
kollektiv
The open source chat powered by LLMs with RAG. Kollektiv makes it easy to sync your custom data sources and get accurate, contextual replies.
Stars: 74

Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.
README:
![]()
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed for one purpose - allow you to chat with your favorite docs (of libraries, frameworks, tools primarily) easily.
This project aims to allow LLMs to tap into the most up-to-date knowledge in 2 clicks so that you don't have to worry about incorrect replies, hallucinations or inaccuracies when working with the best LLMs.
This project was born out of a personal itch - whenever a new feature of my favorite library comes up, I know I can't rely on the LLM to help me build with it - because it simply doesn't know about it!
The root cause - LLMs lack access to the most recent documentation or private knowledge, as they are trained on a set of data that was accumulated way back (sometimes more than a year ago).
The impact - hallucinations in answers, inaccurate, incorrect or outdated information, which directly decreases productivity and usefulness of using LLMs
But there is a better way...
What if LLMs could tap into a source of up-to-date information on libraries, tools, frameworks you are building with?
Imagine your LLM could intelligently decide when it needs to check the documentation source and always provide an accurate reply?
Meet Kollektiv -> an open-source RAG app that helps you easily:
- parse the docs of your favorite libraries
- efficiently stores and embeds them in a local vector storage
- sets up an LLM chat which you can rely on
Note this is v.0.1.6 and reliability of the system can be characterized as following:
- in 50% of the times it works every time!
So do let me know if you are experiencing issues and I'll try to fix them.
- 🕷️ Intelligent Web Crawling: Utilizes FireCrawl API to efficiently crawl and extract content from specified documentation websites.
- 🧠 Advanced Document Processing: Implements custom chunking strategies to optimize document storage and retrieval.
- 🔍 Vector Search: Employs Chroma DB for high-performance similarity search of document chunks.
- 🔄 Multi-Query Expansion: Enhances search accuracy by generating multiple relevant queries for each user input.
- 📊 Smart Re-ranking: Utilizes Cohere's re-ranking API to improve relevancy of search results
- 🤖 AI-Powered Responses: Integrates with Claude 3.5 Sonnet to generate human-like, context-aware responses.
- 🧠 Dynamic system prompt: Automatically summarizes the embedded documentation to improve RAG decision-making.
- Backend: Python/FastAPI
-
Storage:
- Supabase (auth/data)
- ChromaDB (vectors)
- Redis (queues/real-time)
-
AI/ML:
- OpenAI text-embedding-3-small (embeddings)
- Anthropic Claude 3.5 Sonnet (chat)
- Cohere (re-ranking)
- Additional: tiktoken, pydantic, pytest, ruff
-
Clone the repository:
git clone https://github.com/alexander-zuev/kollektiv.git cd kollektiv -
Set up environment variables: Create a
.envfile in the project root with the following:FIRECRAWL_API_KEY="your_firecrawl_api_key" OPENAI_API_KEY="your_openai_api_key" ANTHROPIC_API_KEY="your_anthropic_api_key" COHERE_API_KEY="your_cohere_api_key"
-
Install dependencies:
poetry install
-
Start the application and Redis:
poetry run kollektiv
This command will start the FastAPI application and a Redis server using Docker Compose. The
docker-compose.ymlfile is located atscripts/external_deps/docker-compose.yml.
-
Start the Application:
# Run both API and Chainlit UI poetry run kollektiv # Or run only Chainlit UI chainlit run main.py
-
Add Documentation:
@docs add https://your-docs-url.com
The system will guide you through:
- Setting crawling depth
- Adding exclude patterns (optional)
- Processing and embedding content
-
Manage Documents:
@docs list # List all documents @docs remove [ID] # Remove a document @help # Show all commands
-
Chat with Documentation: Simply ask questions in natural language. The system will:
- Search relevant documentation
- Re-rank results for accuracy
- Generate contextual responses
- Image content not supported (text-only embeddings)
- No automatic re-indexing of documentation
- URL validation limited to common formats
- Exclude patterns must start with
/
For a brief roadmap please check out project wiki page.
Evaluation is currently done using ragas library. There are 2 key parts assessed:
- End-to-end generation
- Faithfulness
- Answer relevancy
- Answer correctness
- Retriever (TBD)
- Context recall
- Context precision
Kollektiv is licensed under a modified version of the Apache License 2.0. While it allows for free use, modification, and distribution for non-commercial purposes, any commercial use requires explicit permission from the copyright owner.
- For non-commercial use: You are free to use, modify, and distribute this software under the terms of the Apache License 2.0.
- For commercial use: Please contact [email protected] to obtain a commercial license.
See the LICENSE file for the full license text and additional conditions.
The project has been renamed from OmniClaude to Kollektiv to:
- avoid confusion / unintended copyright infringement of Anthropic
- emphasize the goal to become a tool to enhance collaboration through simplifying access to knowledge
- overall cool name (isn't it?)
If you have any questions regarding the renaming, feel free to reach out.
- FireCrawl for superb web crawling
- Chroma DB for easy vector storage and retrieval
- Anthropic for Claude 3.5 Sonnet
- OpenAI for text embeddings
- Cohere for re-ranking capabilities
For any questions or issues, please open an issue
Built with ❤️ by AZ
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kollektiv
Similar Open Source Tools
kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

plandex
Plandex is an open source, terminal-based AI coding engine designed for complex tasks. It uses long-running agents to break up large tasks into smaller subtasks, helping users work through backlogs, navigate unfamiliar technologies, and save time on repetitive tasks. Plandex supports various AI models, including OpenAI, Anthropic Claude, Google Gemini, and more. It allows users to manage context efficiently in the terminal, experiment with different approaches using branches, and review changes before applying them. The tool is platform-independent and runs from a single binary with no dependencies.
promptbook
Promptbook is a library designed to build responsible, controlled, and transparent applications on top of large language models (LLMs). It helps users overcome limitations of LLMs like hallucinations, off-topic responses, and poor quality output by offering features such as fine-tuning models, prompt-engineering, and orchestrating multiple prompts in a pipeline. The library separates concerns, establishes a common format for prompt business logic, and handles low-level details like model selection and context size. It also provides tools for pipeline execution, caching, fine-tuning, anomaly detection, and versioning. Promptbook supports advanced techniques like Retrieval-Augmented Generation (RAG) and knowledge utilization to enhance output quality.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.

nanobrowser
Nanobrowser is an open-source AI web automation tool that runs in your browser. It is a free alternative to OpenAI Operator with flexible LLM options and a multi-agent system. Nanobrowser offers premium web automation capabilities while keeping users in complete control, with features like a multi-agent system, interactive side panel, task automation, follow-up questions, and multiple LLM support. Users can easily download and install Nanobrowser as a Chrome extension, configure agent models, and accomplish tasks such as news summary, GitHub research, and shopping research with just a sentence. The tool uses a specialized multi-agent system powered by large language models to understand and execute complex web tasks. Nanobrowser is actively developed with plans to expand LLM support, implement security measures, optimize memory usage, enable session replay, and develop specialized agents for domain-specific tasks. Contributions from the community are welcome to improve Nanobrowser and build the future of web automation.
agent-zero
Agent Zero is a personal and organic AI framework designed to be dynamic, organically growing, and learning as you use it. It is fully transparent, readable, comprehensible, customizable, and interactive. The framework uses the computer as a tool to accomplish tasks, with no single-purpose tools pre-programmed. It emphasizes multi-agent cooperation, complete customization, and extensibility. Communication is key in this framework, allowing users to give proper system prompts and instructions to achieve desired outcomes. Agent Zero is capable of dangerous actions and should be run in an isolated environment. The framework is prompt-based, highly customizable, and requires a specific environment to run effectively.
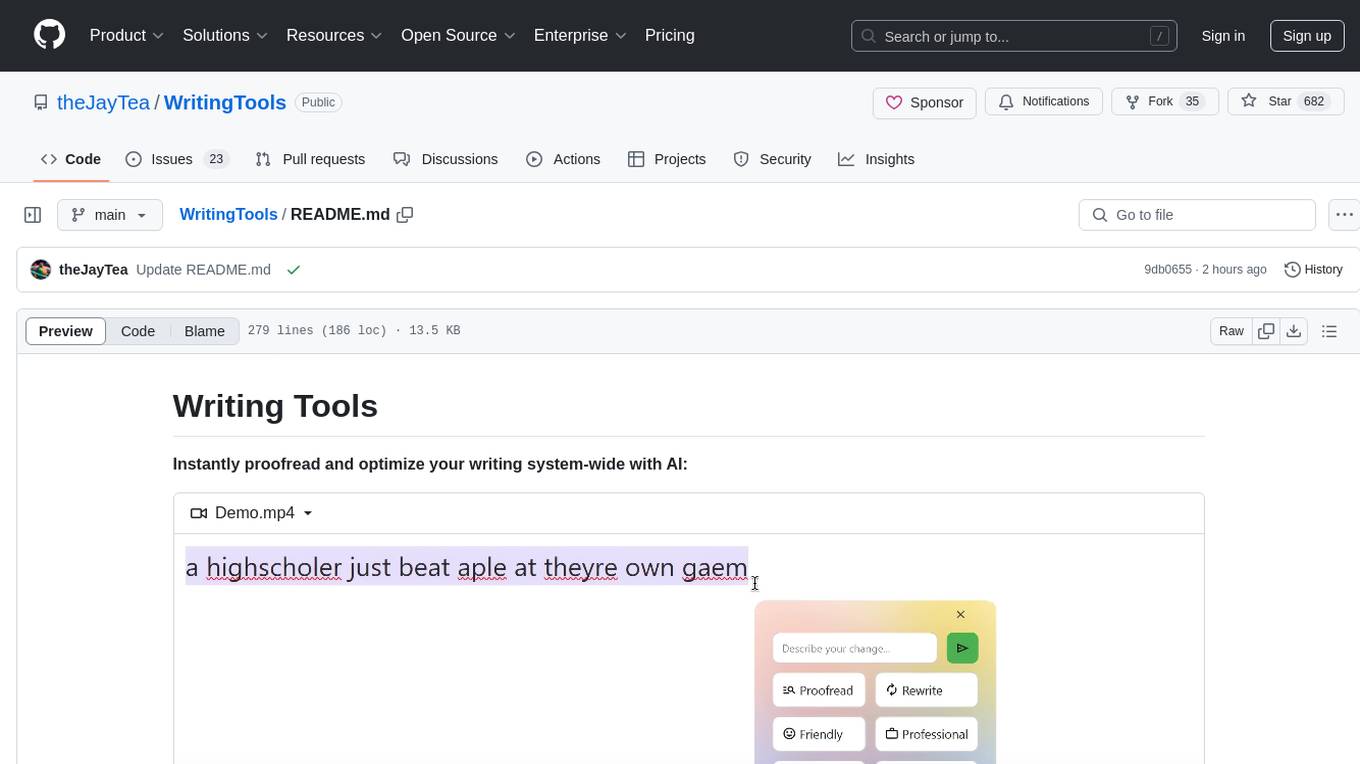
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

Director
Director is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation, etc. It enables users to summarize videos, search for specific moments, create clips instantly, integrate GenAI projects and APIs, add overlays, generate thumbnails, and more. Built on VideoDB's 'video-as-data' infrastructure, Director is perfect for developers, creators, and teams looking to simplify media workflows and unlock new possibilities.

AIOStreams
AIOStreams is a versatile tool that combines streams from various addons into one platform, offering extensive customization options. Users can change result formats, filter results by various criteria, remove duplicates, prioritize services, sort results, specify size limits, and more. The tool scrapes results from selected addons, applies user configurations, and presents the results in a unified manner. It simplifies the process of finding and accessing desired content from multiple sources, enhancing user experience and efficiency.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.
UFO
UFO is a UI-focused dual-agent framework to fulfill user requests on Windows OS by seamlessly navigating and operating within individual or spanning multiple applications.
For similar tasks
kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
simba
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.
Kori
Kori is a unified note-taking app with AI capabilities, providing a consistent experience across Android, iOS, Windows, macOS, and Linux. It supports various formats like Drawing, Markdown, TXT, LaTeX, Mermaid diagrams, and Todo.txt lists. Users can benefit from AI co-writing features, note outline generation, find and replace, note templates, local media support, and export options. The app follows Material Design 3 guidelines, offers comprehensive mouse and keyboard support, and is optimized for different screen sizes and orientations.
docs-mcp-server
The docs-mcp-server repository contains the server-side code for the documentation management system. It provides functionalities for managing, storing, and retrieving documentation files. Users can upload, update, and delete documents through the server. The server also supports user authentication and authorization to ensure secure access to the documentation system. Additionally, the server includes APIs for integrating with other systems and tools, making it a versatile solution for managing documentation in various projects and organizations.
react-native-rag
React Native RAG is a library that enables private, local RAGs to supercharge LLMs with a custom knowledge base. It offers modular and extensible components like `LLM`, `Embeddings`, `VectorStore`, and `TextSplitter`, with multiple integration options. The library supports on-device inference, vector store persistence, and semantic search implementation. Users can easily generate text responses, manage documents, and utilize custom components for advanced use cases.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.