
Q-Bench
①[ICLR2024 Spotlight] (GPT-4V/Gemini-Pro/Qwen-VL-Plus+16 OS MLLMs) A benchmark for multi-modality LLMs (MLLMs) on low-level vision and visual quality assessment.
Stars: 224

Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.
README:

How do multi-modaility LLMs perform on low-level computer vision?

The proposed Q-Bench includes three realms for low-level vision: perception (A1), description (A2), and assessment (A3).
- For perception (A1) /description (A2), we collect two benchmark datasets LLVisionQA/LLDescribe.
- We are open to submission-based evaluation for the two tasks. The details for submission is as follows.
- For assessment (A3), as we use public datasets, we provide an abstract evaluation code for arbitrary MLLMs for anyone to test.
For the Q-Bench-A1 (with multi-choice questions), we have converted them into HF-format datasets that can automatically be downloaded and used with datasets API. Please refer to the following instruction:
pip install datasetsfrom datasets import load_dataset
ds = load_dataset("q-future/Q-Bench-HF")
print(ds["dev"][0])
### {'id': 0,
### 'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=4160x3120>,
### 'question': 'How is the lighting of this building?',
### 'option0': 'High',
### 'option1': 'Low',
### 'option2': 'Medium',
### 'option3': 'N/A',
### 'question_type': 2,
### 'question_concern': 3,
### 'correct_choice': 'B'}from datasets import load_dataset
ds = load_dataset("q-future/Q-Bench2-HF")
print(ds["dev"][0])
### {'id': 0,
### 'image1': <PIL.Image.Image image mode=RGB size=4032x3024>,
### 'image2': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=864x1152>,
### 'question': 'Compared to the first image, how is the clarity of the second image?',
### 'option0': 'More blurry',
### 'option1': 'Clearer',
### 'option2': 'About the same',
### 'option3': 'N/A',
### 'question_type': 2,
### 'question_concern': 0,
### 'correct_choice': 'B'}- [2024/8/8]🔥 The low-level vision compare task part of Q-bench+(also referred as Q-Bench2) has just been accepted by TPAMI! Come and test your MLLM with Q-bench+_Dataset.
- [2024/8/1]🔥 The Q-Bench is released on VLMEvalKit, come and test your LMM with one command like `python run.py --data Q-Bench1_VAL Q-Bench1_TEST --model InternVL2-1B --verbose'.
- [2024/6/17]🔥 The Q-Bench, Q-Bench2(Q-bench+), and A-Bench have now joined lmms-eval, which makes it easier to test LMM !!
- [2024/6/3] 🔥 Github repo for A-Bench is online. Do you want to find out if your LMM is a master at evaluating AI-generated images? Come and test on A-Bench !!
- [3/1] 🔥 We are releasing Co-instruct, Towards Open-ended Visual Quality Comparison here. More details are coming soon.
- [2/27] 🔥 Our work Q-Insturct has been accepted by CVPR 2024, try to learn the details about how to instruct MLLMs on low-level vision!
- [2/23] 🔥 The low-level vision compare task part of Q-bench+ is now released at Q-bench+(Dataset)!
- [2/10] 🔥 We are releasing the extended Q-bench+, which challenges MLLMs with both single images and image pairs on low-level vision. The LeaderBoard is onsite, check out the low-level vision ability for your favorite MLLMs!! More details coming soon.
- [1/16] 🔥 Our work "Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision" is accepted by ICLR2024 as Spotlight Presentation.

We test on three close-source API models, GPT-4V-Turbo (gpt-4-vision-preview, replacing the no-longer-available old version GPT-4V results), Gemini Pro (gemini-pro-vision) and Qwen-VL-Plus (qwen-vl-plus). Slightly improved compared with the older version, GPT-4V still tops among all MLLMs and almost a junior-level human's performance. Gemini Pro and Qwen-VL-Plus follows behind, still better than best open-source MLLMs (0.65 overall).
Update on [2024/7/18], We are glad to release the new SOTA performance of BlueImage-GPT (close-source).
Perception, A1-Single
| Participant Name | yes-or-no | what | how | distortion | others | in-context distortion | in-context others | overall |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus (qwen-vl-plus) |
0.7574 | 0.7325 | 0.5733 | 0.6488 | 0.7324 | 0.6867 | 0.7056 | 0.6893 |
BlueImage-GPT (from VIVO New Champion) |
0.8467 | 0.8351 | 0.7469 | 0.7819 | 0.8594 | 0.7995 | 0.8240 | 0.8107 |
Gemini-Pro (gemini-pro-vision) |
0.7221 | 0.7300 | 0.6645 | 0.6530 | 0.7291 | 0.7082 | 0.7665 | 0.7058 |
GPT-4V-Turbo (gpt-4-vision-preview) |
0.7722 | 0.7839 | 0.6645 | 0.7101 | 0.7107 | 0.7936 | 0.7891 | 0.7410 |
| GPT-4V (old version) | 0.7792 | 0.7918 | 0.6268 | 0.7058 | 0.7303 | 0.7466 | 0.7795 | 0.7336 |
| human-1-junior | 0.8248 | 0.7939 | 0.6029 | 0.7562 | 0.7208 | 0.7637 | 0.7300 | 0.7431 |
| human-2-senior | 0.8431 | 0.8894 | 0.7202 | 0.7965 | 0.7947 | 0.8390 | 0.8707 | 0.8174 |
Perception, A1-Pair
| Participant Name | yes-or-no | what | how | distortion | others | compare | joint | overall |
|---|---|---|---|---|---|---|---|---|
Qwen-VL-Plus (qwen-vl-plus) |
0.6685 | 0.5579 | 0.5991 | 0.6246 | 0.5877 | 0.6217 | 0.5920 | 0.6148 |
Qwen-VL-Max (qwen-vl-max) |
0.6765 | 0.6756 | 0.6535 | 0.6909 | 0.6118 | 0.6865 | 0.6129 | 0.6699 |
BlueImage-GPT (from VIVO New Champion) |
0.8843 | 0.8033 | 0.7958 | 0.8464 | 0.8062 | 0.8462 | 0.7955 | 0.8348 |
Gemini-Pro (gemini-pro-vision) |
0.6578 | 0.5661 | 0.5674 | 0.6042 | 0.6055 | 0.6046 | 0.6044 | 0.6046 |
GPT-4V (gpt-4-vision) |
0.7975 | 0.6949 | 0.8442 | 0.7732 | 0.7993 | 0.8100 | 0.6800 | 0.7807 |
| Junior-level Human | 0.7811 | 0.7704 | 0.8233 | 0.7817 | 0.7722 | 0.8026 | 0.7639 | 0.8012 |
| Senior-level Human | 0.8300 | 0.8481 | 0.8985 | 0.8313 | 0.9078 | 0.8655 | 0.8225 | 0.8548 |
We have also evaluated several new open-source models recently, and will release their results soon.
We now provide two ways to download the datasets (LLVisionQA&LLDescribe)
-
via GitHub Release: Please see our release for details.
-
via Huggingface Datasets: Please refer to the data release notes to download the images.
It is highly recommended to convert your model into Huggingface format to smoothly test these data. See the example scripts for Huggingface's IDEFICS-9B-Instruct as an example, and modify them for your custom model to test on your model.
Please email [email protected] to submit your result in json format.
You can also submit your model (could be Huggingface AutoModel or ModelScope AutoModel) to us, alongside your custom evaluation scripts. Your custom scripts can be modified from the template scripts that works for LLaVA-v1.5 (for A1/A2), and here (for image quality assessment).
Please email [email protected] to submit your model if you are outside China Mainland.
Please email [email protected] to submit your model if you are inside China Mainland.
A snapshot for LLVisionQA benchmark dataset for MLLM low-level perception ability is as follows. See the leaderboard here.

We measure the answer accuracy of MLLMs (provided with the question and all choices) as the metric here.
A snapshot for LLDescribe benchmark dataset for MLLM low-level description ability is as follows. See the leaderboard here.

We measure the completeness, precision, and relevance of MLLM descriptions as the metric here.
An exciting ability that MLLMs are able to predict quantitative scores for IQA!

Similarly as above, as long as a model (based on causal language models) has the following two methods: embed_image_and_text (to allow multi-modality inputs), and forward (for computing logits), the Image Quality Assessment (IQA) with the model can be achieved as follows:
from PIL import Image
from my_mllm_model import Model, Tokenizer, embed_image_and_text
model, tokenizer = Model(), Tokenizer()
prompt = "##User: Rate the quality of the image.\n" \
"##Assistant: The quality of the image is" ### This line can be modified based on MLLM's default behaviour.
good_idx, poor_idx = tokenizer(["good","poor"]).tolist()
image = Image.open("image_for_iqa.jpg")
input_embeds = embed_image_and_text(image, prompt)
output_logits = model(input_embeds=input_embeds).logits[0,-1]
q_pred = (output_logits[[good_idx, poor_idx]] / 100).softmax(0)[0]*Note that you can modify the second line based on your model's default format, e.g. for Shikra, the "##Assistant: The quality of the image is" is modified as "##Assistant: The answer is". It is okay if your MLLM will first answer "Ok, I would like to help! The image quality is", just replace this into line 2 of the prompt.
We further provide a full implementation of IDEFICS on IQA. See example on how to run IQA with this MLLM. Other MLLMs can also be modified in the same way for use in IQA.
We have prepared JSON format human opinion scores (MOS) for the seven IQA databases as evaluated in our benchmark.
Please see IQA_databases for details.
Moved to leaderboards. Please click to see details.
Please contact any of the first authors of this paper for queries.
- Haoning Wu,
[email protected], @teowu - Zicheng Zhang,
[email protected], @zzc-1998 - Erli Zhang,
[email protected], @ZhangErliCarl
If you find our work interesting, please feel free to cite our paper:
@inproceedings{wu2024qbench,
author = {Wu, Haoning and Zhang, Zicheng and Zhang, Erli and Chen, Chaofeng and Liao, Liang and Wang, Annan and Li, Chunyi and Sun, Wenxiu and Yan, Qiong and Zhai, Guangtao and Lin, Weisi},
title = {Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision},
booktitle = {ICLR},
year = {2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Q-Bench
Similar Open Source Tools
Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
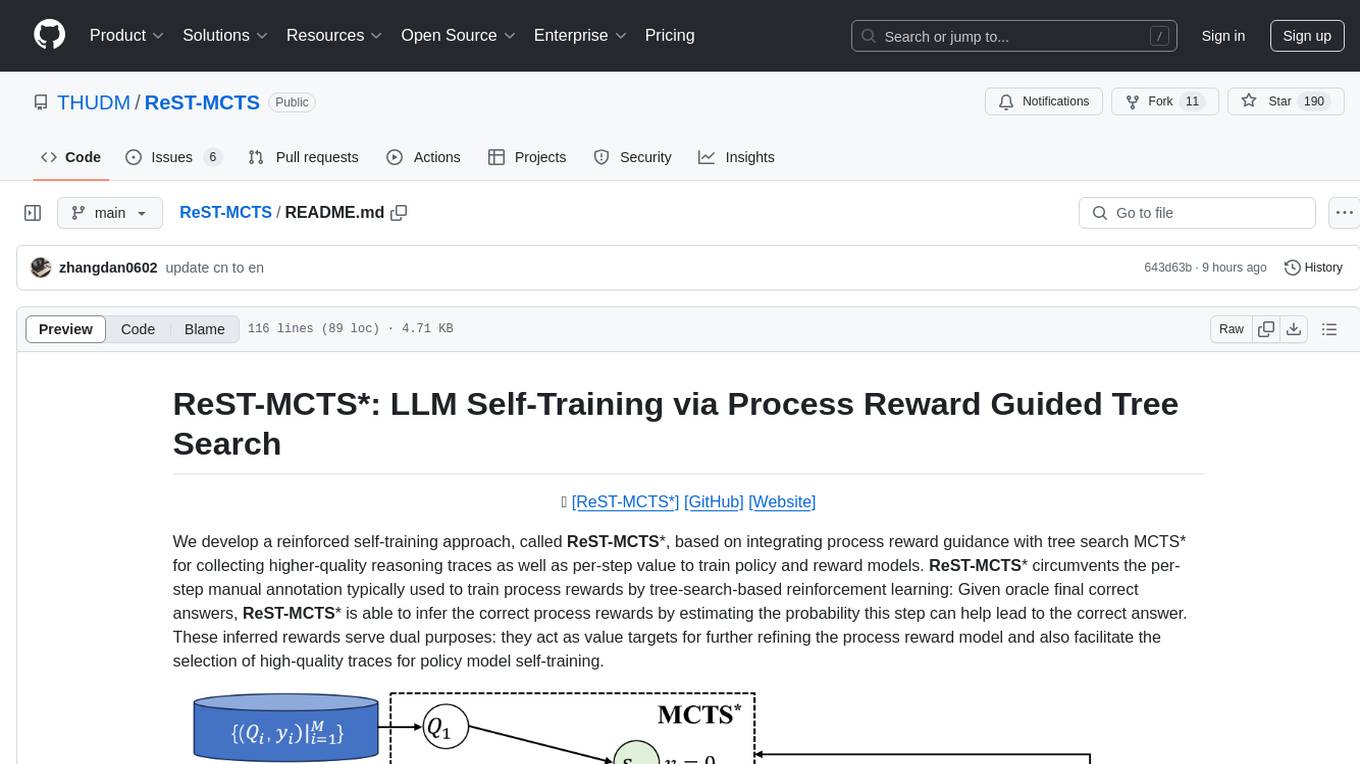
ReST-MCTS
ReST-MCTS is a reinforced self-training approach that integrates process reward guidance with tree search MCTS to collect higher-quality reasoning traces and per-step value for training policy and reward models. It eliminates the need for manual per-step annotation by estimating the probability of steps leading to correct answers. The inferred rewards refine the process reward model and aid in selecting high-quality traces for policy model self-training.
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.
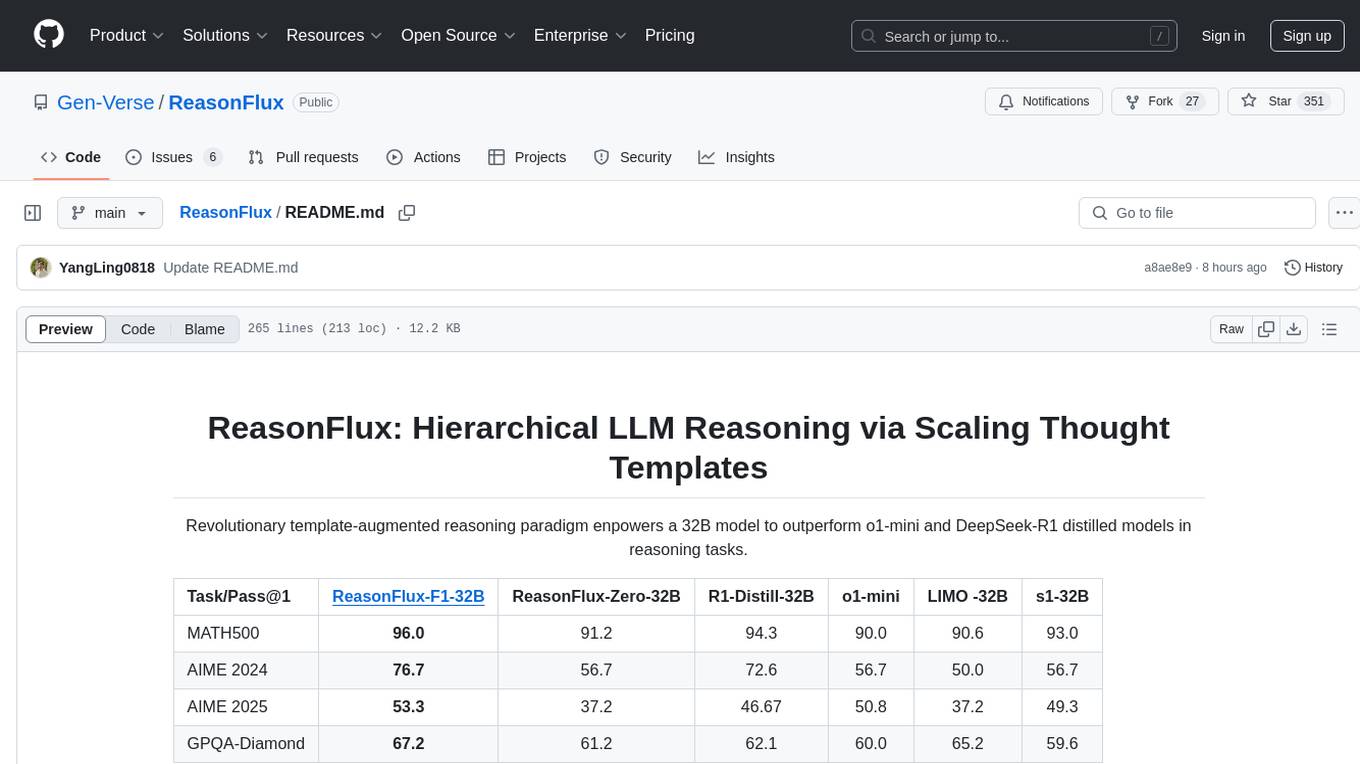
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
terminator
Terminator is an AI-powered desktop automation tool that is open source, MIT-licensed, and cross-platform. It works across all apps and browsers, inspired by GitHub Actions & Playwright. It is 100x faster than generic AI agents, with over 95% success rate and no vendor lock-in. Users can create automations that work across any desktop app or browser, achieve high success rates without costly consultant armies, and pre-train workflows as deterministic code.
Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
hia
HIA (Health Insights Agent) is an AI agent designed to analyze blood reports and provide personalized health insights. It features an intelligent agent-based architecture with multi-model cascade system, in-context learning, PDF upload and text extraction, secure user authentication, session history tracking, and a modern UI. The tech stack includes Streamlit for frontend, Groq for AI integration, Supabase for database, PDFPlumber for PDF processing, and Supabase Auth for authentication. The project structure includes components for authentication, UI, configuration, services, agents, and utilities. Contributions are welcome, and the project is licensed under MIT.

OpenGateLLM
OpenGateLLM is an open-source API gateway developed by the French Government, designed to serve AI models in production. It follows OpenAI standards and offers robust features like RAG integration, audio transcription, OCR, and more. With support for multiple AI backends and built-in security, OpenGateLLM provides a production-ready solution for various AI tasks.
For similar tasks
Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.
LLMs-Planning
This repository contains code for three papers related to evaluating large language models on planning and reasoning about change. It includes benchmarking tools and analysis for assessing the planning abilities of large language models. The latest addition evaluates and enhances the planning and scheduling capabilities of a specific language reasoning model. The repository provides a static test set leaderboard showcasing model performance on various tasks with natural language and planning domain prompts.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.