
llm-detect-ai
1st Place Solution for LLM - Detect AI Generated Text Kaggle Competition
Stars: 116
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.
README:
This repo contains our code and configurations for the LLM - Detect AI Generated Text competition. The summary of the solution is posted here. Please refer to the following sections for details on training and dependencies.
Jarvislabs.ai was our primary source of compute. Specifically, models were trained on the following instance:
Ubuntu 20.04.5 LTS (128 GB boot disk) Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz (7 vCPUs) 4 x NVIDIA A100 40GB GPU OR 4 x NVIDIA A6000 48GB GPU
I used PyTorch-2.1 image from Jarvislabs.ai, which comes with:
- Python 3.10.11
- CUDA 12.3
Please clone the repository and install the required packages using the following commands:
git clone https://github.com/rbiswasfc/llm-detect-ai.git
cd llm-detect-ai
pip install -r requirements.txt
Please make sure Kaggle API is installed. Then run the following script to download the required datasets:
chmod +x ./setup.sh
./setup.sh
Please note that the above script will create datasets and models folder in the directory located one level above the current directory. The external datasets will be downloaded in the datasets folder. Instruction-tuned LLMs, which can be used to generate adversarial essays, will be downloaded in the models folder. Total size of downloaded data and model files is ~8GB.
Training scripts and configurations are located in the code and conf folders respectively. We leveraged HF accelerate library to execute training runs with DDP on multiple GPUs (4x A100). Specifically, we used the following configurations for training:
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 4
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: falseFor (Q)LoRA fine-tuning of the LLM models, please run the following commands:
accelerate launch ./code/train_r_detect.py \
--config-name conf_r_detect_mix_v16 \
use_wandb=falseaccelerate launch ./code/train_r_detect.py \
--config-name conf_r_detect_mix_v26 \
use_wandb=falsePlease note that training takes ~3 hours for mix_v16 and ~4 hours for mix_v26.
To training the deberta-v3-large model with ranking loss, please run the following command:
accelerate launch ./code/train_r_ranking.py \
--config-name conf_r_ranking_large \
use_wandb=falseWe trained an embedding model with supervised contrastive loss to find similar essays (KNN neighbors) for a given essay in the test set.
accelerate launch ./code/train_r_embed.py \
--config-name conf_r_embed \
use_wandb=falseWe fine-tuned a wide variety of LLMs using the CLM objective on PERSUADE corpus to produce student like essays. The fine-tuned checkpoints were uploaded as a Kaggle Dataset conjuring92/detect-ai-persuade-clm-ckpts. These checkpoints can be used to generate essays using the following commands:
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_tiny_llama.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_pythia.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_bloom.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_gpt2.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_opt.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_falcon.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_mpt.yaml
accelerate launch ./code/generate_r_clm.py \
--config_path ./conf/r_clm/conf_r_clm_generate_llama13b.yaml
accelerate launch ./code/generate_r_clm_from_scratch.py \
--config_path ./conf/r_clm/conf_r_clm_generate_mistral_persuade.yamlOptionally, the fine-tuning of LLMs for text generation can be done using the following commands:
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_tiny_llama \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_pythia \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_bloom \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_gpt2 \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_opt \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_falcon \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_mpt \
use_wandb=false
accelerate launch ./code/train_r_clm.py \
--config-name conf_r_clm_llama13b \
use_wandb=false
accelerate launch ./code/train_r_clm_from_scratch.py \
--config-name conf_r_clm_mistral_persuade \
use_wandb=falseFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-detect-ai
Similar Open Source Tools
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.

1.5-Pints
1.5-Pints is a repository that provides a recipe to pre-train models in 9 days, aiming to create AI assistants comparable to Apple OpenELM and Microsoft Phi. It includes model architecture, training scripts, and utilities for 1.5-Pints and 0.12-Pint developed by Pints.AI. The initiative encourages replication, experimentation, and open-source development of Pint by sharing the model's codebase and architecture. The repository offers installation instructions, dataset preparation scripts, model training guidelines, and tools for model evaluation and usage. Users can also find information on finetuning models, converting lit models to HuggingFace models, and running Direct Preference Optimization (DPO) post-finetuning. Additionally, the repository includes tests to ensure code modifications do not disrupt the existing functionality.
friendly-stable-audio-tools
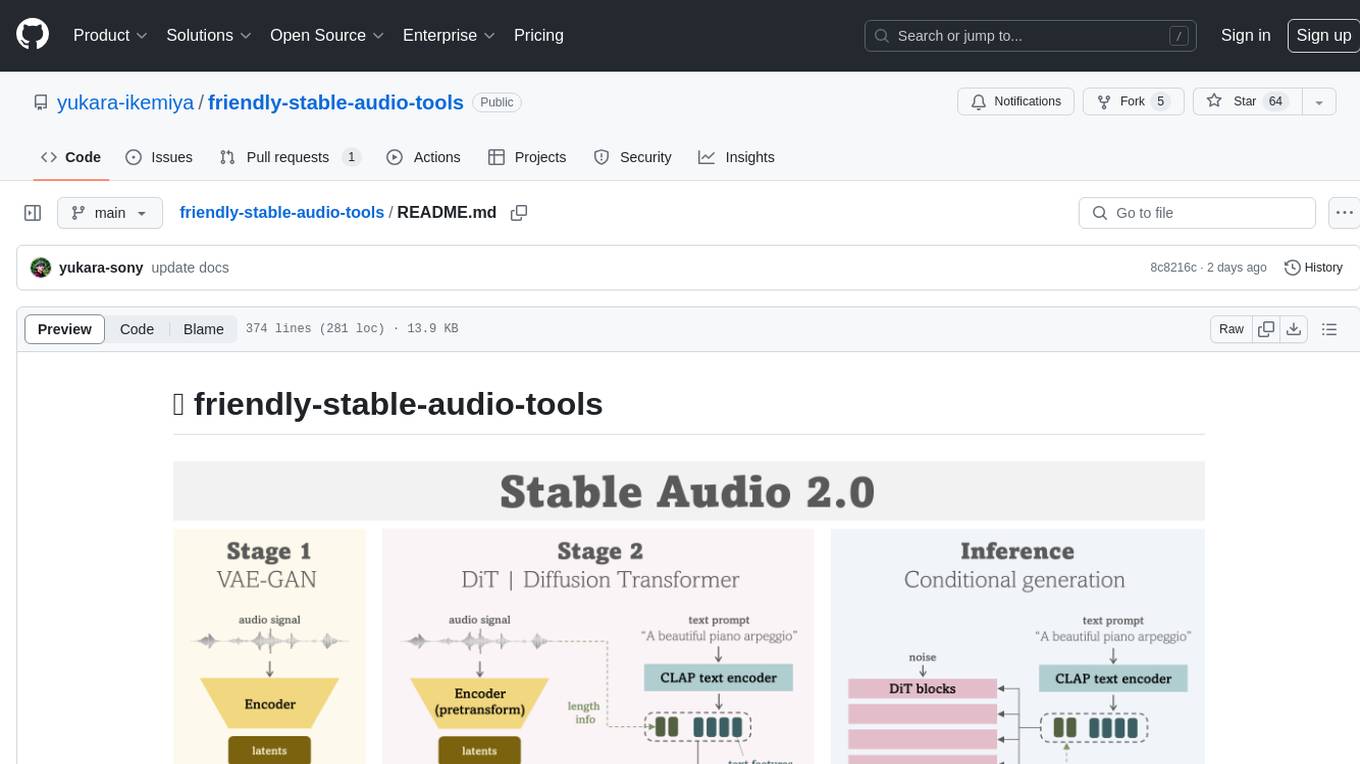
This repository is a refactored and updated version of `stable-audio-tools`, an open-source code for audio/music generative models originally by Stability AI. It contains refactored codes for improved readability and usability, useful scripts for evaluating and playing with trained models, and instructions on how to train models such as `Stable Audio 2.0`. The repository does not contain any pretrained checkpoints. Requirements include PyTorch 2.0 or later for Flash Attention support and Python 3.8.10 or later for development. The repository provides guidance on installing, building a training environment using Docker or Singularity, logging with Weights & Biases, training configurations, and stages for VAE-GAN and Diffusion Transformer (DiT) training.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.
ChatSim
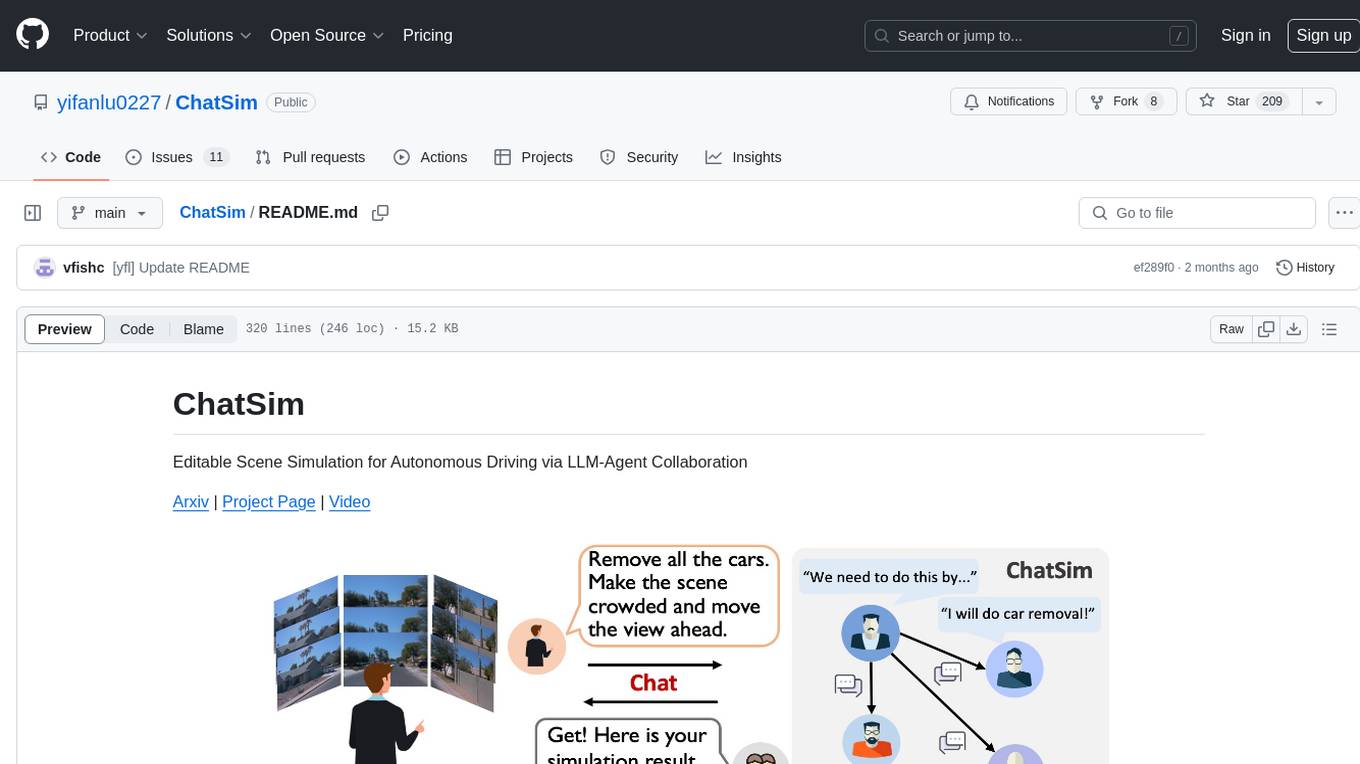
ChatSim is a tool designed for editable scene simulation for autonomous driving via LLM-Agent collaboration. It provides functionalities for setting up the environment, installing necessary dependencies like McNeRF and Inpainting tools, and preparing data for simulation. Users can train models, simulate scenes, and track trajectories for smoother and more realistic results. The tool integrates with Blender software and offers options for training McNeRF models and McLight's skydome estimation network. It also includes a trajectory tracking module for improved trajectory tracking. ChatSim aims to facilitate the simulation of autonomous driving scenarios with collaborative LLM-Agents.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
cheating-based-prompt-engine
This is a vulnerability mining engine purely based on GPT, requiring no prior knowledge base, no fine-tuning, yet its effectiveness can overwhelmingly surpass most of the current related research. The core idea revolves around being task-driven, not question-driven, driven by prompts, not by code, and focused on prompt design, not model design. The essence is encapsulated in one word: deception. It is a type of code understanding logic vulnerability mining that fully stimulates the capabilities of GPT, suitable for real actual projects.

co-llm
Co-LLM (Collaborative Language Models) is a tool for learning to decode collaboratively with multiple language models. It provides a method for data processing, training, and inference using a collaborative approach. The tool involves steps such as formatting/tokenization, scoring logits, initializing Z vector, deferral training, and generating results using multiple models. Co-LLM supports training with different collaboration pairs and provides baseline training scripts for various models. In inference, it uses 'vllm' services to orchestrate models and generate results through API-like services. The tool is inspired by allenai/open-instruct and aims to improve decoding performance through collaborative learning.

consult-llm-mcp
Consult LLM MCP is an MCP server that enables users to consult powerful AI models like GPT-5.2, Gemini 3.0 Pro, and DeepSeek Reasoner for complex problem-solving. It supports multi-turn conversations, direct queries with optional file context, git changes inclusion for code review, comprehensive logging with cost estimation, and various CLI modes for Gemini and Codex. The tool is designed to simplify the process of querying AI models for assistance in resolving coding issues and improving code quality.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

DeepPavlov
DeepPavlov is an open-source conversational AI library built on PyTorch. It is designed for the development of production-ready chatbots and complex conversational systems, as well as for research in the area of NLP and dialog systems. The library offers a wide range of models for tasks such as Named Entity Recognition, Intent/Sentence Classification, Question Answering, Sentence Similarity/Ranking, Syntactic Parsing, and more. DeepPavlov also provides embeddings like BERT, ELMo, and FastText for various languages, along with AutoML capabilities and integrations with REST API, Socket API, and Amazon AWS.
For similar tasks
llm-detect-ai
This repository contains code and configurations for the LLM - Detect AI Generated Text competition. It includes setup instructions for hardware, software, dependencies, and datasets. The training section covers scripts and configurations for training LLM models, DeBERTa ranking models, and an embedding model. Text generation section details fine-tuning LLMs using the CLM objective on the PERSUADE corpus to generate student-like essays.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

torchtune
Torchtune is a PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. It provides native-PyTorch implementations of popular LLMs using composable and modular building blocks, easy-to-use and hackable training recipes for popular fine-tuning techniques, YAML configs for easily configuring training, evaluation, quantization, or inference recipes, and built-in support for many popular dataset formats and prompt templates to help you quickly get started with training.
llm-engine
Scale's LLM Engine is an open-source Python library, CLI, and Helm chart that provides everything you need to serve and fine-tune foundation models, whether you use Scale's hosted infrastructure or do it in your own cloud infrastructure using Kubernetes.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.
Pai-Megatron-Patch
Pai-Megatron-Patch is a deep learning training toolkit built for developers to train and predict LLMs & VLMs by using Megatron framework easily. With the continuous development of LLMs, the model structure and scale are rapidly evolving. Although these models can be conveniently manufactured using Transformers or DeepSpeed training framework, the training efficiency is comparably low. This phenomenon becomes even severer when the model scale exceeds 10 billion. The primary objective of Pai-Megatron-Patch is to effectively utilize the computational power of GPUs for LLM. This tool allows convenient training of commonly used LLM with all the accelerating techniques provided by Megatron-LM.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.