
EDA-GPT
Automated Data Analysis leveraging llms
Stars: 160

EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.
README:



Welcome to EDA GPT, your comprehensive solution for all your data analysis needs. Whether you're analyzing structured data in CSV, XLSX, or SQLite formats, generating insightful graphs, or conducting in-depth analysis of unstructured data such as PDFs and images, EDA GPT is here to assist you every step of the way.
EDA GPT streamlines the data analysis process, allowing users to effortlessly explore, visualize, and gain insights from their data. With a user-friendly interface and powerful features, EDA GPT empowers users to make data-driven decisions with confidence.
To get started with EDA GPT, simply navigate to the app and follow the on-screen instructions. Upload your data, specify your analysis preferences, and let EDA GPT handle the rest. With its intuitive interface and powerful features, EDA GPT makes data analysis accessible to users of all skill levels.
-
Structured Data Analysis:
- Analyze structured data by uploading files or connecting to databases like PostgreSQL. Supports csv,xlxs & sqlite
- Provide additional context about your data and elaborate on desired outcomes for more accurate analysis.
-
Graph Generation:
- Generate various types of graphs effortlessly by specifying clear instructions.
- Access the generated code for fine-tuning and customization.
-
Analysis Questions:
- Post initial EDA, ask analysis questions atop the generated report.
- Gain insights through Plotly graphs and visualization reports.
-
Comparison of Performance:
- Compare the performance of EDA GPT & pandasai based on accuracy, speed, and handling complex queries.
xychart-beta title "Comparison of EDA GPT(blue) and PandasAI Performance(green)" x-axis ["Accuracy", "Speed", "Complex Queries"] y-axis "Score (out of 100)" 0 --> 100 bar EDA_GPT [90, 92, 90] bar PandasAI [85, 90, 70]
-
LLMs (Large Language Models):
- Choose from a variety of LLMs based on dataset characteristics. Supports HuggingFace,Openai,Groq,Gemini models. Claude3 & GPT4 is available for paid members.
- Consider factors such as dataset size and analysis complexity when selecting an LLM. Models with large context length tend to work better for larger datasets.
-
Unstructured Data Analysis:
- Analyze unstructured PDF data efficiently. Table structure and Images are infered from unstructured data for better analysis.
- Provide detailed descriptions to enhance LLM decision-making.
- Has Internet Access and follows action/Observation/Thought principle for solving complex tasks.
-
Multimodal Search:
- Search answers from diverse sources including Wikipedia, Arxiv, DuckDuckGo, and web scrapers.
- Analyze images with integrated Large vision models.
-
Data Cleaning and Editing:
- Clean and edit your data using various methods provided by EDA GPT.
- Benefit from automated data cleaning processes, saving time and effort.
-
Capable of analyzing impressive volume of structured and unstructured data.
-
Unstructured data like audio files, pdfs, images can be analyzed. Youtube video can be analyzed as well for summarizing content.
-
Special class called Lang Group Chain is designed to handle complex queries. It is currently unstable but the architecture is useful and can be enhanced upon. It essentially breaks down a primary question into subquestions represented as nodes. Each node have some dependency or codependency. Special data structures called LangGroups stores these Lang Nodes. These are sorted in topological order and grouped on basis of same indegree. Each group is passed to llm with previous context to iteratively reach the answer. This kind of architecture is useful in questions like : Find M//3 + 2 where M is age difference between Donald Trump and Joe Biden plus the years taken for pluto to complete one revolution. Notice we need to form sequence of well defined steps to solve this like humans do. This costs more llm calls.
-
Advanced rag like multiquery and context filtering is used to get better results. Tables are extracted while making embeddings if any.
-
In Structured EDA GPT section you are provided with interactive visualizations, pygwalker integration, context rich analysis report.
-
You can talk to EDA GPT and ask it to generate visuals, compute complex queries on dataframe, derive insights, see relationships between features and more. ALl with natural language.
-
A wide range of llms are supported and keeping privacy in mind, one can use ollama models for offline analysis.
-
Autoclean is implemented to clean data based on various parameters like linear-regression.
-
Classificatio models are used for faster inference instead of using llms for explicit classification wherever it's needed.
NOTE : It is advised to provide context rich data manually to the llm before analysis for better results after it is done.
RECOMMENDATIONS : Gemini, OpenAI, Claude3 & LLAMA 3 models work better than most other models.
System Architecture
- Structured Data EDA
graph TB
subgraph STRUCTURED-DATA-ANALYZER
DATA(UPLOAD STRUCTURED DATA) --> analyze(ANALYZE) -- llm analyzes --> EDA(Initial EDA Report)
detail[Deals With Relational Data]
end
subgraph VStore
vstore[(VectorEmbeddings)]
includes([FAISS vstore])
end
EDA(Initial EDA Report)-->docs(DOCUMENT STORE)
subgraph CALLING-LLM-LLMCHAIN
prompttemplate(prompts)-->docschain(create-stuff-docs-chain)
llm(llm choice)-->docschain(create-stuff-docs-chain)
vstore[(VectorEmbeddings)] -- returns embeddings --> retriever(embeddings as-retriever) -->retrieverchain(retriever-chain--->retrieves vstore embeddings)
docschain(create-stuff-docs-chain)-->retrieverchain(retriever-chain--->retrieves vstore embeddings) --> Chain(chain-->chain.invoke) --> result(LLM ANSWER)
end
subgraph VSTORE-INTERNALS
coderag([coding examples for rag])-->docs(DOCUMENT STORE)
docs(DOCUMENT STORE)--preprocess-->preprocessing([splitting,chunking,infer tables, structure in text data])
preprocessing--embeddings-->embed&save(save to vstore)--save-->vstore[(VectorEmbeddings)]
end
subgraph EDAGPT-CHAT_INTERFACE
subgraph CHAT
chatinterface(Talk to EDA GPT) -- user-asks-question --> Q&A[Q&A Interface runs] --> function(pandasaichattool)
function(pandasaichattool) -- create-stuff-docs-chain-creates-request --> vstore[(VectorEmbeddings)]
end
end
subgraph CODE CORRECTOR
error&query[Combine Error And Query]--into prompt-->correctorllm(SMARTLLMCHAIN)-->method[Chain OF Thoughts]
method[Chain OF Thoughts]-->corrected(LLM CORRECTION)
end
subgraph OUTPUT_CLASSIFIER
result(LLM ANSWER)--->Clf(Classification Model)
models(Models: Random Forest, Naive Bayes)
Clf(Classification Model)--label:sentence-->sentence(display result)
Clf(Classification Model)--label:code-->code(code parser)-->codeformatter(CODE-FORMATTER)
corrected(LLM CORRECTION)-->code(code parser)
end
subgraph CODE PARSER
codeformatter(CODE-FORMATTER)--formats code-->exe(Executor)--no error-->output(returns code + output)-->display(display code
result)
exe(Executor)--error-->error(if Error)-->error&query[Combine Error And Query]
end
- Unstructured Data EDA
graph TB
subgraph UNSTRUCTURED-DATA-ANALYZER
pdf(UPLOAD PDF) --> checkpdf(pdf content check)
image(UPLOAD IMAGE) --> checkimg(image content check)
checkpdf & checkimg -- |if Valid content| --> embeddings(make-vector embeddings)
detail[Deals With Unstructured Data]
end
subgraph VectorStore
vstore[(VectorEmbeddings)]
includes([FAISS vstore])
end
subgraph CALLING-LLM-LLMCHAIN
prompttemplate(prompts)-->docschain(create-stuff-docs-chain)
llm(llm choice)-->docschain(create-stuff-docs-chain)
chat_history(chat history)-->docschain(create-stuff-docs-chain)
vstore[(VectorEmbeddings)] -- returns embeddings --> retriever(embeddings as-retriever) -->retrieverchain(retriever-chain--->retrieves vstore embeddings)
multiquery([MultiQuery Retriever--> generates diverse questions for retrieval])-->retrieverchain
docschain(create-stuff-docs-chain)-->retrieverchain(retriever-chain--->retrieves vstore embeddings) --> Chain(chain-->chain.invoke) --> result(LLM ANSWER)
end
subgraph VSTORE-INTERNALS
embeddings(make-vector embeddings)--|check for structured data|-->infer-structure([INFER TABLE STRUCTURE if present])--save_too-->docs(DOCUMENT STORE)
docs(DOCUMENT STORE)--preprocess-->preprocessing([splitting,chunking,infer tables, structure in text data])
preprocessing--embeddings-->embed&save(save to vstore)--save-->vstore[(VectorEmbeddings)]
end
subgraph EDAGPT-CHAT_INTERFACE
subgraph CHAT
chatinterface(Talk to DATA) -- user-asks-question --> Q&A[Q&A Interface runs] --> clf(Classification Model)--|user-question|-->models
subgraph MultiClassModels
models(Models: Random Forest, Naive Bayes)--class-->analysis[Analysis]
models(Models: Random Forest, Naive Bayes)--class-->vision[Vision]
models(Models: Random Forest, Naive Bayes)--class-->search[Search]
end
end
subgraph Analysis
analysis[Analysis]-->datanalyst([ANSWERS QUESTION FROM DOCS])
datanalyst--requests-->vstore-->docschain(create-stuff-docs-chain)
end
subgraph Vision
vision[Vision]-->multimodal-LLM(MultiModal-LLM)-->result
end
subgraph SearchAgent
search[Search]-->multimodalsearch[Multimodal-Search Agent]-->agents
end
end
subgraph Agents
agents-->funcs{Capabilities}
subgraph features
funcs-->internet([Search Internet])-->services([Duckduckgo, Tavily, Google])
funcs-->scrape([scraper])
funcs-->findocs([Utilize Docs])-->datanalyst
funcs-->visioncapabilities([Utilize Vision])-->vision
end
subgraph Combine
internet & scrape & findocs & visioncapabilities --> combine([Combine Results])
combine([Combine Results])-->working[Utilizes various Permutation And Combination Of Tools based on Though/Action/Observation]-->result
end
end
-
FAISS Uses Inverted File Based indexing strategy to index the embeddings which is suitable for datasets ranging from 10MB to around 2GB. For higher memory demanding datasets, graph based indexing , hybrid indexing or disk indexing can be used. For most day-to-day purposes FAISS is a good choice.
-
Chroma database is used for comparatively larger files with more text corpus (example : pdf of 130 pages). It uses Hierarchical Navigable Samll World algorithm for indexing which is good for knn algorithm while performing similarity search.
-
EDA GPT is optimized for maximal parallel processing. It embeds a huge list of documents and adds them to chroma parallelly.
-
It is heavily optimized for searching internet, documents and creating analysis reports from structured and unstructured data.
-
Advanced retrieval techniques like multiquery retrieval, emsemble retrieval combined with similarity search with a high threshold is used to get useful documents.
-
A large language model with high context window like gemini-pro-1.5 works best for large volumes of data. Since llms have a limit for context, it is not recommended to feed humungous amount of data in one go. We recommend to divide a huge pdf into smaller pdfs if possible and process independent data in one session. For example a pdf of 1000 pages with over 5 * 10^6 words should be divided for efficiency.
-
data is cached at every point for faster inference.
- link to notebook: https://colab.research.google.com/drive/1vqMTPWeSlF7iYG06PFkrYw9lxcnrrmaE?usp=sharing#scrollTo=9dzFcTeY53eG
For Indepth Understanding Of The Application Check Out Check out the Low Level Design documentation as markdown and High Level Design pdf
To use this app, follow these steps:
-
Clone the repository:
git clone https://github.com/shaunthecomputerscientist/EDA-GPT.git cd EDA-GPT -
Make a virtual environment and install dependencies:
pip install -r requirements.txt
-
Set Up secrets.toml inside .streamlit folder:

-
Start the app:
streamlit run Home.py
Before you begin, ensure you have the following installed on your local system:
- Docker (Make sure Docker Desktop is running if you're on Windows or macOS)
To get started, pull the Docker image from Docker Hub. Open your terminal and run:
docker pull mrpoldockeroperator123/eda-gpt:v2docker run -d -p 8501:8501 mrpoldockeroperator123/eda-gpt:v2This command will:
Run the container in detached mode (-d). Map port 8501 on your local machine to port 8501 on the container.
After the container is running, you can access the EDA-GPT application by navigating to http://localhost:8501 in your web browser.
stop the container when done
docker psThis command will list all running containers. Find the CONTAINER ID of the EDA-GPT container and stop it using:
docker stop <CONTAINER_ID>If you no longer need the container, you can remove it with:
docker rm <CONTAINER_ID>If you want to free up space, you can also remove the Docker image from your local system:
docker rmi mrpoldockeroperator123/eda-gpt:v2Troubleshooting If you encounter issues while running the container, consider the following steps:
Check Docker Installation: Ensure Docker is installed and running correctly. Port Availability: Make sure port 8501 is not being used by another application. Logs: Check container logs to diagnose issues by running:
docker logs <CONTAINER_ID>When you run the command:
docker ps
#you get
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e9f8c9b5b86c mrpoldockeroperator123/eda-gpt:v2 "streamlit run home.py" 10 minutes ago Up 10 minutes 0.0.0.0:8501->8501/tcp charming_mendelThe CONTAINER ID is the e9f8c9b5b86c in this case
- mrpoldockeroperator123/eda-gpt:v1 is the name of the Docker image.
- 0.0.0.0:8501->8501/tcp indicates that port 8501 on the host is forwarded to port - - 8501 in the container.
- charming_mendel is the name automatically assigned to the container by Docker (you can also specify a name using the --name flag when you run the container).
We value your feedback and are constantly working to improve EDA GPT. If you encounter any issues or have suggestions for improvement, please don't hesitate to reach out to our support team. developer contact : [email protected]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for EDA-GPT
Similar Open Source Tools
EDA-GPT
EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.

reductstore
ReductStore is a high-performance time series database designed for storing and managing large amounts of unstructured blob data. It offers features such as real-time querying, batching data, and HTTP(S) API for edge computing, computer vision, and IoT applications. The database ensures data integrity, implements retention policies, and provides efficient data access, making it a cost-effective solution for applications requiring unstructured data storage and access at specific time intervals.

Controllable-RAG-Agent
This repository contains a sophisticated deterministic graph-based solution for answering complex questions using a controllable autonomous agent. The solution is designed to ensure that answers are solely based on the provided data, avoiding hallucinations. It involves various steps such as PDF loading, text preprocessing, summarization, database creation, encoding, and utilizing large language models. The algorithm follows a detailed workflow involving planning, retrieval, answering, replanning, content distillation, and performance evaluation. Heuristics and techniques implemented focus on content encoding, anonymizing questions, task breakdown, content distillation, chain of thought answering, verification, and model performance evaluation.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

graphrag-local-ollama
GraphRAG Local Ollama is a repository that offers an adaptation of Microsoft's GraphRAG, customized to support local models downloaded using Ollama. It enables users to leverage local models with Ollama for large language models (LLMs) and embeddings, eliminating the need for costly OpenAPI models. The repository provides a simple setup process and allows users to perform question answering over private text corpora by building a graph-based text index and generating community summaries for closely-related entities. GraphRAG Local Ollama aims to improve the comprehensiveness and diversity of generated answers for global sensemaking questions over datasets.

nucliadb
NucliaDB is a robust database that allows storing and searching on unstructured data. It is an out of the box hybrid search database, utilizing vector, full text and graph indexes. NucliaDB is written in Rust and Python. We designed it to index large datasets and provide multi-teanant support. When utilizing NucliaDB with Nuclia cloud, you are able to the power of an NLP database without the hassle of data extraction, enrichment and inference. We do all the hard work for you.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

radicalbit-ai-monitoring
The Radicalbit AI Monitoring Platform provides a comprehensive solution for monitoring Machine Learning and Large Language models in production. It helps proactively identify and address potential performance issues by analyzing data quality, model quality, and model drift. The repository contains files and projects for running the platform, including UI, API, SDK, and Spark components. Installation using Docker compose is provided, allowing deployment with a K3s cluster and interaction with a k9s container. The platform documentation includes a step-by-step guide for installation and creating dashboards. Community engagement is encouraged through a Discord server. The roadmap includes adding functionalities for batch and real-time workloads, covering various model types and tasks.

datasets
Datasets is a repository that provides a collection of various datasets for machine learning and data analysis projects. It includes datasets in different formats such as CSV, JSON, and Excel, covering a wide range of topics including finance, healthcare, marketing, and more. The repository aims to help data scientists, researchers, and students access high-quality datasets for training models, conducting experiments, and exploring data analysis techniques.

project_alice
Alice is an agentic workflow framework that integrates task execution and intelligent chat capabilities. It provides a flexible environment for creating, managing, and deploying AI agents for various purposes, leveraging a microservices architecture with MongoDB for data persistence. The framework consists of components like APIs, agents, tasks, and chats that interact to produce outputs through files, messages, task results, and URL references. Users can create, test, and deploy agentic solutions in a human-language framework, making it easy to engage with by both users and agents. The tool offers an open-source option, user management, flexible model deployment, and programmatic access to tasks and chats.

venice
Venice is a derived data storage platform, providing the following characteristics: 1. High throughput asynchronous ingestion from batch and streaming sources (e.g. Hadoop and Samza). 2. Low latency online reads via remote queries or in-process caching. 3. Active-active replication between regions with CRDT-based conflict resolution. 4. Multi-cluster support within each region with operator-driven cluster assignment. 5. Multi-tenancy, horizontal scalability and elasticity within each cluster. The above makes Venice particularly suitable as the stateful component backing a Feature Store, such as Feathr. AI applications feed the output of their ML training jobs into Venice and then query the data for use during online inference workloads.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

LlamaIndexTS
LlamaIndex.TS is a data framework for your LLM application. Use your own data with large language models (LLMs, OpenAI ChatGPT and others) in Typescript and Javascript.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

CosmosAIGraph
CosmosAIGraph is an AI-powered graph and RAG implementation of OmniRAG pattern, utilizing Azure Cosmos DB and other sources. It includes presentations, reference application documentation, FAQs, and a reference dataset of Python libraries pre-vectorized. The project focuses on Azure Cosmos DB for NoSQL and Apache Jena implementation for the in-memory RDF graph. It provides DockerHub images, with plans to add RBAC and Microsoft Entra ID/AAD authentication support, update AI model to gpt-4.5, and offer generic graph examples with a graph generation solution.
For similar tasks

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.
EDA-GPT
EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.
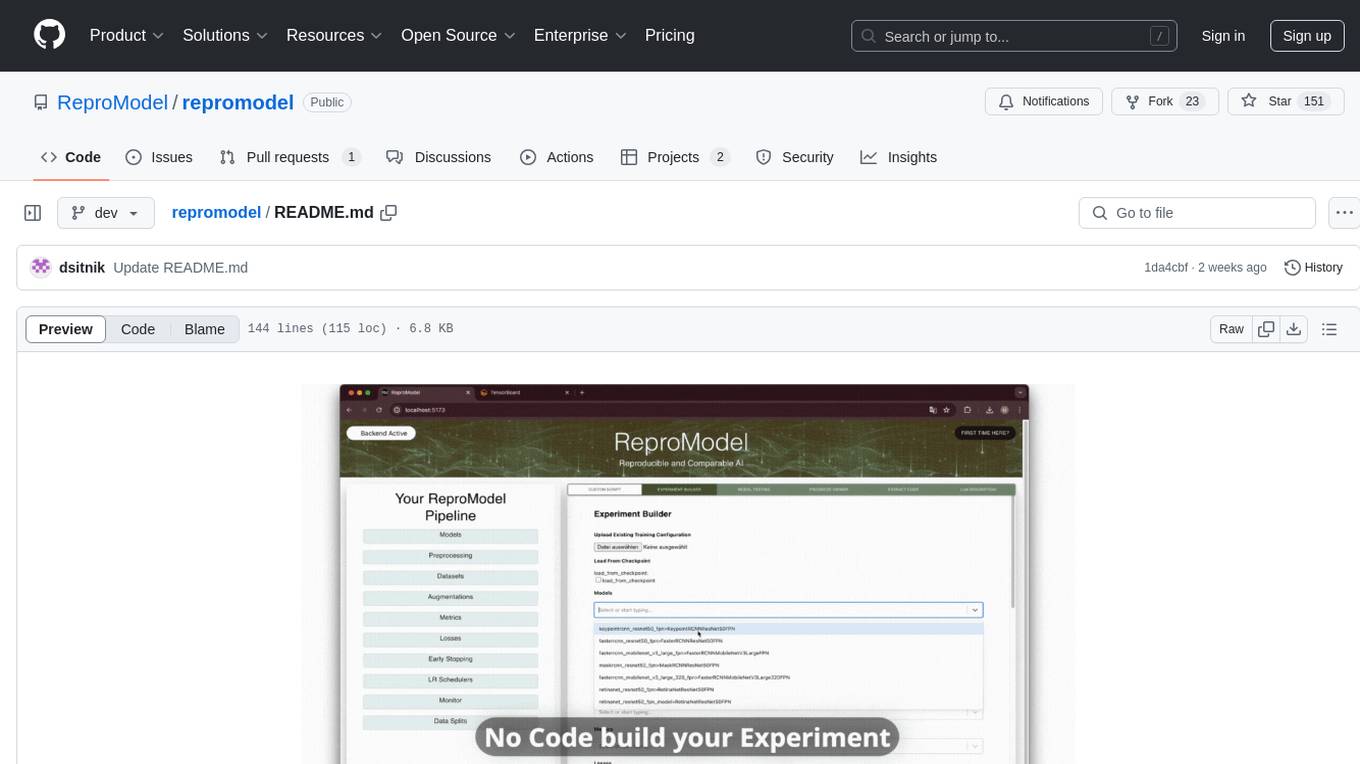
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
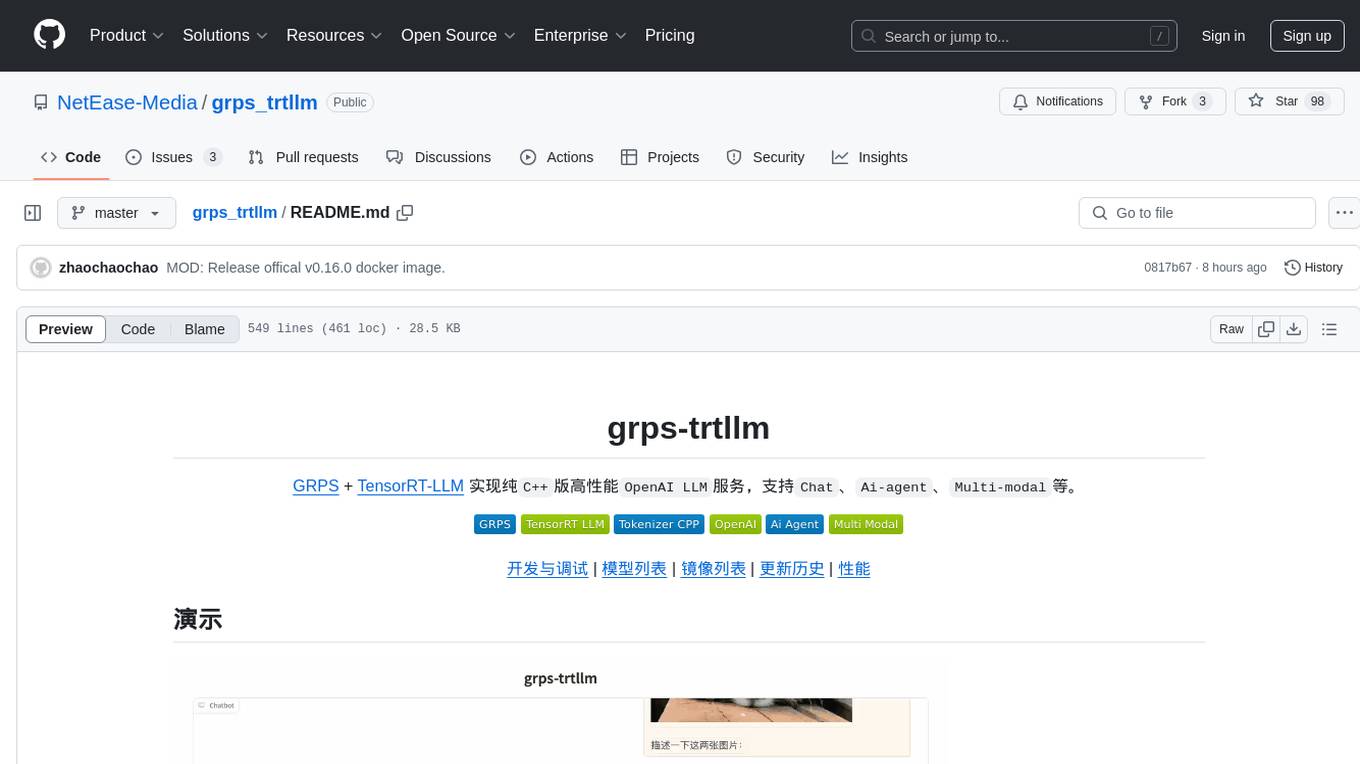
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
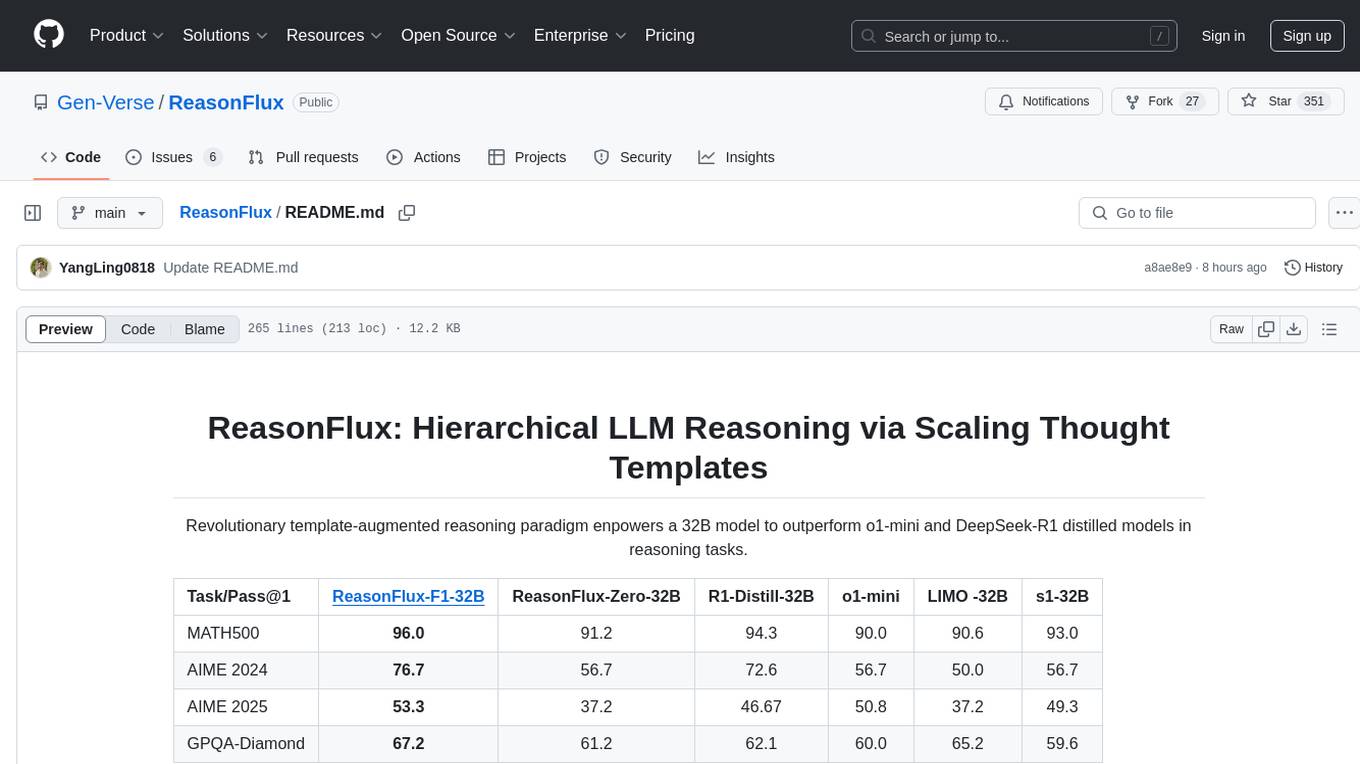
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
terminal-bench
Terminal Bench is a simple command-line benchmark tool for Unix-like systems. It allows users to easily compare the performance of different commands or scripts by measuring their execution time. The tool provides detailed statistics and visualizations to help users analyze the results. With Terminal Bench, users can optimize their scripts and commands for better performance and efficiency.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
For similar jobs

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

vanna
Vanna is an open-source Python framework for SQL generation and related functionality. It uses Retrieval-Augmented Generation (RAG) to train a model on your data, which can then be used to ask questions and get back SQL queries. Vanna is designed to be portable across different LLMs and vector databases, and it supports any SQL database. It is also secure and private, as your database contents are never sent to the LLM or the vector database.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

activepieces
Activepieces is an open source replacement for Zapier, designed to be extensible through a type-safe pieces framework written in Typescript. It features a user-friendly Workflow Builder with support for Branches, Loops, and Drag and Drop. Activepieces integrates with Google Sheets, OpenAI, Discord, and RSS, along with 80+ other integrations. The list of supported integrations continues to grow rapidly, thanks to valuable contributions from the community. Activepieces is an open ecosystem; all piece source code is available in the repository, and they are versioned and published directly to npmjs.com upon contributions. If you cannot find a specific piece on the pieces roadmap, please submit a request by visiting the following link: Request Piece Alternatively, if you are a developer, you can quickly build your own piece using our TypeScript framework. For guidance, please refer to the following guide: Contributor's Guide