
HuggingFaceModelDownloader
Simple go utility to download HuggingFace Models and Datasets
Stars: 475
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification. The tool provides features such as nested file downloading, filter downloads for specific LFS model files, support for HuggingFace Access Token, and configuration file support. It can be used as a library or a single binary for easy model downloading and inference in projects.
README:
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification.
Git LFS was slow for me, and I couldn't find a single binary for easy model downloading. This tool may also be integrated into future projects for inference using a Go/Python combination.
The script downloads the correct version based on your OS/architecture and saves the binary as "hfdownloader" in the current folder.
bash <(curl -sSL https://g.bodaay.io/hfd) -hTo install it to the default OS bin folder:
bash <(curl -sSL https://g.bodaay.io/hfd) -iIt will automatically request higher 'sudo' privileges if required. You can specify the install destination with -p.
bash <(curl -sSL https://g.bodaay.io/hfd) -i -p ~/.local/bin/The bash script just downloads the binary based on your OS/architecture and runs it.
bash <(curl -sSL https://g.bodaay.io/hfd) -m TheBloke/orca_mini_7B-GPTQbash <(curl -sSL https://g.bodaay.io/hfd) -m TheBloke/vicuna-13b-v1.3.0-GGML:q4_0Download Model: TheBloke/vicuna-13b-v1.3.0-GGML and Get GGML Variants: q4_0,q5_0 in Separate Folders
bash <(curl -sSL https://g.bodaay.io/hfd) -f -m TheBloke/vicuna-13b-v1.3.0-GGML:q4_0,q5_0bash <(curl -sSL https://g.bodaay.io/hfd) -m TheBloke/vicuna-13b-v1.3.0-GGML:q4_0,q4_K_S -c 8 -s /workspace/bash <(curl -sSL https://g.bodaay.io/hfd) -j TheBloke/vicuna-13b-v1.3.0-GGML:q4_0hfdownloader [flags]-
-m, --model string: Model/Dataset name (required if dataset not set). You can supply filters for required LFS model files. Filters will discard any LFS file ending with .bin, .act, .safetensors, .zip that are missing the supplied filtered out. -
-d, --dataset string: Dataset name (required if model not set). -
-f, --appendFilterFolder bool: Append the filter name to the folder, use it for GGML quantized filtered download only (optional). -
-k, --skipSHA bool: Skip SHA256 checking for LFS files, useful when trying to resume interrupted downloads and complete missing files quickly (optional). -
-b, --branch string: Model/Dataset branch (optional, default "main"). -
-s, --storage string: Storage path (optional, default "Storage"). -
-c, --concurrent int: Number of LFS concurrent connections (optional, default 5). -
-t, --token string: HuggingFace Access Token, can be supplied by env variable 'HF_TOKEN' or .env file (optional). -
-i, --install bool: Install the binary to the OS default bin folder, Unix-like operating systems only. -
-p, --installPath string: Specify install path, used with-i(optional). -
-j, --justDownload bool: Just download the model to the current directory and assume the first argument is the model name. -
-q, --silentMode bool: Disable progress bar printing. -
-h, --help: Help for hfdownloader.
hfdownloader -m TheBloke/WizardLM-13B-V1.0-Uncensored-GPTQ -c 10 -s MyModelshfdownloader -d facebook/flores -c 10 -s MyDatasets- Nested file downloading of the model
- Multithreaded downloading of large files (LFS)
- Filter downloads for specific LFS model files (useful for GGML/GGUFs)
- Simple utility that can be used as a library or a single binary
- SHA256 checksum verification for downloaded models
- Skipping previously downloaded files
- Resume progress for interrupted downloads
- Simple file size matching for non-LFS files
- Support for HuggingFace Access Token for restricted models/datasets
- Configuration File Support: You can now create a configuration file at
~/.config/hfdownloader.jsonto set default values for all command flags. - Generate Configuration File: A new command
hfdownloader generate-configgenerates an example configuration file with default values at the above path. - Existing downloads will be updated if the model/dataset already exists in the storage path and new files or versions are available.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for HuggingFaceModelDownloader
Similar Open Source Tools
HuggingFaceModelDownloader
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification. The tool provides features such as nested file downloading, filter downloads for specific LFS model files, support for HuggingFace Access Token, and configuration file support. It can be used as a library or a single binary for easy model downloading and inference in projects.
llm-term
LLM-Term is a Rust-based CLI tool that generates and executes terminal commands using OpenAI's language models or local Ollama models. It offers configurable model and token limits, works on both PowerShell and Unix-like shells, and provides a seamless user experience for generating commands based on prompts. Users can easily set up the tool, customize configurations, and leverage different models for command generation.
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.
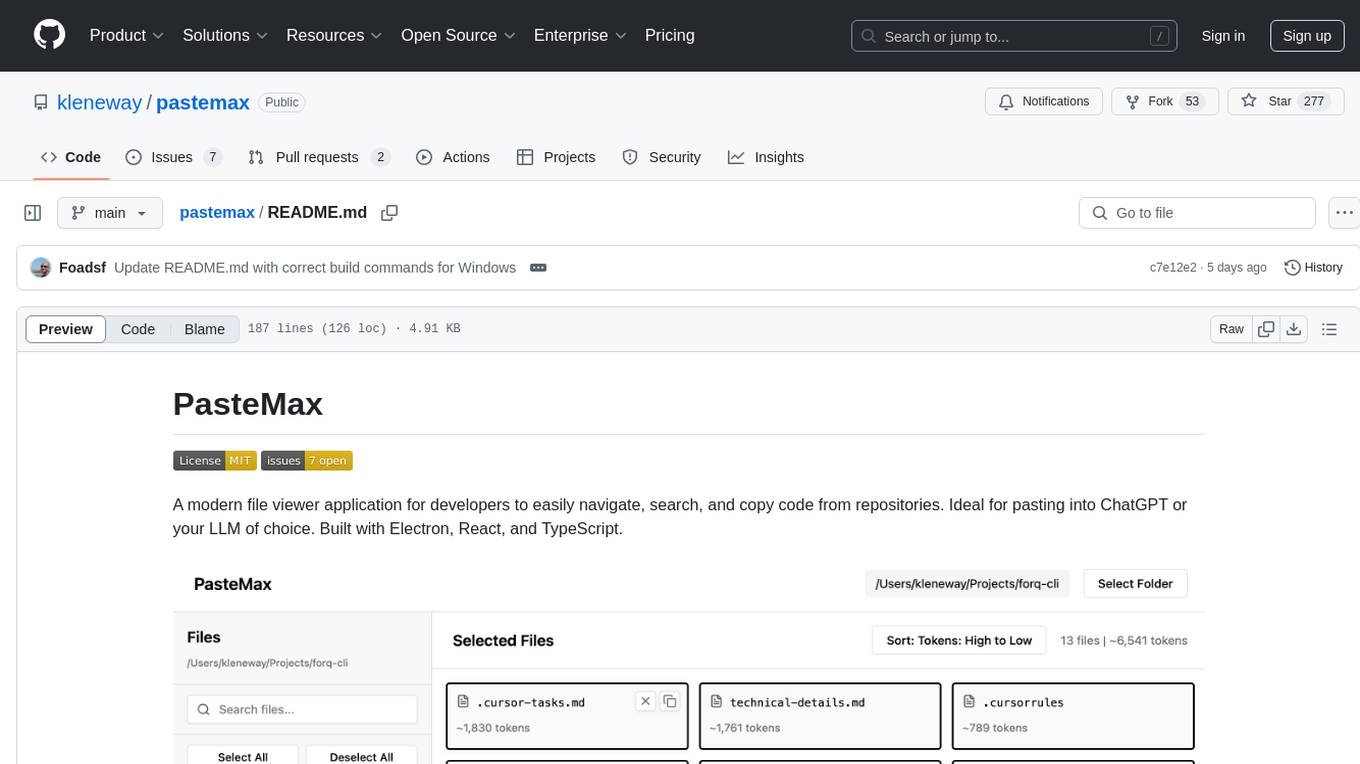
pastemax
PasteMax is a modern file viewer application designed for developers to easily navigate, search, and copy code from repositories. It provides features such as file tree navigation, token counting, search capabilities, selection management, sorting options, dark mode, binary file detection, and smart file exclusion. Built with Electron, React, and TypeScript, PasteMax is ideal for pasting code into ChatGPT or other language models. Users can download the application or build it from source, and customize file exclusions. Troubleshooting steps are provided for common issues, and contributions to the project are welcome under the MIT License.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.
askrepo
askrepo is a tool that reads the content of Git-managed text files in a specified directory, sends it to the Google Gemini API, and provides answers to questions based on a specified prompt. It acts as a question-answering tool for source code by using a Google AI model to analyze and provide answers based on the provided source code files. The tool leverages modules for file processing, interaction with the Google AI API, and orchestrating the entire process of extracting information from source code files.
pyomop
pyomop is a versatile tool designed as an OMOP Swiss Army Knife for working with OHDSI OMOP Common Data Model (CDM) v5.4 or v6 compliant databases using SQLAlchemy as the ORM. It supports converting query results to pandas DataFrames for machine learning pipelines and provides utilities for working with OMOP vocabularies. The tool is lightweight, easy-to-use, and can be used both as a command-line tool and as an imported library in code. It supports SQLite, PostgreSQL, and MySQL databases, LLM-based natural language queries, FHIR to OMOP conversion utilities, and executing QueryLibrary.

datalore-localgen-cli
Datalore is a terminal tool for generating structured datasets from local files like PDFs, Word docs, images, and text. It extracts content, uses semantic search to understand context, applies instructions through a generated schema, and outputs clean, structured data. Perfect for converting raw or unstructured local documents into ready-to-use datasets for training, analysis, or experimentation, all without manual formatting.
desktop
ComfyUI Desktop is a packaged desktop application that allows users to easily use ComfyUI with bundled features like ComfyUI source code, ComfyUI-Manager, and uv. It automatically installs necessary Python dependencies and updates with stable releases. The app comes with Electron, Chromium binaries, and node modules. Users can store ComfyUI files in a specified location and manage model paths. The tool requires Python 3.12+ and Visual Studio with Desktop C++ workload for Windows. It uses nvm to manage node versions and yarn as the package manager. Users can install ComfyUI and dependencies using comfy-cli, download uv, and build/launch the code. Troubleshooting steps include rebuilding modules and installing missing libraries. The tool supports debugging in VSCode and provides utility scripts for cleanup. Crash reports can be sent to help debug issues, but no personal data is included.
ai-digest
ai-digest is a CLI tool designed to aggregate your codebase into a single Markdown file for use with Claude Projects or custom ChatGPTs. It aggregates all files in the specified directory and subdirectories, ignores common build artifacts and configuration files, and provides options for whitespace removal and custom ignore patterns. The tool is useful for preparing codebases for AI analysis and assistance.
sandvault
SandVault is a tool that manages a limited user account to sandbox shell commands and AI agents on macOS, providing a lightweight alternative to application isolation using virtual machines. It allows for running Claude Code, OpenAI Codex, Google Gemini, and shell commands safely within a sandboxed environment. SandVault offers features like fast context switching, passwordless account switching, shared workspace access, and clean uninstallation. The tool operates with limited access to the user's computer, ensuring security by restricting access to certain directories and system files.

pebblo
Pebblo enables developers to safely load data and promote their Gen AI app to deployment without worrying about the organization’s compliance and security requirements. The project identifies semantic topics and entities found in the loaded data and summarizes them on the UI or a PDF report.
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
fragments
Fragments is an open-source tool that leverages Anthropic's Claude Artifacts, Vercel v0, and GPT Engineer. It is powered by E2B Sandbox SDK and Code Interpreter SDK, allowing secure execution of AI-generated code. The tool is based on Next.js 14, shadcn/ui, TailwindCSS, and Vercel AI SDK. Users can stream in the UI, install packages from npm and pip, and add custom stacks and LLM providers. Fragments enables users to build web apps with Python interpreter, Next.js, Vue.js, Streamlit, and Gradio, utilizing providers like OpenAI, Anthropic, Google AI, and more.
glimpse
Glimpse is a blazingly fast tool for peeking at codebases, offering features like fast parallel file processing, tree-view of codebase structure, source code content viewing, token counting with multiple backends, configurable defaults, clipboard support, customizable file type detection, .gitignore respect, web content processing with Markdown conversion, Git repository support, and URL traversal with configurable depth. It supports token counting using Tiktoken or HuggingFace tokenizer backends, helping estimate context window usage for large language models. Glimpse can process local directories, multiple files, Git repositories, web pages, and convert content to Markdown. It offers various options for customization and configuration, including file type inclusions/exclusions, token counting settings, URL processing settings, and default exclude patterns. Glimpse is suitable for developers and data scientists looking to analyze codebases, estimate token counts, and process web content efficiently.

termax
Termax is an LLM agent in your terminal that converts natural language to commands. It is featured by: - Personalized Experience: Optimize the command generation with RAG. - Various LLMs Support: OpenAI GPT, Anthropic Claude, Google Gemini, Mistral AI, and more. - Shell Extensions: Plugin with popular shells like `zsh`, `bash` and `fish`. - Cross Platform: Able to run on Windows, macOS, and Linux.
For similar tasks

qb
QANTA is a system and dataset for question answering tasks. It provides a script to download datasets, preprocesses questions, and matches them with Wikipedia pages. The system includes various datasets, training, dev, and test data in JSON and SQLite formats. Dependencies include Python 3.6, `click`, and NLTK models. Elastic Search 5.6 is needed for the Guesser component. Configuration is managed through environment variables and YAML files. QANTA supports multiple guesser implementations that can be enabled/disabled. Running QANTA involves using `cli.py` and Luigi pipelines. The system accesses raw Wikipedia dumps for data processing. The QANTA ID numbering scheme categorizes datasets based on events and competitions.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
HuggingFaceModelDownloader
The HuggingFace Model Downloader is a utility tool for downloading models and datasets from the HuggingFace website. It offers multithreaded downloading for LFS files and ensures the integrity of downloaded models with SHA256 checksum verification. The tool provides features such as nested file downloading, filter downloads for specific LFS model files, support for HuggingFace Access Token, and configuration file support. It can be used as a library or a single binary for easy model downloading and inference in projects.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
iris_android
This repository contains an offline Android chat application based on llama.cpp example. Users can install, download models, and run the app completely offline and privately. To use the app, users need to go to the releases page, download and install the app. Building the app requires downloading Android Studio, cloning the repository, and importing it into Android Studio. The app can be run offline by following specific steps such as enabling developer options, wireless debugging, and downloading the stable LM model. The project is maintained by Nerve Sparks and contributions are welcome through creating feature branches and pull requests.
podman-desktop-extension-ai-lab
Podman AI Lab is an open source extension for Podman Desktop designed to work with Large Language Models (LLMs) on a local environment. It features a recipe catalog with common AI use cases, a curated set of open source models, and a playground for learning, prototyping, and experimentation. Users can quickly and easily get started bringing AI into their applications without depending on external infrastructure, ensuring data privacy and security.
llamafile-docker
This repository, llamafile-docker, automates the process of checking for new releases of Mozilla-Ocho/llamafile, building a Docker image with the latest version, and pushing it to Docker Hub. Users can download a pre-trained model in gguf format and use the Docker image to interact with the model via a server or CLI version. Contributions are welcome under the Apache 2.0 license.

hordelib
horde-engine is a wrapper around ComfyUI designed to run inference pipelines visually designed in the ComfyUI GUI. It enables users to design inference pipelines in ComfyUI and then call them programmatically, maintaining compatibility with the existing horde implementation. The library provides features for processing Horde payloads, initializing the library, downloading and validating models, and generating images based on input data. It also includes custom nodes for preprocessing and tasks such as face restoration and QR code generation. The project depends on various open source projects and bundles some dependencies within the library itself. Users can design ComfyUI pipelines, convert them to the backend format, and run them using the run_image_pipeline() method in hordelib.comfy.Comfy(). The project is actively developed and tested using git, tox, and a specific model directory structure.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.