debian-based):
- via deadsnakes PPA:
sudo add-apt-repository ppa:deadsnakes/ppa -y sudo apt-get update sudo apt-get install -y python3.11 python3.11-venv python3.11-dev sudo python3.11 -m ensurepip -
Verify Installation via the terminal:
python3 --version -
If you encounter errors with
pip install, try the following:
-
Remove version numbers:
- If a specific package version causes an error, edit the corresponding requirements.txt file to remove the version constraint, that is the
==version.numbersegment, for example:
urllib3==2.0.4
becomes simply:
urllib3
- If a specific package version causes an error, edit the corresponding requirements.txt file to remove the version constraint, that is the
-
Create and use a Python virtual environment:
-
It's advisable to use a virtual environment to avoid conflicts with other Python projects
-
Windows:
-
Create a Python virtual environment (venv):
python -m venv larsenv -
Activate, and subsequently use, the venv:
.\larsenv\Scripts\activate -
Deactivate venv when done:
deactivate
-
-
Linux and MacOS:
-
Create a Python virtual environment (venv):
python3 -m venv larsenv -
Activate, and subsequently use, the venv:
source larsenv/bin/activate -
Deactivate venv when done:
deactivate
-
-
-
If problems persist, consider opening an issue on the LARS GitHub repository for support.
- If you encounter a
CMake nmake failederror when attempting to build llama.cpp such as below:

This typically indicates an issue with your Microsoft Visual Studio build tools, as CMake is unable to find the nmake tool, which is part of the Microsoft Visual Studio build tools. Try the below steps to resolve the issue:
-
Ensure Visual Studio Build Tools are Installed:
-
Make sure you have the Visual Studio build tools installed, including nmake. You can install these tools through the Visual Studio Installer by selecting the
Desktop development with C++workload, and theMSVC and C++ CMakeOptionals -
Check Step 0 of the Dependencies section, specifically the screenshot therein
-
-
Check Environment Variables:
- Ensure that the paths to the Visual Studio tools are included in your system's PATH environment variable. Typically, this includes paths like:
C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\Build C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\Common7\IDE C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\Common7\Tools -
Use Developer Command Prompt:
-
Open a "Developer Command Prompt for Visual Studio" which sets up the necessary environment variables for you
-
You can find this prompt from the Start menu under Visual Studio
-
-
Set CMake Generator:
- When running CMake, specify the generator explicitly to use NMake Makefiles. You can do this by adding the -G option:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON -
If problems persist, consider opening an issue on the LARS GitHub repository for support.
-
Eventually (after approximately 60 seconds) you'll see an alert on the page indicating an error:
Failed to start llama.cpp local-server -
This indicates that first-run has completed, all app directories have been created, but no LLMs are present in the
modelsdirectory and may now be moved to it -
Move your LLMs (any file format supported by llama.cpp, preferably GGUF) to the newly created
modelsdir, located by default in the following locations:- Windows:
C:/web_app_storage/models - Linux:
/app/storage/models - MacOS:
/app/models
- Windows:
-
Once you've placed your LLMs in the appropriate
modelsdir above, refreshhttp://localhost:5000/ -
You'll once again receive an error alert stating
Failed to start llama.cpp local-serverafter approximately 60 seconds -
This is because your LLM now needs to be selected in the LARS
Settingsmenu -
Accept the alert and click on the
Settingsgear icon in the top-right -
In the
LLM Selectiontab, select your LLM and the appropriate Prompt-Template format from the appropriate dropdowns -
Modify Advanced Settings to correctly set
GPUoptions, theContext-Length, and optionally, the token generation limit (Maximum tokens to predict) for your selected LLM -
Hit
Saveand if an automatic refresh is not triggered, manually refresh the page -
If all steps have been executed correctly, first-time setup is now complete, and LARS is ready for use
-
LARS will also remember your LLM settings for subsequent use
-
Document Formats Supported:
-
If LibreOffice is installed and added to PATH as detailed in Step 4 of the Dependencies section, the following formats are supported:
- PDFs
- Word files: doc, docx, odt, rtf, txt
- Excel files: xls, xlsx, ods, csv
- PowerPoint presentations: ppt, pptx, odp
- Image files: bmp, gif, jpg, png, svg, tiff
- Rich Text Format (RTF)
- HTML files
-
If LibreOffice is not setup, only PDFs are supported
-
-
OCR Options for Text Extraction:
-
LARS provides three methods for extracting text from documents, accommodating various document types and quality:
-
Local Text Extraction: Uses PyPDF2 for efficient text extraction from non-scanned PDFs. Ideal for quick processing when high accuracy is not critical, or entirely local processing is a necessity.
-
Azure ComputerVision OCR - Enhances text extraction accuracy and supports scanned documents. Useful for handling standard document layouts. Offers a free tier suitable for initial trials and low-volume use, capped at 5000 transactions/month at 20 transactions/minute.
-
Azure AI Document Intelligence OCR - Best for documents with complex structures like tables. A custom parser in LARS optimizes the extraction process.
-
NOTES:
-
Azure OCR options incur API-costs in most cases and are not bundled with LARS.
-
A limited free-tier for ComputerVision OCR is available as linked above. This service is cheaper overall but slower and may not work for non-standard document layouts (other than A4 etc).
-
Consider the document types and your accuracy needs when selecting an OCR option.
-
-
-
-
LLMs:
-
Only local-LLMs are presently supported
-
The
Settingsmenu provides many options for the power-user to configure and change the LLM via theLLM Selectiontab -
Note if using llama.cpp: Very-Important: Select the appropriate prompt-template format for the LLM you're running
-
LLMs trained for the following prompt-template formats are presently supported via llama.cpp:
- Meta Llama-3
- Meta Llama-2
- Mistral & Mixtral MoE LLMs
- Microsoft Phi-3
- OpenHermes-2.5-Mistral
- Nous-Capybara
- OpenChat-3.5
- Cohere Command-R and Command-R+
- DeepSeek Coder
-
-
Tweak Core-configuration settings via
Advanced Settings(triggers LLM-reload and page-refresh):- Number of layers offloaded to the GPU
- Context-size of the LLM
- Maximum number of tokens to be generated per response
-
Tweak settings to change response behavior at any time:
- Temperature – randomness of the response
- Top-p – Limit to a subset of tokens with a cumulative probability above
- Min-p – Minimum probability for considering a token, relative to most likely <min_p>
- Top-k – Limit to K most probable tokens
- N-keep – Prompt-tokens retained when context-size exceeded <n_keep> (-1 to retain all)
-
-
Embedding models and Vector Database:
-
Four embedding models are provided in LARS:
- sentence-transformers/all-mpnet-base-v2 (default)
- bge-base-en-v1.5
- bge-large-en-v1.5 (highest MTEB ranked model available in LARS)
- Azure-OpenAI Text-Ada (incurs API cost, not bundled with LARS)
-
With the exception of the Azure-OpenAI embeddings, all other models run entirely locally and for free. On first run, these models will be downloaded from the HuggingFace Hub. This is a one-time download and they'll subsequently be present locally.
-
The user may switch between these embedding models at any time via the
VectorDB & Embedding Modelstab in theSettingsmenu -
Docs-Loaded Table: In the
Settingsmenu, a table is displayed for the selected embedding model displaying the list of documents embedded to the associated vector-database. If a document is loaded multiple times, it’ll have multiple entries in this table, which could be useful for debugging any issues. -
Clearing the VectorDB: Use the
Resetbutton and provide confirmation to clear the selected vector database. This creates a new vectorDB on-disk for the selected embedding model. The old vectorDB is still preserved and may be reverted to by manually modifying the config.json file.
-
-
Edit System-Prompt:
-
The System-Prompt serves as an instruction to the LLM for the entire conversation
-
LARS provides the user with the ability to edit the System-Prompt via the
Settingsmenu by selecting theCustomoption from the dropdown in theSystem Prompttab -
Changes to the System-Prompt will start a new chat
-
-
Force Enable/Disable RAG:
-
Via the
Settingsmenu, the user may force enable or disable RAG (Retrieval Augmented Generation – the use of content from your documents to improve LLM-generated responses) whenever required -
This is often useful for the purposes of evaluating LLM responses in both scenarios
-
Force disabling will also turn off attribution features
-
The default setting, which uses NLP to determine when RAG should and shouldn’t be performed, is the recommended option
-
This setting can be changed at any time
-
-
Chat History:
-
Use the chat history menu on the top-left to browse and resume prior conversations
-
Very-Important: Be mindful of prompt-template mismatches when resuming prior conversations! Use the
Informationicon on the top-right to ensure the LLM used in the prior-conversation, and the LLM presently in use, are both based on the same prompt-template formats!
-
-
User rating:
-
Each response may be rated on a 5-point scale by the user at any time
-
Ratings data is stored in the
chat-history.dbSQLite3 database located in the app directory:- Windows:
C:/web_app_storage - Linux:
/app/storage - MacOS:
/app
- Windows:
-
Ratings data is very valuable for evaluation and refinement of the tool for your workflows
-
-
Dos and Don’ts:
- Do NOT tweak any settings or submit additional queries while a response to a query is already being generated! Wait for any ongoing response generation to complete.
-
If a chat goes awry, or any odd responses are generated, simply try starting a
New Chatvia the menu on the top-left -
Alternatively, start a new chat by simply refreshing the page
-
If issues are faced with citations or RAG performance, try resetting the vectorDB as described in Step 4 of the General User Guide above
-
If any application issues crop up and are not resolved simply by starting a new chat or restarting LARS, try deleting the config.json file by following the steps below:
- Shut-down the LARS app server by terminating the Python program with
CTRL+C - Backup and delete the
config.jsonfile located inLARS/web_app(same directory asapp.py)
- Shut-down the LARS app server by terminating the Python program with
-
For any severe data and citation issues that are not resolved even by resetting the VectorDB as described in Step 4 of the General User Guide above, perform the following steps:
- Shut-down the LARS app server by terminating the Python program with
CTRL+C - Backup and delete the entire app directory:
- Windows:
C:/web_app_storage - Linux:
/app/storage - MacOS:
/app
- Windows:
- Shut-down the LARS app server by terminating the Python program with
-
If problems persist, consider opening an issue on the LARS GitHub repository for support.
-
LARS has been adapted to a Docker container-deployment environment via two separate images as below:
-
Both have different requirements with the former being a simpler deployment, but suffering far slower inferencing performance due to the CPU and DDR memory acting as bottlenecks
-
While not explicitly required, some experience with Docker containers and familiarity with the concepts of containerization and virtualization will be very helpful in this section!
-
Beginning with common setup steps for both:
-
Installing Docker
-
Your CPU should support virtualization and it should be enabled in your system's BIOS/UEFI
-
Download and install Docker Desktop
-
If on Windows, you may need to install the Windows Subsystem for Linux if it's not already present. To do so, open PowerShell as an Administrator and run the following:
wsl --install -
Ensure Docker Desktop is up and running, then open a Command Prompt / Terminal and execute the following command to ensure Docker is correctly installed and up and running:
docker ps
-
-
Create a Docker storage volume, which will be attached to the LARS containers at runtime:
-
Creating a storage volume for use with the LARS container is highly advantageous as it'll allow you to upgrade the LARS container to a newer version, or switch between the CPU & GPU container variants while persisting all your settings, chat history and vector databases seamlessly.
-
Execute the following command in a Command Prompt / Terminal:
docker volume create lars_storage_volue -
This volume will be attached to the LARS container later at runtime, for now proceed to building the LARS image in the steps below.
-
-
-
In a Command Prompt / Terminal, execute the following commands:
git clone https://github.com/abgulati/LARS # skip if already done cd LARS # skip if already done cd dockerized docker build -t lars-no-gpu . # Once the build is complete, run the container: docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu -
Once done, Navigate to
http://localhost:5000/in your browser and follow the remainder of the First Run Steps and User Guide -
The Troubleshooting sections applies to Container-LARS as well
-
Requirements (in addition to Docker):
Compatible Nvidia GPU(s) Nvidia GPU drivers Nvidia CUDA Toolkit v12.2 -
For Linux, you're all set up with the above so skip the next step and head directly to the build and run steps further below
-
If on Windows, and if this is your first time running an Nvidia GPU container on Docker, strap in as this is going to be quite the ride (favorite beverage or three highly recommended!)
-
Risking extreme redundancy, before proceeding ensure the following dependencies are present:
Compatible Nvidia GPU(s) Nvidia GPU drivers Nvidia CUDA Toolkit v12.2 Docker Desktop Windows Subsystem for Linux (WSL) -
Refer to the Nvidia CUDA Dependencies section and the Docker Setup section above if unsure
-
If the above are present and setup, you're clear to proceed
-
Open the Microsoft Store app on your PC, and download & install Ubuntu 22.04.3 LTS (must match the version on line 2 in the dockerfile)
-
Yes you read the above right: download and install Ubuntu from the Microsoft store app, refer screenshot below:

-
It's now time to install the Nvidia Container Toolkit within Ubuntu, follow the steps below to do so:
-
Launch an Ubuntu shell in Windows by searching for
Ubuntuin the Start-menu after the installation above is completed -
In this Ubuntu command-line that opens, perform the following steps:
-
Configure the production repository:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list -
Update the packages list from the repository & Install the Nvidia Container Toolkit Packages:
sudo apt-get update && apt-get install -y nvidia-container-toolkit -
Configure the container runtime by using the nvidia-ctk command, which modifies the /etc/docker/daemon.json file so that Docker can use the Nvidia Container Runtime:
sudo nvidia-ctk runtime configure --runtime=docker -
Restart the Docker daemon:
sudo systemctl restart docker
-
-
Now your Ubuntu setup is complete, time to complete the WSL and Docker Integrations:
-
Open a new PowerShell window and set this Ubuntu installation as the WSL default:
wsl --list wsl --set-default Ubuntu-22.04 # if not already marked as Default -
Navigate to
Docker Desktop -> Settings -> Resources -> WSL Integration-> Check Default & Ubuntu 22.04 integrations. Refer to the screenshot below:

-
-
Now if everything has been done correctly, you're ready to build and run the container!
-
-
In a Command Prompt / Terminal, execute the following commands:
git clone https://github.com/abgulati/LARS # skip if already done cd LARS # skip if already done cd dockerized_nvidia_cuda_gpu docker build -t lars-nvcuda . # Once the build is complete, run the container: docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda -
Once done, Navigate to
http://localhost:5000/in your browser and follow the remainder of the First Run Steps and User Guide -
The Troubleshooting sections applies to Container-LARS as well


-
In case you encounter Network-related errors, especially pertaining to unavailable package repositories when building the container, this is a networking issue at your end often pertaining to Firewall issues
-
On Windows, navigate to
Control Panel\System and Security\Windows Defender Firewall\Allowed apps, or searchFirewallin the Start-Menu and head toAllow an app through the firewalland ensure ```Docker Desktop Backend`` is allowed through -
The first time you run LARS, the sentence-transformers embedding model will be downloaded
-
In the containerized environment, this download can sometimes be problematic and result in errors when you ask a query
-
If this occurs, simply head to the LARS Settings menu:
Settings->VectorDB & Embedding Modelsand change the Embedding Model to either BGE-Base or BGE-Large, this will force a reload and redownload -
Once done, proceed to ask questions again and the response should generate as normal
-
You can switch back to the sentence-transformers embedding model and the issue should be resolved
-
As stated in the Troubleshooting section above, embedding models are downloaded the first time LARS runs
-
It's best to save the state of the container before shutting it down so this download step need-not be repeated every subsequent time the container is launched
-
To do so, open another Command Prompt / Terminal and commit changes BEFORE shutting the running LARS container:
docker ps # note the container_id here docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr -
This will create an updated image that you can use on subsequent runs:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr -
NOTE: Having done the above, if you check the space used by images with
docker images, you'll notice a lot of space used. BUT, don’t take the sizes here literally! The size shown for each image includes the total size of all its layers, but many of those layers are shared between images, especially if those images are based on the same base image or if one image is a committed version of another. To see how much disk space your Docker images are actually using, use:docker system df
| Category | Tasks | Status |
|---|---|---|
| Bug fixes: | Zero-Byte text-file creation hazard - Sometimes if OCR/Text-Extraction of the input document fails, a 0B .txt file may be left over which causes further retry attempts to believe the file has already been loaded | 📆 Future Task |
| Practical Features: | Ease-of-use centric: | |
| Azure CV-OCR free-tier UI toggle | ✅ Done on 8th June 2024 | |
| Delete Chats | 📆 Future Task | |
| Rename Chats | 📆 Future Task | |
| PowerShell Installation Script | 📆 Future Task | |
| Linux Installation Script | 📆 Future Task | |
| Ollama LLM-inferencing backend as an alternative to llama.cpp | 📆 Future Task | |
| Integration of OCR services from other cloud providers (GCP, AWS, OCI, etc.) | 📆 Future Task | |
| UI toggle to ignore prior text-extracts when uploading a document | 📆 Future Task | |
| Modal-popup for file uploads: mirror text-extraction options from settings, global over-write on submissions, toggle to persist settings | 📆 Future Task | |
| Performance-centric: | ||
| Nvidia TensorRT-LLM AWQ Support | 📆 Future Task | |
| Research Tasks: | Investigate Nvidia TensorRT-LLM: Necessitates building AWQ-LLM TRT-engines specific to the target GPU, NvTensorRT-LLM is its own ecosystem and only works on Python v3.10. | ✅ Done on 13th June 2024 |
| Local OCR with Vision LLMs: MS-TrOCR (done), Kosmos-2.5 (high Priority), Llava, Florence-2 | 👷 In-Progress 5th July 2024 Update | |
| RAG Improvements: Re-ranker, RAPTOR, T-RAG | 📆 Future Task | |
| Investigate GraphDB integration: using LLMs to extract entity-relationship data from documents and populate, update & maintain a GraphDB | 📆 Future Task |
I hope that LARS has been valuable in your work, and I invite you to support its ongoing development! If you appreciate the tool and would like to contribute to its future enhancements, consider making a donation. Your support helps me to continue improving LARS and adding new features.
How to Donate To make a donation, please use the following link to my PayPal:
Your contributions are greatly appreciated and will be used to fund further development efforts.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LARS
Similar Open Source Tools
LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
LlamaEdge
The LlamaEdge project makes it easy to run LLM inference apps and create OpenAI-compatible API services for the Llama2 series of LLMs locally. It provides a Rust+Wasm stack for fast, portable, and secure LLM inference on heterogeneous edge devices. The project includes source code for text generation, chatbot, and API server applications, supporting all LLMs based on the llama2 framework in the GGUF format. LlamaEdge is committed to continuously testing and validating new open-source models and offers a list of supported models with download links and startup commands. It is cross-platform, supporting various OSes, CPUs, and GPUs, and provides troubleshooting tips for common errors.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
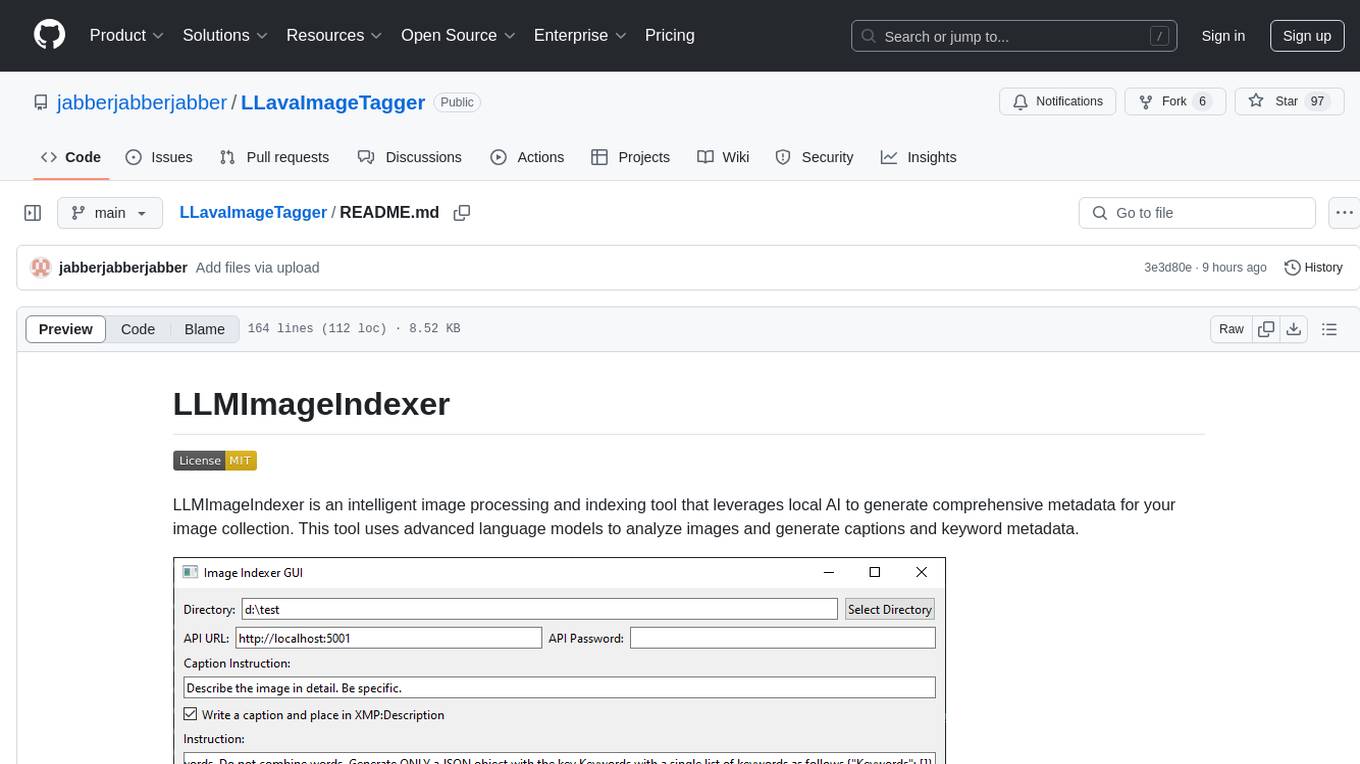
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
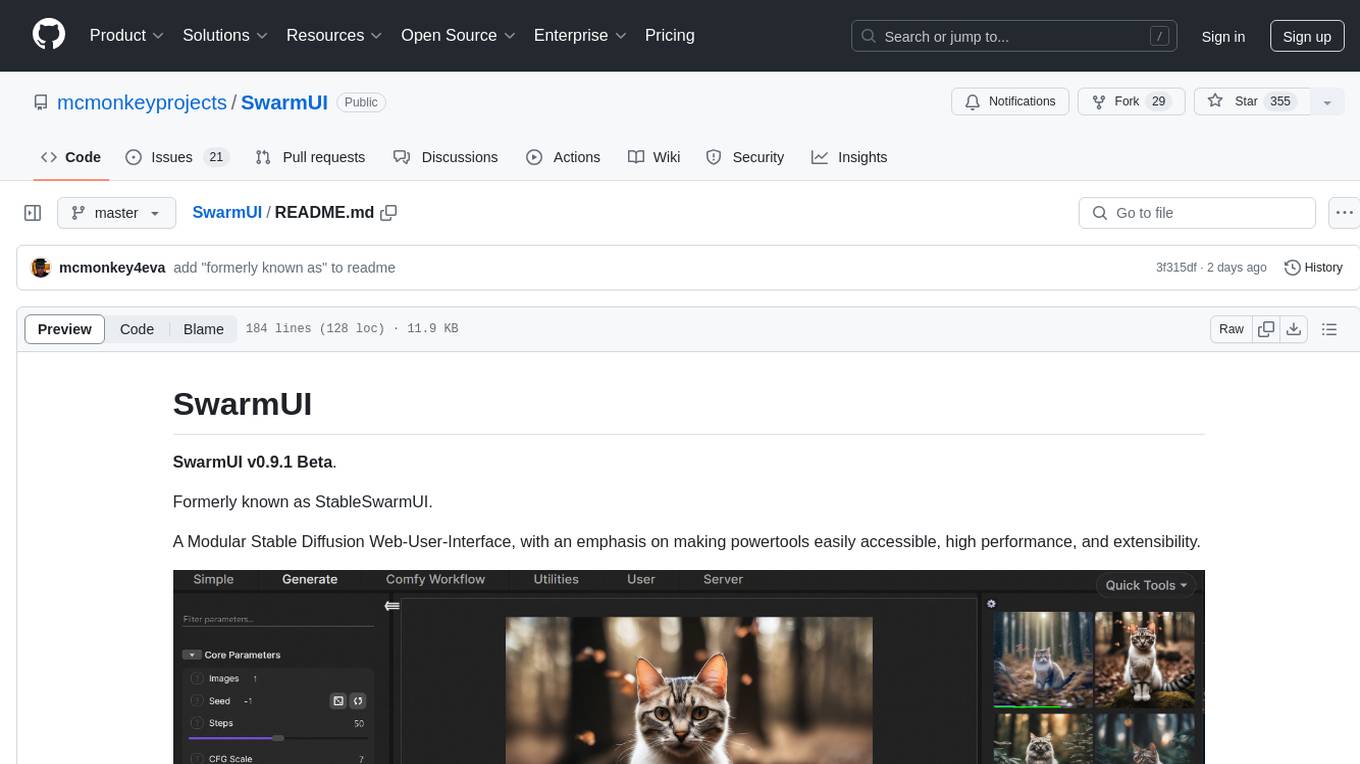
SwarmUI
SwarmUI is a modular stable diffusion web-user-interface designed to make powertools easily accessible, high performance, and extensible. It is in Beta status, offering a primary Generate tab for beginners and a Comfy Workflow tab for advanced users. The tool aims to become a full-featured one-stop-shop for all things Stable Diffusion, with plans for better mobile browser support, detailed 'Current Model' display, dynamic tab shifting, LLM-assisted prompting, and convenient direct distribution as an Electron app.
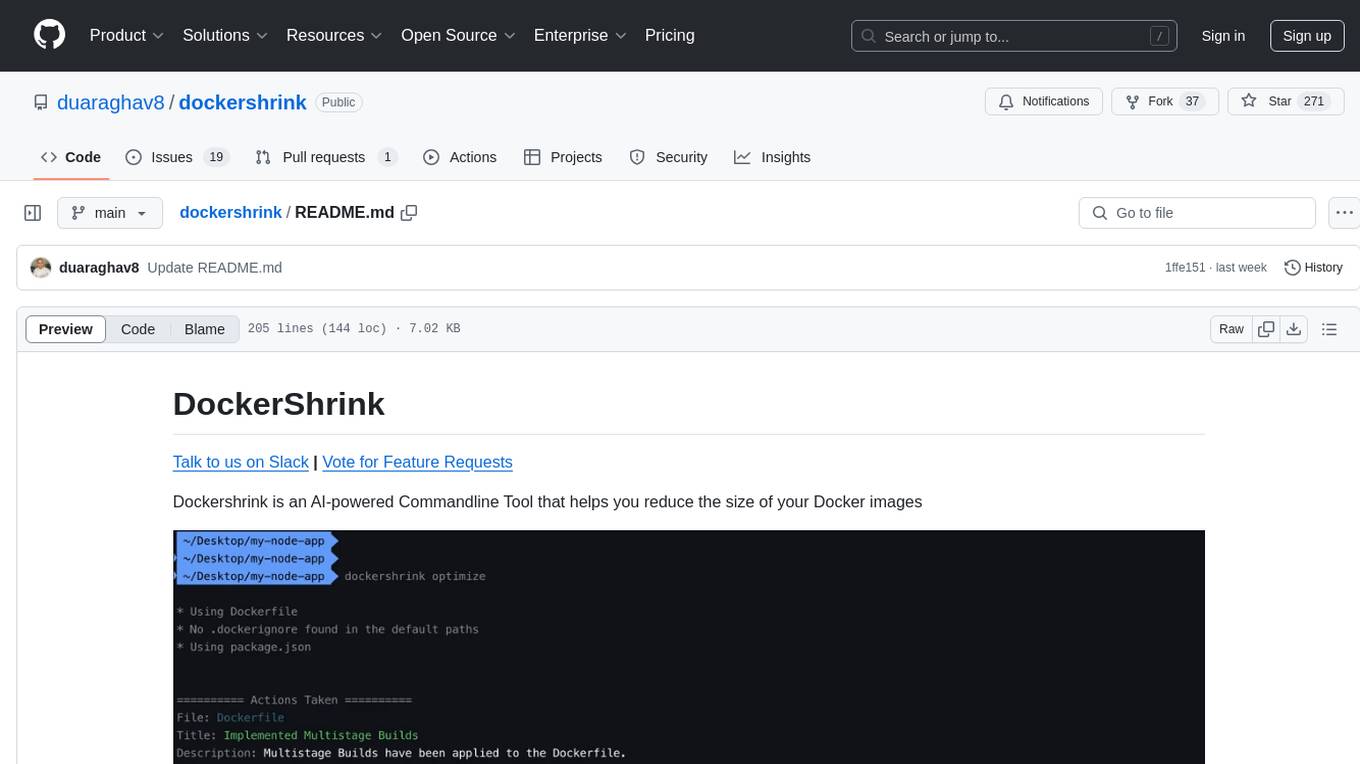
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
just-chat
Just-Chat is a containerized application that allows users to easily set up and chat with their AI agent. Users can customize their AI assistant using a YAML file, add new capabilities with Python tools, and interact with the agent through a chat web interface. The tool supports various modern models like DeepSeek Reasoner, ChatGPT, LLAMA3.3, etc. Users can also use semantic search capabilities with MeiliSearch to find and reference relevant information based on meaning. Just-Chat requires Docker or Podman for operation and provides detailed installation instructions for both Linux and Windows users.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.

aider-composer
Aider Composer is a VSCode extension that integrates Aider into your development workflow. It allows users to easily add and remove files, toggle between read-only and editable modes, review code changes, use different chat modes, and reference files in the chat. The extension supports multiple models, code generation, code snippets, and settings customization. It has limitations such as lack of support for multiple workspaces, Git repository features, linting, testing, voice features, in-chat commands, and configuration options.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.
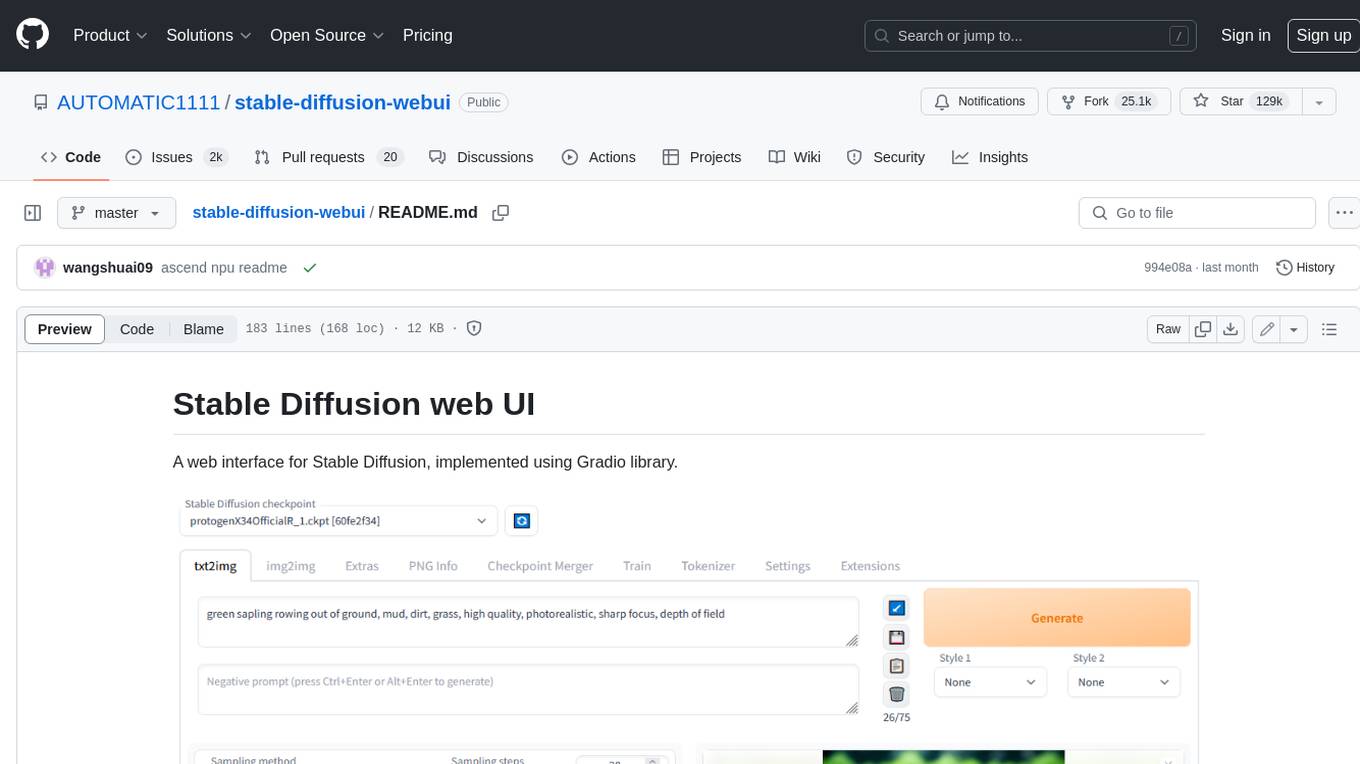
stable-diffusion-webui
Stable Diffusion web UI is a web interface for Stable Diffusion, implemented using Gradio library. It provides a user-friendly interface to access the powerful image generation capabilities of Stable Diffusion. With Stable Diffusion web UI, users can easily generate images from text prompts, edit and refine images using inpainting and outpainting, and explore different artistic styles and techniques. The web UI also includes a range of advanced features such as textual inversion, hypernetworks, and embeddings, allowing users to customize and fine-tune the image generation process. Whether you're an artist, designer, or simply curious about the possibilities of AI-generated art, Stable Diffusion web UI is a valuable tool that empowers you to create stunning and unique images.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.
TypeGPT
TypeGPT is a Python application that enables users to interact with ChatGPT or Google Gemini from any text field in their operating system using keyboard shortcuts. It provides global accessibility, keyboard shortcuts for communication, and clipboard integration for larger text inputs. Users need to have Python 3.x installed along with specific packages and API keys from OpenAI for ChatGPT access. The tool allows users to run the program normally or in the background, manage processes, and stop the program. Users can use keyboard shortcuts like `/ask`, `/see`, `/stop`, `/chatgpt`, `/gemini`, `/check`, and `Shift + Cmd + Enter` to interact with the application in any text field. Customization options are available by modifying files like `keys.txt` and `system_prompt.txt`. Contributions are welcome, and future plans include adding support for other APIs and a user-friendly GUI.
For similar tasks

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
searchGPT
searchGPT is an open-source project that aims to build a search engine based on Large Language Model (LLM) technology to provide natural language answers. It supports web search with real-time results, file content search, and semantic search from sources like the Internet. The tool integrates LLM technologies such as OpenAI and GooseAI, and offers an easy-to-use frontend user interface. The project is designed to provide grounded answers by referencing real-time factual information, addressing the limitations of LLM's training data. Contributions, especially from frontend developers, are welcome under the MIT License.
LLMs-at-DoD
This repository contains tutorials for using Large Language Models (LLMs) in the U.S. Department of Defense. The tutorials utilize open-source frameworks and LLMs, allowing users to run them in their own cloud environments. The repository is maintained by the Defense Digital Service and welcomes contributions from users.
LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.