
Curator
Scalable data pre processing and curation toolkit for LLMs
Stars: 1398

NeMo Curator is a Python library designed for fast and scalable data processing and curation for generative AI use cases. It accelerates data processing by leveraging GPUs with Dask and RAPIDS, providing customizable pipelines for text and image curation. The library offers pre-built pipelines for synthetic data generation, enabling users to train and customize generative AI models such as LLMs, VLMs, and WFMs.
README:




GPU-accelerated data curation for training better AI models, faster. Scale from laptop to multi-node clusters with modular pipelines for text, images, video, and audio.
Part of the NVIDIA NeMo software suite for managing the AI agent lifecycle.
| Modality | Key Capabilities | Get Started |
|---|---|---|
| Text | Deduplication • Classification • Quality Filtering • Language Detection | Text Guide |
| Image | Aesthetic Filtering • NSFW Detection • Embedding Generation • Deduplication | Image Guide |
| Video | Scene Detection • Clip Extraction • Motion Filtering • Deduplication | Video Guide |
| Audio | ASR Transcription • Quality Assessment • WER Filtering | Audio Guide |
# Install for your modality
uv pip install "nemo-curator[text_cuda12]"
# Run the quickstart example
python tutorials/quickstart.py
Full setup: Installation Guide • Docker • Tutorials
Process and curate high-quality text datasets for large language model (LLM) training with multilingual support.
| Category | Features | Documentation |
|---|---|---|
| Data Sources | Common Crawl • Wikipedia • ArXiv • Custom datasets | Load Data |
| Quality Filtering | 30+ heuristic filters • fastText classification • GPU-accelerated classifiers for domain, quality, safety, and content type | Quality Assessment |
| Deduplication | Exact • Fuzzy (MinHash LSH) • Semantic (GPU-accelerated) | Deduplication |
| Processing | Text cleaning • Language identification | Content Processing |
Curate large-scale image datasets for vision language models (VLMs) and generative AI training.
| Category | Features | Documentation |
|---|---|---|
| Data Loading | WebDataset format • Large-scale image-text pairs | Load Data |
| Embeddings | CLIP embeddings for semantic analysis | Embeddings |
| Filtering | Aesthetic quality scoring • NSFW detection | Filters |
Process large-scale video corpora with distributed, GPU-accelerated pipelines for world foundation models (WFMs).
| Category | Features | Documentation |
|---|---|---|
| Data Loading | Local paths • S3-compatible storage • HTTP(S) URLs | Load Data |
| Clipping | Fixed-stride splitting • Scene-change detection (TransNetV2) | Clipping |
| Processing | GPU H.264 encoding • Frame extraction • Motion filtering • Aesthetic filtering | Processing |
| Embeddings | Cosmos-Embed1 for clip-level embeddings | Embeddings |
| Deduplication | K-means clustering • Pairwise similarity for near-duplicates | Deduplication |
Prepare high-quality speech datasets for automatic speech recognition (ASR) and multimodal AI training.
| Category | Features | Documentation |
|---|---|---|
| Data Loading | Local files • Custom manifests • Public datasets (FLEURS) | Load Data |
| ASR Processing | NeMo Framework pretrained models • Automatic transcription | ASR Inference |
| Quality Assessment | Word Error Rate (WER) calculation • Duration analysis • Quality-based filtering | Quality Assessment |
| Integration | Text curation workflow integration for multimodal pipelines | Text Integration |
NeMo Curator leverages NVIDIA RAPIDS™ libraries such as cuDF, cuML, and cuGraph along with Ray to scale workloads across multi-node, multi-GPU environments.
Proven Results:
- 16× faster fuzzy deduplication on 8 TB RedPajama v2 (1.78 trillion tokens)
- 40% lower total cost of ownership (TCO) compared to CPU-based alternatives
- Near-linear scaling from one to four H100 80 GB nodes (2.05 hrs → 0.50 hrs)

Data curation modules measurably improve model performance. In ablation studies using a 357M-parameter GPT model trained on curated Common Crawl data:

Results: Progressive improvements in zero-shot downstream task performance through text cleaning, deduplication, and quality filtering stages.
| Resource | Links |
|---|---|
| Documentation | Main Docs • API Reference • Concepts |
| Tutorials | Text • Image • Video • Audio |
| Deployment | Installation • Infrastructure |
| Community | GitHub Discussions • Issues |
We welcome community contributions! Please refer to CONTRIBUTING.md for guidelines.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Curator
Similar Open Source Tools
Curator
NeMo Curator is a Python library designed for fast and scalable data processing and curation for generative AI use cases. It accelerates data processing by leveraging GPUs with Dask and RAPIDS, providing customizable pipelines for text and image curation. The library offers pre-built pipelines for synthetic data generation, enabling users to train and customize generative AI models such as LLMs, VLMs, and WFMs.
Documents-Parsing-Lab
A curated collection of Jupyter notebooks for experimenting with state-of-the-art OCR, document parsing, table extraction, and chart understanding techniques. This repository enables easy benchmarking and practical usage of the latest open-source and cloud-based solutions for document image processing.
auto-dev
AutoDev Xiuper is an AI-native, multi-agent development platform built on Kotlin Multiplatform. It covers all seven phases of the software development lifecycle and runs on 8+ platforms. The platform provides a unified architecture for writing code once and running it anywhere, with specialized agents for each phase of development. It supports various devices including IntelliJ IDEA, VS Code, CLI, Web, Desktop, Android, iOS, and Server. The platform also offers features like Multi-LLM support, DevIns language for workflow automation, MCP Protocol for extensible tool ecosystem, and code intelligence for multiple programming languages.
neurolink
NeuroLink is an Enterprise AI SDK for Production Applications that serves as a universal AI integration platform unifying 13 major AI providers and 100+ models under one consistent API. It offers production-ready tooling, including a TypeScript SDK and a professional CLI, for teams to quickly build, operate, and iterate on AI features. NeuroLink enables switching providers with a single parameter change, provides 64+ built-in tools and MCP servers, supports enterprise features like Redis memory and multi-provider failover, and optimizes costs automatically with intelligent routing. It is designed for the future of AI with edge-first execution and continuous streaming architectures.
AReaL
AReaL (Ant Reasoning RL) is an open-source reinforcement learning system developed at the RL Lab, Ant Research. It is designed for training Large Reasoning Models (LRMs) in a fully open and inclusive manner. AReaL provides reproducible experiments for 1.5B and 7B LRMs, showcasing its scalability and performance across diverse computational budgets. The system follows an iterative training process to enhance model performance, with a focus on mathematical reasoning tasks. AReaL is equipped to adapt to different computational resource settings, enabling users to easily configure and launch training trials. Future plans include support for advanced models, optimizations for distributed training, and exploring research topics to enhance LRMs' reasoning capabilities.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.
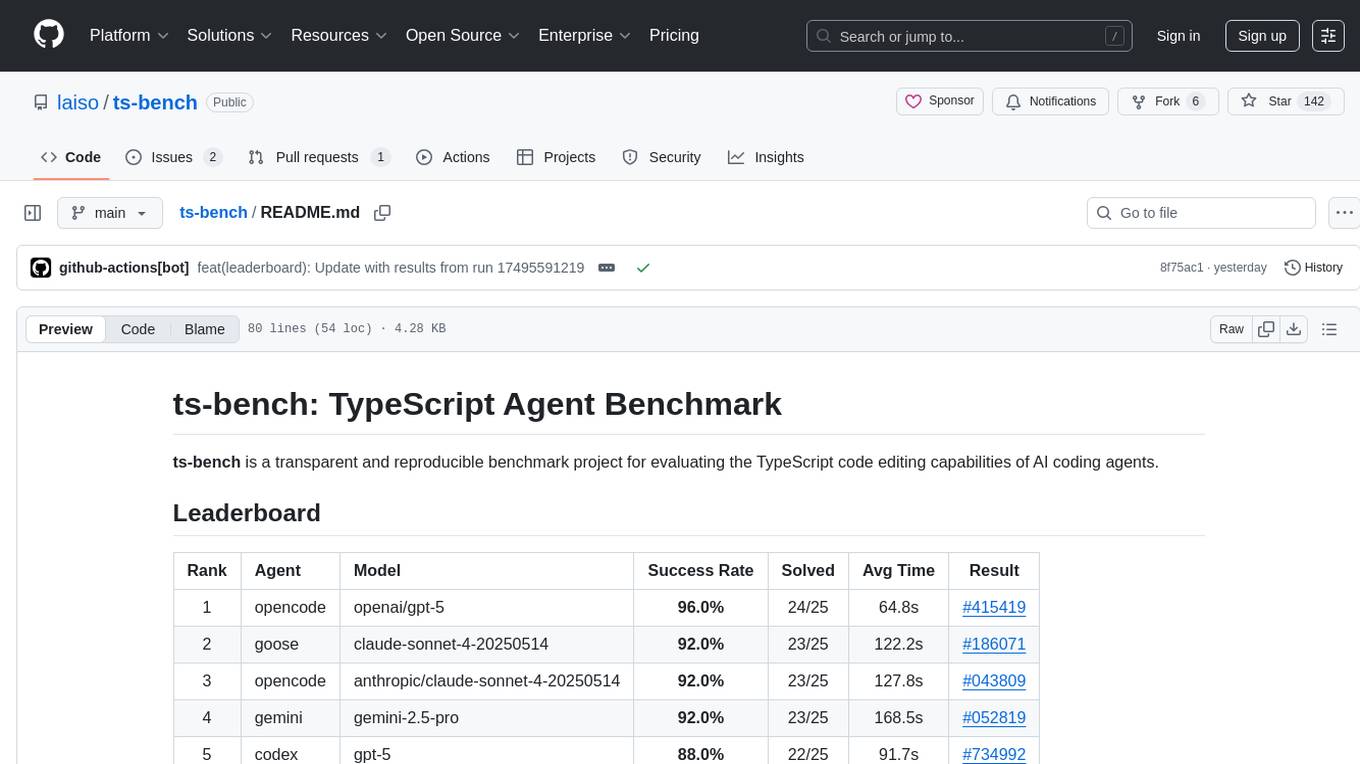
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.

motia
Motia is an AI agent framework designed for software engineers to create, test, and deploy production-ready AI agents quickly. It provides a code-first approach, allowing developers to write agent logic in familiar languages and visualize execution in real-time. With Motia, developers can focus on business logic rather than infrastructure, offering zero infrastructure headaches, multi-language support, composable steps, built-in observability, instant APIs, and full control over AI logic. Ideal for building sophisticated agents and intelligent automations, Motia's event-driven architecture and modular steps enable the creation of GenAI-powered workflows, decision-making systems, and data processing pipelines.

pai-opencode
PAI-OpenCode is a complete port of Daniel Miessler's Personal AI Infrastructure (PAI) to OpenCode, an open-source, provider-agnostic AI coding assistant. It brings modular capabilities, dynamic multi-agent orchestration, session history, and lifecycle automation to personalize AI assistants for users. With support for 75+ AI providers, PAI-OpenCode offers dynamic per-task model routing, full PAI infrastructure, real-time session sharing, and multiple client options. The tool optimizes cost and quality with a 3-tier model strategy and a 3-tier research system, allowing users to switch presets for different routing strategies. PAI-OpenCode's architecture preserves PAI's design while adapting to OpenCode, documented through Architecture Decision Records (ADRs).
BharatMLStack
BharatMLStack is a comprehensive, production-ready machine learning infrastructure platform designed to democratize ML capabilities across India and beyond. It provides a robust, scalable, and accessible ML stack empowering organizations to build, deploy, and manage machine learning solutions at massive scale. It includes core components like Horizon, Trufflebox UI, Online Feature Store, Go SDK, Python SDK, and Numerix, offering features such as control plane, ML management console, real-time features, mathematical compute engine, and more. The platform is production-ready, cloud agnostic, and offers observability through built-in monitoring and logging.
agentic-qe
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.

Athena-Public
Project Athena is a Linux OS designed for AI Agents, providing memory, persistence, scheduling, and governance for AI models. It offers a comprehensive memory layer that survives across sessions, models, and IDEs, allowing users to own their data and port it anywhere. The system is built bottom-up through 1,079+ sessions, focusing on depth and compounding knowledge. Athena features a trilateral feedback loop for cross-model validation, a Model Context Protocol server with 9 tools, and a robust security model with data residency options. The repository structure includes an SDK package, examples for quickstart, scripts, protocols, workflows, and deep documentation. Key concepts cover architecture, knowledge graph, semantic memory, and adaptive latency. Workflows include booting, reasoning modes, planning, research, and iteration. The project has seen significant content expansion, viral validation, and metrics improvements.

deepfabric
DeepFabric is a CLI tool and SDK designed for researchers and developers to generate high-quality synthetic datasets at scale using large language models. It leverages a graph and tree-based architecture to create diverse and domain-specific datasets while minimizing redundancy. The tool supports generating Chain of Thought datasets for step-by-step reasoning tasks and offers multi-provider support for using different language models. DeepFabric also allows for automatic dataset upload to Hugging Face Hub and uses YAML configuration files for flexibility in dataset generation.
holmesgpt
HolmesGPT is an AI agent designed for troubleshooting and investigating issues in cloud environments. It utilizes AI models to analyze data from various sources, identify root causes, and provide remediation suggestions. The tool offers integrations with popular cloud providers, observability tools, and on-call systems, enabling users to streamline the troubleshooting process. HolmesGPT can automate the investigation of alerts and tickets from external systems, providing insights back to the source or communication platforms like Slack. It supports end-to-end automation and offers a CLI for interacting with the AI agent. Users can customize HolmesGPT by adding custom data sources and runbooks to enhance investigation capabilities. The tool prioritizes data privacy, ensuring read-only access and respecting RBAC permissions. HolmesGPT is a CNCF Sandbox Project and is distributed under the Apache 2.0 License.

ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
For similar tasks
Curator
NeMo Curator is a Python library designed for fast and scalable data processing and curation for generative AI use cases. It accelerates data processing by leveraging GPUs with Dask and RAPIDS, providing customizable pipelines for text and image curation. The library offers pre-built pipelines for synthetic data generation, enabling users to train and customize generative AI models such as LLMs, VLMs, and WFMs.
PromptHub
PromptHub is a versatile tool for generating prompts and ideas to spark creativity and overcome writer's block. It provides a wide range of customizable prompts and exercises to inspire writers, artists, educators, and anyone looking to enhance their creative thinking. With PromptHub, users can access a diverse collection of prompts across various categories such as writing, drawing, brainstorming, and more. The tool offers a user-friendly interface and allows users to save and share their favorite prompts for future reference. Whether you're a professional writer seeking inspiration or a student looking to boost your creativity, PromptHub is the perfect companion to ignite your imagination and enhance your creative process.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.