
FlexFlow
FlexFlow Serve: Low-Latency, High-Performance LLM Serving
Stars: 1672

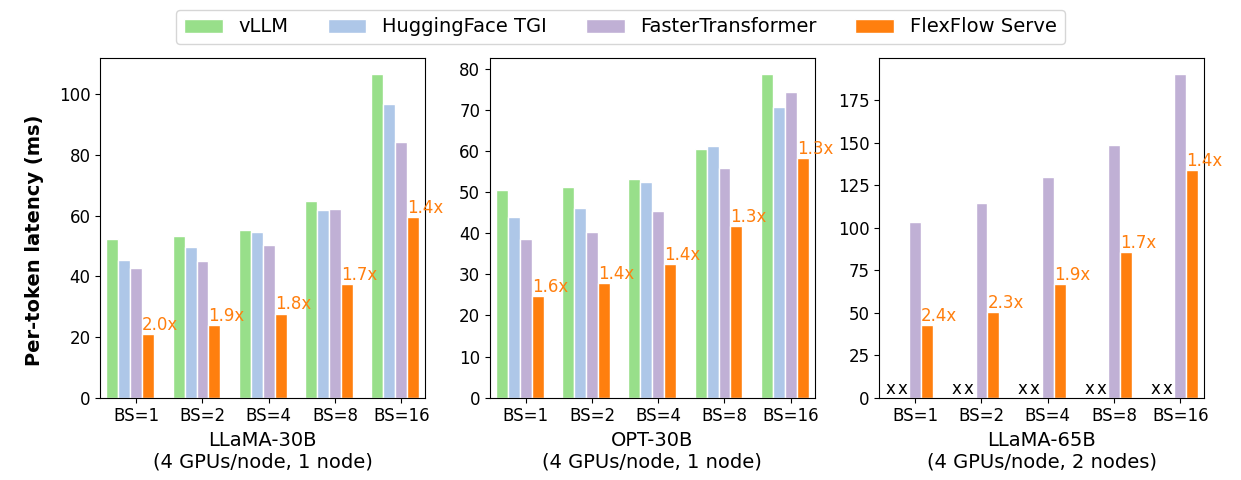
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
README:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. FlexFlow Serve is an open-source compiler and distributed system for low latency, high performance LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
- OS: Linux
- GPU backend: Hip-ROCm or CUDA
- CUDA version: 10.2 – 12.0
- NVIDIA compute capability: 6.0 or higher
- Python: 3.6 or higher
- Package dependencies: see here
You can install FlexFlow Serve using pip:
pip install flexflowIf you run into any issue during the install, or if you would like to use the C++ API without needing to install from source, you can also use our pre-built Docker package for different CUDA versions (NVIDIA backend) and multiple ROCM versions (AMD backend). To download and run our pre-built Docker container:
docker run --gpus all -it --rm --shm-size=8g ghcr.io/flexflow/flexflow-cuda-12.0:latestTo download a Docker container for a backend other than CUDA v12.0, you can replace the cuda-12.0 suffix with any of the following backends: cuda-11.1, cuda-11.2, cuda-11.3, cuda-11.4, cuda-11.5, cuda-11.6, cuda-11.7, cuda-11.8, and hip_rocm-5.3, hip_rocm-5.4, hip_rocm-5.5, hip_rocm-5.6). More info on the Docker images, with instructions to build a new image from source, or run with additional configurations, can be found here.
You can install FlexFlow Serve from source code by building the inference branch of FlexFlow. Please follow these instructions.
The following example shows how to deploy an LLM using FlexFlow Serve and accelerate its serving using speculative inference. First, we import flexflow.serve and initialize the FlexFlow Serve runtime. Note that memory_per_gpu and zero_copy_memory_per_node specify the size of device memory on each GPU (in MB) and zero-copy memory on each node (in MB), respectively.
We need to make sure the aggregated GPU memory and zero-copy memory are both sufficient to store LLM parameters in non-offloading serving. FlexFlow Serve combines tensor and pipeline model parallelism for LLM serving.
import flexflow.serve as ff
ff.init(
num_gpus=4,
memory_per_gpu=14000,
zero_copy_memory_per_node=30000,
tensor_parallelism_degree=4,
pipeline_parallelism_degree=1
)Second, we specify the LLM to serve and the SSM(s) used to accelerate LLM serving. The list of supported LLMs and SSMs is available at supported models.
# Specify the LLM
llm = ff.LLM("meta-llama/Llama-2-7b-hf")
# Specify a list of SSMs (just one in this case)
ssms=[]
ssm = ff.SSM("JackFram/llama-68m")
ssms.append(ssm)Next, we declare the generation configuration and compile both the LLM and SSMs. Note that all SSMs should run in the beam search mode, and the LLM should run in the tree verification mode to verify the speculated tokens from SSMs. You can also use the following arguments to specify serving configuration when compiling LLMs and SSMs:
- max_requests_per_batch: the maximum number of requests to serve in a batch (default: 16)
- max_seq_length: the maximum number of tokens in a request (default: 256)
- max_tokens_per_batch: the maximum number of tokens to process in a batch (default: 128)
# Create the sampling configs
generation_config = ff.GenerationConfig(
do_sample=False, temperature=0.9, topp=0.8, topk=1
)
# Compile the SSMs for inference and load the weights into memory
for ssm in ssms:
ssm.compile(generation_config)
# Compile the LLM for inference and load the weights into memory
llm.compile(generation_config,
max_requests_per_batch = 16,
max_seq_length = 256,
max_tokens_per_batch = 128,
ssms=ssms)Next, we call llm.start_server() to start an LLM server running on a seperate background thread, which allows users to perform computations in parallel with LLM serving. Finally, we call llm.generate to generate the output, which is organized as a list of GenerationResult, which include the output tokens and text. After all serving requests are processed, you can either call llm.stop_server() to terminate the background thread or directly exit the python program, which will automatically terminate the background server thread.
llm.start_server()
result = llm.generate("Here are some travel tips for Tokyo:\n")
llm.stop_server() # This invocation is optionalExpand here
import flexflow.serve as ff
# Initialize the FlexFlow runtime. ff.init() takes a dictionary or the path to a JSON file with the configs
ff.init(
num_gpus=4,
memory_per_gpu=14000,
zero_copy_memory_per_node=30000,
tensor_parallelism_degree=4,
pipeline_parallelism_degree=1
)
# Create the FlexFlow LLM
llm = ff.LLM("meta-llama/Llama-2-7b-hf")
# Create the sampling configs
generation_config = ff.GenerationConfig(
do_sample=True, temperature=0.9, topp=0.8, topk=1
)
# Compile the LLM for inference and load the weights into memory
llm.compile(generation_config,
max_requests_per_batch = 16,
max_seq_length = 256,
max_tokens_per_batch = 128)
# Generation begins!
llm.start_server()
result = llm.generate("Here are some travel tips for Tokyo:\n")
llm.stop_server() # This invocation is optionalIf you'd like to use the C++ interface (mostly used for development and benchmarking purposes), you should install from source, and follow the instructions below.
Expand here
Before running FlexFlow Serve, you should manually download the LLM and SSM(s) model of interest using the inference/utils/download_hf_model.py script (see example below). By default, the script will download all of a model's assets (weights, configs, tokenizer files, etc...) into the cache folder ~/.cache/flexflow. If you would like to use a different folder, you can request that via the parameter --cache-folder.
python3 ./inference/utils/download_hf_model.py <HF model 1> <HF model 2> ...A C++ example is available at this folder. After building FlexFlow Serve, the executable will be available at /build_dir/inference/spec_infer/spec_infer. You can use the following command-line arguments to run FlexFlow Serve:
-
-ll:gpu: number of GPU processors to use on each node for serving an LLM (default: 0) -
-ll:fsize: size of device memory on each GPU in MB -
-ll:zsize: size of zero-copy memory (pinned DRAM with direct GPU access) in MB. FlexFlow Serve keeps a replica of the LLM parameters on zero-copy memory, and therefore requires that the zero-copy memory is sufficient for storing the LLM parameters. -
-llm-model: the LLM model ID from HuggingFace (e.g. "meta-llama/Llama-2-7b-hf") -
-ssm-model: the SSM model ID from HuggingFace (e.g. "JackFram/llama-160m"). You can use multiple-ssm-models in the command line to launch multiple SSMs. -
-cache-folder: the folder -
-data-parallelism-degree,-tensor-parallelism-degreeand-pipeline-parallelism-degree: parallelization degrees in the data, tensor, and pipeline dimensions. Their product must equal the number of GPUs available on the machine. When any of the three parallelism degree arguments is omitted, a default value of 1 will be used. -
-prompt: (optional) path to the prompt file. FlexFlow Serve expects a json format file for prompts. In addition, users can also use the following API for registering requests: -
-output-file: (optional) filepath to use to save the output of the model, together with the generation latency
For example, you can use the following command line to serve a LLaMA-7B or LLaMA-13B model on 4 GPUs and use two collectively boost-tuned LLaMA-68M models for speculative inference.
./inference/spec_infer/spec_infer -ll:gpu 4 -ll:cpu 4 -ll:fsize 14000 -ll:zsize 30000 -llm-model meta-llama/Llama-2-7b-hf -ssm-model JackFram/llama-68m -prompt /path/to/prompt.json -tensor-parallelism-degree 4 --fusionA key technique that enables FlexFlow Serve to accelerate LLM serving is speculative inference, which combines various collectively boost-tuned small speculative models (SSMs) to jointly predict the LLM’s outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified against the LLM’s output in parallel using a novel tree-based parallel decoding mechanism. FlexFlow Serve uses an LLM as a token tree verifier instead of an incremental decoder, which largely reduces the end-to-end inference latency and computational requirement for serving generative LLMs while provably preserving model quality.
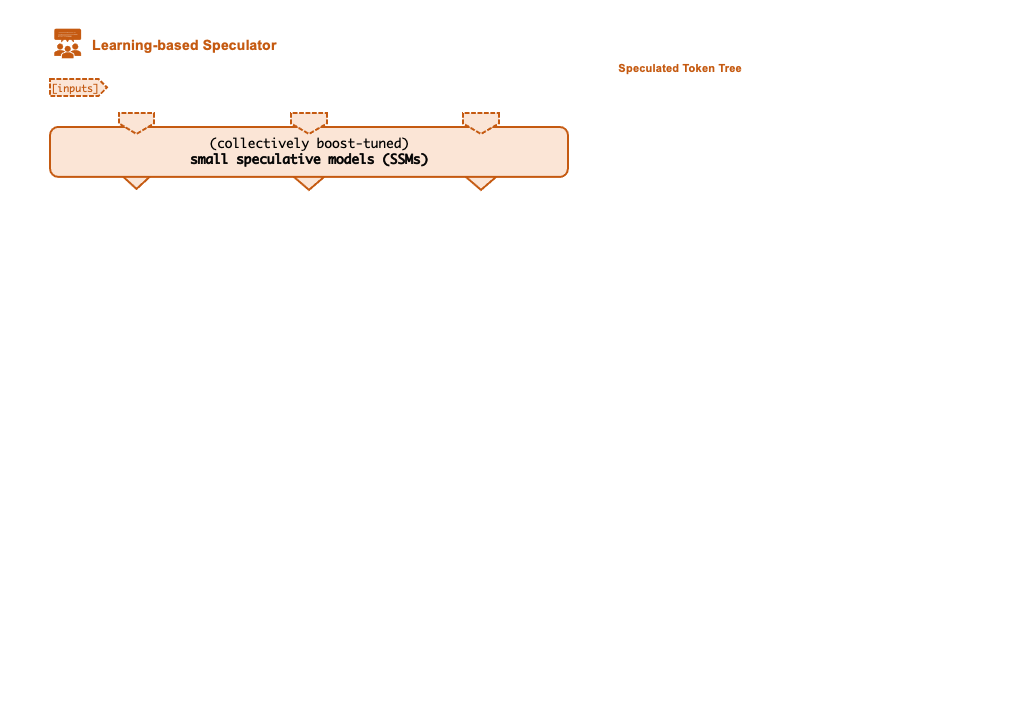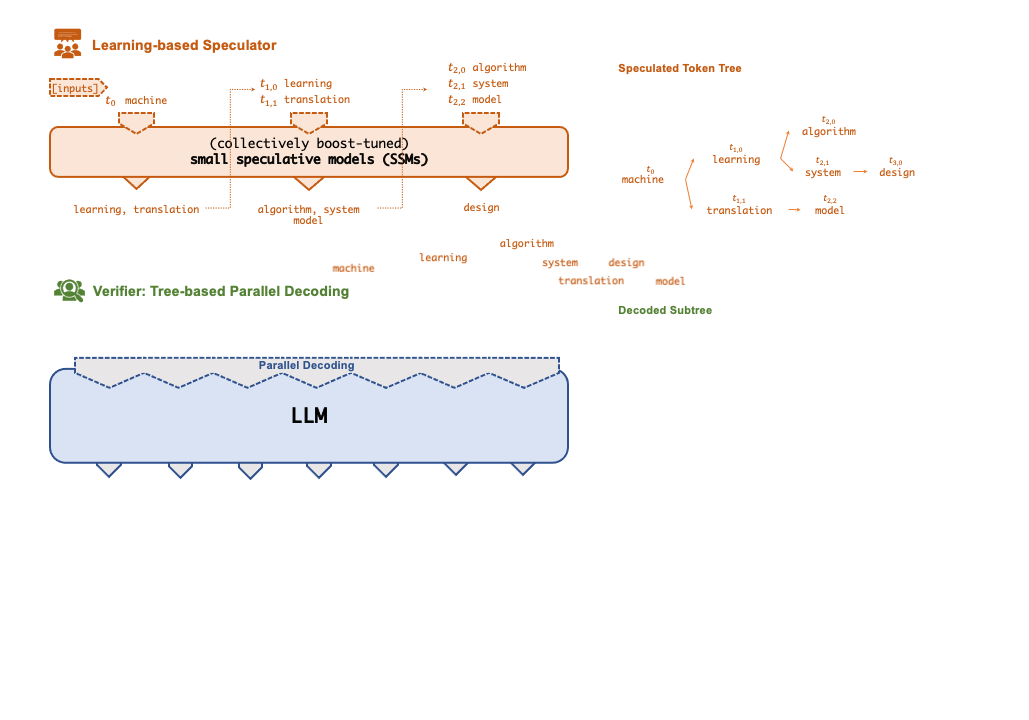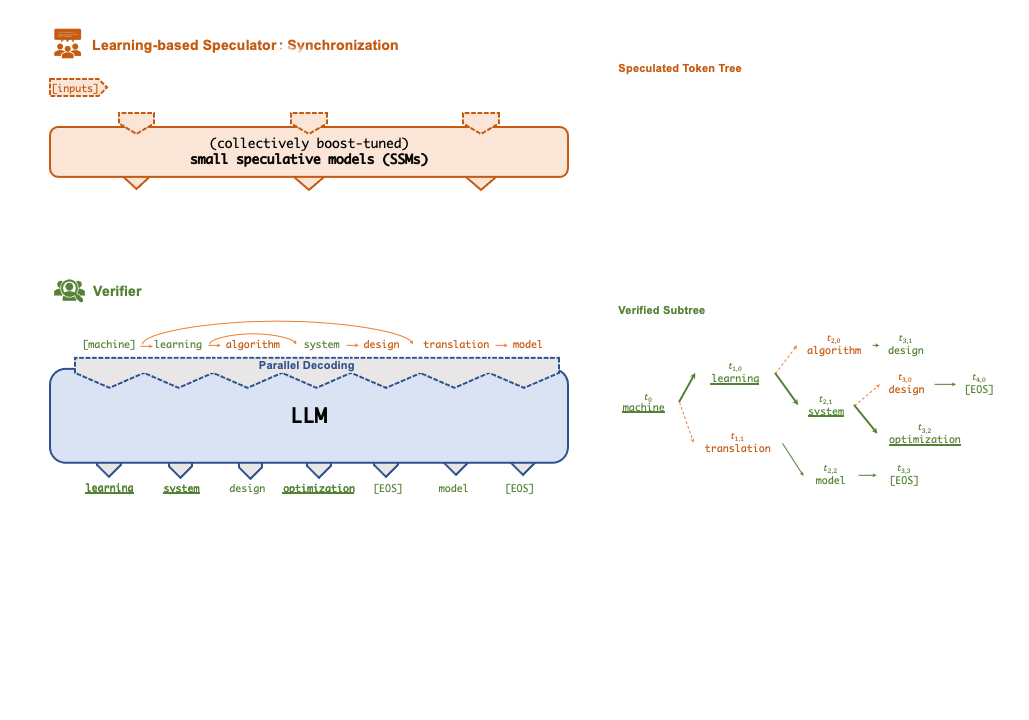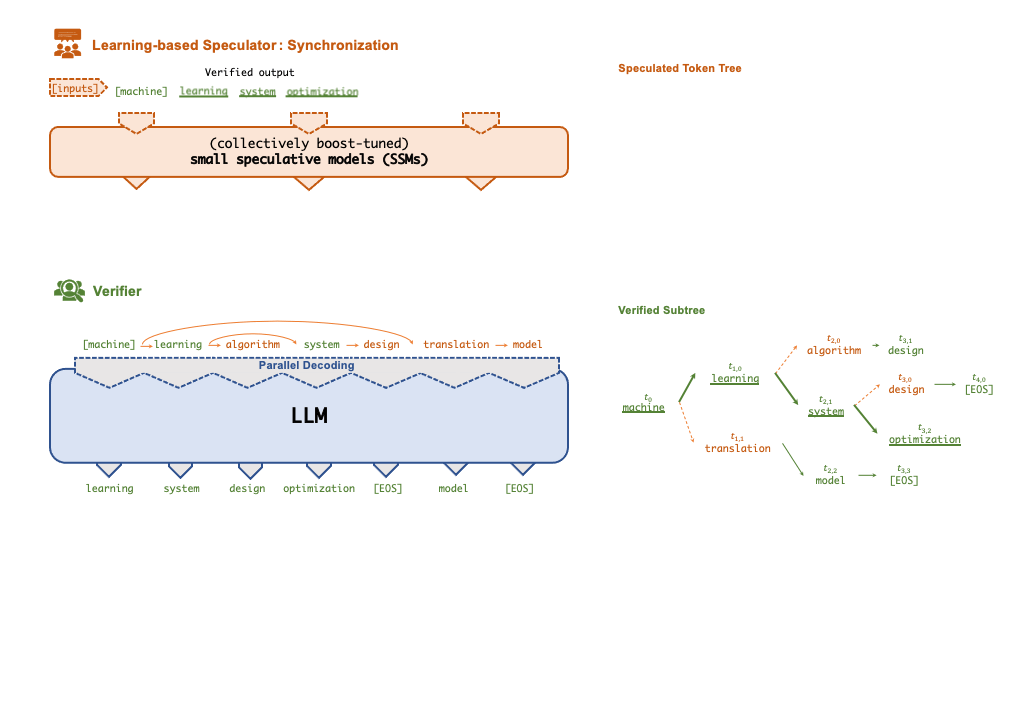
FlexFlow Serve currently supports all HuggingFace models with the following architectures:
-
LlamaForCausalLM/LLaMAForCausalLM(e.g. LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, ...) -
OPTForCausalLM(models from the OPT family) -
RWForCausalLM(models from the Falcon family) -
GPTBigCodeForCausalLM(models from the Starcoder family)
Below is a list of models that we have explicitly tested and for which a SSM may be available:
| Model | Model id on HuggingFace | Boost-tuned SSMs |
|---|---|---|
| LLaMA-7B | meta-llama/Llama-2-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-13B | decapoda-research/llama-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-30B | decapoda-research/llama-30b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-65B | decapoda-research/llama-65b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-7B | meta-llama/Llama-2-7b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-13B | meta-llama/Llama-2-13b-hf | LLaMA-68M , LLaMA-160M |
| LLaMA-2-70B | meta-llama/Llama-2-70b-hf | LLaMA-68M , LLaMA-160M |
| OPT-6.7B | facebook/opt-6.7b | OPT-125M |
| OPT-13B | facebook/opt-13b | OPT-125M |
| OPT-30B | facebook/opt-30b | OPT-125M |
| OPT-66B | facebook/opt-66b | OPT-125M |
| Falcon-7B | tiiuae/falcon-7b | |
| Falcon-40B | tiiuae/falcon-40b | |
| StarCoder-7B | bigcode/starcoderbase-7b | |
| StarCoder-15.5B | bigcode/starcoder |
FlexFlow Serve also offers offloading-based inference for running large models (e.g., llama-7B) on a single GPU. CPU offloading is a choice to save tensors in CPU memory, and only copy the tensor to GPU when doing calculation. Notice that now we selectively offload the largest weight tensors (weights tensor in Linear, Attention). Besides, since the small model occupies considerably less space, it it does not pose a bottleneck for GPU memory, the offloading will bring more runtime space and computational cost, so we only do the offloading for the large model. [TODO: update instructions] You can run the offloading example by enabling the -offload and -offload-reserve-space-size flags.
FlexFlow Serve supports int4 and int8 quantization. The compressed tensors are stored on the CPU side. Once copied to the GPU, these tensors undergo decompression and conversion back to their original precision. Please find the compressed weight files in our s3 bucket, or use this script from FlexGen project to do the compression manually.
We provide five prompt datasets for evaluating FlexFlow Serve: Chatbot instruction prompts, ChatGPT Prompts, WebQA, Alpaca, and PIQA.
FlexFlow Serve is under active development. We currently focus on the following tasks and strongly welcome all contributions from bug fixes to new features and extensions.
- AMD benchmarking. We are actively working on benchmarking FlexFlow Serve on AMD GPUs and comparing it with the performance on NVIDIA GPUs.
- Chatbot prompt templates and Multi-round conversations
- Support for FastAPI server
- Integration with LangChain for document question answering
This project is initiated by members from CMU, Stanford, and UCSD. We will be continuing developing and supporting FlexFlow Serve. Please cite FlexFlow Serve as:
@misc{miao2023specinfer,
title={SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification},
author={Xupeng Miao and Gabriele Oliaro and Zhihao Zhang and Xinhao Cheng and Zeyu Wang and Rae Ying Yee Wong and Alan Zhu and Lijie Yang and Xiaoxiang Shi and Chunan Shi and Zhuoming Chen and Daiyaan Arfeen and Reyna Abhyankar and Zhihao Jia},
year={2023},
eprint={2305.09781},
archivePrefix={arXiv},
primaryClass={cs.CL}
}FlexFlow uses Apache License 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FlexFlow
Similar Open Source Tools
FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

Easy-Translate
Easy-Translate is a script designed for translating large text files with a single command. It supports various models like M2M100, NLLB200, SeamlessM4T, LLaMA, and Bloom. The tool is beginner-friendly and offers seamless and customizable features for advanced users. It allows acceleration on CPU, multi-CPU, GPU, multi-GPU, and TPU, with support for different precisions and decoding strategies. Easy-Translate also provides an evaluation script for translations. Built on HuggingFace's Transformers and Accelerate library, it supports prompt usage and loading huge models efficiently.

Trace
Trace is a new AutoDiff-like tool for training AI systems end-to-end with general feedback. It generalizes the back-propagation algorithm by capturing and propagating an AI system's execution trace. Implemented as a PyTorch-like Python library, users can write Python code directly and use Trace primitives to optimize certain parts, similar to training neural networks.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
rag-chatbot
The RAG ChatBot project combines Lama.cpp, Chroma, and Streamlit to build a Conversation-aware Chatbot and a Retrieval-augmented generation (RAG) ChatBot. The RAG Chatbot works by taking a collection of Markdown files as input and provides answers based on the context provided by those files. It utilizes a Memory Builder component to load Markdown pages, divide them into sections, calculate embeddings, and save them in an embedding database. The chatbot retrieves relevant sections from the database, rewrites questions for optimal retrieval, and generates answers using a local language model. It also remembers previous interactions for more accurate responses. Various strategies are implemented to deal with context overflows, including creating and refining context, hierarchical summarization, and async hierarchical summarization.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.

lhotse
Lhotse is a Python library designed to make speech and audio data preparation flexible and accessible. It aims to attract a wider community to speech processing tasks by providing a Python-centric design and an expressive command-line interface. Lhotse offers standard data preparation recipes, PyTorch Dataset classes for speech tasks, and efficient data preparation for model training with audio cuts. It supports data augmentation, feature extraction, and feature-space cut mixing. The tool extends Kaldi's data preparation recipes with seamless PyTorch integration, human-readable text manifests, and convenient Python classes.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.
FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.