
LLM-Pruner
[NeurIPS 2023] LLM-Pruner: On the Structural Pruning of Large Language Models. Support Llama-3/3.1, Llama-2, LLaMA, BLOOM, Vicuna, Baichuan, TinyLlama, etc.
Stars: 828

LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
README:
![]()


LLM-Pruner: On the Structural Pruning of Large Language Models [arXiv]
Xinyin Ma, Gongfan Fang, Xinchao Wang
National University of Singapore
- [x] Task-agnostic compression: The compressed LLM should retain its original ability as a multi-task solver.
- [x] Less training corpus: In this work, we use only 50k publicly available samples (alpaca) to post-train the LLM.
- [x] Efficient compression: 3 minutes for pruning and 3 hours for post-training. (You can make it longer)
- [x] Automatic structural pruning: Pruning new LLMs with minimal human effort (In progress).
- July 27, 2024: 🚀 Support GQA! Now LLM-Pruner can work on Llama3 and Llama 3.1. We are still testing the pruning results of new LLMs (Llama3, Llama3.1, Gemma) and you can find the pruning results here.
- August 30, 2023: LLM-Pruner now supports BLOOM 🌸
- August 14, 2023: Code and results for finetuning with a large-scale corpus are now available. The fine-tuned LLaMA-5.4B model achieves an average accuracy of 62.36%, closely approaching the original LLaMA-7B (63.25%).
- July 19, 2023: 🔥 LLM-Pruner now supports Llama-2-7b and Llama-2-13b (the huggingface version)
- July 18, 2023: 🚀 Support Baichuan, a bilingual LLM.
- May 20, 2023: 🎉 Code and Preprint Paper released!
- [ ] A tutorial for pruning new LLMs.
- [ ] Support
.from_pretrained()for loading the model.
Join our WeChat group for a chat:
- WeChat Group Group-2, Group-1 (500/500, FULL).
- Quick Start
- Step-by-step Instructions
- Zero-shot Evaluation
- More-Examples
- Version Information
- Limitations
- Acknowledgement
- Citation
pip install -r requirement.txt
bash script/llama_prune.sh
This script would compress the LLaMA-7B model with ~20% parameters pruned. All the pre-trained models and the dataset would be automatically downloaded, so you do not need to manually download the resource. When running this script for the first time, it will require some time to download the model and the dataset.
It takes three steps to prune an LLM:
- Discovery Stage: Discover the complicated inter-dependency in LLMs and find the minimally-removable unit, group.
- Estimation Stage: Estimate the contribution of each group to the overall performance of the model and decide which group to prune.
- Recover Stage: Fast post-training to recover model performance.
After pruning and post-training, we follow lm-evaluation-harness for evaluation.
🦙 LLaMA/Llama-2 pruning with ~20% parameters pruned:
python hf_prune.py --pruning_ratio 0.25 \
--block_wise \
--block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--pruner_type taylor \
--test_after_train \
--device cpu --eval_device cuda \
--save_ckpt_log_name llama_prune
Arguments:
-
Base model: Choose the base model from LLaMA or Llama-2 and pass thepretrained_model_name_or_pathto--base_model. The model name is used forAutoModel.from_pretrainedto load the pre-trained LLM. For example, if you want to use the llama-2 with 13 billion parameters, then passmeta-llama/Llama-2-13b-hfto--base_model. -
Pruning Strategy: Choose between block-wise, channel-wise, or layer-wise pruning using the respective command options: {--block_wise}, {--channel_wise}, {--layer_wise --layer NUMBER_OF_LAYERS}. For block-wise pruning, specify the start and end layers to be pruned. Channel-wise pruning does not require extra arguments. For layer pruning, use --layer NUMBER_OF_LAYERS to specify the desired number of layers to be kept after pruning. -
Importance Criterion: Select from l1, l2, random, or taylor using the --pruner_type argument. For the taylor pruner, choose one of the following options: vectorize, param_second, param_first, param_mix. By default, param_mix is used, which combines approximated second-order hessian and first-order gradient. If using l1, l2, or random, no extra arguments are required. -
Pruning Ratio: Specifies the pruning ratio of groups. It differs from the pruning rate of parameters, as groups are removed as the minimal units. -
DeviceandEval_device: Pruning and evaluation can be performed on different devices. Taylor-based methods require backward computation during pruning, which may require significant GPU RAM. Our implementation uses the CPU for importance estimation (also supports GPU, simply use --device cuda). eval_device is used to test the pruned model.
Details:
If you want to try Vicuna, please specify the argument --base_model to the path to vicuna weight. Please follow https://github.com/lm-sys/FastChat to get Vicuna weights.
python hf_prune.py --pruning_ratio 0.25 \
--block_wise \
--block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--pruner_type taylor \
--test_after_train \
--device cpu --eval_device cuda \
--save_ckpt_log_name llama_prune \
--base_model PATH_TO_VICUNA_WEIGHTS
Details:
Please refer to the Example/Baichuan for more details
Details:
python llama3.py --pruning_ratio 0.25 \
--device cuda --eval_device cuda \
--base_model meta-llama/Meta-Llama-3-8B-Instruct \
--block_wise --block_mlp_layer_start 4 --block_mlp_layer_end 30 \
--block_attention_layer_start 4 --block_attention_layer_end 30 \
--save_ckpt_log_name llama3_prune \
--pruner_type taylor --taylor param_first \
--max_seq_len 2048 \
--test_after_train --test_before_train --save_model
- Train using Alpaca with 50,000 samples. Here's an example of training on a single GPU:
CUDA_VISIBLE_DEVICES=X python post_training.py --prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin \
--data_path yahma/alpaca-cleaned \
--lora_r 8 \
--num_epochs 2 \
--learning_rate 1e-4 \
--batch_size 64 \
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL \
--wandb_project llama_tune
Make sure to replace PATH_TO_PRUNE_MODEL with the path to the pruned model in step 1, and replace PATH_TO_SAVE_TUNE_MODEL with the desired location where you want to save the tuned model.
- Train using MBZUAI/LaMini-instruction with 2.59M samples. Here is an example using multiple gpus for training:
deepspeed --include=localhost:1,2,3,4 post_training.py \
--prune_model prune_log/PATH_TO_PRUNE_MODEL/pytorch_model.bin \
--data_path MBZUAI/LaMini-instruction \
--lora_r 8 \
--num_epochs 3 \
--output_dir tune_log/PATH_TO_SAVE_TUNE_MODEL \
--extra_val_dataset wikitext2,ptb \
--wandb_project llmpruner_lamini_tune \
--learning_rate 5e-5 \
--cache_dataset
For the pruned model, simply use the following command to load your model.
pruned_dict = torch.load(YOUR_CHECKPOINT_PATH, map_location='cpu')
tokenizer, model = pruned_dict['tokenizer'], pruned_dict['model']
Due to the different configurations between modules in the pruned model, where certain layers may have larger width while others have undergone more pruning, it becomes impractical to load the model using the .from_pretrained() as provided by Hugging Face. Currently, we employ the torch.save to store the pruned model.
Since the pruned model has different configuration in each layer, like some layers might be wider but some layers have been pruned more, the model cannot be loaded with the .from_pretrained() in Hugging Face. Currently, we simply use the torch.save to save the pruned model and torch.load to load the pruned model.
We provide a simple script to geneate texts using pre-trained / pruned models / pruned models with post-training.
- LLaMA-7B Pre-trained
python generate.py --model_type pretrain
- Pruned Model without Post-Training
python generate.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
- Pruned Model with Post-Training
python generate.py --model_type tune_prune_LLM --ckpt <YOUR_CKPT_PATH_FOR_PRUNE_MODEL> --lora_ckpt <YOUR_CKPT_PATH_FOR_LORA_WEIGHT>
The above instructions will deploy your LLMs locally.

For evaluating the performance of the pruned model, we follow lm-evaluation-harness to evaluate the model:
- Step 1: If you only need to evaluate the pruned model, then skip this step and jump to Step 2.
This step is to arrange the files to satisfy the input requirement for
lm-evaluation-harness. The tuned checkpoint from the post-training step would be save in the following format:
- PATH_TO_SAVE_TUNE_MODEL
| - checkpoint-200
| - pytorch_model.bin
| - optimizer.pt
...
| - checkpoint-400
| - checkpoint-600
...
| - adapter_config.bin
| - adapter-config.json
Arrange the files by the following commands:
cd PATH_TO_SAVE_TUNE_MODEL
export epoch=YOUR_EVALUATE_EPOCH
cp adapter_config.json checkpoint-$epoch/
mv checkpoint-$epoch/pytorch_model.bin checkpoint-$epoch/adapter_model.bin
If you want to evaluate the checkpoint-200, then set the epoch equalts to 200 by export epoch=200.
- Step 2:
export PYTHONPATH='.'
python lm-evaluation-harness/main.py --model hf-causal-experimental \
--model_args checkpoint=PATH_TO_PRUNE_MODEL,peft=PATH_TO_SAVE_TUNE_MODEL,config_pretrained=PATH_OR_NAME_TO_BASE_MODEL \
--tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq \
--device cuda:0 --no_cache \
--output_path PATH_TO_SAVE_EVALUATION_LOG
Here, replace PATH_TO_PRUNE_MODEL and PATH_TO_SAVE_TUNE_MODEL with the path you save the pruned model and the tuned model, and PATH_OR_NAME_TO_BASE_MODEL is for loading the configuration file of the base model.
[Update]: We upload a script to simply the evaluation process if you want to evaluate the pruned model with the tuned checkpoint. Simply use the following command:
CUDA_VISIBLE_DEVICES=X bash scripts/evaluate.sh PATH_OR_NAME_TO_BASE_MODEL PATH_TO_SAVE_TUNE_MODEL PATH_TO_PRUNE_MODEL EPOCHS_YOU_WANT_TO_EVALUATE
Replace the necessary information of your model in the command. The final one is used to iterate over different epochs if you want to evaluate several checkpoints in one command. For example:
CUDA_VISIBLE_DEVICES=1 bash scripts/evaluate.sh decapoda-research/llama-7b-hf tune_log/llama_7B_hessian prune_log/llama_prune_7B 200 1000 2000
- Pre-trained
python test_speedup.py --model_type pretrain
- Pruned Model
python test_speedup.py --model_type pruneLLM --ckpt <YOUR_MODEL_PATH_FOR_PRUNE_MODEL>
A brief quantitative results for LLaMA-7B:

The results for Vicuna-7B:

The results for ChatGLM-6B:

Statistics for pruned models:

Results of LLM-Pruner with 2.59M samples:
| Pruning Ratio | #Param | Memory | Latency | Speedup | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-7B | 6.74B | 12884.5MiB | 69.32s | 1x | 73.18 | 78.35 | 72.99 | 67.01 | 67.45 | 41.38 | 42.40 | 63.25 |
| LLaMA-5.4B with Alpaca(50k) | 5.47B | 10488.4MiB | 58.55s | 1.18x | 64.62 | 77.20 | 68.80 | 63.14 | 64.31 | 36.77 | 39.80 | 59.23 |
| LLaMA-5.4B with LaMini(2.59M) | 5.47B | 10488.4MiB | 58.55s | 1.18x | 76.57 | 77.37 | 66.60 | 65.82 | 70.62 | 40.70 | 38.80 | 62.36 |
More results can be found in the paper.
| Original Model | Output | Pruned Model | Output |
|---|---|---|---|
| LLaMa-7B | The universe is the entirety of space, time, matter, and energy that exists. It includes all matter and energy, whether visible or not, and in fact the whole universe is invisible. There are many theories regarding its origin and ultimate fate... | LLaMa-5.4B | The universe is the entirety of space, time, matter, and energy that exists. The laws that make up physics — electrons orbiting atoms, magnets attracting other objects, planets orbiting the Sun—have been consistent over ... |
| Vicuna-7B | 10 steps to build an ios app: 1. Research and develop the idea. 2. Decide on the platform you want to use (iOS, Android, or both). 3. Create a plan and budget. 4. Hire a team of developers. 5. Design the user interface (UI). 6. Develop the user interface (UI). 7. Test and iterate on the app. 8. Submit the app to the app store. 9. Optimize the app for performance and user experience (UX). 10. Market and promote the app. | Vicuna-5.4B | 10 steps to build an ios app: 1. Plan your app: decide what it should do, what it will look like, and what it will cost to build it. 2. Hire a developer: A good iOS developer will help you design the user interface, create the app, and make sure it’s bug-free. 3. Create a user interface: This is where the magic happens. Your app’s user interface will be designed and mocked up at this point... |
| ChatGLM-6B | Write a poetry about love and peace. In the midst of life's hustle and bustle, I find your love a soothing peace. It is a feeling that cannot be conveyed, A connection that cannot be distanced. With your smile, your eyes, your embrace, I feel a sense of belonging that only you can give. It is a love that lasts forever, A love that cannot be defeat... | ChatGLM-5.6B | Write a poetry about love and peace. Love and peace, two such wonderful things\ A pure and endless desire in my heart\ And both of them, I must seek for\ A long, long time, I know..\ Love, I know, is a feeling of being\ A perfect partner, in every sense\ And peace, I need it, so much, one day\ A long, long way, my heart will go.. |
Due to changes in the versions of models and repos used in this project, we listed some known version issues and the specific versions needed to reproduce our method:
- lm-eval-harness: We use this commit of lm-evaluation-harness, and the code is also included in this repo. Please check Issue #25 for details.
- LLaMA1-7B: We use the checkpoint of decapoda-research/llama-7b-hf in our experiments, which is not available now. Please consider using the copied version, e.g.,baffo32/decapoda-research-llama-7B-hf.
- Although we only used 50K data and trained for three hours, more data would definitely be better. We are testing on this.
- The current compressed model still has several issues, such as generating repetitive tokens or producing nonsensical sentences. We believe there is significant room for improvement in the quality of the compressed model.
- There are still some models for which we cannot automatically identify the mapping of indexes after concatenation and view operations. Therefore, we need to perform additional manual operations.
- Logo is generated by Stable Diffusion
- The evaluation of the LLM: lm-evaluation-harness
- LLaMA: https://github.com/facebookresearch/llama
- Vicuna: https://github.com/lm-sys/FastChat
- Peft: https://github.com/huggingface/peft
- Alpaca-lora: https://github.com/tloen/alpaca-lora
If you find this project useful, please cite
@inproceedings{ma2023llmpruner,
title={LLM-Pruner: On the Structural Pruning of Large Language Models},
author={Xinyin Ma and Gongfan Fang and Xinchao Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2023},
}
@article{fang2023depgraph,
title={DepGraph: Towards Any Structural Pruning},
author={Fang, Gongfan and Ma, Xinyin and Song, Mingli and Mi, Michael Bi and Wang, Xinchao},
journal={The IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Pruner
Similar Open Source Tools
LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

SeerAttention
SeerAttention is a novel trainable sparse attention mechanism that learns intrinsic sparsity patterns directly from LLMs through self-distillation at post-training time. It achieves faster inference while maintaining accuracy for long-context prefilling. The tool offers features such as trainable sparse attention, block-level sparsity, self-distillation, efficient kernel, and easy integration with existing transformer architectures. Users can quickly start using SeerAttention for inference with AttnGate Adapter and training attention gates with self-distillation. The tool provides efficient evaluation methods and encourages contributions from the community.
open-chatgpt
Open-ChatGPT is an open-source library that enables users to train a hyper-personalized ChatGPT-like AI model using their own data with minimal computational resources. It provides an end-to-end training framework for ChatGPT-like models, supporting distributed training and offloading for extremely large models. The project implements RLHF (Reinforcement Learning with Human Feedback) powered by transformer library and DeepSpeed, allowing users to create high-quality ChatGPT-style models. Open-ChatGPT is designed to be user-friendly and efficient, aiming to empower users to develop their own conversational AI models easily.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.
model2vec
Model2Vec is a technique to turn any sentence transformer into a really small static model, reducing model size by 15x and making the models up to 500x faster, with a small drop in performance. It outperforms other static embedding models like GLoVe and BPEmb, is lightweight with only `numpy` as a major dependency, offers fast inference, dataset-free distillation, and is integrated into Sentence Transformers, txtai, and Chonkie. Model2Vec creates powerful models by passing a vocabulary through a sentence transformer model, reducing dimensionality using PCA, and weighting embeddings using zipf weighting. Users can distill their own models or use pre-trained models from the HuggingFace hub. Evaluation can be done using the provided evaluation package. Model2Vec is licensed under MIT.

WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

FlashRank
FlashRank is an ultra-lite and super-fast Python library designed to add re-ranking capabilities to existing search and retrieval pipelines. It is based on state-of-the-art Language Models (LLMs) and cross-encoders, offering support for pairwise/pointwise rerankers and listwise LLM-based rerankers. The library boasts the tiniest reranking model in the world (~4MB) and runs on CPU without the need for Torch or Transformers. FlashRank is cost-conscious, with a focus on low cost per invocation and smaller package size for efficient serverless deployments. It supports various models like ms-marco-TinyBERT, ms-marco-MiniLM, rank-T5-flan, ms-marco-MultiBERT, and more, with plans for future model additions. The tool is ideal for enhancing search precision and speed in scenarios where lightweight models with competitive performance are preferred.

ALMA
ALMA (Advanced Language Model-based Translator) is a many-to-many LLM-based translation model that utilizes a two-step fine-tuning process on monolingual and parallel data to achieve strong translation performance. ALMA-R builds upon ALMA models with LoRA fine-tuning and Contrastive Preference Optimization (CPO) for even better performance, surpassing GPT-4 and WMT winners. The repository provides ALMA and ALMA-R models, datasets, environment setup, evaluation scripts, training guides, and data information for users to leverage these models for translation tasks.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.
simple_GRPO
simple_GRPO is a very simple implementation of the GRPO algorithm for reproducing r1-like LLM thinking. It provides a codebase that supports saving GPU memory, understanding RL processes, trying various improvements like multi-answer generation, regrouping, penalty on KL, and parameter tuning. The project focuses on simplicity, performance, and core loss calculation based on Hugging Face's trl. It offers a straightforward setup with minimal dependencies and efficient training on multiple GPUs.
For similar tasks

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀

llm-resource
llm-resource is a comprehensive collection of high-quality resources for Large Language Models (LLM). It covers various aspects of LLM including algorithms, training, fine-tuning, alignment, inference, data engineering, compression, evaluation, prompt engineering, AI frameworks, AI basics, AI infrastructure, AI compilers, LLM application development, LLM operations, AI systems, and practical implementations. The repository aims to gather and share valuable resources related to LLM for the community to benefit from.
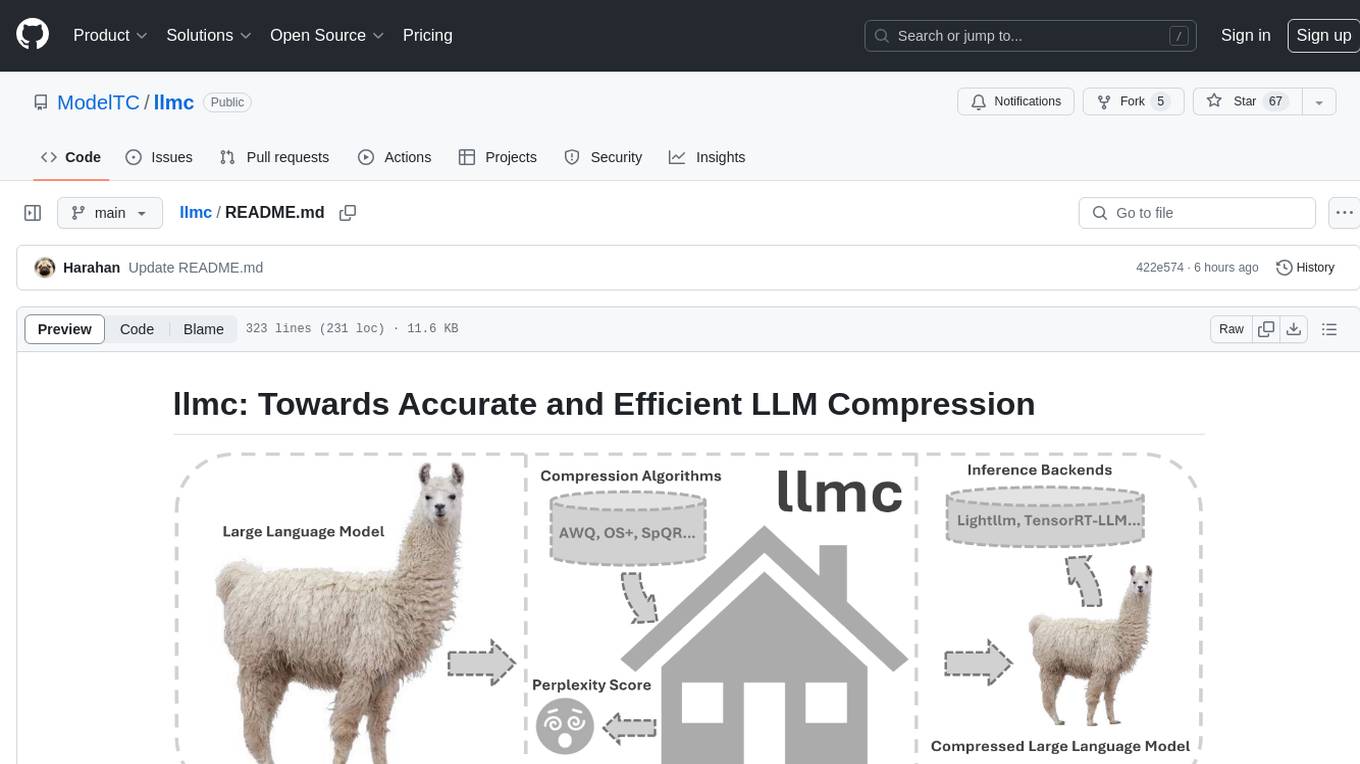
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
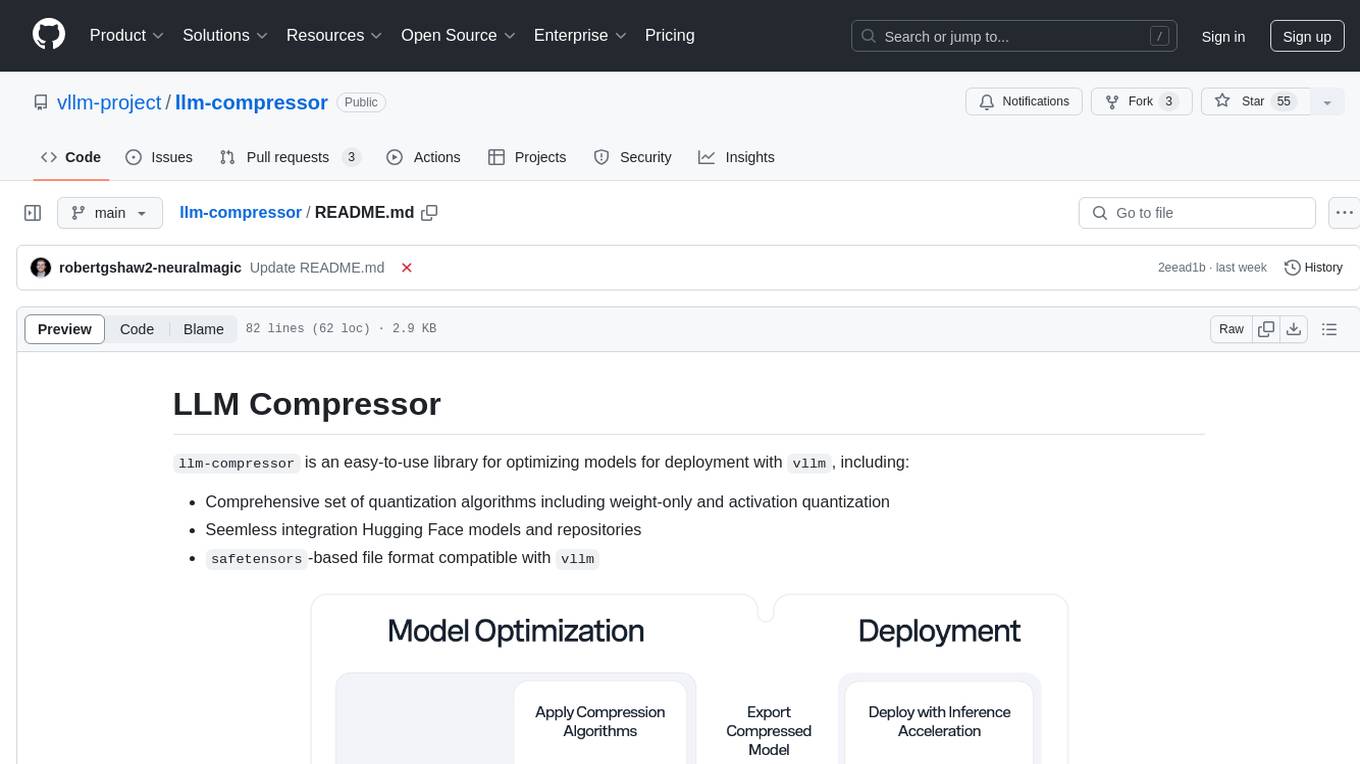
llm-compressor
llm-compressor is an easy-to-use library for optimizing models for deployment with vllm. It provides a comprehensive set of quantization algorithms, seamless integration with Hugging Face models and repositories, and supports mixed precision, activation quantization, and sparsity. Supported algorithms include PTQ, GPTQ, SmoothQuant, and SparseGPT. Installation can be done via git clone and local pip install. Compression can be easily applied by selecting an algorithm and calling the oneshot API. The library also offers end-to-end examples for model compression. Contributions to the code, examples, integrations, and documentation are appreciated.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.