
pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment
Stars: 118

Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
README:
![]()





Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
Pebblo has these components.
- Pebblo Server - a REST api application with topic-classifier, entity-classifier and reporting features
- Pebblo SafeLoader - a thin wrapper to Gen-AI framework's data loaders
- Pebblo SafeRetriever - a retrieval QA chain that enforces identity and semantic rules on Vector database retrieval before LLM inference
pip install pebblo --extra-index-url https://packages.daxa.ai/simple/Alternatively, download and install the latest Pebblo python .whl package from URL https://packages.daxa.ai/pebblo/0.1.13/pebblo-0.1.13-py3-none-any.whl
Example:
curl -LO "https://packages.daxa.ai/pebblo/0.1.13/pebblo-0.1.13-py3-none-any.whl"
pip install pebblo-0.1.13-py3-none-any.whlpebbloPebblo Server now listens to localhost:8000 to accept Gen-AI application data snippets for inspection and reporting.
-
--config <file>: specify a configuration file in yaml format.
See configuration guide for knobs to control Pebblo Server behavior like enabling snippet anonymization, selecting specific report renderer, etc.
docker run -p 8000:8000 docker.daxa.ai/daxaai/pebbloLocal UI can be accessed by pointing the browser to https://localhost:8000.
See installation guide for details on how to pass custom config.yaml and accessing PDF reports in the host machine.
Refer to troubleshooting guide.
Pebblo SafeLoader is natively supported in Langchain framework. It is available in Langchain versions >=0.1.7
Add PebbloSafeLoader wrapper to the existing Langchain document loader(s) used in the RAG application. PebbloSafeLoader is interface compatible with Langchain BaseLoader. The application can continue to use load() and lazy_load() methods as it would on a Langchain document loader.
Here is the snippet of Langchain RAG application using CSVLoader before enabling PebbloSafeLoader.
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(file_path)
documents = loader.load()
vectordb = Chroma.from_documents(documents, OpenAIEmbeddings())The Pebblo SafeLoader can be enabled with few lines of code change to the above snippet.
from langchain_community.document_loaders import CSVLoader
from langchain_community.document_loaders.pebblo import PebbloSafeLoader
loader = PebbloSafeLoader(
CSVLoader(file_path),
name="acme-corp-rag-1", # App name (Mandatory)
owner="Joe Smith", # Owner (Optional)
description="Support productivity RAG application", # Description (Optional)
)
documents = loader.load()
vectordb = Chroma.from_documents(documents, OpenAIEmbeddings())See here for samples with Pebblo SafeLoader enabled RAG applications and this document for more details.
PebbloRetrievalQA chain uses a SafeRetrieval to enforce that the snippets used for in-context are retrieved only from the documents authorized for the user and semantically allowed for the Gen-AI application.
Here is a sample code for the PebbloRetrievalQA with authorized_identities from the user accessing the RAG
application, passed in auth_context.
from langchain_community.chains import PebbloRetrievalQA
from langchain_community.chains.pebblo_retrieval.models import AuthContext, ChainInput
safe_rag_chain = PebbloRetrievalQA.from_chain_type(
llm=llm,
app_name="pebblo-safe-retriever-demo",
owner="Joe Smith",
description="Safe RAG demo using Pebblo",
chain_type="stuff",
retriever=vectordb.as_retriever(),
verbose=True,
)
def ask(question: str, auth_context: dict):
auth_context_obj = AuthContext(**auth_context)
chain_input_obj = ChainInput(query=question, auth_context=auth_context_obj)
return safe_rag_chain.invoke(chain_input_obj.dict())See here for samples with Pebblo SafeRetriever enabled RAG applications and this document for more details.
Pebblo is a open-source community project. If you want to contribute see Contributor Guidelines for more details.
Pebblo is released under the MIT License
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pebblo
Similar Open Source Tools
pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.

raglite
RAGLite is a Python toolkit for Retrieval-Augmented Generation (RAG) with PostgreSQL or SQLite. It offers configurable options for choosing LLM providers, database types, and rerankers. The toolkit is fast and permissive, utilizing lightweight dependencies and hardware acceleration. RAGLite provides features like PDF to Markdown conversion, multi-vector chunk embedding, optimal semantic chunking, hybrid search capabilities, adaptive retrieval, and improved output quality. It is extensible with a built-in Model Context Protocol server, customizable ChatGPT-like frontend, document conversion to Markdown, and evaluation tools. Users can configure RAGLite for various tasks like configuring, inserting documents, running RAG pipelines, computing query adapters, evaluating performance, running MCP servers, and serving frontends.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.

context7
Context7 is a powerful tool for analyzing and visualizing data in various formats. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With advanced features such as data filtering, aggregation, and customization, Context7 is suitable for both beginners and experienced data analysts. The tool supports a wide range of data sources and formats, making it versatile for different use cases. Whether you are working on exploratory data analysis, data visualization, or data storytelling, Context7 can help you uncover valuable insights and communicate your findings effectively.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.

plexe
Plexe is a tool that allows users to create machine learning models by describing them in plain language. Users can explain their requirements, provide a dataset, and the AI-powered system will build a fully functional model through an automated agentic approach. It supports multiple AI agents and model building frameworks like XGBoost, CatBoost, and Keras. Plexe also provides Docker images with pre-configured environments, YAML configuration for customization, and support for multiple LiteLLM providers. Users can visualize experiment results using the built-in Streamlit dashboard and extend Plexe's functionality through custom integrations.
SciPIP
SciPIP is a scientific paper idea generation tool powered by a large language model (LLM) designed to assist researchers in quickly generating novel research ideas. It conducts a literature review based on user-provided background information and generates fresh ideas for potential studies. The tool is designed to help researchers in various fields by providing a GUI environment for idea generation, supporting NLP, multimodal, and CV fields, and allowing users to interact with the tool through a web app or terminal. SciPIP uses Neo4j as its database and provides functionalities for generating new ideas, fetching papers, and constructing the database.
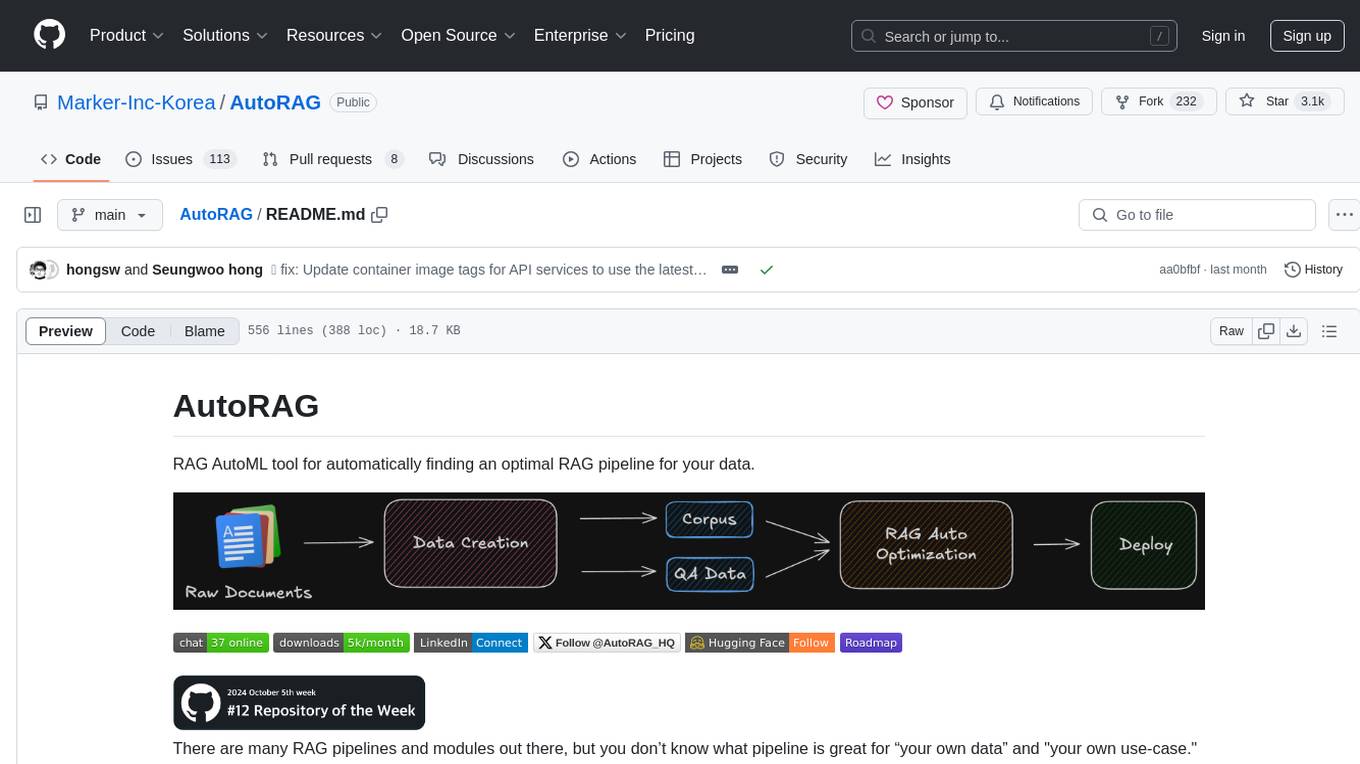
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
For similar tasks
runhouse
Runhouse is a tool that allows you to build, run, and deploy production-quality AI apps and workflows on your own compute. It provides simple, powerful APIs for the full lifecycle of AI development, from research to evaluation to production to updates to scaling to management, and across any infra. By automatically packaging your apps into scalable, secure, and observable services, Runhouse can also turn otherwise redundant AI activities into common reusable components across your team or company, which improves cost, velocity, and reproducibility.
pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.

marvin
Marvin is a lightweight AI toolkit for building natural language interfaces that are reliable, scalable, and easy to trust. Each of Marvin's tools is simple and self-documenting, using AI to solve common but complex challenges like entity extraction, classification, and generating synthetic data. Each tool is independent and incrementally adoptable, so you can use them on their own or in combination with any other library. Marvin is also multi-modal, supporting both image and audio generation as well using images as inputs for extraction and classification. Marvin is for developers who care more about _using_ AI than _building_ AI, and we are focused on creating an exceptional developer experience. Marvin users should feel empowered to bring tightly-scoped "AI magic" into any traditional software project with just a few extra lines of code. Marvin aims to merge the best practices for building dependable, observable software with the best practices for building with generative AI into a single, easy-to-use library. It's a serious tool, but we hope you have fun with it. Marvin is open-source, free to use, and made with 💙 by the team at Prefect.

deep-seek
DeepSeek is a new experimental architecture for a large language model (LLM) powered internet-scale retrieval engine. Unlike current research agents designed as answer engines, DeepSeek aims to process a vast amount of sources to collect a comprehensive list of entities and enrich them with additional relevant data. The end result is a table with retrieved entities and enriched columns, providing a comprehensive overview of the topic. DeepSeek utilizes both standard keyword search and neural search to find relevant content, and employs an LLM to extract specific entities and their associated contents. It also includes a smaller answer agent to enrich the retrieved data, ensuring thoroughness. DeepSeek has the potential to revolutionize research and information gathering by providing a comprehensive and structured way to access information from the vastness of the internet.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together

spaCy
spaCy is an industrial-strength Natural Language Processing (NLP) library in Python and Cython. It incorporates the latest research and is designed for real-world applications. The library offers pretrained pipelines supporting 70+ languages, with advanced neural network models for tasks such as tagging, parsing, named entity recognition, and text classification. It also facilitates multi-task learning with pretrained transformers like BERT, along with a production-ready training system and streamlined model packaging, deployment, and workflow management. spaCy is commercial open-source software released under the MIT license.

lima
LIMA is a multilingual linguistic analyzer developed by the CEA LIST, LASTI laboratory. It is Free Software available under the MIT license. LIMA has state-of-the-art performance for more than 60 languages using deep learning modules. It also includes a powerful rules-based mechanism called ModEx for extracting information in new domains without annotated data.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.