
MITSUHA
World's First Multilingual Inexpensive Therapeutic Sophisticated Ultra-responsive Holographic Agent. In simple terms, an AI you can talk to and it'll talk back with a body using VTube Studio.
Stars: 174

OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.
README:

Redefining Reality
Demo video with 3D printed hologram box
·
Report Bug
·
Request Feature
Table of Contents
!Please don't attempt to install this right now, the project is undergoing major changes and exllamav2 likely will throw many errors!
 Click on image for demo video
Click on image for demo video
A virtual waifu / assistant that you can speak to through your mic and it'll speak back to you! Has many features such as:
- You can speak to her with a mic
- It can speak back to you
- Has short-term memory and long-term memory
- Can open apps
- Smarter than you
- Fluent in English, Japanese, Korean, and Chinese
- Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites)
More features I'm planning to add soon in the Roadmap. Also, here's a summary of how it works for those of you who want to know:
First, the Python package SpeechRecognition recognizes what you say into your mic, then that speech is written into an audio (.wav) file, which is sent to OpenAI's Whisper speech-to-text transcription AI, and the transcribed result is printed in the terminal and written in a conversation.jsonl which the vector database hyperdb uses cosine similarity on to find 2 of the closest matches to what you said in the conversation.jsonl and appends that to the prompt to give Megumin context, the response is then passed through multiple NLE RTE and other checks to see if you want to open an app or do something with your smarthome, the prompt is then sent to llama.cpp, and the response from Megumin is printed to the terminal and appended to conversation.jsonl, and finally, the response is spoken by VITS TTS.
- Python
- Llama-cpp-python
- Whisper
- SpeechRecognition
- PocketSphinx
- VITS-fast-fine-tuning
- VITS-simple-api
- HyperDB
- Sentence Transformers
- Tuya Cloud IoT
- Install Python 3.10.11 and set it as an environment variable in PATH
- Install GIT
- Install CUDA 11.7 if you have an Nvidia GPU
-
Install Visual Studio Community 2022 and select
Desktop Development with C++in the install options - Install VTube Studio on Steam
- Download Megumin's VTube Studio Model
- Extract the downloaded zip so it's only one folder deep (you should be able to open the folder and have all the files there, not one folder containing everything)
- Open VTube Studio > Settings icon >
Open Data Folderand move the folder there > Person icon > c001_f_costume_kouma - Install VB Cable Audio Driver, but don't set it as your audio devices just yet
- Open Control Panel > Sound and Hardware > Sound > Recording > find CABLE Output > right-click > Properties > Listen > Check
Listen to this device> ForPlayback through this device, select your headphones or speakers - (Optional) Create a Tuya cloud project if you want to control your smart devices with the AI, for example, you can say 'Hey Megumin, can you turn on my LEDs' it's a bit complicated though and I'll probably make a video on it later because it's hard to explain through text, but here's a guide that should help you out: https://developer.tuya.com/en/docs/iot/device-control-practice?id=Kat1jdeul4uf8
- Open cmd in whatever folder you want the project to be in, and run
git clone --recurse-submodules https://github.com/DogeLord081/OneReality.git - Open the folder and run
python setup.pyand follow the instructions - Edit the variables in
.envif you must - Run
OneReality.batand while it's running, open the start menu and typeSound Mixer Optionsand open it. You might have to wait and make Megumin say something first, but you should see Python in the App Volume list - Change the output to
CABLE Input (VB-Audio Virtual Cable) - Open VTube Studio > Settings icon > Scroll to Microphone Settings > Select Microphone > CABLE Output (VB-Audio Virtual Cable) > Person with settings icon > Scroll to Mouth Smile > Copy these settings > Scroll to Mouth Open > Copy these settings
- Open
Sound Mixer Optionsagain and change the input for VTube Studio toCABLE Output (VB-Audio Virtual Cable) - May need to restart computer if lip sync doesn't work
- You're good to go! If you run into any issues, let me know on Discord and I can help you. Once again, it's https://discord.gg/PN48PZEXJS
- When you want to stop, say goodbye, bye, or see you somewhere in your sentence because that automatically ends the program, otherwise you can just ctrl + c or close the window
- [x] Long-term memory
- [x] Time and date awareness
- [ ] Virtual reality / augmented reality / mixed reality integration
- [x] Gatebox-style hologram
- [ ] Animatronic body
- [x] Alexa-like smart home control
- [ ] More languages for the AI's voice
- [x] Japanese
- [x] English
- [x] Korean
- [x] Chinese
- [ ] Spanish
- [ ] Indonesian
- [ ] Mobile version
- [x] Easier setup
- [ ] Compiling into one exe
- [x] Localized
- [ ] VTube Studio lip-sync without driver like in this project but I don't really understand the VTube Studio API used here
Distributed under the GNU General Public License v3.0 License. See LICENSE.txt for more information.
E-mail: [email protected]
YouTube: https://www.be.com/@OneReality-tb4ut
Discord: https://discord.gg/PN48PZEXJS
Project Link: https://github.com/DogeLord081/OneReality
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MITSUHA
Similar Open Source Tools
MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.
Kuebiko
Kuebiko is a Twitch Chat Bot that reads twitch chat and generates text-to-speech responses using Google Cloud API and OpenAI's GPT-3 text completion model. It allows users to set up their own VTuber AI similar to 'Neuro-Sama'. The project is built with Python and requires setting up various API keys and configurations to enable the bot functionality. Users can customize the voice of their VTuber and route audio using VBAudio Cable. Kuebiko provides a unique way to interact with viewers through chat responses and captions in OBS.
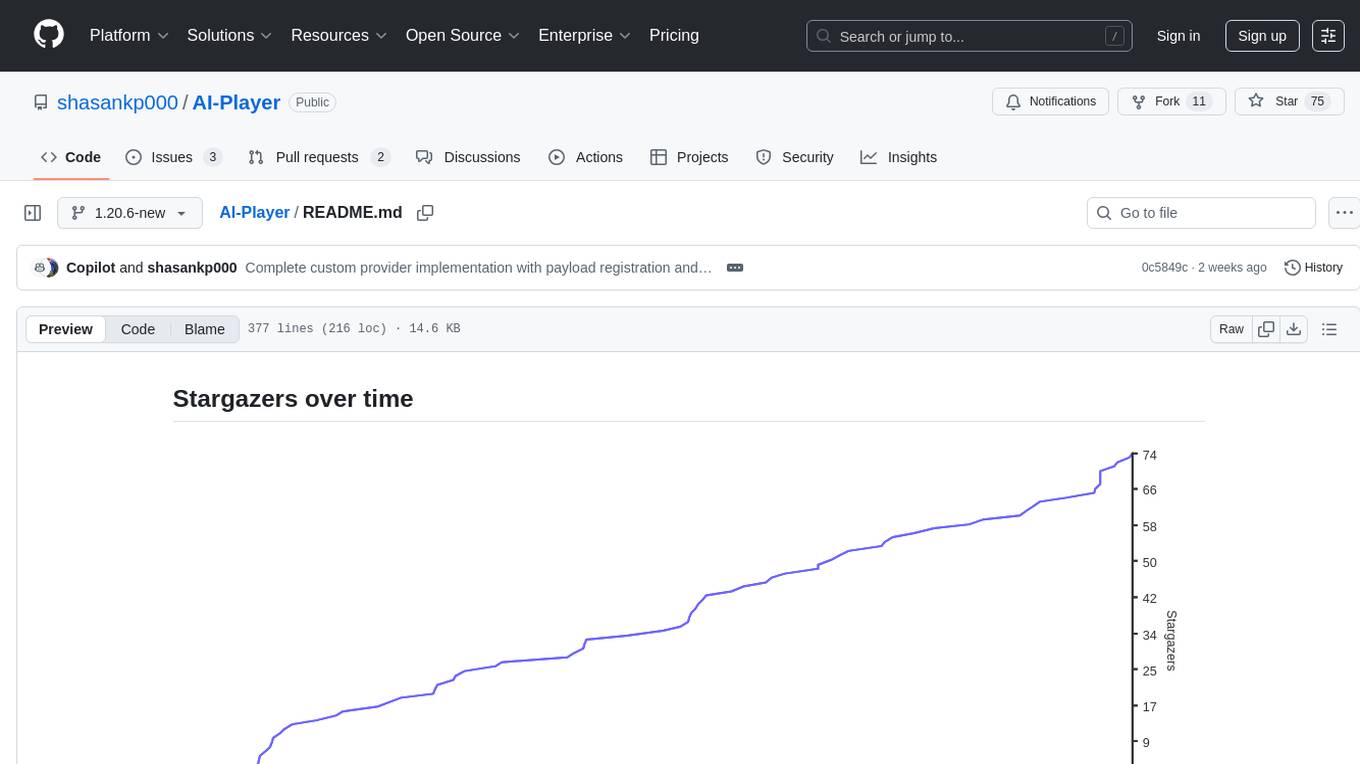
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.
voice-chat-ai
Voice Chat AI is a project that allows users to interact with different AI characters using speech. Users can choose from various characters with unique personalities and voices, and have conversations or role play with them. The project supports OpenAI, xAI, or Ollama language models for chat, and provides text-to-speech synthesis using XTTS, OpenAI TTS, or ElevenLabs. Users can seamlessly integrate visual context into conversations by having the AI analyze their screen. The project offers easy configuration through environment variables and can be run via WebUI or Terminal. It also includes a huge selection of built-in characters for engaging conversations.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
Helios
Helios is a powerful open-source tool for managing and monitoring your Kubernetes clusters. It provides a user-friendly interface to easily visualize and control your cluster resources, including pods, deployments, services, and more. With Helios, you can efficiently manage your containerized applications and ensure high availability and performance of your Kubernetes infrastructure.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.
Dough
Dough is a tool for crafting videos with AI, allowing users to guide video generations with precision using images and example videos. Users can create guidance frames, assemble shots, and animate them by defining parameters and selecting guidance videos. The tool aims to help users make beautiful and unique video creations, providing control over the generation process. Setup instructions are available for Linux and Windows platforms, with detailed steps for installation and running the app.
thread
Thread is an AI-powered Jupyter alternative that integrates an AI copilot into your editing experience. It offers a familiar Jupyter Notebook editing experience with features like natural language code edits, generating cells to answer questions, context-aware chat sidebar, and automatic error explanations or fixes. The tool aims to enhance code editing and data exploration by providing a more interactive and intuitive experience for users. Thread can be used for free with Ollama or your own API key, and it runs locally for convenience and privacy.
obsidian-chat-cbt-plugin
ChatCBT is an AI-powered journaling assistant for Obsidian, inspired by cognitive behavioral therapy (CBT). It helps users reframe negative thoughts and rewire reactions to distressful situations. The tool provides kind and objective responses to uncover negative thinking patterns, store conversations privately, and summarize reframed thoughts. Users can choose between a cloud-based AI service (OpenAI) or a local and private service (Ollama) for handling data. ChatCBT is not a replacement for therapy but serves as a journaling assistant to help users gain perspective on their problems.

Sentient
Sentient is a personal, private, and interactive AI companion developed by Existence. The project aims to build a completely private AI companion that is deeply personalized and context-aware of the user. It utilizes automation and privacy to create a true companion for humans. The tool is designed to remember information about the user and use it to respond to queries and perform various actions. Sentient features a local and private environment, MBTI personality test, integrations with LinkedIn, Reddit, and more, self-managed graph memory, web search capabilities, multi-chat functionality, and auto-updates for the app. The project is built using technologies like ElectronJS, Next.js, TailwindCSS, FastAPI, Neo4j, and various APIs.
merlinn
Merlinn is an open-source AI-powered on-call engineer that automatically jumps into incidents & alerts, providing useful insights and RCA in real time. It integrates with popular observability tools, lives inside Slack, offers an intuitive UX, and prioritizes security. Users can self-host Merlinn, use it for free, and benefit from automatic RCA, Slack integration, integrations with various tools, intuitive UX, and security features.
leon
Leon is an open-source personal assistant who can live on your server. He does stuff when you ask him to. You can talk to him and he can talk to you. You can also text him and he can also text you. If you want to, Leon can communicate with you by being offline to protect your privacy.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.
oh-my-opencode
OhMyOpenCode is a free and open-source tool that enhances coding productivity by providing an agent harness for orchestrating multiple models and tools. It offers features like background agents, LSP/AST tools, curated MCPs, and compatibility with various agents like Claude Code. The tool aims to boost productivity, automate tasks, and streamline the coding process for users. It is highly extensible and customizable, catering to both hackers and non-hackers alike, with a focus on enhancing the development experience and performance.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.
For similar tasks
MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

bedrock-claude-chat
This repository is a sample chatbot using the Anthropic company's LLM Claude, one of the foundational models provided by Amazon Bedrock for generative AI. It allows users to have basic conversations with the chatbot, personalize it with their own instructions and external knowledge, and analyze usage for each user/bot on the administrator dashboard. The chatbot supports various languages, including English, Japanese, Korean, Chinese, French, German, and Spanish. Deployment is straightforward and can be done via the command line or by using AWS CDK. The architecture is built on AWS managed services, eliminating the need for infrastructure management and ensuring scalability, reliability, and security.
For similar jobs

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.
MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.