
BrowserAI
Run local LLMs inside your browser
Stars: 590
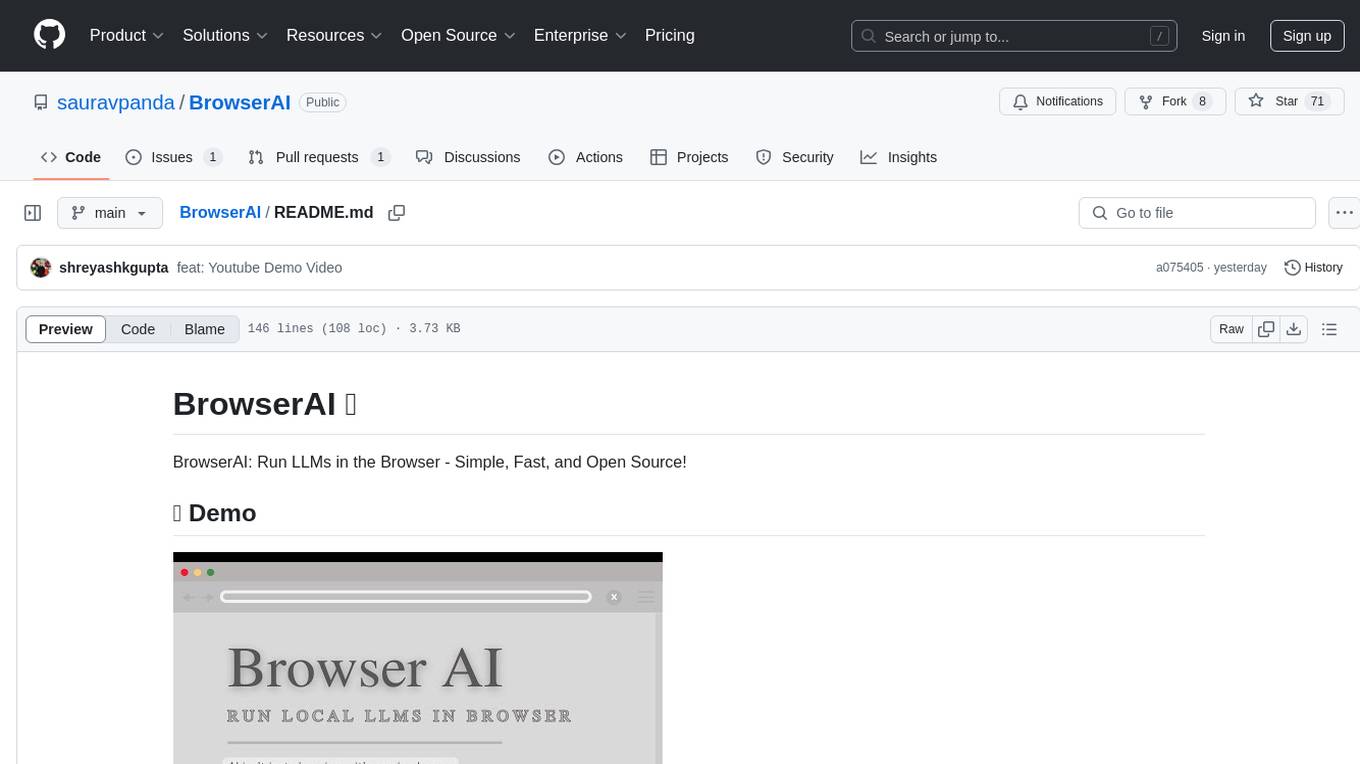
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.
README:
| Demo | Description | Try It |
|---|---|---|
| Chat | Multi-model chat interface | chat.browserai.dev |
| Voice Chat | Full-featured with speech recognition & TTS | voice-demo.browserai.dev |
| Text-to-Speech | Powered by Kokoro 82M | tts-demo.browserai.dev |
- 🔒 100% Private: All processing happens locally in your browser
- 🚀 WebGPU Accelerated: Near-native performance
- 💰 Zero Server Costs: No complex infrastructure needed
- 🌐 Offline Capable: Works without internet after initial download
- 🎯 Developer Friendly: Simple sdk with multiple engine support
- 📦 Production Ready: Pre-optimized popular models
- Web developers building AI-powered applications
- Companies needing privacy-conscious AI solutions
- Researchers experimenting with browser-based AI
- Hobbyists exploring AI without infrastructure overhead
- 🎯 Run AI models directly in the browser - no server required!
- ⚡ WebGPU acceleration for blazing fast inference
- 🔄 Seamless switching between MLC and Transformers engines
- 📦 Pre-configured popular models ready to use
- 🛠️ Easy-to-use API for text generation and more
npm install @browserai/browseraiOR
yarn add @browserai/browseraiimport { BrowserAI } from '@browserai/browserai';
const browserAI = new BrowserAI();
browserAI.loadModel('llama-3.2-1b-instruct');
const response = await browserAI.generateText('Hello, how are you?');
console.log(response);const ai = new BrowserAI();
await ai.loadModel('llama-3.2-1b-instruct', {
quantization: 'q4f16_1' // Optimize for size/speed
});
const response = await ai.generateText('Write a short poem about coding', {
temperature: 0.8,
maxTokens: 100
});const ai = new BrowserAI();
await ai.loadModel('gemma-2b-it');
const response = await ai.generateText([
{ role: 'system', content: 'You are a helpful assistant.' },
{ role: 'user', content: 'What is WebGPU?' }
]);const ai = new BrowserAI();
await ai.loadModel('whisper-tiny-en');
// Using the built-in recorder
await ai.startRecording();
const audioBlob = await ai.stopRecording();
const transcription = await ai.transcribeAudio(audioBlob);const ai = new BrowserAI();
await ai.loadModel('kokoro-tts');
const audioBuffer = await ai.textToSpeech('Hello, how are you today?');
// Play the audio using Web Audio API
const audioContext = new AudioContext();
const source = audioContext.createBufferSource();
audioContext.decodeAudioData(audioBuffer, (buffer) => {
source.buffer = buffer;
source.connect(audioContext.destination);
source.start(0);
});More models will be added soon. Request a model by creating an issue.
- Llama-3.2-1b-Instruct
- SmolLM2-135M-Instruct
- SmolLM2-360M-Instruct
- SmolLM2-1.7B-Instruct
- Qwen-0.5B-Instruct
- Gemma-2B-IT
- TinyLlama-1.1B-Chat-v0.4
- Phi-3.5-mini-instruct
- Qwen2.5-1.5B-Instruct
- Llama-3.2-1b-Instruct
- Whisper-tiny-en (Speech Recognition)
- Kokoro-TTS (Text-to-Speech)
- 🎯 Simplified model initialization
- 📊 Basic monitoring and metrics
- 🔍 Simple RAG implementation
- 🛠️ Developer tools integration
- 📚 Enhanced RAG capabilities
- Hybrid search
- Auto-chunking
- Source tracking
- 📊 Advanced observability
- Performance dashboards
- Memory profiling
- Error tracking
- 🔐 Security features
- 📈 Advanced analytics
- 🤝 Multi-model orchestration
We welcome contributions! Feel free to:
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
- MLC AI for their incredible mode compilation library and support for webgpu runtime and xgrammar
- Hugging Face and Xenova for their Transformers.js library, licensed under Apache License 2.0. The original code has been modified to work in a browser environment and converted to TypeScript.
- All our contributors and supporters!
Made with ❤️ for the AI community
- Modern browser with WebGPU support (Chrome 113+, Edge 113+, or equivalent)
- For models with
shader-f16requirement, hardware must support 16-bit floating point operations
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BrowserAI
Similar Open Source Tools
BrowserAI
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
zcf
ZCF (Zero-Config Claude-Code Flow) is a tool that provides zero-configuration, one-click setup for Claude Code with bilingual support, intelligent agent system, and personalized AI assistant. It offers an interactive menu for easy operations and direct commands for quick execution. The tool supports bilingual operation with automatic language switching and customizable AI output styles. ZCF also includes features like BMad Workflow for enterprise-grade workflow system, Spec Workflow for structured feature development, CCR (Claude Code Router) support for proxy routing, and CCometixLine for real-time usage tracking. It provides smart installation, complete configuration management, and core features like professional agents, command system, and smart configuration. ZCF is cross-platform compatible, supports Windows and Termux environments, and includes security features like dangerous operation confirmation mechanism.
enferno
Enferno is a modern Flask framework optimized for AI-assisted development workflows. It combines carefully crafted development patterns, smart Cursor Rules, and modern libraries to enable developers to build sophisticated web applications with unprecedented speed. Enferno's intelligent patterns and contextual guides help create production-ready SAAS applications faster than ever. It includes features like modern stack, authentication, OAuth integration, database support, task queue, frontend components, security measures, Docker readiness, and more.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.
trpc-agent-go
A powerful Go framework for building intelligent agent systems with large language models (LLMs), hierarchical planners, memory, telemetry, and a rich tool ecosystem. tRPC-Agent-Go enables the creation of autonomous or semi-autonomous agents that reason, call tools, collaborate with sub-agents, and maintain long-term state. The framework provides detailed documentation, examples, and tools for accelerating the development of AI applications.
tunacode
TunaCode CLI is an AI-powered coding assistant that provides a command-line interface for developers to enhance their coding experience. It offers features like model selection, parallel execution for faster file operations, and various commands for code management. The tool aims to improve coding efficiency and provide a seamless coding environment for developers.
llm-context.py
LLM Context is a tool designed to assist developers in quickly injecting relevant content from code/text projects into Large Language Model chat interfaces. It leverages `.gitignore` patterns for smart file selection and offers a streamlined clipboard workflow using the command line. The tool also provides direct integration with Large Language Models through the Model Context Protocol (MCP). LLM Context is optimized for code repositories and collections of text/markdown/html documents, making it suitable for developers working on projects that fit within an LLM's context window. The tool is under active development and aims to enhance AI-assisted development workflows by harnessing the power of Large Language Models.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
dive
Dive is an AI toolkit for Go that enables the creation of specialized teams of AI agents and seamless integration with leading LLMs. It offers a CLI and APIs for easy integration, with features like creating specialized agents, hierarchical agent systems, declarative configuration, multiple LLM support, extended reasoning, model context protocol, advanced model settings, tools for agent capabilities, tool annotations, streaming, CLI functionalities, thread management, confirmation system, deep research, and semantic diff. Dive also provides semantic diff analysis, unified interface for LLM providers, tool system with annotations, custom tool creation, and support for various verified models. The toolkit is designed for developers to build AI-powered applications with rich agent capabilities and tool integrations.
orra
Orra is a tool for building production-ready multi-agent applications that handle complex real-world interactions. It coordinates tasks across existing stack, agents, and tools run as services using intelligent reasoning. With features like smart pre-evaluated execution plans, domain grounding, durable execution, and automatic service health monitoring, Orra enables users to go fast with tools as services and revert state to handle failures. It provides real-time status tracking and webhook result delivery, making it ideal for developers looking to move beyond simple crews and agents.
dotclaude
A sophisticated multi-agent configuration system for Claude Code that provides specialized agents and command templates to accelerate code review, refactoring, security audits, tech-lead-guidance, and UX evaluations. It offers essential commands, directory structure details, agent system overview, command templates, usage patterns, collaboration philosophy, sync management, advanced usage guidelines, and FAQ. The tool aims to streamline development workflows, enhance code quality, and facilitate collaboration between developers and AI agents.
LongLLaVA
LongLLaVA is a tool for scaling multi-modal LLMs to 1000 images efficiently via hybrid architecture. It includes stages for single-image alignment, instruction-tuning, and multi-image instruction-tuning, with evaluation through a command line interface and model inference. The tool aims to achieve GPT-4V level capabilities and beyond, providing reproducibility of results and benchmarks for efficiency and performance.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
Shellsage
Shell Sage is an intelligent terminal companion and AI-powered terminal assistant that enhances the terminal experience with features like local and cloud AI support, context-aware error diagnosis, natural language to command translation, and safe command execution workflows. It offers interactive workflows, supports various API providers, and allows for custom model selection. Users can configure the tool for local or API mode, select specific models, and switch between modes easily. Currently in alpha development, Shell Sage has known limitations like limited Windows support and occasional false positives in error detection. The roadmap includes improvements like better context awareness, Windows PowerShell integration, Tmux integration, and CI/CD error pattern database.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.