
nodejs-todo-api-boilerplate
🛠️ A production-ready LLM-Powered Node.js & TypeScript REST API template, with a focus on Clean Architecture
Stars: 127
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.
README:

An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description.
Before you proceed, verify that Node.js and npm are installed, and update your .env file with a valid LLM provider API key (e.g., OPENAI_API_KEY). You may choose from providers like OpenAI, Claude, DeepSeek, or OpenRouter/Llama.
It orchestrates 3 LLM micro-agents (Developer, Troubleshooter and TestsFixer) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture. It uses OpenAI/Anthropic/DeepSeek/Llama LLM API to perform code-generation
First, navigate to the root ./llm-codegen folder and run npm install to install dependencies. Then execute npm run start and provide the requested module description when prompted. Finally, after the code generation finishes, review the output, and if the output meets your expectations, begin integrating it into your codebase

This project is a simple Node.js boilerplate using TypeScript and Docker. It demonstrates vertical slicing architecture for a REST API, as detailed here: https://markhneedham.com/blog/2012/02/20/coding-packaging-by-vertical-slice/. Unlike horizontal slicing (layered architecture), vertical slicing reduces the model code gap, making the modeled domain easier to understand. The implementation also follows the principles of Clean Architecture by Uncle Bob: https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html.
The application provides APIs for users to get, create, update, and delete Todo (CRUD operations)
- Vertical slicing architecture based on DDD & MVC principles
- Services input validation using ZOD
- Decoupling application components through dependency injection using InversifyJS
- Integration and E2E testing with Supertest
- Docker-compose simplifies multi-service setup, running application, DB, and Redis in isolated docker containers easily
- Simple DB transaction management with Knex
- Multi-layer trace ID support for logging with winston
- Support graceful shutdown for the express.js server
- In-memory data storage and caching with ioredis
- Auto-reload on save using ts-node-dev
- Automated documentation generation with TypeDoc
- Scheduled server-side cron jobs using node-cron
- AWS S3 integration for file uploads using aws-sdk
Please make sure that you have docker installed https://docs.docker.com/engine/install/
How to run locally (in dev mode):
- Copy
.env.sampleand rename it to.env, providing the appropriate environment variable values. Some of the variables are defined in the docker-compose file - Install dependencies locally
npm i - Start the app using
npm run docker:run - By default, the API server is available at
http://localhost:8080/
Migrations and seed run automatically
How to run tests in separate docker containers locally:
- Install dependencies locally
npm i - Run API tests in separate docker containers
npm run docker:test
How to run tests locally with a local SQLite DB:
- Install dependencies locally
npm i - Execute API tests using a local SQLite DB that stores data in a file:
npm run local:test
todo-api
├─ package.json
├─ src
│ ├─modules (domain components)
│ │ ├─ todos
│ │ │ ├─ tests
│ │ │ ├─ repository
│ │ │ ├─ routes
│ │ │ ├─ controllers
│ │ │ ├─ *.service (business logic implementation)
│ ├─ users
│ ├─ ...
│ │
├─ infra (generic cross-component functionality)
│ ├─ data (migrations, seeds)
│ ├─ integrations (services responsible for integrations with 3rd party services - belong to repository layer)
│ ├─ loaders
│ ├─ middlewaresComprehensive API documentation is created directly from the source code using TypeDoc. To generate the documentation, run:
- Generate documentation:
npm run generate:docs - Serve documentation locally:
npm run serve:docs
After running these commands, the documentation will be accessible at http://127.0.0.1:8081.
Here is Postman collection to work with API locally:

List of available routes:
Auth routes:
POST /api/signup - register
POST /api/signin - login
POST /api/jwt/refresh - refresh auth token
POST /api/signout - logout
User routes:
GET /v1/users - get all users (requires admin access rights)
GET /v1/users/me - get current user
Todo routes:
POST /api/todos - create new todo
PUT /api/todos/:todoId - update todo
GET /api/todos/:todoId - get specific todo
GET /api/todos/my - get all users' todos
DELETE /api/todos/:todoId - delete user
GET /api/todos - get all created todos (requires admin access rights)
The codebase is organized into modules, with each module representing either a use case (business logic) or an integration service (with a third-party service, e.g., AWS). Each module defines its dependencies using dependency injection and validates input parameters with ZOD.
To easily manage dependencies and decouple parts of the application, the InversifyJS package is used. Each class or module can consume one of the registered dependencies via decorators. In the dependency container file located at src/infra/loaders/diContainer.ts, you can find each dependency and its corresponding imported module.
The application uses the winston logger for effective logging and implements cross-layer trace IDs in the winston wrapper output logic. As a result, logs related to the same request but from different layers (service, repository, controller) are outputted with the same trace ID without any extra implementation.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nodejs-todo-api-boilerplate
Similar Open Source Tools
nodejs-todo-api-boilerplate
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
backend.ai
Backend.AI is a streamlined, container-based computing cluster platform that hosts popular computing/ML frameworks and diverse programming languages, with pluggable heterogeneous accelerator support including CUDA GPU, ROCm GPU, TPU, IPU and other NPUs. It allocates and isolates the underlying computing resources for multi-tenant computation sessions on-demand or in batches with customizable job schedulers with its own orchestrator. All its functions are exposed as REST/GraphQL/WebSocket APIs.
CodeRAG
CodeRAG is an AI-powered code retrieval and assistance tool that combines Retrieval-Augmented Generation (RAG) with AI to provide intelligent coding assistance. It indexes your entire codebase for contextual suggestions based on your complete project, offering real-time indexing, semantic code search, and contextual AI responses. The tool monitors your code directory, generates embeddings for Python files, stores them in a FAISS vector database, matches user queries against the code database, and sends retrieved code context to GPT models for intelligent responses. CodeRAG also features a Streamlit web interface with a chat-like experience for easy usage.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
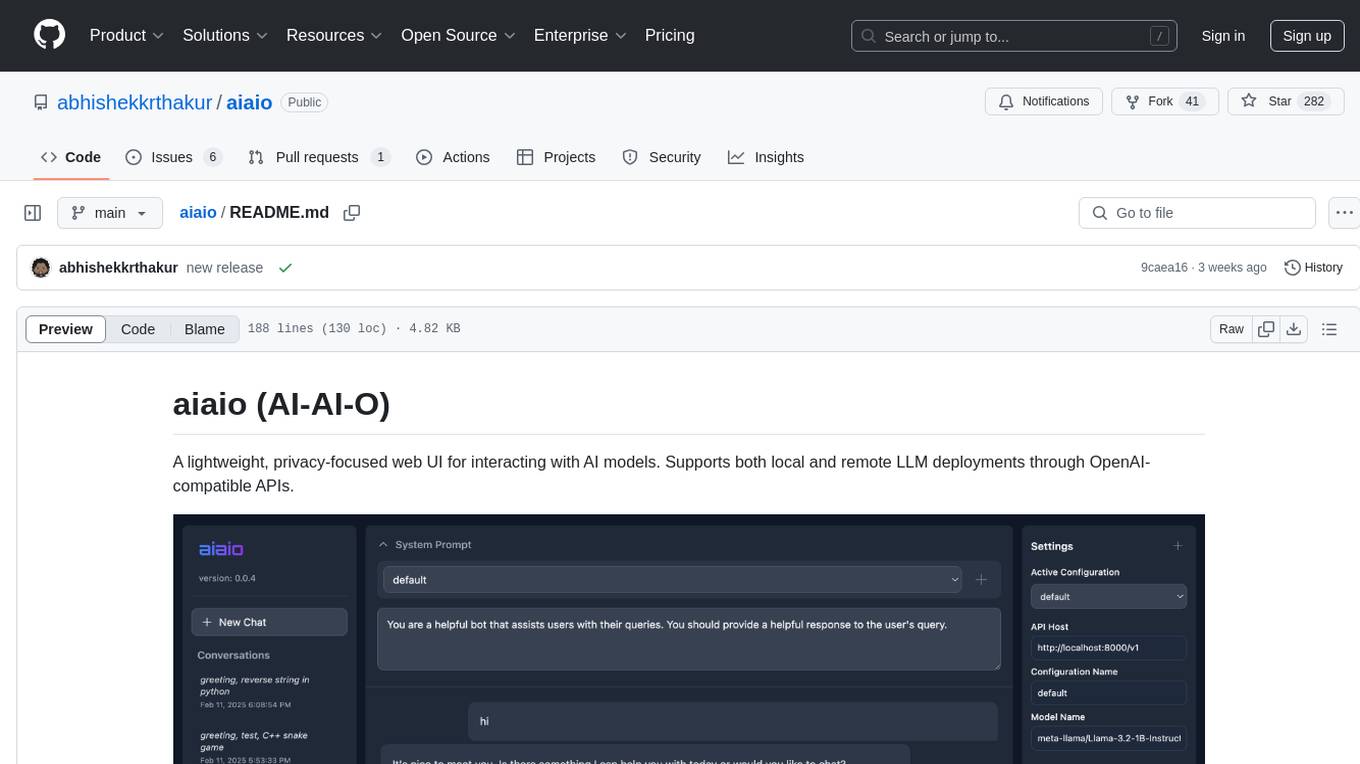
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
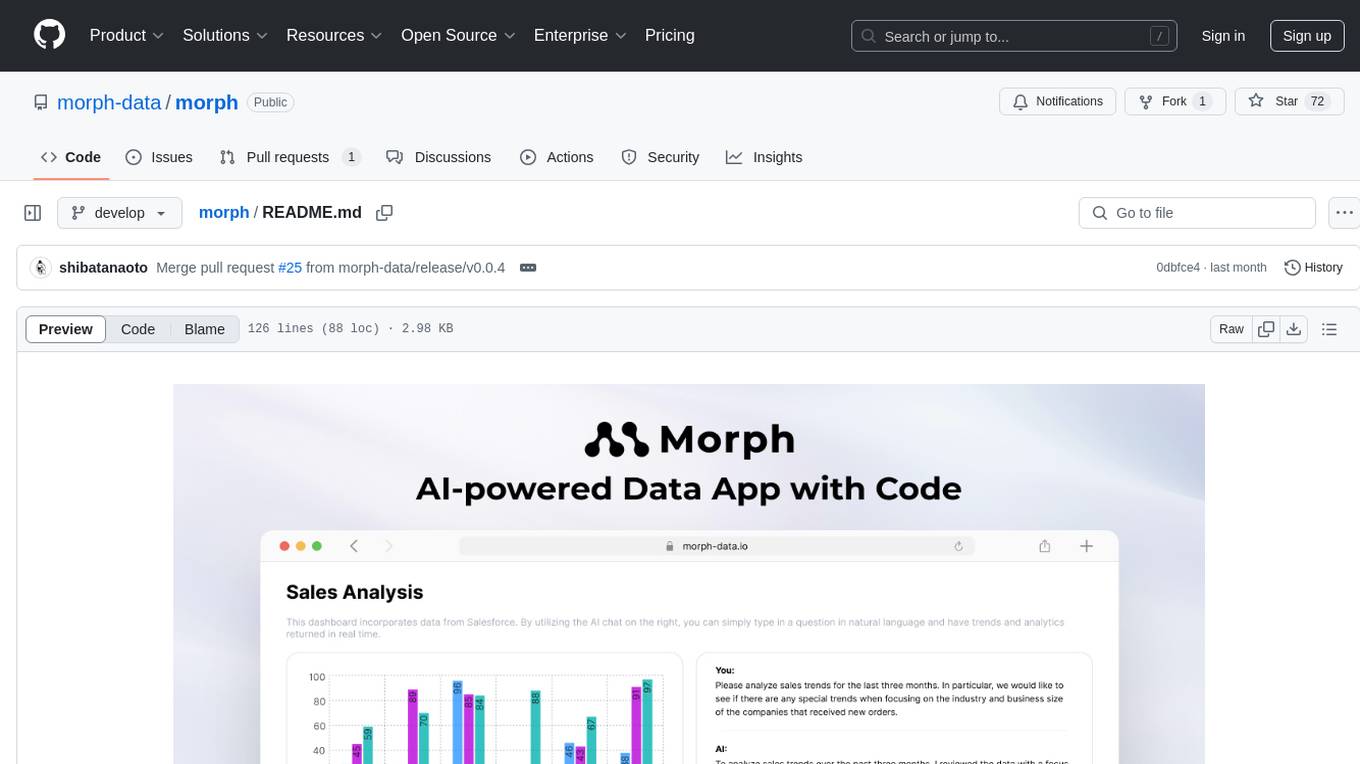
morph
Morph is a python-centric full-stack framework for building and deploying data apps. It is fast to start, deploy and operate, requires no HTML/CSS knowledge, and is customizable with Python and SQL for advanced data workflows. With Markdown-based syntax and pre-made components, users can create visually appealing designs without writing HTML or CSS.
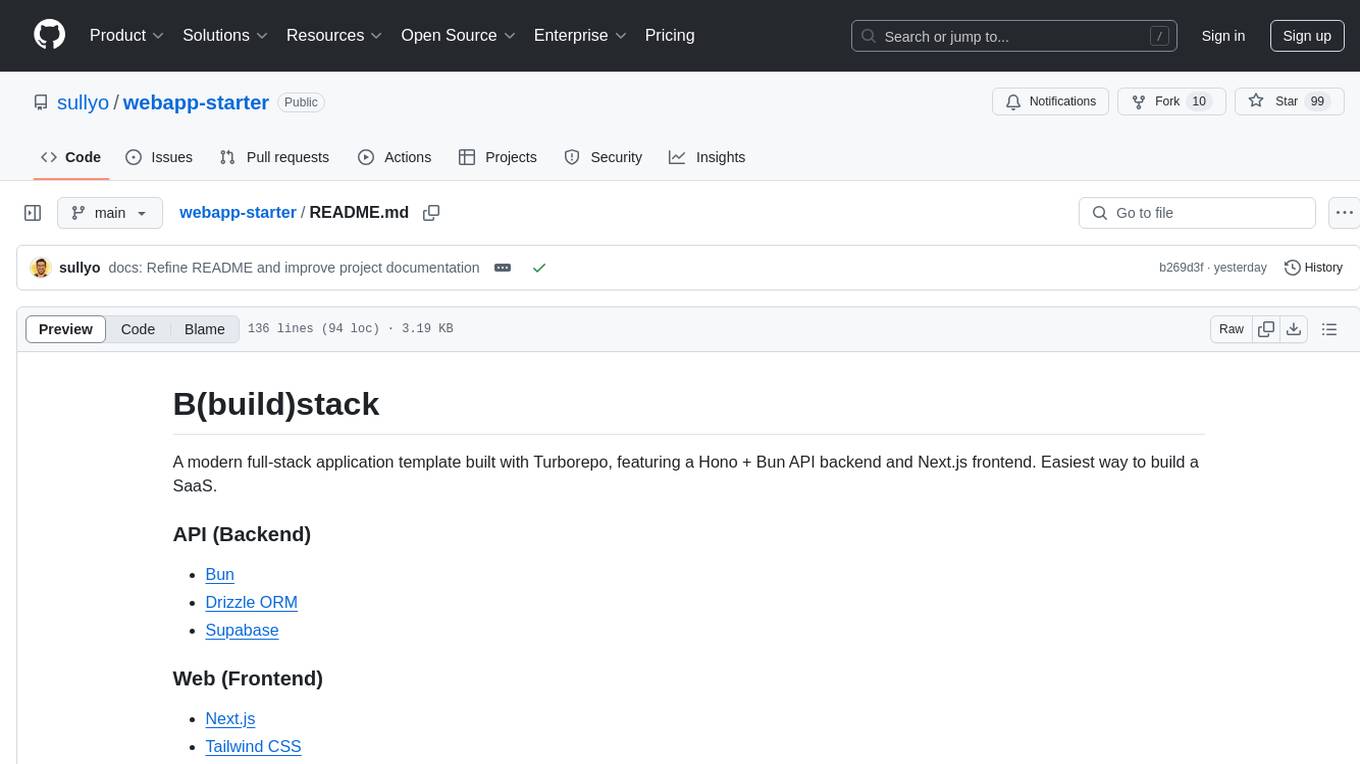
webapp-starter
webapp-starter is a modern full-stack application template built with Turborepo, featuring a Hono + Bun API backend and Next.js frontend. It provides an easy way to build a SaaS product. The backend utilizes technologies like Bun, Drizzle ORM, and Supabase, while the frontend is built with Next.js, Tailwind CSS, Shadcn/ui, and Clerk. Deployment can be done using Vercel and Render. The project structure includes separate directories for API backend and Next.js frontend, along with shared packages for the main database. Setup involves installing dependencies, configuring environment variables, and setting up services like Bun, Supabase, and Clerk. Development can be done using 'turbo dev' command, and deployment instructions are provided for Vercel and Render. Contributions are welcome through pull requests.
gateway
CentralMind Gateway is an AI-first data gateway that securely connects any data source and automatically generates secure, LLM-optimized APIs. It filters out sensitive data, adds traceability, and optimizes for AI workloads. Suitable for companies deploying AI agents for customer support and analytics.
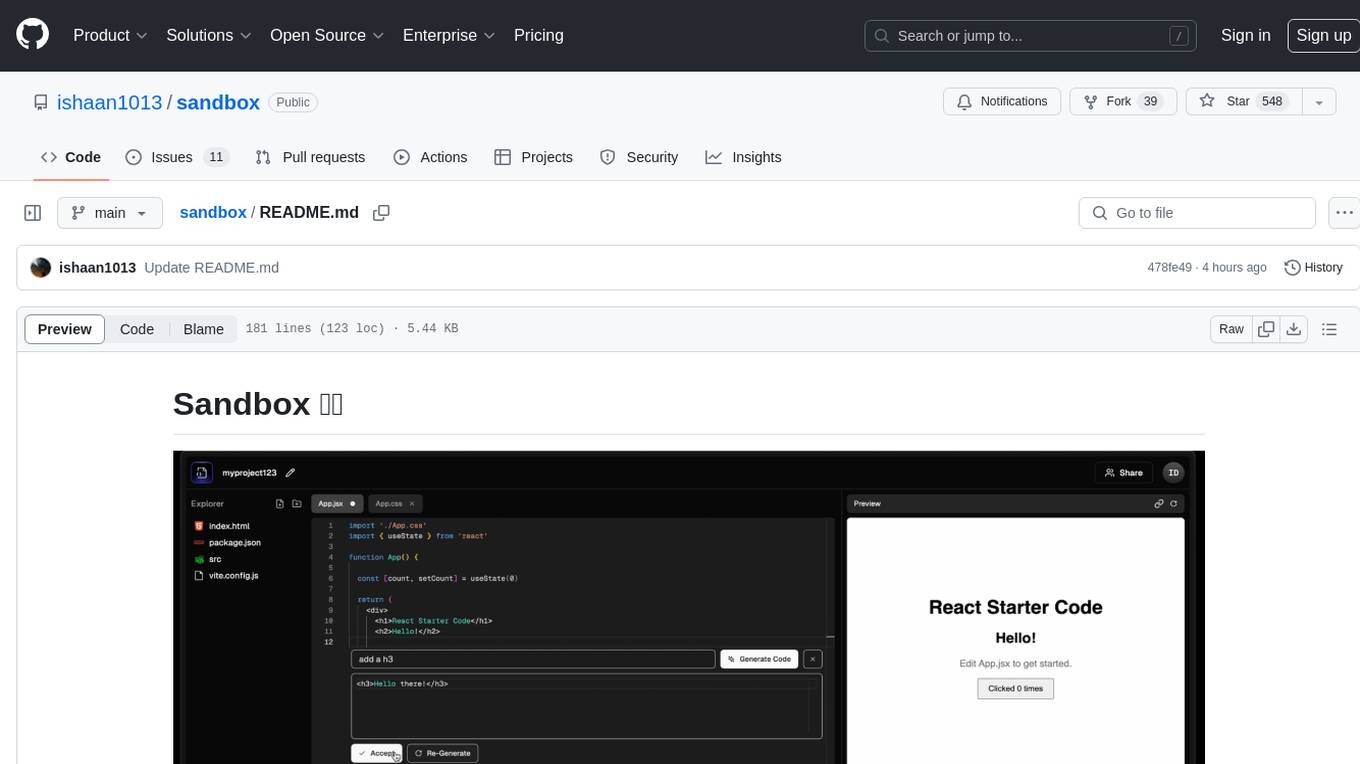
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.
model-compose
model-compose is an open-source, declarative workflow orchestrator inspired by docker-compose. It lets you define and run AI model pipelines using simple YAML files. Effortlessly connect external AI services or run local AI models within powerful, composable workflows. Features include declarative design, multi-workflow support, modular components, flexible I/O routing, streaming mode support, and more. It supports running workflows locally or serving them remotely, Docker deployment, environment variable support, and provides a CLI interface for managing AI workflows.
mcpd
mcpd is a tool developed by Mozilla AI to declaratively manage Model Context Protocol (MCP) servers, enabling consistent interface for defining and running tools across different environments. It bridges the gap between local development and enterprise deployment by providing secure secrets management, declarative configuration, and seamless environment promotion. mcpd simplifies the developer experience by offering zero-config tool setup, language-agnostic tooling, version-controlled configuration files, enterprise-ready secrets management, and smooth transition from local to production environments.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.

probe
Probe is an AI-friendly, fully local, semantic code search tool designed to power the next generation of AI coding assistants. It combines the speed of ripgrep with the code-aware parsing of tree-sitter to deliver precise results with complete code blocks, making it perfect for large codebases and AI-driven development workflows. Probe is fully local, keeping code on the user's machine without relying on external APIs. It supports multiple languages, offers various search options, and can be used in CLI mode, MCP server mode, AI chat mode, and web interface. The tool is designed to be flexible, fast, and accurate, providing developers and AI models with full context and relevant code blocks for efficient code exploration and understanding.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.
For similar tasks
nodejs-todo-api-boilerplate
An LLM-powered code generation tool that relies on the built-in Node.js API Typescript Template Project to easily generate clean, well-structured CRUD module code from text description. It orchestrates 3 LLM micro-agents (`Developer`, `Troubleshooter` and `TestsFixer`) to generate code, fix compilation errors, and ensure passing E2E tests. The process includes module code generation, DB migration creation, seeding data, and running tests to validate output. By cycling through these steps, it guarantees consistent and production-ready CRUD code aligned with vertical slicing architecture.

ChatDBG
ChatDBG is an AI-based debugging assistant for C/C++/Python/Rust code that integrates large language models into a standard debugger (`pdb`, `lldb`, `gdb`, and `windbg`) to help debug your code. With ChatDBG, you can engage in a dialog with your debugger, asking open-ended questions about your program, like `why is x null?`. ChatDBG will _take the wheel_ and steer the debugger to answer your queries. ChatDBG can provide error diagnoses and suggest fixes. As far as we are aware, ChatDBG is the _first_ debugger to automatically perform root cause analysis and to provide suggested fixes.
dravid
Dravid (DRD) is an advanced, AI-powered CLI coding framework designed to follow user instructions until the job is completed, including fixing errors. It can generate code, fix errors, handle image queries, manage file operations, integrate with external APIs, and provide a development server with error handling. Dravid is extensible and requires Python 3.7+ and CLAUDE_API_KEY. Users can interact with Dravid through CLI commands for various tasks like creating projects, asking questions, generating content, handling metadata, and file-specific queries. It supports use cases like Next.js project development, working with existing projects, exploring new languages, Ruby on Rails project development, and Python project development. Dravid's project structure includes directories for source code, CLI modules, API interaction, utility functions, AI prompt templates, metadata management, and tests. Contributions are welcome, and development setup involves cloning the repository, installing dependencies with Poetry, setting up environment variables, and using Dravid for project enhancements.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.
thread
Thread is an AI-powered Jupyter alternative that integrates an AI copilot into your editing experience. It offers a familiar Jupyter Notebook editing experience with features like natural language code edits, generating cells to answer questions, context-aware chat sidebar, and automatic error explanations or fixes. The tool aims to enhance code editing and data exploration by providing a more interactive and intuitive experience for users. Thread can be used for free with Ollama or your own API key, and it runs locally for convenience and privacy.
chatgpt-arcana.el
ChatGPT-Arcana is an Emacs package that allows users to interact with ChatGPT directly from Emacs, enabling tasks such as chatting with GPT, operating on code or text, generating eshell commands from natural language, fixing errors, writing commit messages, and creating agents for web search and code evaluation. The package requires an API key from OpenAI's GPT-3 model and offers various interactive functions for enhancing productivity within Emacs.
aide
Aide is an Open Source AI-native code editor that combines the powerful features of VS Code with advanced AI capabilities. It provides a combined chat + edit flow, proactive agents for fixing errors, inline editing widget, intelligent code completion, and AST navigation. Aide is designed to be an intelligent coding companion, helping users write better code faster while maintaining control over the development process.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.
For similar jobs
resonance
Resonance is a framework designed to facilitate interoperability and messaging between services in your infrastructure and beyond. It provides AI capabilities and takes full advantage of asynchronous PHP, built on top of Swoole. With Resonance, you can: * Chat with Open-Source LLMs: Create prompt controllers to directly answer user's prompts. LLM takes care of determining user's intention, so you can focus on taking appropriate action. * Asynchronous Where it Matters: Respond asynchronously to incoming RPC or WebSocket messages (or both combined) with little overhead. You can set up all the asynchronous features using attributes. No elaborate configuration is needed. * Simple Things Remain Simple: Writing HTTP controllers is similar to how it's done in the synchronous code. Controllers have new exciting features that take advantage of the asynchronous environment. * Consistency is Key: You can keep the same approach to writing software no matter the size of your project. There are no growing central configuration files or service dependencies registries. Every relation between code modules is local to those modules. * Promises in PHP: Resonance provides a partial implementation of Promise/A+ spec to handle various asynchronous tasks. * GraphQL Out of the Box: You can build elaborate GraphQL schemas by using just the PHP attributes. Resonance takes care of reusing SQL queries and optimizing the resources' usage. All fields can be resolved asynchronously.
aiogram_bot_template
Aiogram bot template is a boilerplate for creating Telegram bots using Aiogram framework. It provides a solid foundation for building robust and scalable bots with a focus on code organization, database integration, and localization.

pluto
Pluto is a development tool dedicated to helping developers **build cloud and AI applications more conveniently** , resolving issues such as the challenging deployment of AI applications and open-source models. Developers are able to write applications in familiar programming languages like **Python and TypeScript** , **directly defining and utilizing the cloud resources necessary for the application within their code base** , such as AWS SageMaker, DynamoDB, and more. Pluto automatically deduces the infrastructure resource needs of the app through **static program analysis** and proceeds to create these resources on the specified cloud platform, **simplifying the resources creation and application deployment process**.
pinecone-ts-client
The official Node.js client for Pinecone, written in TypeScript. This client library provides a high-level interface for interacting with the Pinecone vector database service. With this client, you can create and manage indexes, upsert and query vector data, and perform other operations related to vector search and retrieval. The client is designed to be easy to use and provides a consistent and idiomatic experience for Node.js developers. It supports all the features and functionality of the Pinecone API, making it a comprehensive solution for building vector-powered applications in Node.js.
aiohttp-pydantic
Aiohttp pydantic is an aiohttp view to easily parse and validate requests. You define using function annotations what your methods for handling HTTP verbs expect, and Aiohttp pydantic parses the HTTP request for you, validates the data, and injects the parameters you want. It provides features like query string, request body, URL path, and HTTP headers validation, as well as Open API Specification generation.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.
aioconsole
aioconsole is a Python package that provides asynchronous console and interfaces for asyncio. It offers asynchronous equivalents to input, print, exec, and code.interact, an interactive loop running the asynchronous Python console, customization and running of command line interfaces using argparse, stream support to serve interfaces instead of using standard streams, and the apython script to access asyncio code at runtime without modifying the sources. The package requires Python version 3.8 or higher and can be installed from PyPI or GitHub. It allows users to run Python files or modules with a modified asyncio policy, replacing the default event loop with an interactive loop. aioconsole is useful for scenarios where users need to interact with asyncio code in a console environment.
aiosqlite
aiosqlite is a Python library that provides a friendly, async interface to SQLite databases. It replicates the standard sqlite3 module but with async versions of all the standard connection and cursor methods, along with context managers for automatically closing connections and cursors. It allows interaction with SQLite databases on the main AsyncIO event loop without blocking execution of other coroutines while waiting for queries or data fetches. The library also replicates most of the advanced features of sqlite3, such as row factories and total changes tracking.