
TrustEval-toolkit
[NAACL 25 Demo] TrustEval: A modular and extensible toolkit for comprehensive trust evaluation of generative foundation models (GenFMs)
Stars: 95

TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
README:
![]()



Watch step-by-step tutorials on our YouTube channel:
https://github.com/user-attachments/assets/489501b9-69ae-467f-9be3-e4a02a7f9019
- Video Tutorials
- 📍 Overview
- 👾 Features
- 🚀 Getting Started
- Trustworthiness Report
- Contributing
- Citation
- License
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more.

- Dynamic Dataset Generation: Automatically generate datasets tailored for evaluation tasks.
- Multi-Model Compatibility: Evaluate LLMs, VLMs, T2I models, and more.
- Customizable Metrics: Configure workflows with flexible metrics and evaluation methods.
- Metadata-Driven Pipelines: Design and execute test cases efficiently using metadata.
- Comprehensive Dimensions: Evaluate models across safety, fairness, robustness, privacy, and truthfulness.
- Optimized Inference: Faster evaluations with optimized inference pipelines.
- Detailed Reports: Generate interactive, easy-to-interpret evaluation reports.
To install the TrustEval-toolkit, follow these steps:
git clone https://github.com/nauyisu022/TrustEval-toolkit.git
cd TrustEval-toolkitCreate and activate a new environment with Python 3.10:
conda create -n trusteval_env python=3.10
conda activate trusteval_envInstall the package and its dependencies:
pip install .Run the configuration script to set up your API keys:
python trusteval/src/configuration.py
The following example demonstrates an Advanced AI Risk Evaluation workflow.
import os
base_dir = os.getcwd() + '/advanced_ai_risk'from trusteval import download_metadata
download_metadata(
section='advanced_ai_risk',
output_path=base_dir
)from trusteval.dimension.ai_risk import dynamic_dataset_generator
dynamic_dataset_generator(
base_dir=base_dir,
)from trusteval import contextual_variator_cli
contextual_variator_cli(
dataset_folder=base_dir
)from trusteval import generate_responses
request_type = ['llm'] # Options: 'llm', 'vlm', 't2i'
async_list = ['your_async_model']
sync_list = ['your_sync_model']
await generate_responses(
data_folder=base_dir,
request_type=request_type,
async_list=async_list,
sync_list=sync_list,
)-
Judge the Responses
from trusteval import judge_responses target_models = ['your_target_model1', 'your_target_model2'] judge_type = 'llm' # Options: 'llm', 'vlm', 't2i' judge_key = 'your_judge_key' async_judge_model = ['your_async_model'] await judge_responses( data_folder=base_dir, async_judge_model=async_judge_model, target_models=target_models, judge_type=judge_type, )
-
Generate Evaluation Metrics
from trusteval import lm_metric lm_metric( base_dir=base_dir, aspect='ai_risk', model_list=target_models, )
-
Generate Final Report
from trusteval import report_generator report_generator( base_dir=base_dir, aspect='ai_risk', model_list=target_models, )
Your report.html will be saved in the base_dir folder. For additional examples, check the examples folder.
A detailed trustworthiness evaluation report is generated for each dimension. The reports are presented as interactive web pages, which can be opened in a browser to explore the results. The report includes the following sections:
The data shown in the images below is simulated and does not reflect actual results.
Displays the evaluation scores for each model, with a breakdown of average scores across evaluation dimensions.

Summarizes the model's performance in the evaluated dimension using LLM-generated summaries, highlighting comparisons with other models.

Presents error cases for the evaluated dimension, including input/output examples and detailed judgments.

Shows the evaluation results for all models, along with visualized comparisons to previous versions (e.g., our v1.0 results).

We welcome contributions from the community! To contribute:
- Fork the repository.
- Create a feature branch (
git checkout -b feature-name). - Commit your changes (
git commit -m 'Add feature'). - Push to your branch (
git push origin feature-name). - Open a pull request.
@article{huang2025trustgen,
title={On the Trustworthiness of Generative Foundation Models: Guideline, Assessment, and Perspective},
author={Yue Huang and Chujie Gao and Siyuan Wu and Haoran Wang and Xiangqi Wang and Yujun Zhou and Yanbo Wang and Jiayi Ye and Jiawen Shi and Qihui Zhang and Yuan Li and Han Bao and Zhaoyi Liu and Tianrui Guan and Dongping Chen and Ruoxi Chen and Kehan Guo and Andy Zou and Bryan Hooi Kuen-Yew and Caiming Xiong and Elias Stengel-Eskin and Hongyang Zhang and Hongzhi Yin and Huan Zhang and Huaxiu Yao and Jaehong Yoon and Jieyu Zhang and Kai Shu and Kaijie Zhu and Ranjay Krishna and Swabha Swayamdipta and Taiwei Shi and Weijia Shi and Xiang Li and Yiwei Li and Yuexing Hao and Zhihao Jia and Zhize Li and Xiuying Chen and Zhengzhong Tu and Xiyang Hu and Tianyi Zhou and Jieyu Zhao and Lichao Sun and Furong Huang and Or Cohen Sasson and Prasanna Sattigeri and Anka Reuel and Max Lamparth and Yue Zhao and Nouha Dziri and Yu Su and Huan Sun and Heng Ji and Chaowei Xiao and Mohit Bansal and Nitesh V. Chawla and Jian Pei and Jianfeng Gao and Michael Backes and Philip S. Yu and Neil Zhenqiang Gong and Pin-Yu Chen and Bo Li and Xiangliang Zhang},
journal={arXiv preprint arXiv:2502.14296},
year={2025}
}This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TrustEval-toolkit
Similar Open Source Tools
TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
QuantaAlpha
QuantaAlpha is a framework designed for factor mining in quantitative alpha research. It combines LLM intelligence with evolutionary strategies to automatically mine, evolve, and validate alpha factors through self-evolving trajectories. The framework provides a trajectory-based approach with diversified planning initialization and structured hypothesis-code constraint. Users can describe their research direction and observe the automatic factor mining process. QuantaAlpha aims to transform how quantitative alpha factors are discovered by leveraging advanced technologies and self-evolving methodologies.
ctinexus
CTINexus is a framework that leverages optimized in-context learning of large language models to automatically extract cyber threat intelligence from unstructured text and construct cybersecurity knowledge graphs. It processes threat intelligence reports to extract cybersecurity entities, identify relationships between security concepts, and construct knowledge graphs with interactive visualizations. The framework requires minimal configuration, with no extensive training data or parameter tuning needed.
alphora
Alphora is a full-stack framework for building production AI agents, providing agent orchestration, prompt engineering, tool execution, memory management, streaming, and deployment with an async-first, OpenAI-compatible design. It offers features like agent derivation, reasoning-action loop, async streaming, visual debugger, OpenAI compatibility, multimodal support, tool system with zero-config tools and type safety, prompt engine with dynamic prompts, memory and storage management, sandbox for secure execution, deployment as API, and more. Alphora allows users to build sophisticated AI agents easily and efficiently.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
afc-crs-all-you-need-is-a-fuzzing-brain
All You Need Is A Fuzzing Brain is an AI-driven automated vulnerability detection and remediation framework developed for the 2025 DARPA AIxCC finals. It leverages multiple LLM providers for intelligent vulnerability detection, offers 23+ specialized strategies for POV generation and patch synthesis, generates and validates patches automatically, integrates seamlessly with Google's fuzzing infrastructure, and supports vulnerability detection in C/C++ and Java. Users can perform tasks such as Delta Scan, Full Scan, and SARIF Analysis for specific commits, repository-wide analysis, and validation/patching from static analysis reports, respectively. The tool can be used via Docker or by installing from source, and citations are provided for research purposes.

routilux
Routilux is a powerful event-driven workflow orchestration framework designed for building complex data pipelines and workflows effortlessly. It offers features like event queue architecture, flexible connections, built-in state management, robust error handling, concurrent execution, persistence & recovery, and simplified API. Perfect for tasks such as data pipelines, API orchestration, event processing, workflow automation, microservices coordination, and LLM agent workflows.
trpc-agent-go
A powerful Go framework for building intelligent agent systems with large language models (LLMs), hierarchical planners, memory, telemetry, and a rich tool ecosystem. tRPC-Agent-Go enables the creation of autonomous or semi-autonomous agents that reason, call tools, collaborate with sub-agents, and maintain long-term state. The framework provides detailed documentation, examples, and tools for accelerating the development of AI applications.
sdk
The Kubeflow SDK is a set of unified Pythonic APIs that simplify running AI workloads at any scale without needing to learn Kubernetes. It offers consistent APIs across the Kubeflow ecosystem, enabling users to focus on building AI applications rather than managing complex infrastructure. The SDK provides a unified experience, simplifies AI workloads, is built for scale, allows rapid iteration, and supports local development without a Kubernetes cluster.
ai-counsel
AI Counsel is a true deliberative consensus MCP server where AI models engage in actual debate, refine positions across multiple rounds, and converge with voting and confidence levels. It features two modes (quick and conference), mixed adapters (CLI tools and HTTP services), auto-convergence, structured voting, semantic grouping, model-controlled stopping, evidence-based deliberation, local model support, data privacy, context injection, semantic search, fault tolerance, and full transcripts. Users can run local and cloud models to deliberate on various questions, ground decisions in reality by querying code and files, and query past decisions for analysis. The tool is designed for critical technical decisions requiring multi-model deliberation and consensus building.
OpenMemory
OpenMemory is a cognitive memory engine for AI agents, providing real long-term memory capabilities beyond simple embeddings. It is self-hosted and supports Python + Node SDKs, with integrations for various tools like LangChain, CrewAI, AutoGen, and more. Users can ingest data from sources like GitHub, Notion, Google Drive, and others directly into memory. OpenMemory offers explainable traces for recalled information and supports multi-sector memory, temporal reasoning, decay engine, waypoint graph, and more. It aims to provide a true memory system rather than just a vector database with marketing copy, enabling users to build agents, copilots, journaling systems, and coding assistants that can remember and reason effectively.

OpenResearcher
OpenResearcher is a fully open agentic large language model designed for long-horizon deep research scenarios. It achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1, and Tongyi-DeepResearch. The tool is fully open-source, providing the training and evaluation recipe—including data, model, training methodology, and evaluation framework for everyone to progress deep research. It offers features like a fully open-source recipe, highly scalable and low-cost generation of deep research trajectories, and remarkable performance on deep research benchmarks.
LLMTSCS
LLMLight is a novel framework that employs Large Language Models (LLMs) as decision-making agents for Traffic Signal Control (TSC). The framework leverages the advanced generalization capabilities of LLMs to engage in a reasoning and decision-making process akin to human intuition for effective traffic control. LLMLight has been demonstrated to be remarkably effective, generalizable, and interpretable against various transportation-based and RL-based baselines on nine real-world and synthetic datasets.
BrowserAI
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.
nanolang
NanoLang is a minimal, LLM-friendly programming language that transpiles to C for native performance. It features mandatory testing, unambiguous syntax, automatic memory management, LLM-powered autonomous optimization, dual notation for operators, static typing, C interop, and native performance. The language supports variables, functions with mandatory tests, control flow, structs, enums, generic types, and provides a clean, modern syntax optimized for both human readability and AI code generation.
For similar tasks
TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
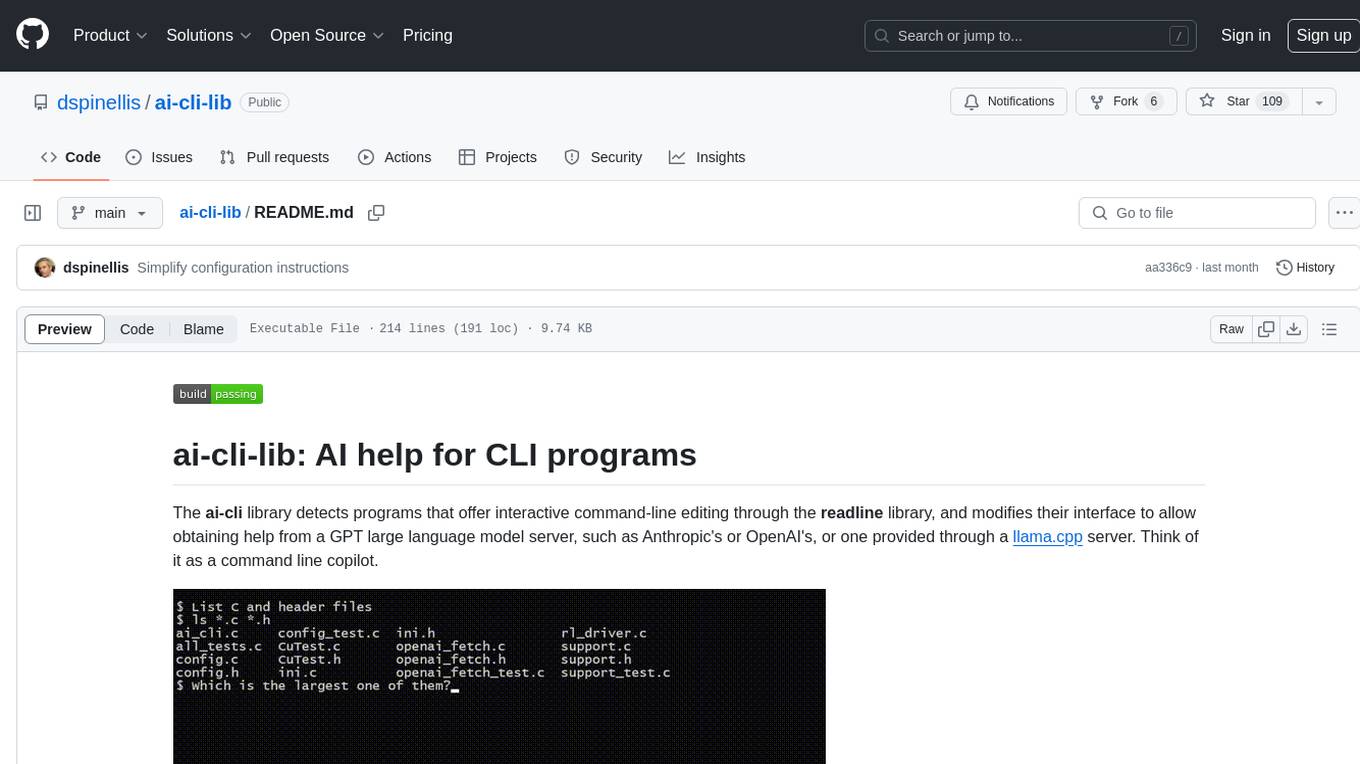
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
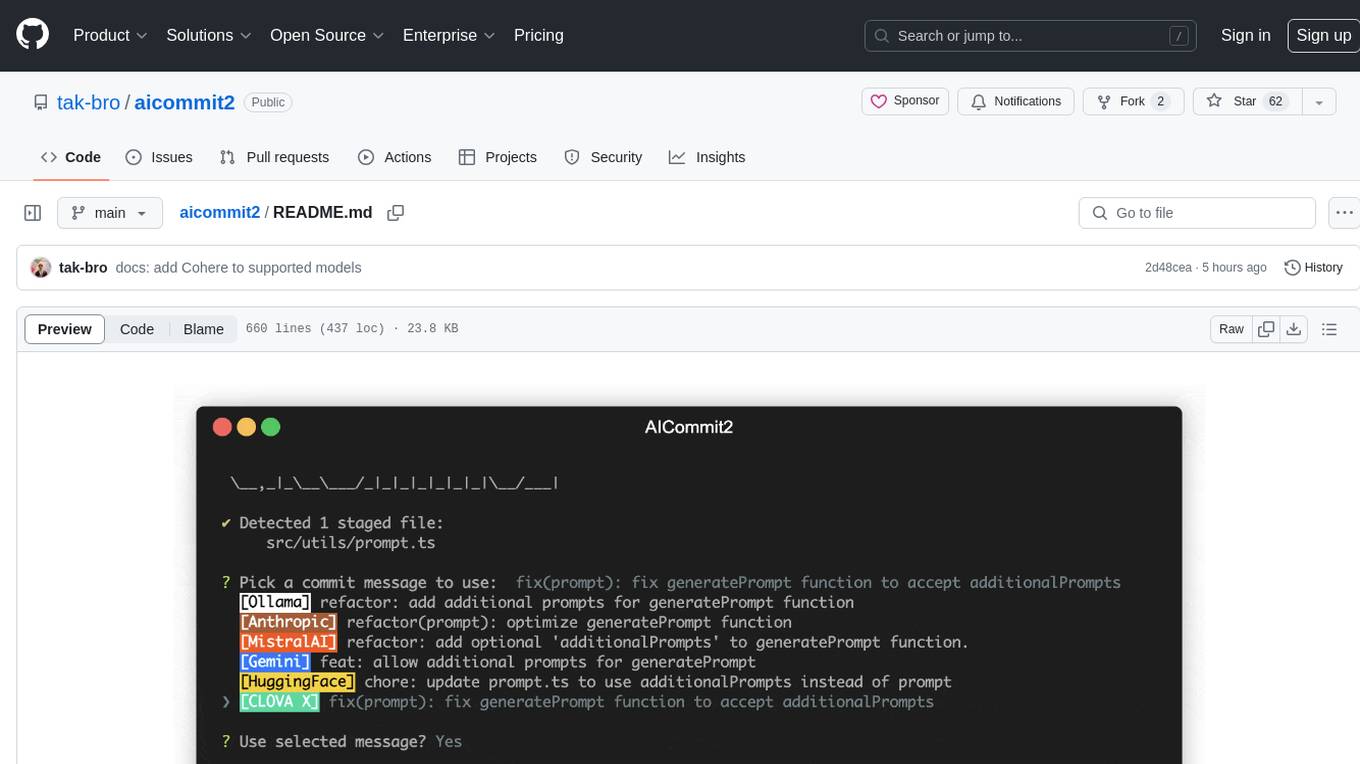
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
prompt-optimizer
Prompt Optimizer is a powerful AI prompt optimization tool that helps you write better AI prompts, improving AI output quality. It supports both web application and Chrome extension usage. The tool features intelligent optimization for prompt words, real-time testing to compare before and after optimization, integration with multiple mainstream AI models, client-side processing for security, encrypted local storage for data privacy, responsive design for user experience, and more.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
OpenClawChineseTranslation
OpenClaw Chinese Translation is a localization project that provides a fully Chinese interface for the OpenClaw open-source personal AI assistant platform. It allows users to interact with their AI assistant through chat applications like WhatsApp, Telegram, and Discord to manage daily tasks such as emails, calendars, and files. The project includes both CLI command-line and dashboard web interface fully translated into Chinese.
openwhispr
OpenWhispr is an open source desktop dictation application that converts speech to text using OpenAI Whisper. It features both local and cloud processing options for maximum flexibility and privacy. The application supports multiple AI providers, customizable hotkeys, agent naming, and various AI processing models. It offers a modern UI built with React 19, TypeScript, and Tailwind CSS v4, and is optimized for speed using Vite and modern tooling. Users can manage settings, view history, configure API keys, and download/manage local Whisper models. The application is cross-platform, supporting macOS, Windows, and Linux, and offers features like automatic pasting, draggable interface, global hotkeys, and compound hotkeys.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.