
EAGLE
Eagle Family: Exploring Model Designs, Data Recipes and Training Strategies for Frontier-Class Multimodal LLMs
Stars: 646

Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
README:
[📜 Eagle2 Paper] [📜 Eagle1 Paper] [🤗 HF Models] [🗨️ Demo]
We are thrilled to release our latest Eagle2 series Vision-Language Model. Open-source Vision-Language Models (VLMs) have made significant strides in narrowing the gap with proprietary models. However, critical details about data strategies and implementation are often missing, limiting reproducibility and innovation. In this project, we focus on VLM post-training from a data-centric perspective, sharing insights into building effective data strategies from scratch. By combining these strategies with robust training recipes and model design, we introduce Eagle2, a family of performant VLMs. Our work aims to empower the open-source community to develop competitive VLMs with transparent processes.

- [2025/01] 🔥 Release Eagle-2 (WIP)
- [2025/01] 🔥 Eagle-1 is accepted by ICLR 2025.
- [2024/08] Release Eagle-1.
We provide the following models:
| model name | LLM | Vision | Max Length | HF Link |
|---|---|---|---|---|
| Eagle2-1B | Qwen2.5-0.5B-Instruct | Siglip | 16K | 🤗 link |
| Eagle2-2B | Qwen2.5-1.5B-Instruct | Siglip | 16K | 🤗 link |
| Eagle2-9B | Qwen2.5-7B-Instruct | Siglip+ConvNext | 16K | 🤗 link |
Eagle2-1B Results
| Benchmark | LLaVa-One-Vision-0.5B | InternVL2-1B | InternVL2.5-1B | Qwen2-VL-2B | Eagle2-1B |
|---|---|---|---|---|---|
| DocVQAtest | 70.0 | 81.7 | 84.8 | 90.1 | 81.8 |
| ChartQAtest | 61.4 | 72.9 | 75.9 | 73.0 | 77.0 |
| InfoVQAtest | 41.8 | 50.9 | 56.0 | 65.5 | 54.8 |
| TextVQAval | - | 70.0 | 72.0 | 79.7 | 76.6 |
| OCRBench | 565 | 754 | 785 | 809 | 767 |
| MMEsum | 1438.0 | 1794.4 | 1950.5 | 1872.0 | 1790.2 |
| RealWorldQA | 55.6 | 50.3 | 57.5 | 62.6 | 55.4 |
| AI2Dtest | 57.1 | 64.1 | 69.3 | 74.7 | 70.9 |
| MMMUval | 31.4 | 36.7 | 40.9 | 41.1 | 38.8 |
| MMVetGPT-4-Turbo | 32.2 | 32.7 | 48.8 | 49.5 | 40.9 |
| MathVistatestmini | 33.8 | 37.7 | 43.2 | 43.0 | 45.3 |
| MMstar | 37.7 | 45.7 | 50.1 | 48.0 | 48.5 |
Eagle2-2B Results
| Benchmark | InternVL2-2B | InternVL2.5-2B | InternVL2-4B | Qwen2-VL-2B | Eagle2-2B |
|---|---|---|---|---|---|
| DocVQAtest | 86.9 | 88.7 | 89.2 | 90.1 | 88.0 |
| ChartQAtest | 76.2 | 79.2 | 81.5 | 73.0 | 82.0 |
| InfoVQAtest | 58.9 | 60.9 | 67.0 | 65.5 | 65.8 |
| TextVQAval | 73.4 | 74.3 | 74.4 | 79.7 | 79.1 |
| OCRBench | 784 | 804 | 788 | 809 | 818 |
| MMEsum | 1876.8 | 2138.2 | 2059.8 | 1872.0 | 2109.8 |
| RealWorldQA | 57.3 | 60.1 | 60.7 | 62.6 | 63.1 |
| AI2Dtest | 74.1 | 74.9 | 74.7 | 78.9 | 79.3 |
| MMMUval | 36.3 | 43.6 | 47.9 | 41.1 | 43.1 |
| MMVetGPT-4-Turbo | 39.5 | 60.8 | 51.0 | 49.5 | 53.8 |
| HallBenchavg | 37.9 | 42.6 | 41.9 | 41.7 | 45.8 |
| MathVistatestmini | 46.3 | 51.3 | 58.6 | 43.0 | 54.7 |
| MMstar | 50.1 | 53.7 | 54.3 | 48.0 | 56.4 |
| Benchmark | MiniCPM-Llama3-V-2_5 | InternVL-Chat-V1-5 | InternVL2-8B | QwenVL2-7B | Eagle2-9B |
|---|---|---|---|---|---|
| Model Size | 8.5B | 25.5B | 8.1B | 8.3B | 8.9B |
| DocVQAtest | 84.8 | 90.9 | 91.6 | 94.5 | 92.6 |
| ChartQAtest | - | 83.8 | 83.3 | 83.0 | 86.4 |
| InfoVQAtest | - | 72.5 | 74.8 | 74.3 | 77.2 |
| TextVQAval | 76.6 | 80.6 | 77.4 | 84.3 | 83.0 |
| OCRBench | 725 | 724 | 794 | 845 | 868 |
| MMEsum | 2024.6 | 2187.8 | 2210.3 | 2326.8 | 2260 |
| RealWorldQA | 63.5 | 66.0 | 64.4 | 70.1 | 69.3 |
| AI2Dtest | 78.4 | 80.7 | 83.8 | - | 83.9 |
| MMMUval | 45.8 | 45.2 / 46.8 | 49.3 / 51.8 | 54.1 | 56.1 |
| MMBench_V11test | 79.5 | 79.4 | 80.6 | ||
| MMVetGPT-4-Turbo | 52.8 | 55.4 | 54.2 | 62.0 | 62.2 |
| SEED-Image | 72.3 | 76.0 | 76.2 | 77.1 | |
| HallBenchavg | 42.4 | 49.3 | 45.2 | 50.6 | 49.3 |
| MathVistatestmini | 54.3 | 53.5 | 58.3 | 58.2 | 63.8 |
| MMstar | - | - | 60.9 | 60.7 | 62.6 |
We provide a local chat demo powered by Streamlit to help users get started with Eagle2 quickly and easily.
This demo is built upon InternVL's template and extends it with additional video input support for enhanced functionality.
We provide a inference script to help you quickly start using the model. We support different input types:
- pure text input
- single image input
- multiple image input
- video input
pip install transformers==4.37.2
pip install flash-attnNote: Latest version of transformers is not compatible with the model.
Click to expand
"""
A model worker executes the model.
Copied and modified from https://github.com/OpenGVLab/InternVL/blob/main/streamlit_demo/model_worker.py
"""
# Importing torch before transformers can cause `segmentation fault`
from transformers import AutoModel, AutoTokenizer, TextIteratorStreamer, AutoConfig
import argparse
import base64
import json
import os
import decord
import threading
import time
from io import BytesIO
from threading import Thread
import math
import requests
import torch
import torchvision.transforms as T
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
import numpy as np
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
SIGLIP_MEAN = (0.5, 0.5, 0.5)
SIGLIP_STD = (0.5, 0.5, 0.5)
def get_seq_frames(total_num_frames, desired_num_frames=-1, stride=-1):
"""
Calculate the indices of frames to extract from a video.
Parameters:
total_num_frames (int): Total number of frames in the video.
desired_num_frames (int): Desired number of frames to extract.
Returns:
list: List of indices of frames to extract.
"""
assert desired_num_frames > 0 or stride > 0 and not (desired_num_frames > 0 and stride > 0)
if stride > 0:
return list(range(0, total_num_frames, stride))
# Calculate the size of each segment from which a frame will be extracted
seg_size = float(total_num_frames - 1) / desired_num_frames
seq = []
for i in range(desired_num_frames):
# Calculate the start and end indices of each segment
start = int(np.round(seg_size * i))
end = int(np.round(seg_size * (i + 1)))
# Append the middle index of the segment to the list
seq.append((start + end) // 2)
return seq
def build_video_prompt(meta_list, num_frames, time_position=False):
# if time_position is True, the frame_timestamp is used.
# 1. pass time_position, 2. use env TIME_POSITION
time_position = os.environ.get("TIME_POSITION", time_position)
prefix = f"This is a video:\n"
for i in range(num_frames):
if time_position:
frame_txt = f"Frame {i+1} sampled at {meta_list[i]:.2f} seconds: <image>\n"
else:
frame_txt = f"Frame {i+1}: <image>\n"
prefix += frame_txt
return prefix
def load_video(video_path, num_frames=64, frame_cache_root=None):
if isinstance(video_path, str):
video = decord.VideoReader(video_path)
elif isinstance(video_path, dict):
assert False, 'we not support vidoe: "video_path" as input'
fps = video.get_avg_fps()
sampled_frames = get_seq_frames(len(video), num_frames)
samepld_timestamps = [i / fps for i in sampled_frames]
frames = video.get_batch(sampled_frames).asnumpy()
images = [Image.fromarray(frame) for frame in frames]
return images, build_video_prompt(samepld_timestamps, len(images), time_position=True)
def load_image(image):
if isinstance(image, str) and os.path.exists(image):
return Image.open(image)
elif isinstance(image, dict):
if 'disk_path' in image:
return Image.open(image['disk_path'])
elif 'base64' in image:
return Image.open(BytesIO(base64.b64decode(image['base64'])))
elif 'url' in image:
response = requests.get(image['url'])
return Image.open(BytesIO(response.content))
elif 'bytes' in image:
return Image.open(BytesIO(image['bytes']))
else:
raise ValueError(f'Invalid image: {image}')
else:
raise ValueError(f'Invalid image: {image}')
def build_transform(input_size, norm_type='imagenet'):
if norm_type == 'imagenet':
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
elif norm_type == 'siglip':
MEAN, STD = SIGLIP_MEAN, SIGLIP_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
"""
previous version mainly foucs on ratio.
We also consider area ratio here.
"""
best_factor = float('-inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
area_ratio = (ratio[0]*ratio[1]*image_size*image_size)/ area
"""
new area > 60% of original image area is enough.
"""
factor_based_on_area_n_ratio = min((ratio[0]*ratio[1]*image_size*image_size)/ area, 0.6)* \
min(target_aspect_ratio/aspect_ratio, aspect_ratio/target_aspect_ratio)
if factor_based_on_area_n_ratio > best_factor:
best_factor = factor_based_on_area_n_ratio
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def split_model(model_path, device):
device_map = {}
world_size = torch.cuda.device_count()
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
num_layers = config.llm_config.num_hidden_layers
print('world_size', world_size)
num_layers_per_gpu_ = math.floor(num_layers / (world_size - 1))
num_layers_per_gpu = [num_layers_per_gpu_] * world_size
num_layers_per_gpu[device] = num_layers - num_layers_per_gpu_ * (world_size-1)
print(num_layers_per_gpu)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = device
device_map['mlp1'] = device
device_map['language_model.model.tok_embeddings'] = device
device_map['language_model.model.embed_tokens'] = device
device_map['language_model.output'] = device
device_map['language_model.model.norm'] = device
device_map['language_model.lm_head'] = device
device_map['language_model.model.rotary_emb'] = device
device_map[f'language_model.model.layers.{num_layers - 1}'] = device
return device_map
class ModelWorker:
def __init__(self, model_path, model_name,
load_8bit, device):
if model_path.endswith('/'):
model_path = model_path[:-1]
if model_name is None:
model_paths = model_path.split('/')
if model_paths[-1].startswith('checkpoint-'):
self.model_name = model_paths[-2] + '_' + model_paths[-1]
else:
self.model_name = model_paths[-1]
else:
self.model_name = model_name
print(f'Loading the model {self.model_name}')
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
tokens_to_keep = ['<box>', '</box>', '<ref>', '</ref>']
tokenizer.additional_special_tokens = [item for item in tokenizer.additional_special_tokens if item not in tokens_to_keep]
self.tokenizer = tokenizer
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
model_type = config.vision_config.model_type
self.device = torch.cuda.current_device()
if model_type == 'siglip_vision_model':
self.norm_type = 'siglip'
elif model_type == 'MOB':
self.norm_type = 'siglip'
else:
self.norm_type = 'imagenet'
if any(x in model_path.lower() for x in ['34b']):
device_map = split_model(model_path, self.device)
else:
device_map = None
if device_map is not None:
self.model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
device_map=device_map,
trust_remote_code=True,
load_in_8bit=load_8bit).eval()
else:
self.model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16,
trust_remote_code=True,
load_in_8bit=load_8bit).eval()
if not load_8bit and device_map is None:
self.model = self.model.to(device)
self.load_8bit = load_8bit
self.model_path = model_path
self.image_size = self.model.config.force_image_size
self.context_len = tokenizer.model_max_length
self.per_tile_len = 256
def reload_model(self):
del self.model
torch.cuda.empty_cache()
if self.device == 'auto':
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# This can make distributed deployment work properly
self.model = AutoModel.from_pretrained(
self.model_path,
load_in_8bit=self.load_8bit,
torch_dtype=torch.bfloat16,
device_map=self.device_map,
trust_remote_code=True).eval()
else:
self.model = AutoModel.from_pretrained(
self.model_path,
load_in_8bit=self.load_8bit,
torch_dtype=torch.bfloat16,
trust_remote_code=True).eval()
if not self.load_8bit and not self.device == 'auto':
self.model = self.model.cuda()
@torch.inference_mode()
def generate(self, params):
system_message = params['prompt'][0]['content']
send_messages = params['prompt'][1:]
max_input_tiles = params['max_input_tiles']
temperature = params['temperature']
top_p = params['top_p']
max_new_tokens = params['max_new_tokens']
repetition_penalty = params['repetition_penalty']
video_frame_num = params.get('video_frame_num', 64)
do_sample = True if temperature > 0.0 else False
global_image_cnt = 0
history, pil_images, max_input_tile_list = [], [], []
for message in send_messages:
if message['role'] == 'user':
prefix = ''
if 'image' in message:
for image_data in message['image']:
pil_images.append(load_image(image_data))
prefix = prefix + f'<image {global_image_cnt + 1}><image>\n'
global_image_cnt += 1
max_input_tile_list.append(max_input_tiles)
if 'video' in message:
for video_data in message['video']:
video_frames, tmp_prefix = load_video(video_data, num_frames=video_frame_num)
pil_images.extend(video_frames)
prefix = prefix + tmp_prefix
global_image_cnt += len(video_frames)
max_input_tile_list.extend([1] * len(video_frames))
content = prefix + message['content']
history.append([content, ])
else:
history[-1].append(message['content'])
question, history = history[-1][0], history[:-1]
if global_image_cnt == 1:
question = question.replace('<image 1><image>\n', '<image>\n')
history = [[item[0].replace('<image 1><image>\n', '<image>\n'), item[1]] for item in history]
try:
assert len(max_input_tile_list) == len(pil_images), 'The number of max_input_tile_list and pil_images should be the same.'
except Exception as e:
from IPython import embed; embed()
exit()
print(f'Error: {e}')
print(f'max_input_tile_list: {max_input_tile_list}, pil_images: {pil_images}')
# raise e
old_system_message = self.model.system_message
self.model.system_message = system_message
transform = build_transform(input_size=self.image_size, norm_type=self.norm_type)
if len(pil_images) > 0:
max_input_tiles_limited_by_contect = params['max_input_tiles']
while True:
image_tiles = []
for current_max_input_tiles, pil_image in zip(max_input_tile_list, pil_images):
if self.model.config.dynamic_image_size:
tiles = dynamic_preprocess(
pil_image, image_size=self.image_size, max_num=min(current_max_input_tiles, max_input_tiles_limited_by_contect),
use_thumbnail=self.model.config.use_thumbnail)
else:
tiles = [pil_image]
image_tiles += tiles
if (len(image_tiles) * self.per_tile_len < self.context_len):
break
else:
max_input_tiles_limited_by_contect -= 2
if max_input_tiles_limited_by_contect < 1:
break
pixel_values = [transform(item) for item in image_tiles]
pixel_values = torch.stack(pixel_values).to(self.model.device, dtype=torch.bfloat16)
print(f'Split images to {pixel_values.shape}')
else:
pixel_values = None
generation_config = dict(
num_beams=1,
max_new_tokens=max_new_tokens,
do_sample=do_sample,
temperature=temperature,
repetition_penalty=repetition_penalty,
max_length=self.context_len,
top_p=top_p,
)
response = self.model.chat(
tokenizer=self.tokenizer,
pixel_values=pixel_values,
question=question,
history=history,
return_history=False,
generation_config=generation_config,
)
self.model.system_message = old_system_message
return {'text': response, 'error_code': 0}
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model-path', type=str, default='nvidia/Eagle2-1B')
parser.add_argument('--model-name', type=str, default='Eagle2-1B')
parser.add_argument('--device', type=str, default='cuda')
parser.add_argument('--load-8bit', action='store_true')
args = parser.parse_args()
print(f'args: {args}')
worker = ModelWorker(
args.model_path,
args.model_name,
args.load_8bit,
args.device)- Single image input
prompt = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Describe this image in details.',
'image':[
{'url': 'https://www.nvidia.com/content/dam/en-zz/Solutions/about-nvidia/logo-and-brand/[email protected]'}
],
}
]- Multiple image input
prompt = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Describe these two images in details.',
'image':[
{'url': 'https://www.nvidia.com/content/dam/en-zz/Solutions/about-nvidia/logo-and-brand/[email protected]'},
{'url': 'https://www.nvidia.com/content/dam/en-zz/Solutions/about-nvidia/logo-and-brand/[email protected]'}
],
}
]- Video input
prompt = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{'role': 'user', 'content': 'Describe this video in details.',
'video':[
'path/to/your/video.mp4'
],
}
]params = {
'prompt': prompt,
'max_input_tiles': 24,
'temperature': 0.7,
'top_p': 1.0,
'max_new_tokens': 4096,
'repetition_penalty': 1.0,
}
worker.generate(params)We evaluate the performance of Eagle2 based on VLMEvalKit. We temporarily provide a custom vlmeval implementation that supports Eagle2 in our repo, and we will support Eagle2 in the official version as soon as possible.
- [ ] Support vLLM Inference
- [ ] Provide AWQ Quantization Weights
- [ ] Provide fine-tuning scripts
If you find this project useful, please cite our work:
@misc{li2025eagle2buildingposttraining,
title={Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models},
author={Zhiqi Li and Guo Chen and Shilong Liu and Shihao Wang and Vibashan VS and Yishen Ji and Shiyi Lan and Hao Zhang and Yilin Zhao and Subhashree Radhakrishnan and Nadine Chang and Karan Sapra and Amala Sanjay Deshmukh and Tuomas Rintamaki and Matthieu Le and Ilia Karmanov and Lukas Voegtle and Philipp Fischer and De-An Huang and Timo Roman and Tong Lu and Jose M. Alvarez and Bryan Catanzaro and Jan Kautz and Andrew Tao and Guilin Liu and Zhiding Yu},
year={2025},
eprint={2501.14818},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.14818},
}
@article{shi2024eagle,
title = {Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders},
author={Min Shi and Fuxiao Liu and Shihao Wang and Shijia Liao and Subhashree Radhakrishnan and De-An Huang and Hongxu Yin and Karan Sapra and Yaser Yacoob and Humphrey Shi and Bryan Catanzaro and Andrew Tao and Jan Kautz and Zhiding Yu and Guilin Liu},
journal={arXiv:2408.15998},
year={2024}
}
- The code is released under the Apache 2.0 license as found in the LICENSE file.
- The pretrained model weights are released under the Creative Commons Attribution: Non-Commercial 4.0 International
- The service is a research preview intended for non-commercial use only, and is subject to the following licenses and terms:
- Model License of Qwen2.5-7B-Instruct: Apache-2.0
- Model License of LLama: Llama community license
- Model License of PaliGemma: Gemma license
- Furthermore, users are reminded to ensure that their use of the dataset and checkpoints is in compliance with all applicable laws and regulations.
-
InternVL: we built the codebase based on InternVL. Thanks for the great open-source project.
-
VLMEvalKit: We use vlmeval for evaluation. Many thanks for their wonderful tools.
-
Thanks to Cambrian, LLaVA-One-Vision and more great work for their efforts in organizing open-source data.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EAGLE
Similar Open Source Tools
EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.

nncase
nncase is a neural network compiler for AI accelerators that supports multiple inputs and outputs, static memory allocation, operators fusion and optimizations, float and quantized uint8 inference, post quantization from float model with calibration dataset, and flat model with zero copy loading. It can be installed via pip and supports TFLite, Caffe, and ONNX ops. Users can compile nncase from source using Ninja or make. The tool is suitable for tasks like image classification, object detection, image segmentation, pose estimation, and more.
AnyCrawl
AnyCrawl is a high-performance crawling and scraping toolkit designed for SERP crawling, web scraping, site crawling, and batch tasks. It offers multi-threading and multi-process capabilities for high performance. The tool also provides AI extraction for structured data extraction from pages, making it LLM-friendly and easy to integrate and use.
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.

llm4s
llm4s is an experimental Scala 3 bindings tool for llama.cpp using Slinc. It provides version compatibility with Scala 3.3.0 and JDK 17, 19 for llama.cpp. Users can utilize llm4s to work with llama.cpp shared library and model, enabling completion and embeddings functionalities in Scala.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.
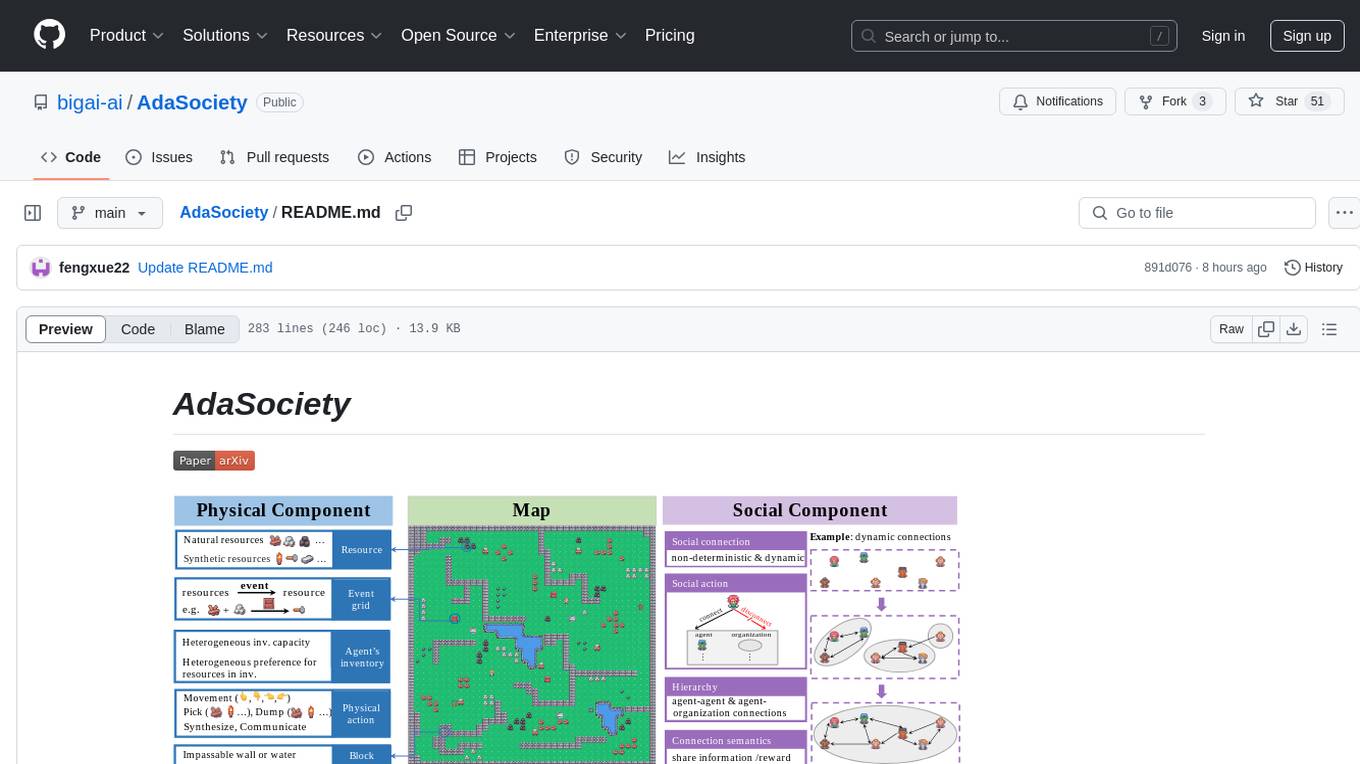
AdaSociety
AdaSociety is a multi-agent environment designed for simulating social structures and decision-making processes. It offers built-in resources, events, and player interactions. Users can customize the environment through JSON configuration or custom Python code. The environment supports training agents using RLlib and LLM frameworks. It provides a platform for studying multi-agent systems and social dynamics.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.
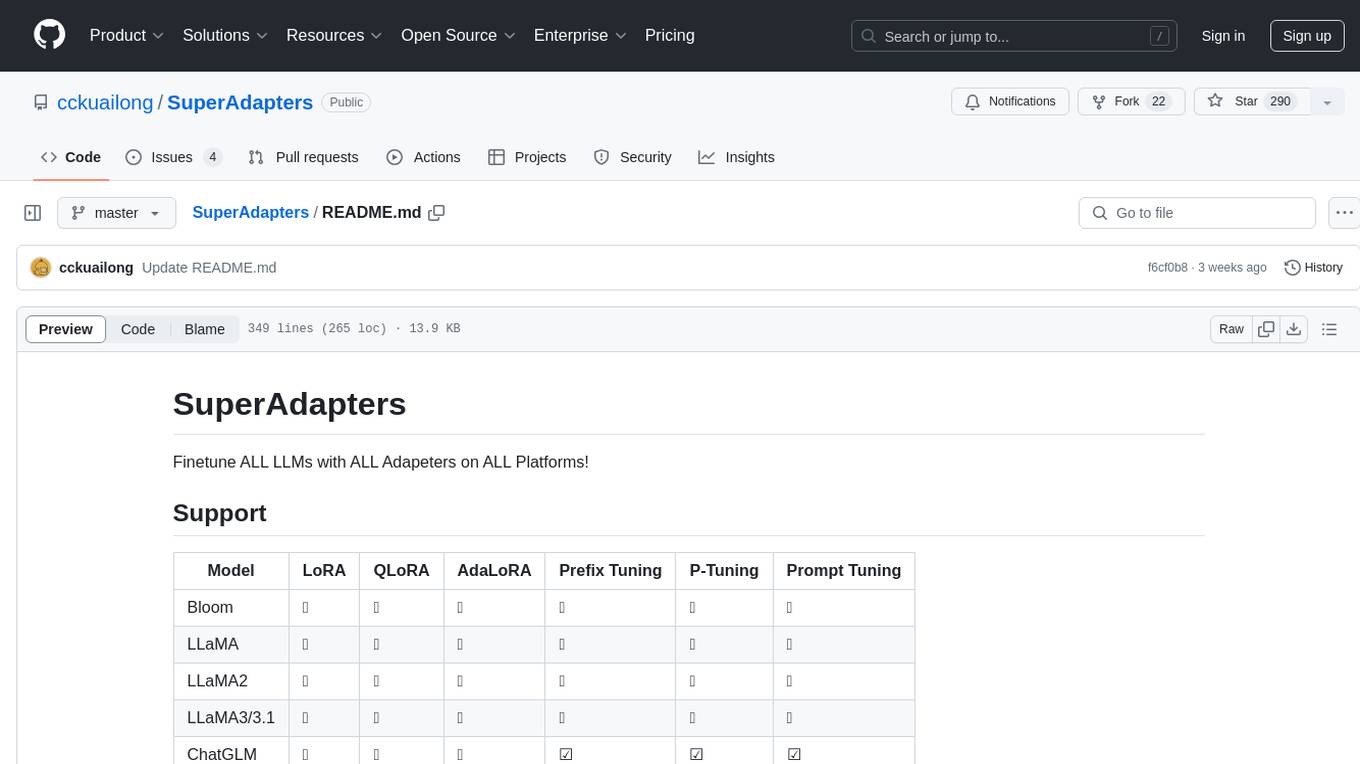
SuperAdapters
SuperAdapters is a tool designed to finetune Large Language Models (LLMs) with various adapters on different platforms. It supports models like Bloom, LLaMA, ChatGLM, Qwen, Baichuan, Mixtral, Phi, and more. Users can finetune LLMs on Windows, Linux, and Mac M1/2, handle train/test data with Terminal, File, or DataBase, and perform tasks like CausalLM and SequenceClassification. The tool provides detailed instructions on how to use different models with specific adapters for tasks like finetuning and inference. It also includes requirements for CentOS, Ubuntu, and MacOS, along with information on LLM downloads and data formats. Additionally, it offers parameters for finetuning and inference, as well as options for web and API-based inference.
PraisonAI
Praison AI is a low-code, centralised framework that simplifies the creation and orchestration of multi-agent systems for various LLM applications. It emphasizes ease of use, customization, and human-agent interaction. The tool leverages AutoGen and CrewAI frameworks to facilitate the development of AI-generated scripts and movie concepts. Users can easily create, run, test, and deploy agents for scriptwriting and movie concept development. Praison AI also provides options for full automatic mode and integration with OpenAI models for enhanced AI capabilities.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.
Conduit
Conduit is a unified Swift 6.2 SDK for local and cloud LLM inference, providing a single Swift-native API that can target Anthropic, OpenRouter, Ollama, MLX, HuggingFace, and Apple’s Foundation Models without rewriting your prompt pipeline. It allows switching between local, cloud, and system providers with minimal code changes, supports downloading models from HuggingFace Hub for local MLX inference, generates Swift types directly from LLM responses, offers privacy-first options for on-device running, and is built with Swift 6.2 concurrency features like actors, Sendable types, and AsyncSequence.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.
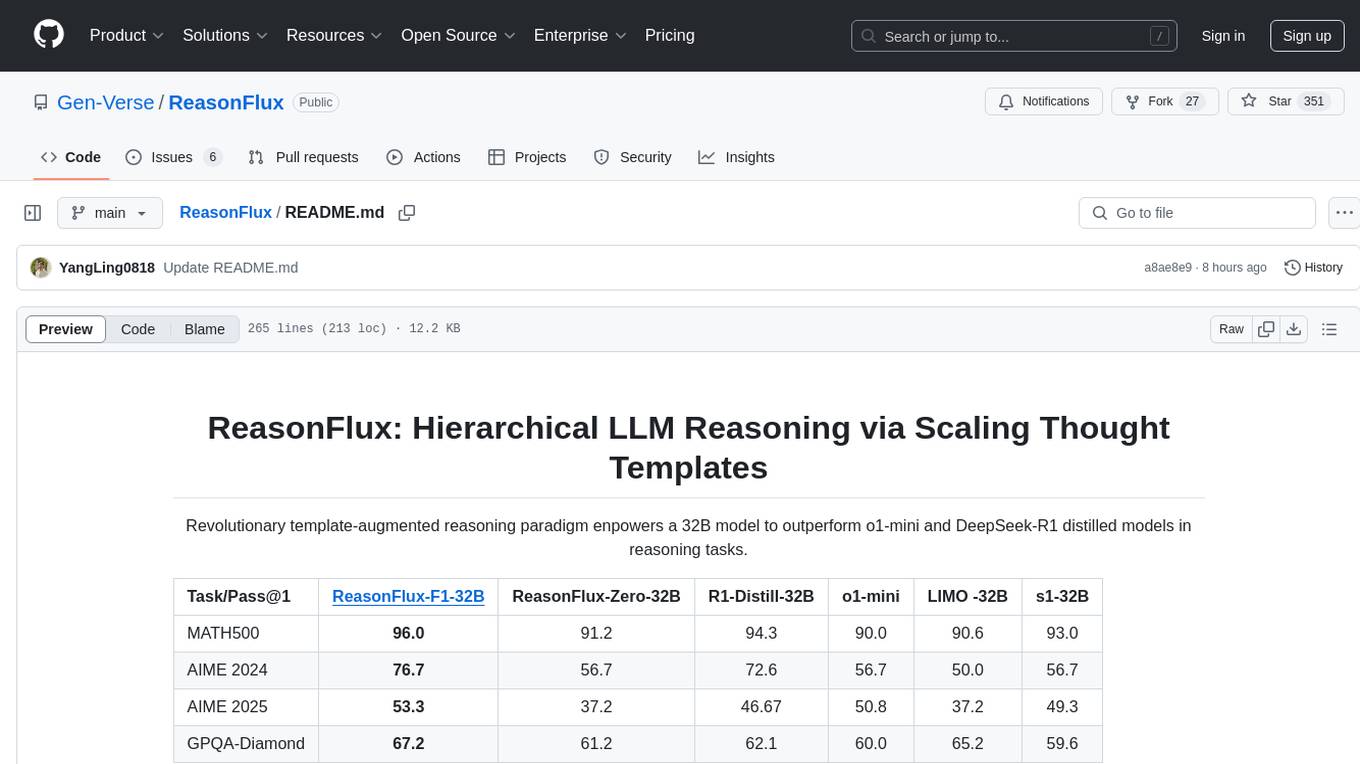
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
ryoma
Ryoma is an AI Powered Data Agent framework that offers a comprehensive solution for data analysis, engineering, and visualization. It leverages cutting-edge technologies like Langchain, Reflex, Apache Arrow, Jupyter Ai Magics, Amundsen, Ibis, and Feast to provide seamless integration of language models, build interactive web applications, handle in-memory data efficiently, work with AI models, and manage machine learning features in production. Ryoma also supports various data sources like Snowflake, Sqlite, BigQuery, Postgres, MySQL, and different engines like Apache Spark and Apache Flink. The tool enables users to connect to databases, run SQL queries, and interact with data and AI models through a user-friendly UI called Ryoma Lab.
For similar tasks

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
searchGPT
searchGPT is an open-source project that aims to build a search engine based on Large Language Model (LLM) technology to provide natural language answers. It supports web search with real-time results, file content search, and semantic search from sources like the Internet. The tool integrates LLM technologies such as OpenAI and GooseAI, and offers an easy-to-use frontend user interface. The project is designed to provide grounded answers by referencing real-time factual information, addressing the limitations of LLM's training data. Contributions, especially from frontend developers, are welcome under the MIT License.
LLMs-at-DoD
This repository contains tutorials for using Large Language Models (LLMs) in the U.S. Department of Defense. The tutorials utilize open-source frameworks and LLMs, allowing users to run them in their own cloud environments. The repository is maintained by the Defense Digital Service and welcomes contributions from users.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.