
ReasonFlux
ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates
Stars: 367
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
README:
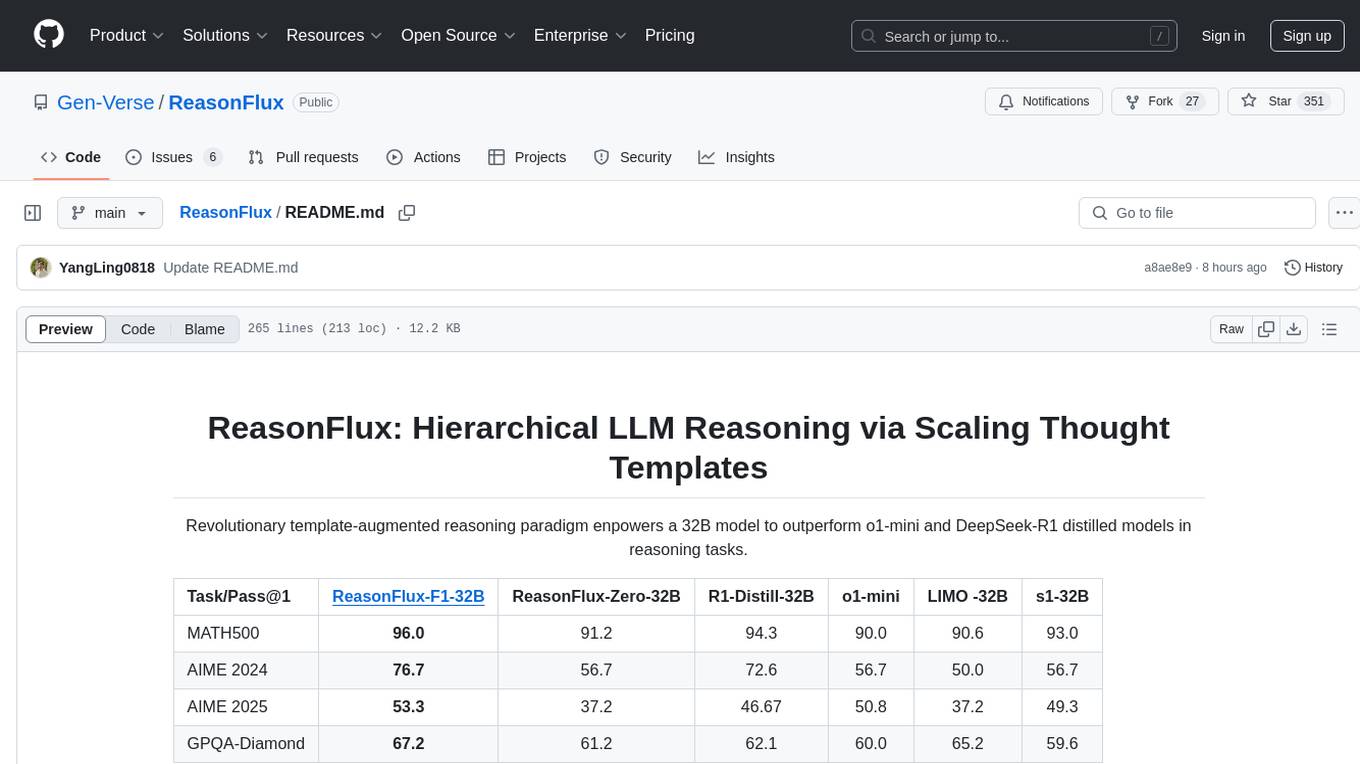
Revolutionary template-augmented reasoning paradigm enpowers a 32B model to outperform o1-mini and DeepSeek-R1 distilled models in reasoning tasks.
| Task/Pass@1 | ReasonFlux-F1-32B | ReasonFlux-Zero-32B | R1-Distill-32B | o1-mini | LIMO -32B | s1-32B |
|---|---|---|---|---|---|---|
| MATH500 | 96.0 | 91.2 | 94.3 | 90.0 | 90.6 | 93.0 |
| AIME 2024 | 76.7 | 56.7 | 72.6 | 56.7 | 50.0 | 56.7 |
| AIME 2025 | 53.3 | 37.2 | 46.67 | 50.8 | 37.2 | 49.3 |
| GPQA-Diamond | 67.2 | 61.2 | 62.1 | 60.0 | 65.2 | 59.6 |
This repository provides official resources for the paper "ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates". Try our latest released model ReasonFlux-F1-32B.

- Updates
- Dataset Links
- Model Zoo
- Getting Started
- Performance
- Reasoning Example
- Preliminary Work
- Citation
- [2025/3/24] 🎉We release ReasonFlux-F1-32B, ReasonFlux-F1-14B, ReasonFlux-F1-7B, a series of SOTA-level reasoning LLMs by leveraging the template-augmented reasoning trajectories collected from our ReasonFlux-Zero. For the training and evaluation scripts, please refer to reasonflux-f1/README.md for detail.

- [2025/2/11] 🎉We release the data, training scripts for SFT stage and demo inference code along with template library of ReasonFlux-Zero.
| Model | Download |
|---|---|
| ReasonFlux-F1-32B | 🤗 HuggingFace |
| ReasonFlux-F1-14B | 🤗 HuggingFace |
| ReasonFlux-F1-7B | 🤗 HuggingFace |
conda create -n ReasonFlux python==3.9
conda activate ReasonFlux
pip install -r requirements.txtTraining ReasonFlux-F1
To train ReasonFlux-F1, you should follow the steps below (also refer to ./reasonflux-f1/README.md):
-
Step 1: Add the data path to the
file_name field of the ReasonFlux-F1 entry in
LLaMA-Factory/data/dataset_info.json.
Step 2: Run the following command to train ReasonFlux-F1-32B:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--preprocessing_num_workers 16 \
--finetuning_type full \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset ReasonFlux-F1 \
--cutoff_len 16384 \
--learning_rate 1e-05 \
--num_train_epochs 5.0 \
--max_samples 100000 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/DeepSeek-R1-Distill-Qwen-32B/full/ReasonFlux-F1 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--deepspeed cache/ds_z3_offload_config.json
Training ReasonFlux-Zero
We utilize the open-source framework LLaMA-Factory for our training process.
Step 1: Add the data path to thefile_name field of the ReasonFlux entry in
LLaMA-Factory/data/dataset_info.json.
Step 2: Run the following command to train from a 32B model on 8 A100 GPUs:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path Qwen/Qwen2.5-32B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type full \
--template qwen \
--flash_attn auto \
--dataset_dir train/LLaMA-Factory/data \
--dataset ReasonFlux \
--cutoff_len 2048 \
--learning_rate 2e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen2.5-32B-Instruct/full \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--optim adamw_torch \
--deepspeed cache/ds_z3_offload_config.json
For evaluation, we reuse the evaluation framework in s1 . It is cloned lm-evaluation-harness at commit 4cec66e4e468d15789473d6d63c3a61a751fa524 and has been modified to add some tasks. Setup:
cd reasonflux-f1/eval/lm-evaluation-harness
pip install -e .[math,vllm]All commands are in eval/commands.sh. For AIME24 we always pick the aime24_nofigures result, which uses a dataset that only contains the AIME24 figures if they are important for the task.
For example, to evaluate ReasonFlux-F1-32B on AIME24/25, MATH500 and GPQA-Diamond, you can use the command below:
OPENAI_API_KEY=Input your openai key here lm_eval --model vllm --model_args pretrained=Gen-verse/ReasonFlux-F1,dtype=float32,tensor_parallel_size=8,gpu_memory_utilization=0.95 --tasks aime24_figures,aime25_nofigures,openai_math,gpqa_diamond_openai --batch_size auto --apply_chat_template --output_path ReasonFlux-F1 --log_samples --gen_kwargs "max_gen_toks=32768"ReasonFlux-F1
from vllm import LLM, SamplingParams
from transformers import AutoTokenizer
model_id = 'Gen-Verse/ReasonFlux-F1'
model = LLM(
model_id,
tensor_parallel_size=8,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# stop_token_ids = tok("<|im_end|>\n")["input_ids"]
sampling_params = SamplingParams(
max_tokens=32768,
)
# 2022 AIME I Problems/Problem 15
question = """Let \(x, y\), and \(z\) be positive real numbers satisfying the system of equations:
\[
\begin{array}{c}
\sqrt{2 x-x y}+\sqrt{2 y-x y}=1 \\
\sqrt{2 y-y z}+\sqrt{2 z-y z}=\sqrt{2} \\
\sqrt{2 z-z x}+\sqrt{2 x-z x}=\sqrt{3} .
\end{array}
\]
Then \(\left[(1-x)(1-y)(1-z)\right]^{2}\) can be written as \(\frac{m}{n}\), where \(m\) and \(n\) are relatively prime positive integers. Find \(m+n\)."""
ds_prompt="REDACTED_SPECIAL_TOKEN\n" + question + "REDACTED_SPECIAL_TOKEN\n"
output = model.generate(ds_prompt, sampling_params=sampling_params)
print(output[0].outputs[0].text)ReasonFlux-Zero
When you complete your first-stage training, you can try to use simple lines of codes to conduct reasoning based on few lines of code.
from reasonflux import ReasonFlux
reasonflux = ReasonFlux(navigator_path='path-to-navigator',
template_matcher_path='jinaai/jina-embeddings-v3',
inference_path='path-to-infernece-model',
template_path='template_library.json')
problem = """Given a sequence {aₙ} satisfying a₁=3, and aₙ₊₁=2aₙ+5 (n≥1), find the general term formula aₙ"""navigator_path is the path to the navigator, you can put the path to your trained LLM after SFT-stage here.
template_matcher_path is the path to the embedding model, you can set the path to your local embedding model or download jina-embedding-v3 from huggingface.
inference_path is the path to the reasoning model, you can choose different-sized LLMs to test but here we recommend you to choose the same LLMs as the navigator to save memory.
template_path is the path to our template library. When you run the code for the first time, we will encode the template library for efficient query and retrieve and save the embedding in cache, and it is normal the first run will consume longer time in the initialization stage before reasoning.
You can test your trained model after the SFT stage to see if it could retrieve accurate templates given the problem and solve it in our demo implementation.
🚨 It should be noted that if you choose to use jina-embedding-v3, you have to make sure that you do not install flash-attn in your environment, which will cause conflicts and thus fail to encode the query and the template library.
We present the evaluation results of our ReasonFlux-F1-32B on challenging reasoning tasks including AIME2024,AIM2025,MATH500 and GPQA-Diamond. To make a fair comparison, we report the results of the LLMs on our evaluation scripts in ReasonFlux-F1.
| Model | AIME2024@pass1 | AIME2025@pass1 | MATH500@pass1 | GPQA@pass1 |
|---|---|---|---|---|
| QwQ-32B-Preview | 46.7 | 37.2 | 90.6 | 65.2 |
| LIMO-32B | 56.3 | 44.5 | 94.8 | 58.1 |
| s1-32B | 56.7 | 49.3 | 93.0 | 59.6 |
| OpenThinker-32B | 66.0 | 53.3 | 94.8 | 60.1 |
| R1-Distill-32B | 70.0 | 46.7 | 92.0 | 59.6 |
| ReasonFlux-Zero-32B | 56.7 | 37.2 | 91.2 | 61.2 |
| ReasonFlux-F1-32B | 76.7 | 53.3 | 96.0 | 67.2 |

We build our ReasonFlux mainly based on some preliminary works, such as Buffer of Thoughts and SuperCorrect.
@article{yang2025reasonflux,
title={ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates},
author={Yang, Ling and Yu, Zhaochen and Cui, Bin and Wang, Mengdi},
journal={arXiv preprint arXiv:2502.06772},
year={2025}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ReasonFlux
Similar Open Source Tools
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

Q-Bench
Q-Bench is a benchmark for general-purpose foundation models on low-level vision, focusing on multi-modality LLMs performance. It includes three realms for low-level vision: perception, description, and assessment. The benchmark datasets LLVisionQA and LLDescribe are collected for perception and description tasks, with open submission-based evaluation. An abstract evaluation code is provided for assessment using public datasets. The tool can be used with the datasets API for single images and image pairs, allowing for automatic download and usage. Various tasks and evaluations are available for testing MLLMs on low-level vision tasks.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
For similar tasks

EDA-GPT
EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.
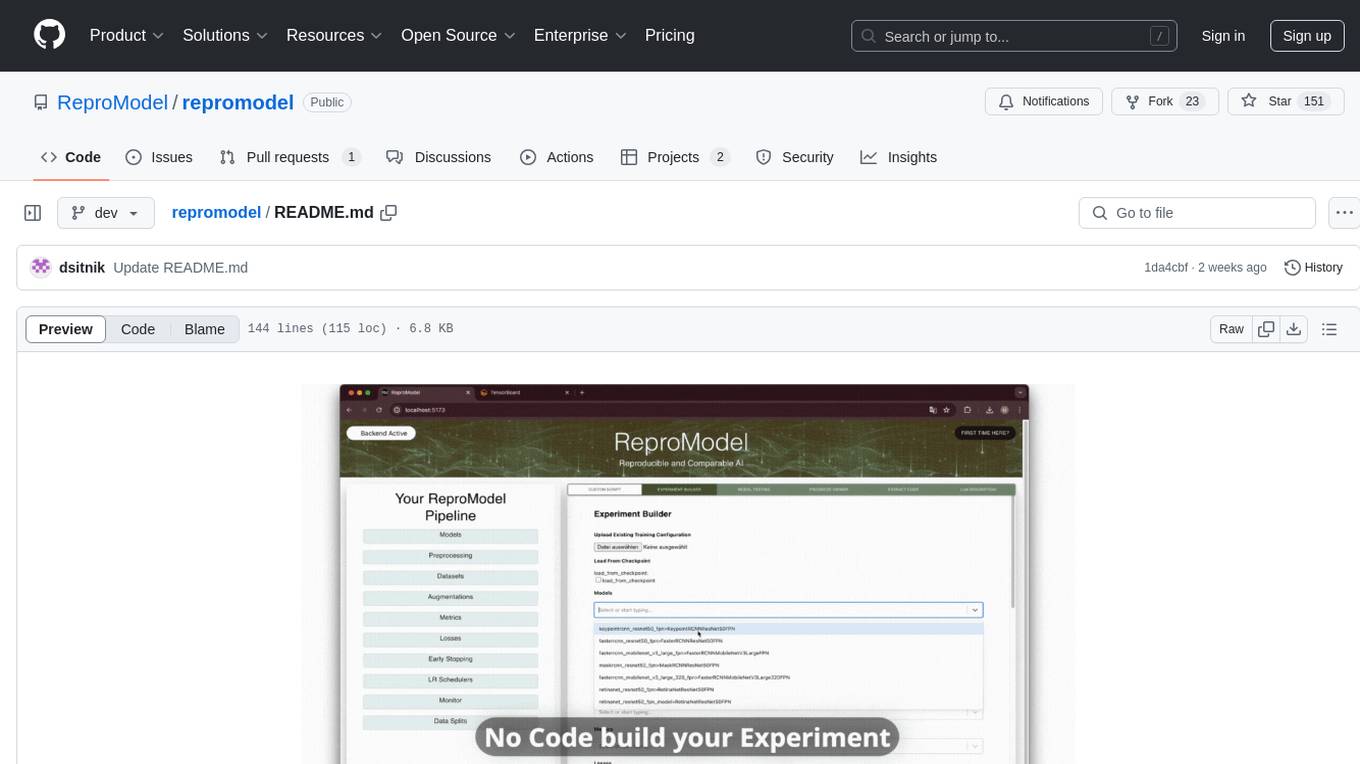
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
terminal-bench
Terminal Bench is a simple command-line benchmark tool for Unix-like systems. It allows users to easily compare the performance of different commands or scripts by measuring their execution time. The tool provides detailed statistics and visualizations to help users analyze the results. With Terminal Bench, users can optimize their scripts and commands for better performance and efficiency.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.

LLMBox
LLMBox is a comprehensive library designed for implementing Large Language Models (LLMs) with a focus on a unified training pipeline and comprehensive model evaluation. It serves as a one-stop solution for training and utilizing LLMs, offering flexibility and efficiency in both training and utilization stages. The library supports diverse training strategies, comprehensive datasets, tokenizer vocabulary merging, data construction strategies, parameter efficient fine-tuning, and efficient training methods. For utilization, LLMBox provides comprehensive evaluation on various datasets, in-context learning strategies, chain-of-thought evaluation, evaluation methods, prefix caching for faster inference, support for specific LLM models like vLLM and Flash Attention, and quantization options. The tool is suitable for researchers and developers working with LLMs for natural language processing tasks.
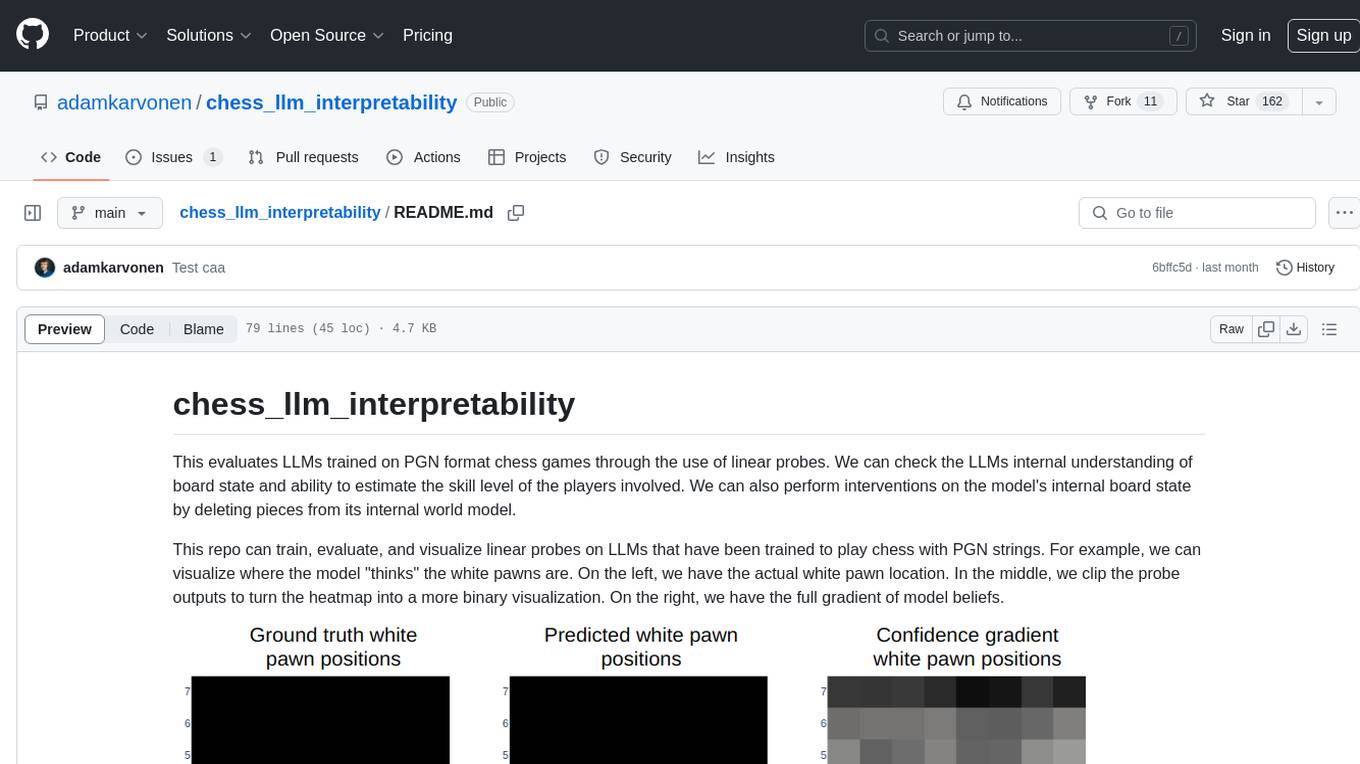
chess_llm_interpretability
This repository evaluates Large Language Models (LLMs) trained on PGN format chess games using linear probes. It assesses the LLMs' internal understanding of board state and their ability to estimate player skill levels. The repo provides tools to train, evaluate, and visualize linear probes on LLMs trained to play chess with PGN strings. Users can visualize the model's predictions, perform interventions on the model's internal board state, and analyze board state and player skill level accuracy across different LLMs. The experiments in the repo can be conducted with less than 1 GB of VRAM, and training probes on the 8 layer model takes about 10 minutes on an RTX 3050. The repo also includes scripts for performing board state interventions and skill interventions, along with useful links to open-source code, models, datasets, and pretrained models.
For similar jobs

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).

1filellm
1filellm is a command-line data aggregation tool designed for LLM ingestion. It aggregates and preprocesses data from various sources into a single text file, facilitating the creation of information-dense prompts for large language models. The tool supports automatic source type detection, handling of multiple file formats, web crawling functionality, integration with Sci-Hub for research paper downloads, text preprocessing, and token count reporting. Users can input local files, directories, GitHub repositories, pull requests, issues, ArXiv papers, YouTube transcripts, web pages, Sci-Hub papers via DOI or PMID. The tool provides uncompressed and compressed text outputs, with the uncompressed text automatically copied to the clipboard for easy pasting into LLMs.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

HebTTS
HebTTS is a language modeling approach to diacritic-free Hebrew text-to-speech (TTS) system. It addresses the challenge of accurately mapping text to speech in Hebrew by proposing a language model that operates on discrete speech representations and is conditioned on a word-piece tokenizer. The system is optimized using weakly supervised recordings and outperforms diacritic-based Hebrew TTS systems in terms of content preservation and naturalness of generated speech.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.