
repromodel
Boosting the AI research efficiency
Stars: 151
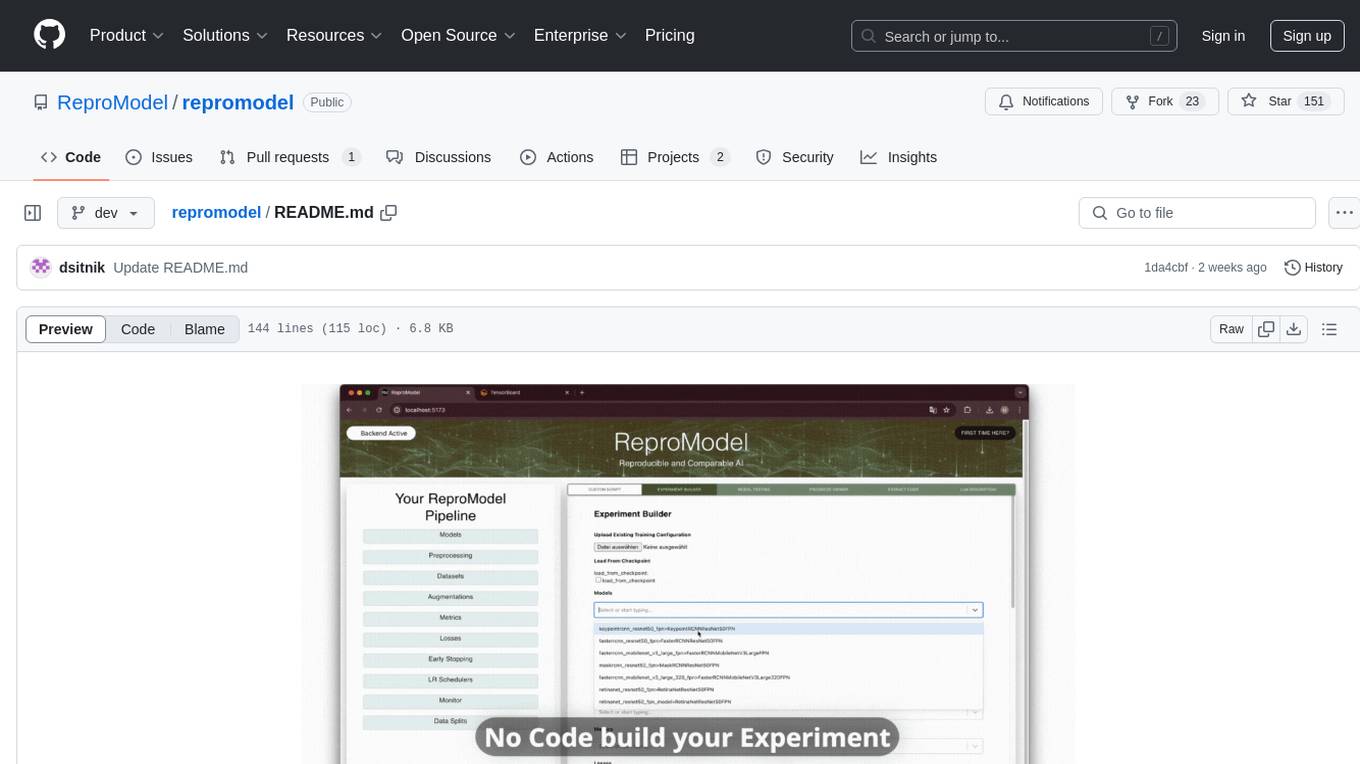
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
README:

Open Source Toolbox for Boosting the AI Research Efficiency


ReproModel helps the AI research community to reproduce, compare, train, and test AI models faster.
ReproModel toolbox revolutionizes research efficiency by providing standardized models, dataloaders, and processing procedures. It features a comprehensive suite of pre-existing experiments, a code extractor, and an LLM descriptor. This toolbox allows researchers to focus on new datasets and model development, significantly reducing time and computational costs.
With this no-code solution, you'll have access to a collection of benchmark and SOTA models and datasets. Dive into training visualizations, effortlessly extract code for publication, and let our LLM-powered automated methodology description writer do the heavy lifting.
The current prototype helps researchers to modularize their development and compare the performance of each step in the pipeline in a reproducible way. This prototype version helped us reduce the time for model development, computation, and writing by at least 40%. Watch our demo.
The coming versions will help researchers build upon state-of-the-art research faster by just loading the previously published study ID. All code, experiments, and results will already be verified and stored in our system.
https://repromodel.netlify.app
✅ Standard Models Included
✅ Benchmark Datasets
✅ Metrics (100+)
✅ Losses (20+)
✅ Data Splitting
✅ Augmentations
✅ Optimizers (10+)
✅ Learning Rate Schedulers
✅ Early Stopping Criterion
✅ Training Device Selection
✅ Logging (Tensorboard ...)
✅ AI Experiment Description Generator
✅ Code Extractor
✅ Custom Script Editor
✅ Docker image
🔲 GUI augmentation builder
🔲 Conventional ML models workflow
🔲 Parallel training
🔲 Statistical testing
🔲 Explainability
🔲 Interpretability
For examples and step-by-step instructions, please visit our full documentation at https://www.repromodel.com/docs.
Please verify that you have Docker or Docker CLI installed on your system.
Pull the docker image:
docker pull dsitnik1612/repromodel
Run the container:
docker run --name ReproModel -p 5173:5173 -p 6006:6006 -p 5005:5005 dsitnik1612/repromodel
Then open the frontend under: http://localhost:5173/
In case you want to run the ReproModel directly from the source code, here are the steps:
You will need to have Node.js installed.
Combines npm install, creation of a virtual environment, as well as the launch of the frontend and backend:
npm run repromodel // Mac and Linux
npm run repromodel-windows // Windows
If you want to launch the frontend only:
npm install
npm run dev
For using the Methodology Generator, you need to have Ollama installed You can get Ollama from their website and pull the model of your choice.
npm install
npm run repromodel-with-llm // Mac and Linux
npm run repromodel-with-llm-windows // Windows
Then open the frontend under: http://localhost:5173/
Contributions are what make the open-source community such an amazing place to learn, inspire, and create.
Any contributions you make are greatly appreciated. If you have a suggestion that would make this better, please read our Contribution Guidelines and Code of Conduct.
 Dario Sitnik, PhD AI Scientist GitHub |
 Mint Owl ML Engineer GitHub |
 Martin Schumakher Developer GitHub |
 Tomonari Feehan Developer GitHub |

For questions or any type of support, you can reach out to me via [email protected]
This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for repromodel
Similar Open Source Tools
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
HAMi
HAMi is a Heterogeneous AI Computing Virtualization Middleware designed to manage Heterogeneous AI Computing Devices in a Kubernetes cluster. It allows for device sharing, device memory control, device type specification, and device UUID specification. The tool is easy to use and does not require modifying task YAML files. It includes features like hard limits on device memory, partial device allocation, streaming multiprocessor limits, and core usage specification. HAMi consists of components like a mutating webhook, scheduler extender, device plugins, and in-container virtualization techniques. It is suitable for scenarios requiring device sharing, specific device memory allocation, GPU balancing, low utilization optimization, and scenarios needing multiple small GPUs. The tool requires prerequisites like NVIDIA drivers, CUDA version, nvidia-docker, Kubernetes version, glibc version, and helm. Users can install, upgrade, and uninstall HAMi, submit tasks, and monitor cluster information. The tool's roadmap includes supporting additional AI computing devices, video codec processing, and Multi-Instance GPUs (MIG).
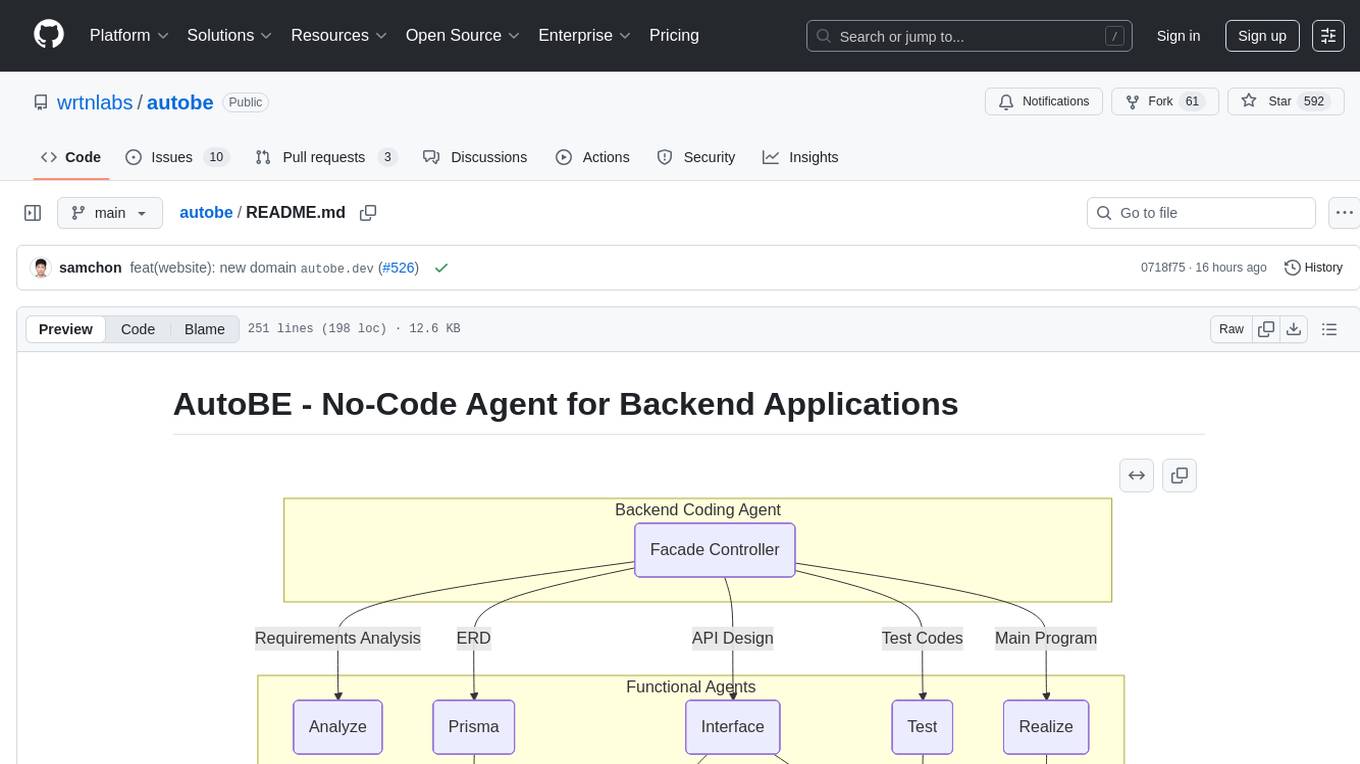
autobe
AutoBE is an AI-powered no-code agent that builds backend applications, enhanced by compiler feedback. It automatically generates backend applications using TypeScript, NestJS, and Prisma following a waterfall development model. The generated code is validated by review agents and OpenAPI/TypeScript/Prisma compilers, ensuring 100% working code. The tool aims to enable anyone to build backend servers, AI chatbots, and frontend applications without coding knowledge by conversing with AI.
StratosphereLinuxIPS
Slips is a powerful endpoint behavioral intrusion prevention and detection system that uses machine learning to detect malicious behaviors in network traffic. It can work with network traffic in real-time, PCAP files, and network flows from tools like Suricata, Zeek/Bro, and Argus. Slips threat detection is based on machine learning models, threat intelligence feeds, and expert heuristics. It gathers evidence of malicious behavior and triggers alerts when enough evidence is accumulated. The tool is Python-based and supported on Linux and MacOS, with blocking features only on Linux. Slips relies on Zeek network analysis framework and Redis for interprocess communication. It offers a graphical user interface for easy monitoring and analysis.

AIOS
AIOS, a Large Language Model (LLM) Agent operating system, embeds large language model into Operating Systems (OS) as the brain of the OS, enabling an operating system "with soul" -- an important step towards AGI. AIOS is designed to optimize resource allocation, facilitate context switch across agents, enable concurrent execution of agents, provide tool service for agents, maintain access control for agents, and provide a rich set of toolkits for LLM Agent developers.
legacy-sourcegraph
Sourcegraph is a tool that simplifies reading, writing, and fixing code in large and complex codebases. It offers features such as code search across repositories and hosts, code intelligence for navigation and references, and the ability to roll out large-scale changes and track migrations. Sourcegraph can be used on the cloud or self-hosted, with public code search available on Sourcegraph.com. The tool provides high-level architecture documentation, database setup best practices, Go and documentation style guides, tips for modifying the GraphQL API, and guidelines for contributing.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.
workflows-py
LlamaIndex Workflows is a framework for orchestrating and chaining together complex systems of steps and events. It shines in orchestrating complex, multi-step processes involving AI models, APIs, and decision-making. The async-first, event-driven architecture allows building workflows that can route between different capabilities, implement parallel processing patterns, loop over complex sequences, and maintain state across multiple steps. Key features include async-first design, event-driven structure, state management, and observability through tools like Arize Phoenix and OpenTelemetry.
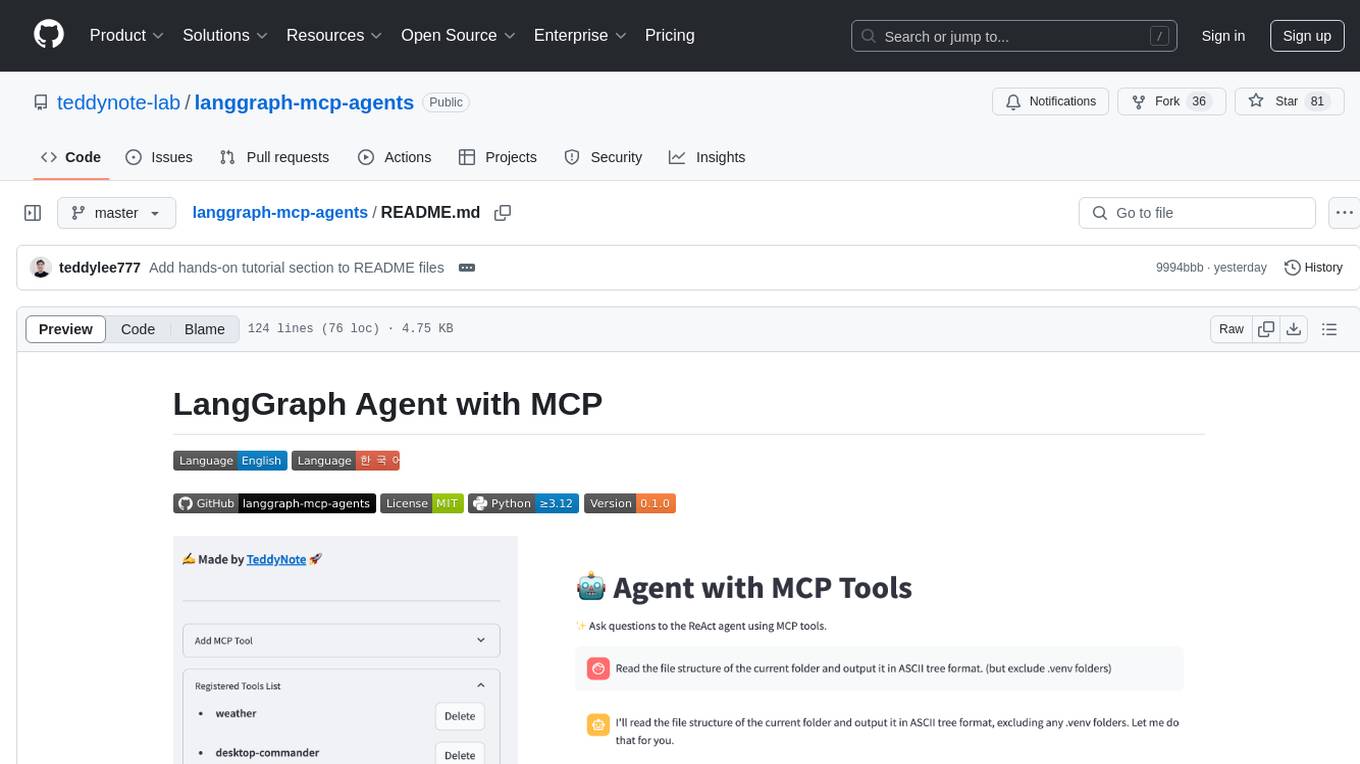
langgraph-mcp-agents
LangGraph Agent with MCP is a toolkit provided by LangChain AI that enables AI agents to interact with external tools and data sources through the Model Context Protocol (MCP). It offers a user-friendly interface for deploying ReAct agents to access various data sources and APIs through MCP tools. The toolkit includes features such as a Streamlit Interface for interaction, Tool Management for adding and configuring MCP tools dynamically, Streaming Responses in real-time, and Conversation History tracking.

ludwig
Ludwig is a declarative deep learning framework designed for scale and efficiency. It is a low-code framework that allows users to build custom AI models like LLMs and other deep neural networks with ease. Ludwig offers features such as optimized scale and efficiency, expert level control, modularity, and extensibility. It is engineered for production with prebuilt Docker containers, support for running with Ray on Kubernetes, and the ability to export models to Torchscript and Triton. Ludwig is hosted by the Linux Foundation AI & Data.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
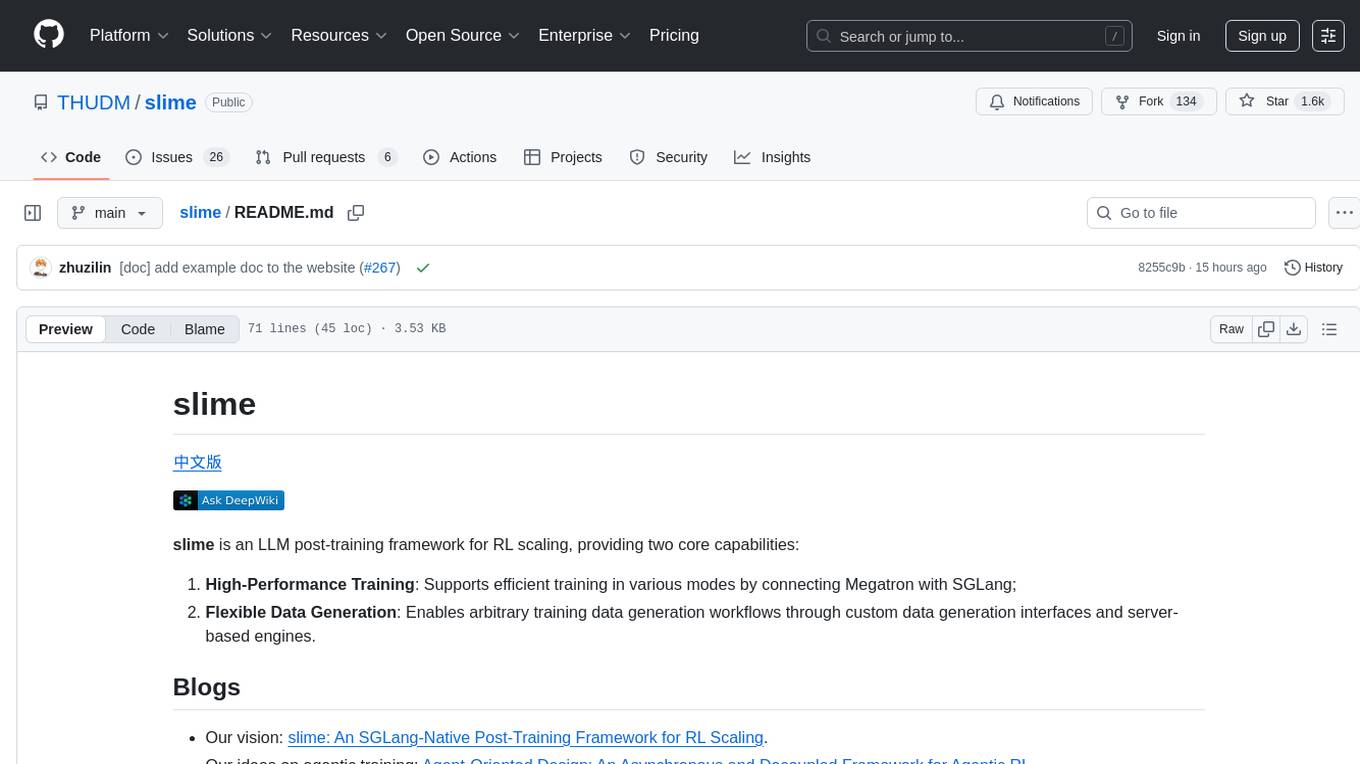
slime
Slime is an LLM post-training framework for RL scaling that provides high-performance training and flexible data generation capabilities. It connects Megatron with SGLang for efficient training and enables custom data generation workflows through server-based engines. The framework includes modules for training, rollout, and data buffer management, offering a comprehensive solution for RL scaling.
LLM-Zero-to-Hundred
LLM-Zero-to-Hundred is a repository showcasing various applications of LLM chatbots and providing insights into training and fine-tuning Language Models. It includes projects like WebGPT, RAG-GPT, WebRAGQuery, LLM Full Finetuning, RAG-Master LLamaindex vs Langchain, open-source-RAG-GEMMA, and HUMAIN: Advanced Multimodal, Multitask Chatbot. The projects cover features like ChatGPT-like interaction, RAG capabilities, image generation and understanding, DuckDuckGo integration, summarization, text and voice interaction, and memory access. Tutorials include LLM Function Calling and Visualizing Text Vectorization. The projects have a general structure with folders for README, HELPER, .env, configs, data, src, images, and utils.
For similar tasks

EDA-GPT
EDA GPT is an open-source data analysis companion that offers a comprehensive solution for structured and unstructured data analysis. It streamlines the data analysis process, empowering users to explore, visualize, and gain insights from their data. EDA GPT supports analyzing structured data in various formats like CSV, XLSX, and SQLite, generating graphs, and conducting in-depth analysis of unstructured data such as PDFs and images. It provides a user-friendly interface, powerful features, and capabilities like comparing performance with other tools, analyzing large language models, multimodal search, data cleaning, and editing. The tool is optimized for maximal parallel processing, searching internet and documents, and creating analysis reports from structured and unstructured data.
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
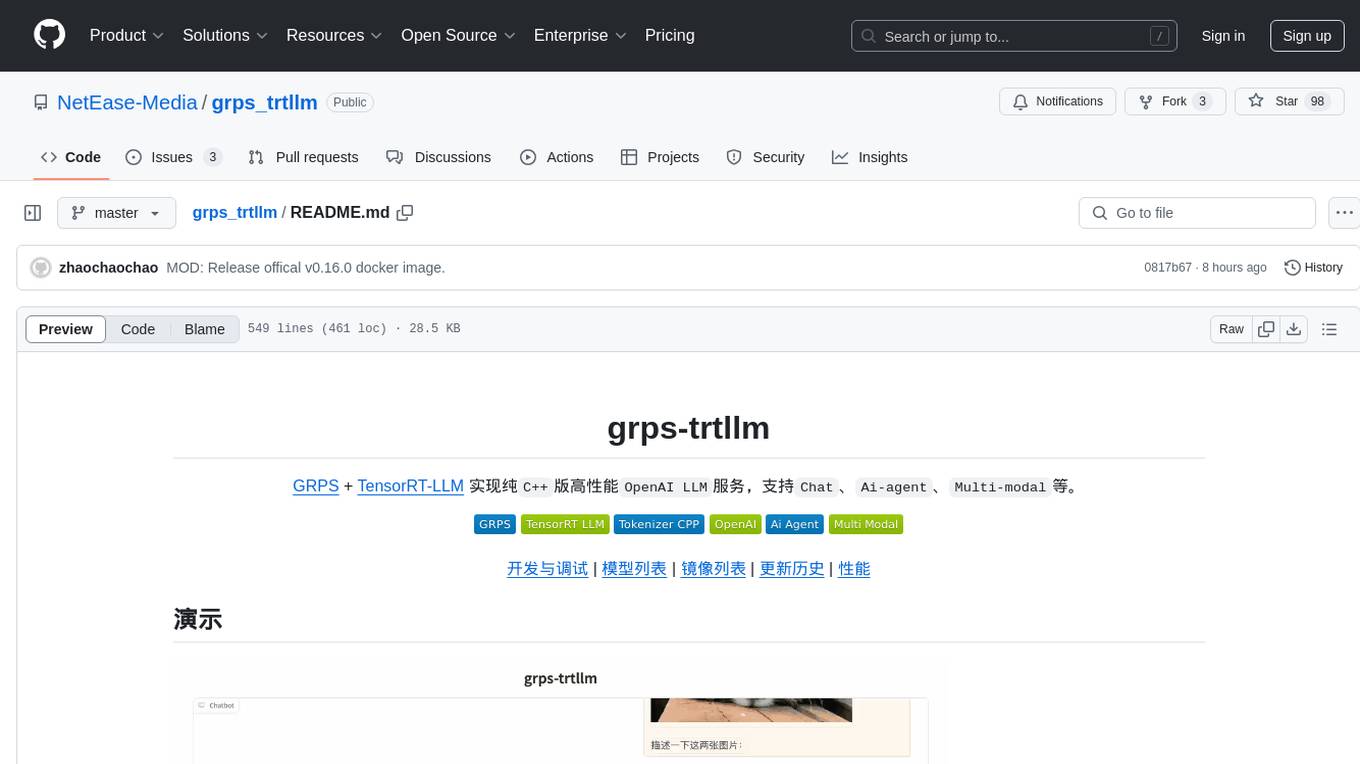
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.
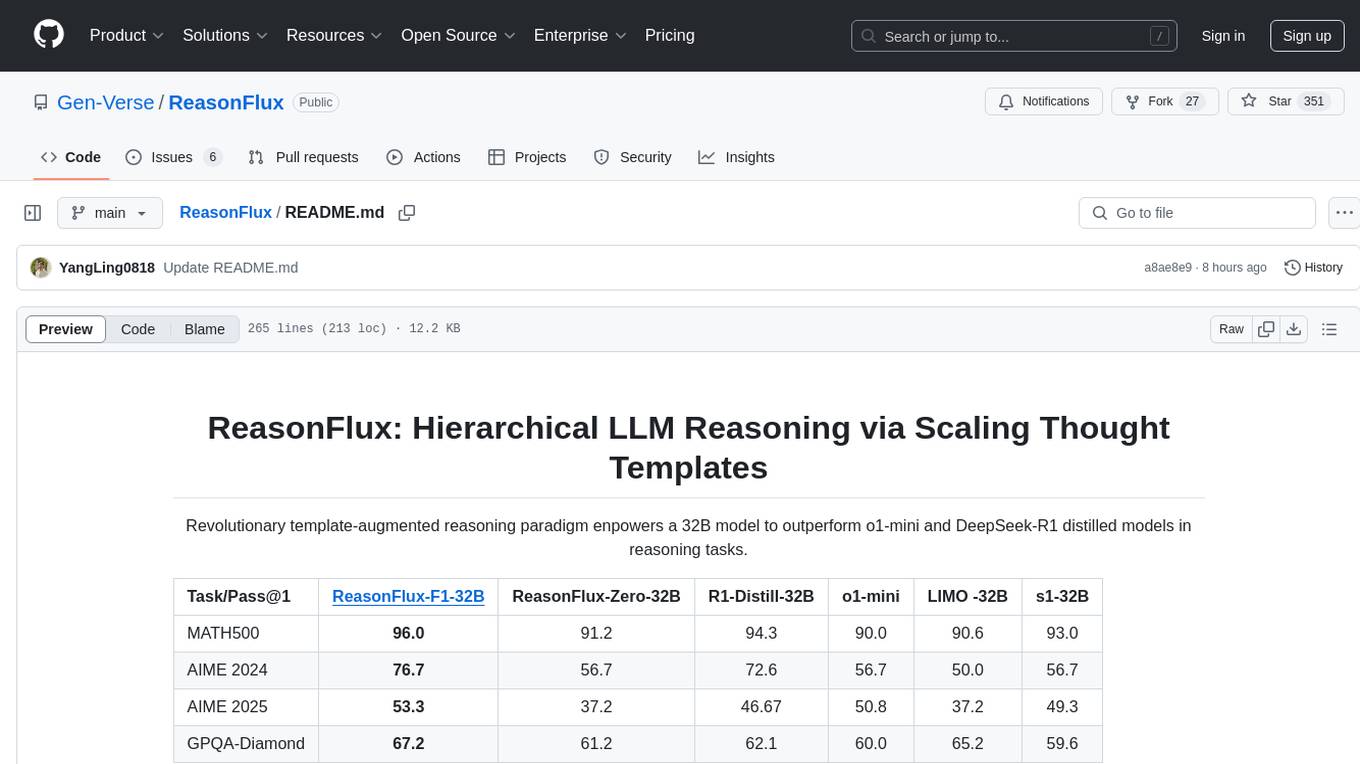
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.
terminal-bench
Terminal Bench is a simple command-line benchmark tool for Unix-like systems. It allows users to easily compare the performance of different commands or scripts by measuring their execution time. The tool provides detailed statistics and visualizations to help users analyze the results. With Terminal Bench, users can optimize their scripts and commands for better performance and efficiency.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.
ChatAFL
ChatAFL is a protocol fuzzer guided by large language models (LLMs) that extracts machine-readable grammar for protocol mutation, increases message diversity, and breaks coverage plateaus. It integrates with ProfuzzBench for stateful fuzzing of network protocols, providing smooth integration. The artifact includes modified versions of AFLNet and ProfuzzBench, source code for ChatAFL with proposed strategies, and scripts for setup, execution, analysis, and cleanup. Users can analyze data, construct plots, examine LLM-generated grammars, enriched seeds, and state-stall responses, and reproduce results with downsized experiments. Customization options include modifying fuzzers, tuning parameters, adding new subjects, troubleshooting, and working on GPT-4. Limitations include interaction with OpenAI's Large Language Models and a hard limit of 150,000 tokens per minute.
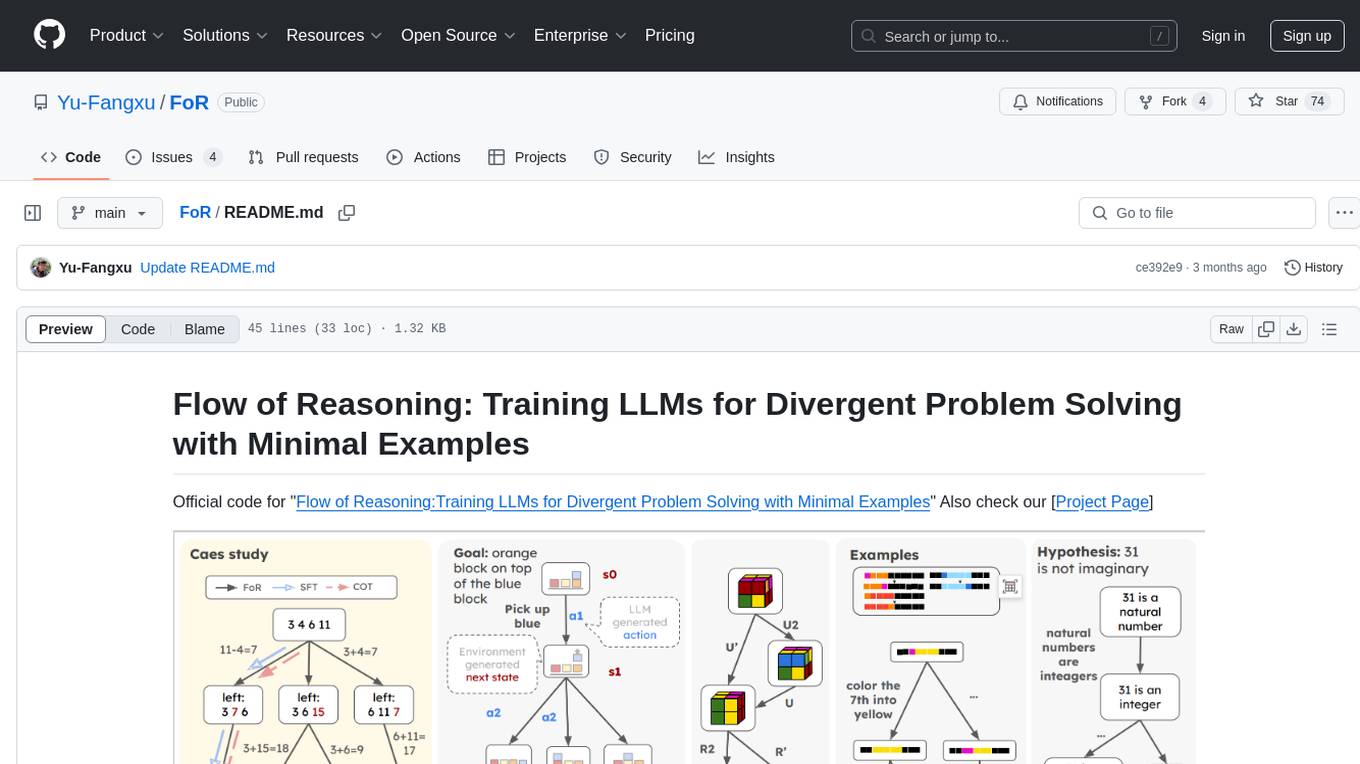
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.
For similar jobs

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.
paperbanana
PaperBanana is an automated academic illustration tool designed for AI scientists. It implements an agentic framework for generating publication-quality academic diagrams and statistical plots from text descriptions. The tool utilizes a two-phase multi-agent pipeline with iterative refinement, Gemini-based VLM planning, and image generation. It offers a CLI, Python API, and MCP server for IDE integration, along with Claude Code skills for generating diagrams, plots, and evaluating diagrams. PaperBanana is not affiliated with or endorsed by the original authors or Google Research, and it may differ from the original system described in the paper.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.