
AutoDocs
We handle what AI editors won't: generating and maintaining documentation for your codebase, while also providing search with dependency-aware context that helps your tools understand your codebase and its conventions.
Stars: 134
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
README:

AutoDocs, by Sita
Automate documentation for any repo: we traverse your codebase, parse the AST, build a dependency graph, and walk that graph to generate accurate, high‑signal docs. A built‑in MCP server lets coding agents deep‑search your code via HTTP.
(Interested in our hosted or enterprise offerings? Join the waitlist at https://trysita.com)
- Parses your repository using tree‑sitter (AST parsing) and SCIP (symbol resolution).
- Constructs a code dependency graph (files, definitions, calls, imports) and topologically sorts the dependency order.
- Traverses that graph to create repository‑wide, dependency‑aware documentation and summaries.
- Exposes a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration.
- Provides an MCP server at so agentic tools can query your repo with deep search.
Install these once on your machine:
- pnpm 10+ (Node 20+ recommended; Corepack is fine). Docs
- uv (fast Python package manager). Docs
- Docker + Docker Compose (to run everything locally). Docs
Reference docs
- pnpm install: https://pnpm.io/installation
- uv install: https://docs.astral.sh/uv/
Some features or scripts may call the GitHub API (e.g., fetching repo metadata). If you hit rate limits or need to access private repos, create a Personal Access Token (PAT) and set it in your environment.
- How-to (official docs): https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token
- Create fine-grained PAT (recommended): https://github.com/settings/personal-access-tokens/new
- Create classic PAT (legacy): https://github.com/settings/tokens/new
Suggested scopes
- Public repos only: use a fine-grained token with selected repositories (read-only) or a classic token with
public_repo. - Private repos: fine-grained token with read-only repo access to the needed repositories, or a classic token with
repo.
Add to your .env (or shell env):
GITHUB_TOKEN=ghp_your_token_hereNotes
- Keep this token secret; do not commit
.env. - Fine-grained tokens are preferred for tighter, per-repo permissions.
- Environment
cp .env.example .env- Database:
DATABASE_URL(local postgres DB). In Compose, DB is available atpostgresql://postgres:postgres@db:5432/app. - Ingestion API:
INGESTION_API_URLfor the web app to call the FastAPI service. - Analysis storage:
ANALYSIS_DB_DIRcontrols where generated per-repo SQLite files live.
- Summaries:
SUMMARIES_API_KEY,SUMMARIES_MODEL,SUMMARIES_BASE_URL(OpenAI-compatible, default OpenRouter) - Embeddings:
EMBEDDINGS_API_KEY,EMBEDDINGS_MODEL,EMBEDDINGS_BASE_URL(OpenAI-compatible, default OpenAI) - Rate limiting:
MAX_REQUESTS_PER_SECONDfor LLM summary batching (default 15)
- Run locally with Docker Compose
docker compose up -d
# If you want to see logs
docker compose upYou should now have:
- Web UI at http://localhost:3000
- API at http://localhost:8000 (OpenAPI schema at
/schema)
To refresh a repository’s docs after code changes, remove the repo and re‑ingest it (temporary workflow):
- UI: delete the repo in your Workspace, then add it again (ingestion starts automatically).
We’re actively adding a one‑click "Resync" button in the UI, followed by automatic periodic ingestion (coming soon)
The MCP server is available at http://localhost:3000/api/mcp and is designed for coding agents and MCP‑compatible clients. It exposes a codebase-qna tool that answers repository‑scoped questions by querying the analysis databases that AutoDocs produces.
Tips
- Point your MCP client at
http://localhost:3000/api/mcp. - Include an
x-repo-idheader with the repo ID (you can find it in the UI). - For setup guides with popular tools (Claude, Cursor, Continue), see https://docs.trysita.com
For a local dev loop without Docker Compose you can run the API and web dev servers directly:
# concurrent dev (API + Web + DB)
./tools/dev.sh --syncDatabase migration (run if modifying the postgres schema)
cd packages/shared
DATABASE_URL=postgresql://postgres:postgres@localhost:5432/app pnpm drizzle-kit push --config drizzle.main.config.ts-
ingestion/— Python FastAPI service, AST parser, graph builder, embeddings, and search. -
webview/— Next.js app (Turborepo workspace) and shared TS packages. -
docker-compose.yml— local Postgres, API, and Web services. -
tools/— helper scripts (build_all.sh,dev.sh,uv_export_requirements.sh).
- Web can’t reach the API: ensure
INGESTION_API_URL=http://api:8000is set in.env. - Missing
uv/pnpm: install them (see links above)
- In your repositories, code must live at the repository root, not in a nested folder.
- Language support: currently supports TS, JS, and Python; currently working on expansion to Go, Kotlin, Java, and Rust.
- Polyglot repos (multiple languages in one repo): not supported yet, but we’re actively working on it.
Licensed under the Apache 2.0 License. See LICENSE.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AutoDocs
Similar Open Source Tools
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
sosumi.ai
sosumi.ai provides Apple Developer documentation in an AI-readable format by converting JavaScript-rendered pages into Markdown. It offers an HTTP API to access Apple docs, supports external Swift-DocC sites, integrates with MCP server, and provides tools like searchAppleDocumentation and fetchAppleDocumentation. The project can be self-hosted and is currently hosted on Cloudflare Workers. It is built with Hono and supports various runtimes. The application is designed for accessibility-first, on-demand rendering of Apple Developer pages to Markdown.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
ai-context
AI Context is a CLI tool that generates AI-friendly markdown files from GitHub repos, local code, YouTube videos, or webpages. It supports processing local directories, GitHub repositories, YouTube transcripts, and webpages, converting them to markdown format. The tool simplifies interactions with LLMs like ChatGPT and Claude by providing a text-first context creation approach. It offers features for installation, usage, and acknowledgments, with options to process single paths, URLs, or lists of paths concurrently.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
pyomop
pyomop is a versatile tool designed as an OMOP Swiss Army Knife for working with OHDSI OMOP Common Data Model (CDM) v5.4 or v6 compliant databases using SQLAlchemy as the ORM. It supports converting query results to pandas DataFrames for machine learning pipelines and provides utilities for working with OMOP vocabularies. The tool is lightweight, easy-to-use, and can be used both as a command-line tool and as an imported library in code. It supports SQLite, PostgreSQL, and MySQL databases, LLM-based natural language queries, FHIR to OMOP conversion utilities, and executing QueryLibrary.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
datagouv-mcp
datagouv-mcp is a Model Context Protocol (MCP) server designed to facilitate AI chatbots (such as Claude, ChatGPT, Gemini) in searching, exploring, and analyzing datasets from data.gouv.fr, the French national Open Data platform, through conversation. Users can ask questions like 'Quels jeux de données sont disponibles sur les prix de l'immobilier?' or 'Montre-moi les dernières données de population pour Paris' to get instant answers without manually browsing the website. The server provides tools to interact with datasets and dataservices, supporting features like searching datasets, getting dataset information, listing resources, querying resource data, and more. It also offers support for various chatbots like ChatGPT, Claude Desktop, Claude Code, Gemini CLI, Mistral Vibe CLI, AnythingLLM, VS Code, Cursor, Windsurf, and provides detailed instructions for connecting chatbots to the server.
lunary
Lunary is an open-source observability and prompt platform for Large Language Models (LLMs). It provides a suite of features to help AI developers take their applications into production, including analytics, monitoring, prompt templates, fine-tuning dataset creation, chat and feedback tracking, and evaluations. Lunary is designed to be usable with any model, not just OpenAI, and is easy to integrate and self-host.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
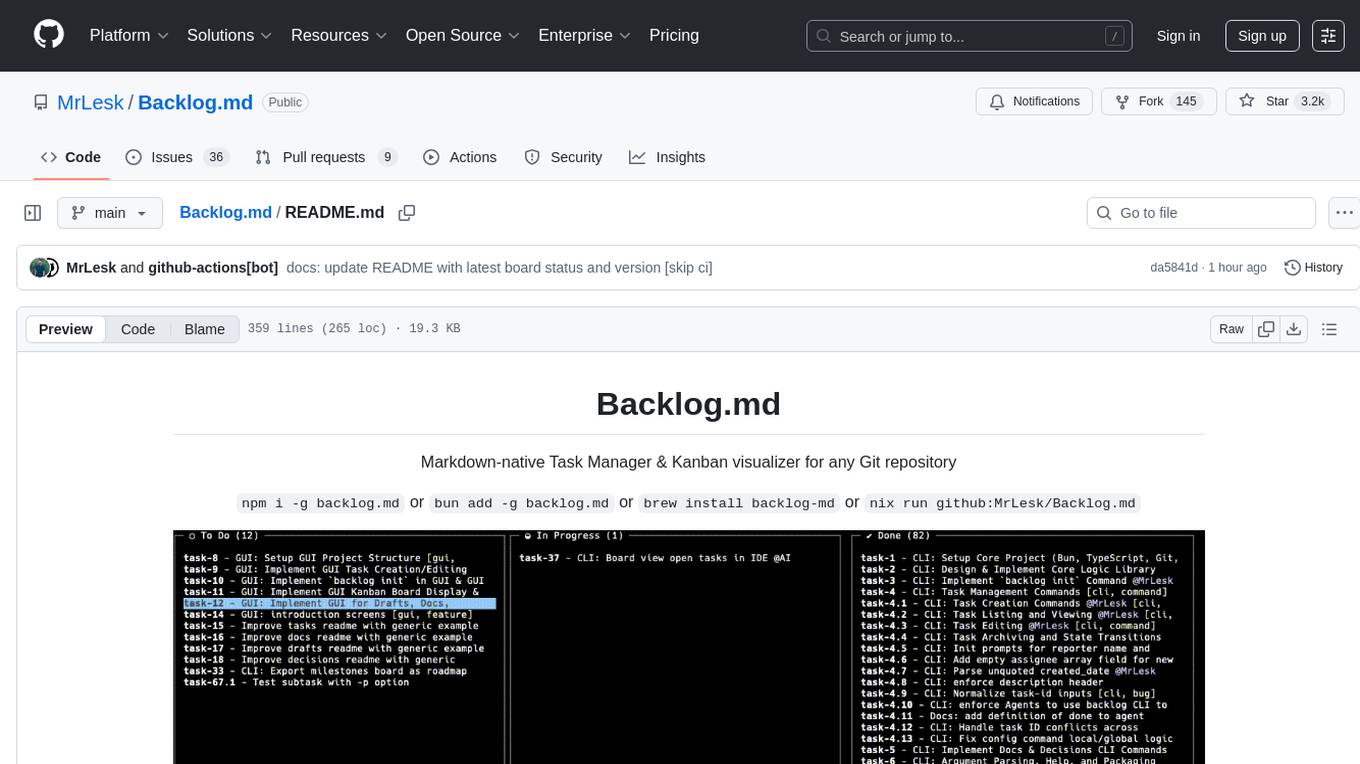
Backlog.md
Backlog.md is a Markdown-native Task Manager & Kanban visualizer for any Git repository. It turns any folder with a Git repo into a self-contained project board powered by plain Markdown files and a zero-config CLI. Features include managing tasks as plain .md files, private & offline usage, instant terminal Kanban visualization, board export, modern web interface, AI-ready CLI, rich query commands, cross-platform support, and MIT-licensed open-source. Users can create tasks, view board, assign tasks to AI, manage documentation, make decisions, and configure settings easily.
mcp-server
The UI5 Model Context Protocol server offers tools to improve the developer experience when working with agentic AI tools. It helps with creating new UI5 projects, detecting and fixing UI5-specific errors, and providing additional UI5-specific information for agentic AI tools. The server supports various tools such as scaffolding new UI5 applications, fetching UI5 API documentation, providing UI5 development best practices, extracting metadata and configuration from UI5 projects, retrieving version information for the UI5 framework, analyzing and reporting issues in UI5 code, offering guidelines for converting UI5 applications to TypeScript, providing UI Integration Cards development best practices, scaffolding new UI Integration Cards, and validating the manifest against the UI5 Manifest schema. The server requires Node.js and npm versions specified, along with an MCP client like VS Code or Cline. Configuration options are available for customizing the server's behavior, and specific setup instructions are provided for MCP clients like VS Code and Cline.
ChatGPT
The ChatGPT API Free Reverse Proxy provides free self-hosted API access to ChatGPT (`gpt-3.5-turbo`) with OpenAI's familiar structure, eliminating the need for code changes. It offers streaming response, API endpoint compatibility, and complimentary access without an API key. Installation options include Docker, PC/Server, and Termux on Android devices. The API can be accessed through a self-hosted local server or a pre-hosted API with an API key obtained from the Discord server. Usage examples are provided for Python and Node.js, and the project is licensed under AGPL-3.0.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
For similar tasks
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.

CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
air
air is an R formatter and language server written in Rust. It is currently in alpha stage, so users should expect breaking changes in both the API and formatting results. The tool draws inspiration from various sources like roslyn, swift, rust-analyzer, prettier, biome, and ruff. It provides formatters and language servers, influenced by design decisions from these tools. Users can install air using standalone installers for macOS, Linux, and Windows, which automatically add air to the PATH. Developers can also install the dev version of the air CLI and VS Code extension for further customization and development.
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.