
CodebaseToPrompt
Turn local files into a prompt for an LLM
Stars: 139

CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
README:
A simple tool that converts your local directory into a structured prompt for Large Language Models (LLMs). It helps you pick which files to include or ignore, then outputs everything in a format you can copy directly into an LLM for code review, analysis, or documentation.

Try it here: CodebaseToPrompt Web App
CodebaseToPrompt scans your chosen folder right in the browser (no files are uploaded anywhere) and builds a file tree. You can expand folders, see which files are text or code, and select only what you need. The selected files are then compiled into a snippet of structured text, which you can copy for use with an LLM.
-
Interactive File Tree
Explore and expand your local folders in a simple interface. -
File Filtering
Automatically ignores system or binary files (e.g.,.DS_Store,node_modules, images, videos). -
Local Storage
Your selections are remembered so you can pick up where you left off. -
LLM-Ready Output
Generates a format that’s easy to paste into chatbots and other AI tools. -
Token Count Estimate
Provides a rough calculation of how many tokens the selected content might use.
-
Open the App
Clone this repository, then openindex.htmlin a modern browser (Chrome or Firefox recommended).git clone https://github.com/path-find-er/CodebaseToPrompt.git
-
Select Your Folder
Click “Select Directory” to choose the folder you want to analyze. -
Pick Files
Expand or collapse directories. Check or uncheck files to decide what gets included. -
Copy Output
View or copy your selected files in the generated prompt format by clicking “Copy to Clipboard.”
- Creating context for AI-based code review or Q&A
- Quickly extracting only the important parts of a large project for analysis
- Preparing short or large code snippets for LLM debugging
- Generating reference material for new developers or documentation
Certain folders and file types are automatically ignored (e.g., node_modules, .git, venv, common binary files). You can modify the lists inside the JavaScript code (app.js) if you need more control.
- Chrome/Chromium (recommended)
- Edge
- Firefox
- Safari (basic directory selection may vary)
Contributions are welcome! Feel free to open issues for bugs or requests. For major changes, create an issue to discuss them first.
- Fork and clone the repo
- Make your changes in a branch
- Open a Pull Request describing your updates
- Built with vanilla JavaScript and Web APIs
- Uses SheetJS for spreadsheet parsing
- Uses PDF.js for PDF parsing
- Open an issue on GitHub for ideas or bug reports
- Submit a Pull Request for direct contributions
- Reach out via the repo’s issues page if you have questions
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for CodebaseToPrompt
Similar Open Source Tools
CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
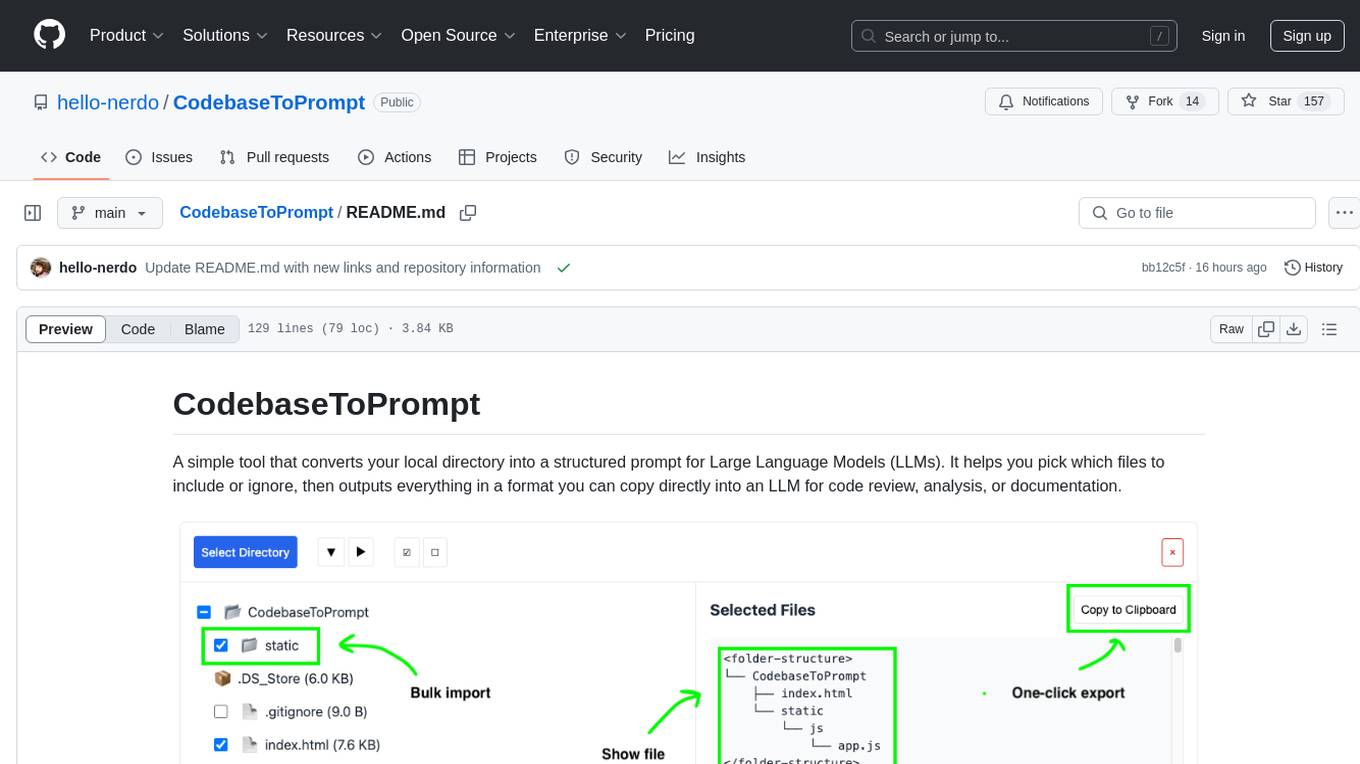
CodebaseToPrompt
CodebaseToPrompt is a tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in an interactive interface. The tool generates a formatted output that can be directly used with LLMs, estimates token count, and supports flexible text selection. Users can deploy the tool using Docker for self-contained usage and can contribute to the project by opening issues or submitting pull requests.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.
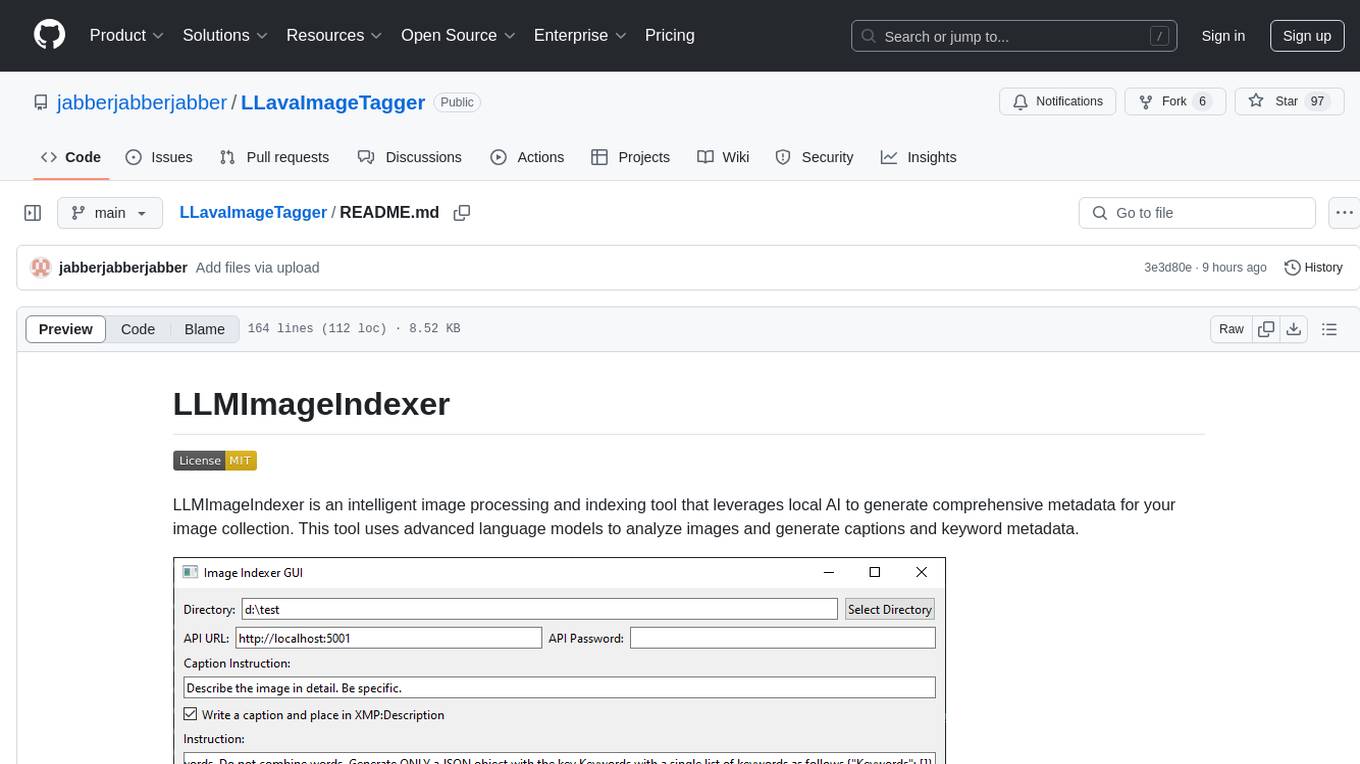
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
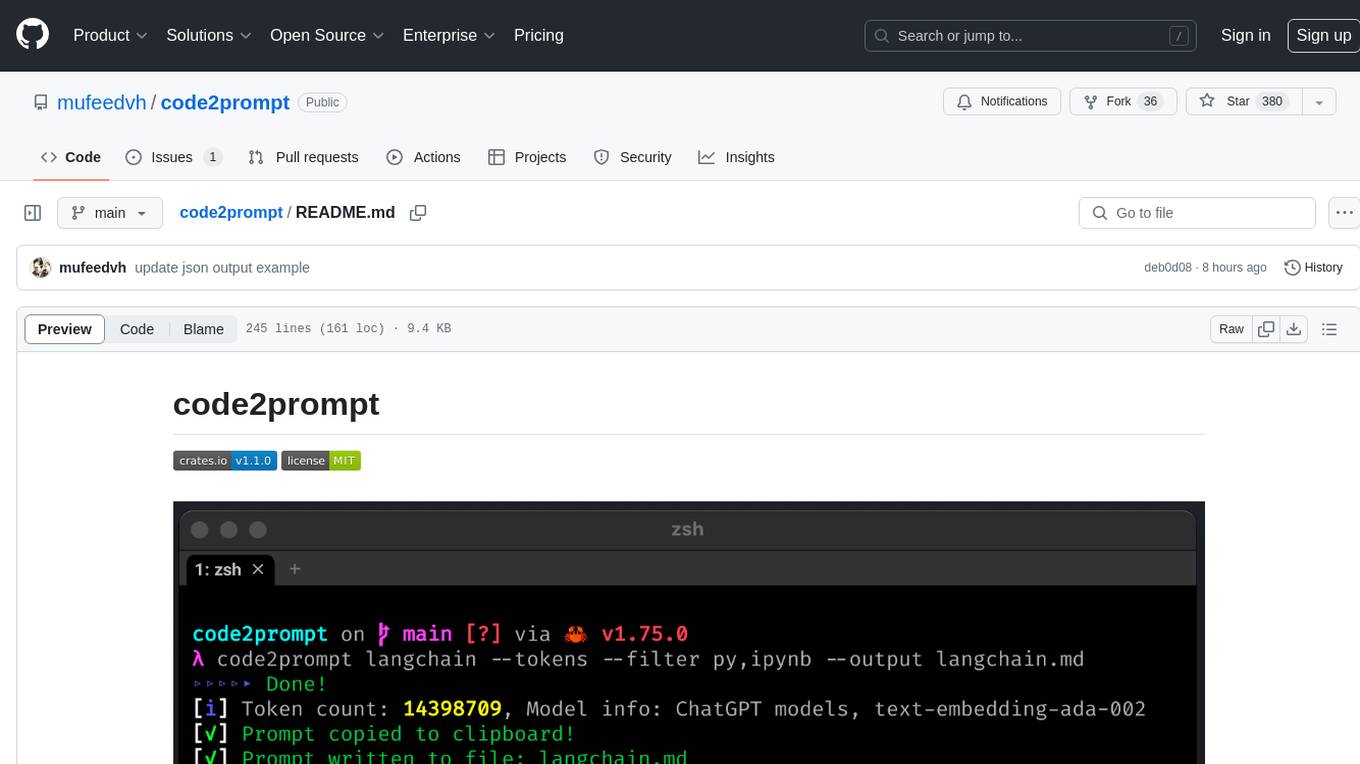
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.
yn
Yank Note is a highly extensible Markdown editor designed for productivity. It offers features like easy-to-use interface, powerful support for version control and various embedded content, high compatibility with local Markdown files, plug-in extension support, and encryption for saving private files. Users can write their own plug-ins to expand the editor's functionality. However, for more extendability, security protection is sacrificed. The tool supports sync scrolling, outline navigation, version control, encryption, auto-save, editing assistance, image pasting, attachment embedding, code running, to-do list management, quick file opening, integrated terminal, Katex expression, GitHub-style Markdown, multiple data locations, external link conversion, HTML resolving, multiple formats export, TOC generation, table cell editing, title link copying, embedded applets, various graphics embedding, mind map display, custom container support, macro replacement, image hosting service, OpenAI auto completion, and custom plug-ins development.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
AIOLists
AIOLists is a stateless open source list management addon for Stremio that allows users to import and manage lists from various sources in one place. It offers unified search, metadata customization, Trakt integration, MDBList integration, external lists import, list sorting, customization options, watchlist updates, RPDB support, genre filtering, discovery lists, and shareable configurations. The addon aims to enhance the list management experience for Stremio users by providing a comprehensive set of features and functionalities.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
uxie
Uxie is a PDF reader app designed to revolutionize the learning experience. It offers features such as annotation, note-taking, collaboration tools, integration with LLM for enhanced learning, and flashcard generation with LLM feedback. Built using Nextjs, tRPC, Zod, TypeScript, Tailwind CSS, React Query, React Hook Form, Supabase, Prisma, and various other tools. Users can take notes, summarize PDFs, chat and collaborate with others, create custom blocks in the editor, and use AI-powered text autocompletion. The tool allows users to craft simple flashcards, test knowledge, answer questions, and receive instant feedback through AI evaluation.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.

cognita
Cognita is an open-source framework to organize your RAG codebase along with a frontend to play around with different RAG customizations. It provides a simple way to organize your codebase so that it becomes easy to test it locally while also being able to deploy it in a production ready environment. The key issues that arise while productionizing RAG system from a Jupyter Notebook are: 1. **Chunking and Embedding Job** : The chunking and embedding code usually needs to be abstracted out and deployed as a job. Sometimes the job will need to run on a schedule or be trigerred via an event to keep the data updated. 2. **Query Service** : The code that generates the answer from the query needs to be wrapped up in a api server like FastAPI and should be deployed as a service. This service should be able to handle multiple queries at the same time and also autoscale with higher traffic. 3. **LLM / Embedding Model Deployment** : Often times, if we are using open-source models, we load the model in the Jupyter notebook. This will need to be hosted as a separate service in production and model will need to be called as an API. 4. **Vector DB deployment** : Most testing happens on vector DBs in memory or on disk. However, in production, the DBs need to be deployed in a more scalable and reliable way. Cognita makes it really easy to customize and experiment everything about a RAG system and still be able to deploy it in a good way. It also ships with a UI that makes it easier to try out different RAG configurations and see the results in real time. You can use it locally or with/without using any Truefoundry components. However, using Truefoundry components makes it easier to test different models and deploy the system in a scalable way. Cognita allows you to host multiple RAG systems using one app. ### Advantages of using Cognita are: 1. A central reusable repository of parsers, loaders, embedders and retrievers. 2. Ability for non-technical users to play with UI - Upload documents and perform QnA using modules built by the development team. 3. Fully API driven - which allows integration with other systems. > If you use Cognita with Truefoundry AI Gateway, you can get logging, metrics and feedback mechanism for your user queries. ### Features: 1. Support for multiple document retrievers that use `Similarity Search`, `Query Decompostion`, `Document Reranking`, etc 2. Support for SOTA OpenSource embeddings and reranking from `mixedbread-ai` 3. Support for using LLMs using `Ollama` 4. Support for incremental indexing that ingests entire documents in batches (reduces compute burden), keeps track of already indexed documents and prevents re-indexing of those docs.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.
PyWxDump
PyWxDump is a powerful tool designed to help extract and manage WeChat data efficiently. It allows users to read local databases, view chat histories, and export data in various formats such as CSV and HTML. With features like multi-account support, version compatibility, data export, AI training, and automated responses, PyWxDump offers flexibility for training AI models and developing automated replies.
For similar tasks
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
SinkFinder
SinkFinder + LLM is a closed-source semi-automatic vulnerability discovery tool that performs static code analysis on jar/war/zip files. It enhances the capability of LLM large models to verify path reachability and assess the trustworthiness score of the path based on the contextual code environment. Users can customize class and jar exclusions, depth of recursive search, and other parameters through command-line arguments. The tool generates rule.json configuration file after each run and requires configuration of the DASHSCOPE_API_KEY for LLM capabilities. The tool provides detailed logs on high-risk paths, LLM results, and other findings. Rules.json file contains sink rules for various vulnerability types with severity levels and corresponding sink methods.
open-repo-wiki
OpenRepoWiki is a tool designed to automatically generate a comprehensive wiki page for any GitHub repository. It simplifies the process of understanding the purpose, functionality, and core components of a repository by analyzing its code structure, identifying key files and functions, and providing explanations. The tool aims to assist individuals who want to learn how to build various projects by providing a summarized overview of the repository's contents. OpenRepoWiki requires certain dependencies such as Google AI Studio or Deepseek API Key, PostgreSQL for storing repository information, Github API Key for accessing repository data, and Amazon S3 for optional usage. Users can configure the tool by setting up environment variables, installing dependencies, building the server, and running the application. It is recommended to consider the token usage and opt for cost-effective options when utilizing the tool.
CodebaseToPrompt
CodebaseToPrompt is a simple tool that converts a local directory into a structured prompt for Large Language Models (LLMs). It allows users to select specific files for code review, analysis, or documentation by exploring and filtering through the file tree in a browser-based interface. The tool generates a formatted output that can be directly used with AI tools, provides token count estimates, and supports local storage for saving selections. Users can easily copy the selected files in the desired format for further use.
air
air is an R formatter and language server written in Rust. It is currently in alpha stage, so users should expect breaking changes in both the API and formatting results. The tool draws inspiration from various sources like roslyn, swift, rust-analyzer, prettier, biome, and ruff. It provides formatters and language servers, influenced by design decisions from these tools. Users can install air using standalone installers for macOS, Linux, and Windows, which automatically add air to the PATH. Developers can also install the dev version of the air CLI and VS Code extension for further customization and development.
code-graph
Code-graph is a tool composed of FalkorDB Graph DB, Code-Graph-Backend, and Code-Graph-Frontend. It allows users to store and query graphs, manage backend logic, and interact with the website. Users can run the components locally by setting up environment variables and installing dependencies. The tool supports analyzing C & Python source files with plans to add support for more languages in the future. It provides a local repository analysis feature and a live demo accessible through a web browser.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.