
simba
Portable KMS (knowledge management system) designed to integrate seamlessly with any Retrieval-Augmented Generation (RAG) system
Stars: 1152
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.
README:
![]()
Connect your knowledge to any RAG system







Simba is an open-source, portable Knowledge Management System (KMS) designed specifically for seamless integration with Retrieval-Augmented Generation (RAG) systems. With its intuitive UI, modular architecture, and powerful SDK, Simba simplifies knowledge management, allowing developers to focus on building advanced AI solutions.
- 🔌 Powerful SDK: Comprehensive Python SDK for easy integration.
- 🧩 Modular Architecture: Flexible integration of vector stores, embedding models, chunkers, and parsers.
- 🖥️ Modern UI: User-friendly interface for managing document chunks.
- 🔗 Seamless Integration: Effortlessly connects with any RAG-based system.
- 👨💻 Developer-Centric: Simplifies complex knowledge management tasks.
- 📦 Open Source & Extensible: Community-driven with extensive customization options.

Ensure you have the following installed:
pip install simba-clientLeverage Simba's SDK for powerful programmatic access:
from simba_sdk import SimbaClient
client = SimbaClient(api_url="http://localhost:8000") # you need to install simba-core and run simba server first
document = client.documents.create(file_path="path/to/your/document.pdf")
document_id = document[0]["id"]
parsing_result = client.parser.parse_document(document_id, parser="docling", sync=True)
retrieval_results = client.retriever.retrieve(query="your-query")
for result in retrieval_results["documents"]:
print(f"Content: {result['page_content']}")
print(f"Metadata: {result['metadata']['source']}")
print("====" * 10)Explore more in the Simba SDK documentation.
Install Simba core :
pip install simba-coreOr Clone and set up the repository:
git clone https://github.com/GitHamza0206/simba.git
cd simba
poetry config virtualenvs.in-project true
poetry install
source .venv/bin/activateCreate a .env file:
OPENAI_API_KEY=your_openai_api_key
REDIS_HOST=localhost
CELERY_BROKER_URL=redis://localhost:6379/0
CELERY_RESULT_BACKEND=redis://localhost:6379/1Configure config.yaml:
# config.yaml
project:
name: "Simba"
version: "1.0.0"
api_version: "/api/v1"
paths:
base_dir: null # Will be set programmatically
faiss_index_dir: "vector_stores/faiss_index"
vector_store_dir: "vector_stores"
llm:
provider: "openai"
model_name: "gpt-4o-mini"
temperature: 0.0
max_tokens: null
streaming: true
additional_params: {}
embedding:
provider: "huggingface"
model_name: "BAAI/bge-base-en-v1.5"
device: "mps" # Changed from mps to cpu for container compatibility
additional_params: {}
vector_store:
provider: "faiss"
collection_name: "simba_collection"
additional_params: {}
chunking:
chunk_size: 512
chunk_overlap: 200
retrieval:
method: "hybrid" # Options: default, semantic, keyword, hybrid, ensemble, reranked
k: 5
# Method-specific parameters
params:
# Semantic retrieval parameters
score_threshold: 0.5
# Hybrid retrieval parameters
prioritize_semantic: true
# Ensemble retrieval parameters
weights: [0.7, 0.3] # Weights for semantic and keyword retrievers
# Reranking parameters
reranker_model: colbert
reranker_threshold: 0.7
# Database configuration
database:
provider: litedb # Options: litedb, sqlite
additional_params: {}
celery:
broker_url: ${CELERY_BROKER_URL:-redis://redis:6379/0}
result_backend: ${CELERY_RESULT_BACKEND:-redis://redis:6379/1}Start the server, frontend, and parsers:
simba server
simba front
simba parsersDeploy Simba using Docker:
- CPU:
DEVICE=cpu make build
DEVICE=cpu make up- NVIDIA GPU:
DEVICE=cuda make build
DEVICE=cuda make up- Apple Silicon:
DEVICE=cpu make build
DEVICE=cpu make up- [x] 💻 pip install simba-core
- [x] 🔧 pip install simba-sdk
- [ ] 🌐 www.simba-docs.com
- [ ] 🔒 Auth & access management
- [ ] 🕸️ Web scraping
- [ ] ☁️ Cloud integrations (Azure/AWS/GCP)
- [ ] 📚 Additional parsers and chunkers
- [ ] 🎨 Enhanced UX/UI
We welcome contributions! Follow these steps:
- Fork the repository
- Create a feature or bugfix branch
- Commit clearly documented changes
- Submit a pull request
For support or inquiries, open an issue on GitHub or contact Hamza Zerouali.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for simba
Similar Open Source Tools
simba
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
sdk
The Kubeflow SDK is a set of unified Pythonic APIs that simplify running AI workloads at any scale without needing to learn Kubernetes. It offers consistent APIs across the Kubeflow ecosystem, enabling users to focus on building AI applications rather than managing complex infrastructure. The SDK provides a unified experience, simplifies AI workloads, is built for scale, allows rapid iteration, and supports local development without a Kubernetes cluster.
local-cocoa
Local Cocoa is a privacy-focused tool that runs entirely on your device, turning files into memory to spark insights and power actions. It offers features like fully local privacy, multimodal memory, vector-powered retrieval, intelligent indexing, vision understanding, hardware acceleration, focused user experience, integrated notes, and auto-sync. The tool combines file ingestion, intelligent chunking, and local retrieval to build a private on-device knowledge system. The ultimate goal includes more connectors like Google Drive integration, voice mode for local speech-to-text interaction, and a plugin ecosystem for community tools and agents. Local Cocoa is built using Electron, React, TypeScript, FastAPI, llama.cpp, and Qdrant.
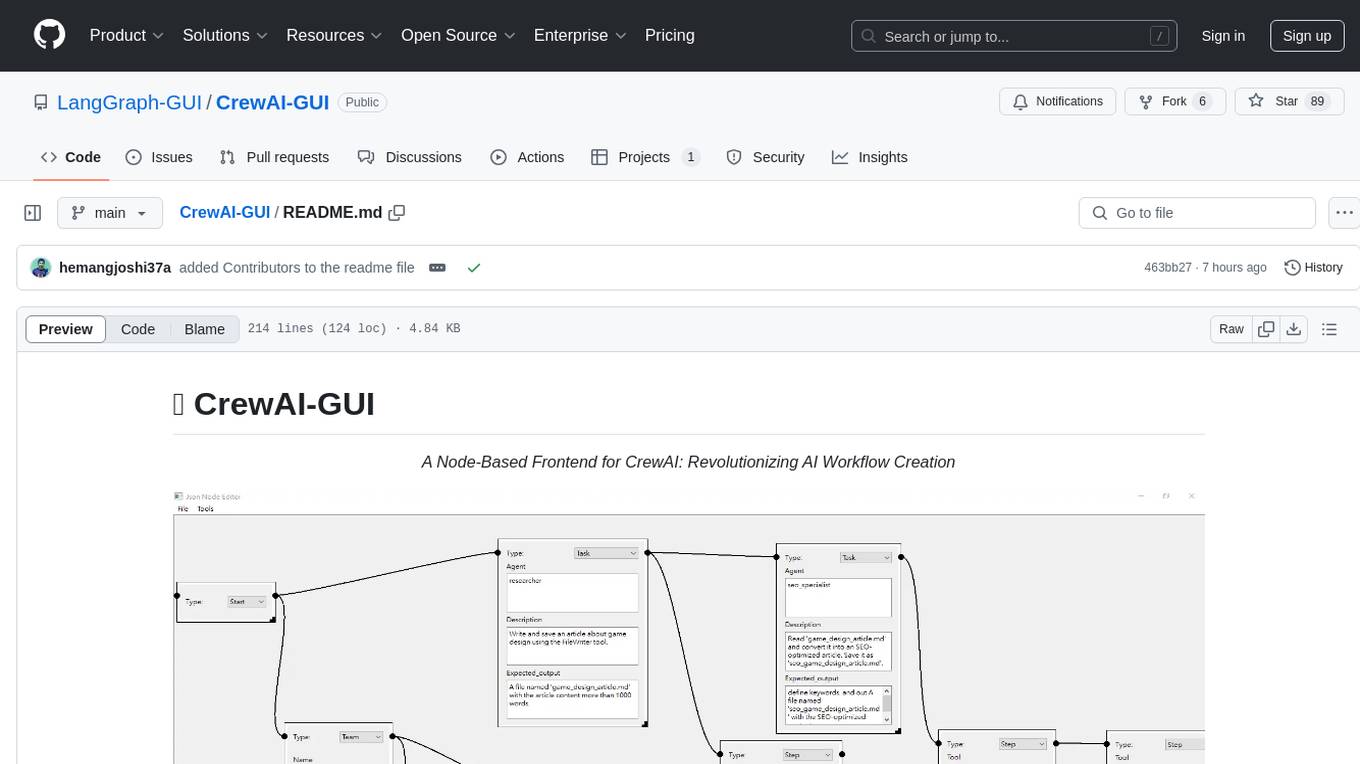
CrewAI-GUI
CrewAI-GUI is a Node-Based Frontend tool designed to revolutionize AI workflow creation. It empowers users to design complex AI agent interactions through an intuitive drag-and-drop interface, export designs to JSON for modularity and reusability, and supports both GPT-4 API and Ollama for flexible AI backend. The tool ensures cross-platform compatibility, allowing users to create AI workflows on Windows, Linux, or macOS efficiently.
lean-spec
LeanSpec is a tool for Spec-Driven Development that aims to help users ship faster with higher quality by creating small, focused documents that both humans and AI can understand. It provides features like Kanban board, smart search, dependency tracking, web UI, project stats, and AI integration. The tool is designed to work with various AI coding assistants and offers agent skills to teach AI the Spec-Driven Development methodology. LeanSpec is compatible with tools like VS Code Copilot, Claude Code, GitHub Copilot, and more, and it requires Node.js, pnpm, and Rust for development. The desktop app has a separate repository for development, and the tool supports common development tasks like testing, building, and documentation.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

InsForge
InsForge is a backend development platform designed for AI coding agents and AI code editors. It serves as a semantic layer that enables agents to interact with backend primitives such as databases, authentication, storage, and functions in a meaningful way. The platform allows agents to fetch backend context, configure primitives, and inspect backend state through structured schemas. InsForge facilitates backend context engineering for AI coding agents to understand, operate, and monitor backend systems effectively.
browser4
Browser4 is a lightning-fast, coroutine-safe browser designed for AI integration with large language models. It offers ultra-fast automation, deep web understanding, and powerful data extraction APIs. Users can automate the browser, extract data at scale, and perform tasks like summarizing products, extracting product details, and finding specific links. The tool is developer-friendly, supports AI-powered automation, and provides advanced features like X-SQL for precise data extraction. It also offers RPA capabilities, browser control, and complex data extraction with X-SQL. Browser4 is suitable for web scraping, data extraction, automation, and AI integration tasks.
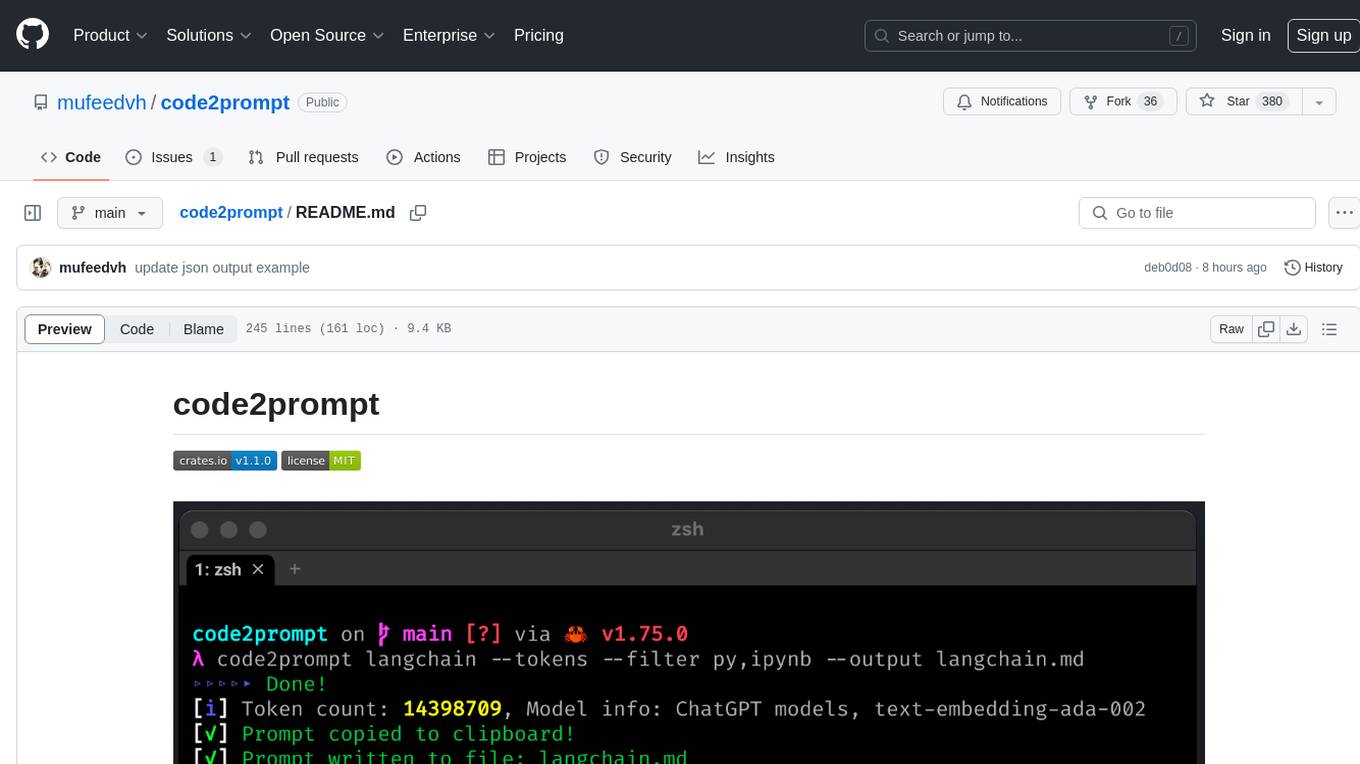
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
BookWorm
BookWorm is a cloud-native application showcasing Aspire with AI integration. It features DDD and VSA, multi-agent orchestration, standardized AI tooling through MCP, A2A & AG-UI Protocol support, and various microservices patterns. The project includes API versioning, feature flags, AuthN/AuthZ with Keycloak, caching with HybridCache, CI/CD with GitHub Actions, comprehensive documentation, modern client applications with Next.js, testing strategies, and more.
zotero-mcp
Zotero MCP is an open-source project that integrates AI capabilities with Zotero using the Model Context Protocol. It consists of a Zotero plugin and an MCP server, enabling AI assistants to search, retrieve, and cite references from Zotero library. The project features a unified architecture with an integrated MCP server, eliminating the need for a separate server process. It provides features like intelligent search, detailed reference information, filtering by tags and identifiers, aiding in academic tasks such as literature reviews and citation management.

Lumina-Note
Lumina Note is a local-first AI note-taking app designed to help users write, connect, and evolve knowledge with AI capabilities while ensuring data ownership. It offers a knowledge-centered workflow with features like Markdown editor, WikiLinks, and graph view. The app includes AI workspace modes such as Chat, Agent, Deep Research, and Codex, along with support for multiple model providers. Users can benefit from bidirectional links, LaTeX support, graph visualization, PDF reader with annotations, real-time voice input, and plugin ecosystem for extended functionalities. Lumina Note is built on Tauri v2 framework with a tech stack including React 18, TypeScript, Tailwind CSS, and SQLite for vector storage.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
For similar tasks
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
simba
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

cherry-studio
Cherry Studio is a desktop client that supports multiple LLM providers on Windows, Mac, and Linux. It offers diverse LLM provider support, AI assistants & conversations, document & data processing, practical tools integration, and enhanced user experience. The tool includes features like support for major LLM cloud services, AI web service integration, local model support, pre-configured AI assistants, document processing for text, images, and more, global search functionality, topic management system, AI-powered translation, and cross-platform support with ready-to-use features and themes for a better user experience.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.
Kori
Kori is a unified note-taking app with AI capabilities, providing a consistent experience across Android, iOS, Windows, macOS, and Linux. It supports various formats like Drawing, Markdown, TXT, LaTeX, Mermaid diagrams, and Todo.txt lists. Users can benefit from AI co-writing features, note outline generation, find and replace, note templates, local media support, and export options. The app follows Material Design 3 guidelines, offers comprehensive mouse and keyboard support, and is optimized for different screen sizes and orientations.
docs-mcp-server
The docs-mcp-server repository contains the server-side code for the documentation management system. It provides functionalities for managing, storing, and retrieving documentation files. Users can upload, update, and delete documents through the server. The server also supports user authentication and authorization to ensure secure access to the documentation system. Additionally, the server includes APIs for integrating with other systems and tools, making it a versatile solution for managing documentation in various projects and organizations.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.