
aicommit2
A Reactive CLI that generates git commit messages with Ollama, ChatGPT, Gemini, Claude, Mistral and other AI
Stars: 242
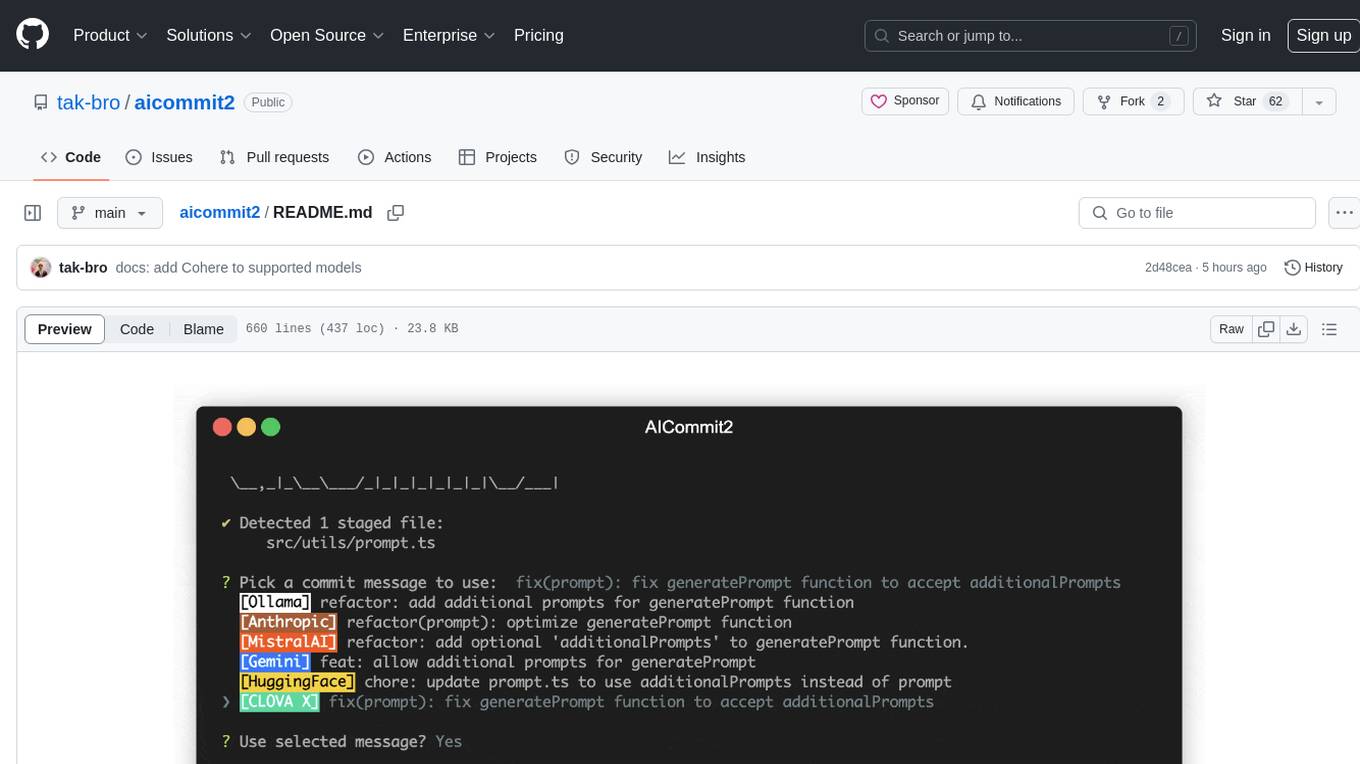
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
README:

A Reactive CLI that generates git commit messages with Ollama, ChatGPT, Gemini, Claude, Mistral and other AI


# Install globally
npm install -g aicommit2
# Set up at least one AI provider
aicommit2 config set OPENAI.key=<your-key>
# Use in your git repository
git add .
aicommit2aicommit2 is a reactive CLI tool that automatically generates Git commit messages using various AI models. It supports simultaneous requests to multiple AI providers, allowing users to select the most suitable commit message. The core functionalities and architecture of this project are inspired by AICommits.
- Multi-AI Support: Integrates with OpenAI, Anthropic Claude, Google Gemini, Mistral AI, Cohere, Groq, Ollama and more.
- OpenAI API Compatibility: Support for any service that implements the OpenAI API specification.
- Reactive CLI: Enables simultaneous requests to multiple AIs and selection of the best commit message.
- Git Hook Integration: Can be used as a prepare-commit-msg hook.
- Custom Prompt: Supports user-defined system prompt templates.
- OpenAI
- Anthropic Claude
- Gemini
- Mistral AI (including Codestral)
- Cohere
- Groq
- Perplexity
- DeepSeek
- Ollama
- OpenAI API Compatibility
⚠️ The minimum supported version of Node.js is the v18. Check your Node.js version withnode --version.
- Install aicommit2:
Directly from npm:
npm install -g aicommit2Alternatively, from source:
git clone https://github.com/tak-bro/aicommit2.git
cd aicommit2
npm run build
npm install -g .- Set up API keys (at least ONE key must be set):
aicommit2 config set OPENAI.key=<your key>
aicommit2 config set ANTHROPIC.key=<your key>
# ... (similar commands for other providers)- Run aicommit2 with your staged files in git repository:
git add <files...>
aicommit2👉 Tip: Use the
aic2alias ifaicommit2is too long for you.
You can also use your model for free with Ollama and it is available to use both Ollama and remote providers simultaneously.
-
Install Ollama from https://ollama.com
-
Start it with your model
ollama run llama3.2 # model you want use. ex) codellama, deepseek-coder- Set the host, model and numCtx. (The default numCtx value in Ollama is 2048. It is recommended to set it to
4096or higher.)
aicommit2 config set OLLAMA.host=<your host>
aicommit2 config set OLLAMA.model=<your model>
aicommit2 config set OLLAMA.numCtx=4096If you want to use Ollama, you must set OLLAMA.model.
- Run aicommit2 with your staged in git repository
git add <files...>
aicommit2👉 Tip: Ollama can run LLMs in parallel from v0.1.33. Please see this section.
This CLI tool runs git diff to grab all your latest code changes, sends them to configured AI, then returns the AI generated commit message.
If the diff becomes too large, AI will not function properly. If you encounter an error saying the message is too long or it's not a valid commit message, try reducing the commit unit.
You can call aicommit2 directly to generate a commit message for your staged changes:
git add <files...>
aicommit2aicommit2 passes down unknown flags to git commit, so you can pass in commit flags.
For example, you can stage all changes in tracked files with as you commit:
aicommit2 --all # or -a-
--localeor-l: Locale to use for the generated commit messages (default: en) -
--allor-a: Automatically stage changes in tracked files for the commit (default: false) -
--typeor-t: Git commit message format (default: conventional). It supportsconventionalandgitmoji -
--confirmor-y: Skip confirmation when committing after message generation (default: false) -
--clipboardor-c: Copy the selected message to the clipboard (default: false).- If you give this option, aicommit2 will not commit.
-
--generateor-g: Number of messages to generate (default: 1)- Warning: This uses more tokens, meaning it costs more.
-
--excludeor-x: Files to exclude from AI analysis -
--hook-mode: Run as a Git hook, typically used with prepare-commit-msg hook (default: false)- This mode is automatically enabled when running through the Git hook system
- See Git hook section for more details
-
--pre-commit: Run in pre-commit framework mode (default: false)- This option is specifically for use with the pre-commit framework
- See Integration with pre-commit framework section for setup instructions
Example:
aicommit2 --locale "jp" --all --type "conventional" --generate 3 --clipboard --exclude "*.json" --exclude "*.ts"You can also integrate aicommit2 with Git via the prepare-commit-msg hook. This lets you use Git like you normally would, and edit the commit message before committing.
In the Git repository you want to install the hook in:
aicommit2 hook installif you prefer to set up the hook manually, create or edit the .git/hooks/prepare-commit-msg file:
#!/bin/sh
# your-other-hook "$@"
aicommit2 --hook-mode "$@"Make the hook executable:
chmod +x .git/hooks/prepare-commit-msgIn the Git repository you want to uninstall the hook from:
aicommit2 hook uninstallOr manually delete the .git/hooks/prepare-commit-msg file.
- READ:
aicommit2 config get <key> - SET:
aicommit2 config set <key>=<value>
Example:
aicommit2 config get OPENAI
aicommit2 config get GEMINI.key
aicommit2 config set OPENAI.generate=3 GEMINI.temperature=0.5You can configure API keys using environment variables. This is particularly useful for CI/CD environments or when you don't want to store keys in the configuration file.
# OpenAI
OPENAI_API_KEY="your-openai-key"
# Anthropic
ANTHROPIC_API_KEY="your-anthropic-key"
# Google
GEMINI_API_KEY="your-gemini-key"
# Mistral AI
MISTRAL_API_KEY="your-mistral-key"
CODESTRAL_API_KEY="your-codestral-key"
# Other Providers
COHERE_API_KEY="your-cohere-key"
GROQ_API_KEY="your-groq-key"
PERPLEXITY_API_KEY="your-perplexity-key"
DEEPSEEK_API_KEY="your-deepseek-key"Usage Example:
OPENAI_API_KEY="your-openai-key" ANTHROPIC_API_KEY="your-anthropic-key" aicommit2Note: Environment variables take precedence over configuration file settings.
- Command-line arguments: use the format
--[Model].[Key]=value
aicommit2 --OPENAI.locale="jp" --GEMINI.temperatue="0.5"- Configuration file: use INI format in the
~/.aicommit2file or usesetcommand. Example~/.aicommit2:
# General Settings
logging=true
generate=2
temperature=1.0
# Model-Specific Settings
[OPENAI]
key="<your-api-key>"
temperature=0.8
generate=1
systemPromptPath="<your-prompt-path>"
[GEMINI]
key="<your-api-key>"
generate=5
includeBody=true
[OLLAMA]
temperature=0.7
model[]=llama3.2
model[]=codestralThe priority of settings is: Command-line Arguments > Environment Variables > Model-Specific Settings > General Settings > Default Values.
The following settings can be applied to most models, but support may vary. Please check the documentation for each specific model to confirm which settings are supported.
| Setting | Description | Default |
|---|---|---|
systemPrompt |
System Prompt text | - |
systemPromptPath |
Path to system prompt file | - |
exclude |
Files to exclude from AI analysis | - |
type |
Type of commit message to generate | conventional |
locale |
Locale for the generated commit messages | en |
generate |
Number of commit messages to generate | 1 |
logging |
Enable logging | true |
includeBody |
Whether the commit message includes body | false |
maxLength |
Maximum character length of the Subject of generated commit message | 50 |
timeout |
Request timeout (milliseconds) | 10000 |
temperature |
Model's creativity (0.0 - 2.0) | 0.7 |
maxTokens |
Maximum number of tokens to generate | 1024 |
topP |
Nucleus sampling | 0.9 |
codeReview |
Whether to include an automated code review in the process | false |
codeReviewPromptPath |
Path to code review prompt file | - |
disabled |
Whether a specific model is enabled or disabled | false |
👉 Tip: To set the General Settings for each model, use the following command.
aicommit2 config set OPENAI.locale="jp" aicommit2 config set CODESTRAL.type="gitmoji" aicommit2 config set GEMINI.includeBody=true
- Allow users to specify a custom system prompt
aicommit2 config set systemPrompt="Generate git commit message."
systemPrompttakes precedence oversystemPromptPathand does not apply at the same time.
- Allow users to specify a custom file path for their own system prompt template
- Please see Custom Prompt Template
aicommit2 config set systemPromptPath="/path/to/user/prompt.txt"- Files to exclude from AI analysis
- It is applied with the
--excludeoption of the CLI option. All files excluded through--excludein CLI andexcludegeneral setting.
aicommit2 config set exclude="*.ts"
aicommit2 config set exclude="*.ts,*.json"NOTE:
excludeoption does not support per model. It is only supported by General Settings.
Default: conventional
Supported: conventional, gitmoji
The type of commit message to generate. Set this to "conventional" to generate commit messages that follow the Conventional Commits specification:
aicommit2 config set type="conventional"Default: en
The locale to use for the generated commit messages. Consult the list of codes in: https://wikipedia.org/wiki/List_of_ISO_639_language_codes.
aicommit2 config set locale="jp"Default: 1
The number of commit messages to generate to pick from.
Note, this will use more tokens as it generates more results.
aicommit2 config set generate=2Default: true
Option that allows users to decide whether to generate a log file capturing the responses.
The log files will be stored in the ~/.aicommit2_log directory(user's home).
- You can remove all logs below comamnd.
aicommit2 log removeAllDefault: false
This option determines whether the commit message includes body. If you want to include body in message, you can set it to true.
aicommit2 config set includeBody="true"
aicommit2 config set includeBody="false"
The maximum character length of the Subject of generated commit message
Default: 50
aicommit2 config set maxLength=100The timeout for network requests in milliseconds.
Default: 10_000 (10 seconds)
aicommit2 config set timeout=20000 # 20sThe temperature (0.0-2.0) is used to control the randomness of the output
Default: 0.7
aicommit2 config set temperature=0.3The maximum number of tokens that the AI models can generate.
Default: 1024
aicommit2 config set maxTokens=3000Default: 0.9
Nucleus sampling, where the model considers the results of the tokens with top_p probability mass.
aicommit2 config set topP=0.2Default: false
This option determines whether a specific model is enabled or disabled. If you want to disable a particular model, you can set this option to true.
To disable a model, use the following commands:
aicommit2 config set GEMINI.disabled="true"
aicommit2 config set GROQ.disabled="true"Default: false
The codeReview parameter determines whether to include an automated code review in the process.
aicommit2 config set codeReview=trueNOTE: When enabled, aicommit2 will perform a code review before generating commit messages.

- The
codeReviewfeature is currently experimental. - This feature performs a code review before generating commit messages.
- Using this feature will significantly increase the overall processing time.
- It may significantly impact performance and cost.
- The code review process consumes a large number of tokens.
- Allow users to specify a custom file path for code review
aicommit2 config set codeReviewPromptPath="/path/to/user/prompt.txt"| timeout | temperature | maxTokens | topP | |
|---|---|---|---|---|
| OpenAI | ✓ | ✓ | ✓ | ✓ |
| Anthropic Claude | ✓ | ✓ | ✓ | |
| Gemini | ✓ | ✓ | ✓ | |
| Mistral AI | ✓ | ✓ | ✓ | ✓ |
| Codestral | ✓ | ✓ | ✓ | ✓ |
| Cohere | ✓ | ✓ | ✓ | |
| Groq | ✓ | ✓ | ✓ | ✓ |
| Perplexity | ✓ | ✓ | ✓ | ✓ |
| DeepSeek | ✓ | ✓ | ✓ | ✓ |
| Ollama | ✓ | ✓ | ✓ | |
| OpenAI API-Compatible | ✓ | ✓ | ✓ | ✓ |
All AI support the following options in General Settings.
- systemPrompt, systemPromptPath, codeReview, codeReviewPromptPath, exclude, type, locale, generate, logging, includeBody, maxLength
Some models mentioned below are subject to change.
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | gpt-4o-mini |
url |
API endpoint URL | https://api.openai.com |
path |
API path | /v1/chat/completions |
proxy |
Proxy settings | - |
The OpenAI API key. You can retrieve it from OpenAI API Keys page.
aicommit2 config set OPENAI.key="your api key"Default: gpt-4o-mini
The Chat Completions (/v1/chat/completions) model to use. Consult the list of models available in the OpenAI Documentation.
aicommit2 config set OPENAI.model=gpt-4oDefault: https://api.openai.com
The OpenAI URL. Both https and http protocols supported. It allows to run local OpenAI-compatible server.
aicommit2 config set OPENAI.url="<your-host>"Default: /v1/chat/completions
The OpenAI Path.
Default: 0.9
The top_p parameter selects tokens whose combined probability meets a threshold. Please see detail.
aicommit2 config set OPENAI.topP=0.2NOTE: If
topPis less than 0, it does not deliver thetop_pparameter to the request.
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | claude-3-5-haiku-20241022 |
The Anthropic API key. To get started with Anthropic Claude, request access to their API at anthropic.com/earlyaccess.
Default: claude-3-5-haiku-20241022
Supported:
claude-3-7-sonnet-20250219claude-3-5-sonnet-20241022claude-3-5-haiku-20241022claude-3-opus-20240229claude-3-sonnet-20240229claude-3-haiku-20240307
aicommit2 config set ANTHROPIC.model="claude-3-5-sonnet-20240620"Anthropic does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | gemini-2.0-flash |
The Gemini API key. If you don't have one, create a key in Google AI Studio.
aicommit2 config set GEMINI.key="your api key"Default: gemini-2.0-flash
Supported:
gemini-2.0-flashgemini-2.0-flash-litegemini-2.0-pro-exp-02-05gemini-2.0-flash-thinking-exp-01-21gemini-2.0-flash-expgemini-1.5-flashgemini-1.5-flash-8bgemini-1.5-pro
aicommit2 config set GEMINI.model="gemini-2.0-flash"Gemini does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | pixtral-12b-2409 |
The Mistral API key. If you don't have one, please sign up and subscribe in Mistral Console.
Default: pixtral-12b-2409
Supported:
codestral-latestmistral-large-latestpixtral-large-latestministral-8b-latestmistral-small-latestmistral-embedmistral-moderation-latest
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | codestral-latest |
The Codestral API key. If you don't have one, please sign up and subscribe in Mistral Console.
Default: codestral-latest
Supported:
codestral-latestcodestral-2501
aicommit2 config set CODESTRAL.model="codestral-2501"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | command |
The Cohere API key. If you don't have one, please sign up and get the API key in Cohere Dashboard.
Default: command
Supported models:
command-r7b-12-2024command-r-plus-08-2024command-r-plus-04-2024command-r-pluscommand-r-08-2024command-r-03-2024command-rcommandcommand-nightlycommand-lightcommand-light-nightlyc4ai-aya-expanse-8bc4ai-aya-expanse-32b
aicommit2 config set COHERE.model="command-nightly"Cohere does not support the following options in General Settings.
- timeout
| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | deepseek-r1-distill-llama-70b |
The Groq API key. If you don't have one, please sign up and get the API key in Groq Console.
Default: deepseek-r1-distill-llama-70b
Supported:
qwen-2.5-32bqwen-2.5-coder-32bdeepseek-r1-distill-qwen-32bdeepseek-r1-distill-llama-70bdistil-whisper-large-v3-engemma2-9b-itllama-3.3-70b-versatilellama-3.1-8b-instantllama-guard-3-8bllama3-70b-8192llama3-8b-8192mixtral-8x7b-32768whisper-large-v3whisper-large-v3-turbollama-3.3-70b-specdecllama-3.2-1b-previewllama-3.2-3b-previewllama-3.2-11b-vision-previewllama-3.2-90b-vision-preview
aicommit2 config set GROQ.model="deepseek-r1-distill-llama-70b"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | sonar |
The Perplexity API key. If you don't have one, please sign up and get the API key in Perplexity
Default: sonar
Supported:
sonar-prosonarllama-3.1-sonar-small-128k-onlinellama-3.1-sonar-large-128k-onlinellama-3.1-sonar-huge-128k-online
The models mentioned above are subject to change.
aicommit2 config set PERPLEXITY.model="sonar-pro"| Setting | Description | Default |
|---|---|---|
key |
API key | - |
model |
Model to use | deepseek-chat |
The DeepSeek API key. If you don't have one, please sign up and subscribe in DeepSeek Platform.
Default: deepseek-chat
Supported:
deepseek-chatdeepseek-reasoner
aicommit2 config set DEEPSEEK.model="deepseek-reasoner"| Setting | Description | Default |
|---|---|---|
model |
Model(s) to use (comma-separated list) | - |
host |
Ollama host URL | http://localhost:11434 |
auth |
Authentication type | Bearer |
key |
Authentication key | - |
timeout |
Request timeout (milliseconds) | 100_000 (100sec) |
numCtx |
The maximum number of tokens the model can process at once | 2048 |
The Ollama Model. Please see a list of models available
aicommit2 config set OLLAMA.model="llama3.1"
aicommit2 config set OLLAMA.model="llama3,codellama" # for multiple models
aicommit2 config add OLLAMA.model="gemma2" # Only Ollama.model can be added.OLLAMA.model is string array type to support multiple Ollama. Please see this section.
Default: http://localhost:11434
The Ollama host
aicommit2 config set OLLAMA.host=<host>Not required. Use when your Ollama server requires authentication. Please see this issue.
aicommit2 config set OLLAMA.auth=<auth>Not required. Use when your Ollama server requires authentication. Please see this issue.
aicommit2 config set OLLAMA.key=<key>Few examples of authentication methods:
| Authentication Method | OLLAMA.auth | OLLAMA.key |
|---|---|---|
| Bearer | Bearer |
<API key> |
| Basic | Basic |
<Base64 Encoded username:password> |
| JWT | Bearer |
<JWT Token> |
| OAuth 2.0 | Bearer |
<Access Token> |
| HMAC-SHA256 | HMAC |
<Base64 Encoded clientId:signature> |
Default: 100_000 (100 seconds)
Request timeout for the Ollama.
aicommit2 config set OLLAMA.timeout=<timeout>The maximum number of tokens the model can process at once, determining its context length and memory usage. It is recommended to set it to 4096 or higher.
aicommit2 config set OLLAMA.numCtx=4096Ollama does not support the following options in General Settings.
- maxTokens
You can configure any OpenAI API-compatible service by adding a configuration section with the compatible=true option. This allows you to use services that implement the OpenAI API specification.
# together
aicommit2 config set TOGETHER.compatible=true
aicommit2 config set TOGETHER.url=https://api.together.xyz
aicommit2 config set TOGETHER.path=/v1
aicommit2 config set TOGETHER.model=meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo
aicommit2 config set TOGETHER.key="your-api-key"| Setting | Description | Required | Default |
|---|---|---|---|
compatible |
Enable OpenAI API compatibility mode | ✓ (must be true) | false |
url |
Base URL of the API endpoint | ✓ | - |
path |
API path for chat completions | - | |
key |
API key for authentication | ✓ | - |
model |
Model identifier to use | ✓ | - |
Example configuration:
[TOGETHER]
compatible=true
key=<your-api-key>
url=https://api.together.xyz/v1
model=meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo
[GEMINI_COMPATIBILITY]
compatible=true
key=<your-api-key>
url=https://generativelanguage.googleapis.com
path=/v1beta/openai/
model=gemini-1.5-flash
[OLLAMA_COMPATIBILITY]
compatible=true
key=ollama
url=http://localhost:11434/v1
model=llama3.2
Watch Commit mode allows you to monitor Git commits in real-time and automatically perform AI code reviews using the --watch-commit flag.
aicommit2 --watch-commitThis feature only works within Git repository directories and automatically triggers whenever a commit event occurs. When a new commit is detected, it automatically:
- Analyzes commit changes
- Performs AI code review
- Displays results in real-time
For detailed configuration of the code review feature, please refer to the codeReview section. The settings in that section are shared with this feature.
- The Watch Commit feature is currently experimental
- This feature performs AI analysis for each commit, which consumes a significant number of API tokens
- API costs can increase substantially if there are many commits
- It is recommended to carefully monitor your token usage when using this feature
- To use this feature, you must enable watch mode for at least one AI model:
aicommit2 config set [MODEL].watchMode="true"
Check the installed version with:
aicommit2 --version
If it's not the latest version, run:
npm update -g aicommit2aicommit2 supports custom prompt templates through the systemPromptPath option. This feature allows you to define your own prompt structure, giving you more control over the commit message generation process.
To use a custom prompt template, specify the path to your template file when running the tool:
aicommit2 config set systemPromptPath="/path/to/user/prompt.txt"
aicommit2 config set OPENAI.systemPromptPath="/path/to/another-prompt.txt"
For the above command, OpenAI uses the prompt in the another-prompt.txt file, and the rest of the model uses prompt.txt.
NOTE: For the
systemPromptPathoption, set the template path, not the template content
Your custom template can include placeholders for various commit options.
Use curly braces {} to denote these placeholders for options. The following placeholders are supported:
- {locale}: The language for the commit message (string)
- {maxLength}: The maximum length for the commit message (number)
- {type}: The type of the commit message (conventional or gitmoji)
- {generate}: The number of commit messages to generate (number)
Here's an example of how your custom template might look:
Generate a {type} commit message in {locale}.
The message should not exceed {maxLength} characters.
Please provide {generate} messages.
Remember to follow these guidelines:
1. Use the imperative mood
2. Be concise and clear
3. Explain the 'why' behind the change
Please note that the following text will ALWAYS be appended to the end of your custom prompt:
Lastly, Provide your response as a JSON array containing exactly {generate} object, each with the following keys:
- "subject": The main commit message using the {type} style. It should be a concise summary of the changes.
- "body": An optional detailed explanation of the changes. If not needed, use an empty string.
- "footer": An optional footer for metadata like BREAKING CHANGES. If not needed, use an empty string.
The array must always contain {generate} element, no more and no less.
Example response format:
[
{
"subject": "fix: fix bug in user authentication process",
"body": "- Update login function to handle edge cases\n- Add additional error logging for debugging",
"footer": ""
}
]
Ensure you generate exactly {generate} commit message, even if it requires creating slightly varied versions for similar changes.
The response should be valid JSON that can be parsed without errors.
This ensures that the output is consistently formatted as a JSON array, regardless of the custom template used.
If you're using the pre-commit framework, you can add aicommit2 to your .pre-commit-config.yaml:
repos:
- repo: local
hooks:
- id: aicommit2
name: AI Commit Message Generator
entry: aicommit2 --pre-commit
language: node
stages: [prepare-commit-msg]
always_run: trueMake sure you have:
- Installed pre-commit:
brew install pre-commit - Installed aicommit2 globally:
npm install -g aicommit2 - Run
pre-commit install --hook-type prepare-commit-msgto set up the hook
Note : The
--pre-commitflag is specifically designed for use with the pre-commit framework and ensures proper integration with other pre-commit hooks.

You can load and make simultaneous requests to multiple models using Ollama's experimental feature, the OLLAMA_MAX_LOADED_MODELS option.
-
OLLAMA_MAX_LOADED_MODELS: Load multiple models simultaneously
Follow these steps to set up and utilize multiple models simultaneously:
First, launch the Ollama server with the OLLAMA_MAX_LOADED_MODELS environment variable set. This variable specifies the maximum number of models to be loaded simultaneously.
For example, to load up to 3 models, use the following command:
OLLAMA_MAX_LOADED_MODELS=3 ollama serveRefer to configuration for detailed instructions.
Next, set up aicommit2 to specify multiple models. You can assign a list of models, separated by commas(,), to the OLLAMA.model environment variable. Here's how you do it:
aicommit2 config set OLLAMA.model="mistral,dolphin-llama3"With this command, aicommit2 is instructed to utilize both the "mistral" and "dolphin-llama3" models when making requests to the Ollama server.
aicommit2Note that this feature is available starting from Ollama version 0.1.33 and aicommit2 version 1.9.5.
This project uses functionalities from external APIs but is not officially affiliated with or endorsed by their providers. Users are responsible for complying with API terms, rate limits, and policies.
For bug fixes or feature implementations, please check the Contribution Guide.
Thanks goes to these wonderful people (emoji key):
 @eltociear 📖 |
 @ubranch 💻 |
 @bhodrolok 💻 |
 @ryicoh 💻 |
 @noamsto 💻 |
 @tdabasinskas 💻 |
 @gnpaone 💻 |
 @devxpain 💻 |
If this project has been helpful, please consider giving it a Star ⭐️!
Maintainer: @tak-bro
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aicommit2
Similar Open Source Tools
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.
ruler
Ruler is a tool designed to centralize AI coding assistant instructions, providing a single source of truth for managing instructions across multiple AI coding tools. It helps in avoiding inconsistent guidance, duplicated effort, context drift, onboarding friction, and complex project structures by automatically distributing instructions to the right configuration files. With support for nested rule loading, Ruler can handle complex project structures with context-specific instructions for different components. It offers features like centralised rule management, nested rule loading, automatic distribution, targeted agent configuration, MCP server propagation, .gitignore automation, and a simple CLI for easy configuration management.
VimLM
VimLM is an AI-powered coding assistant for Vim that integrates AI for code generation, refactoring, and documentation directly into your Vim workflow. It offers native Vim integration with split-window responses and intuitive keybindings, offline first execution with MLX-compatible models, contextual awareness with seamless integration with codebase and external resources, conversational workflow for iterating on responses, project scaffolding for generating and deploying code blocks, and extensibility for creating custom LLM workflows with command chains.
cortex.cpp
Cortex.cpp is an open-source platform designed as the brain for robots, offering functionalities such as vision, speech, language, tabular data processing, and action. It provides an AI platform for running AI models with multi-engine support, hardware optimization with automatic GPU detection, and an OpenAI-compatible API. Users can download models from the Hugging Face model hub, run models, manage resources, and access advanced features like multiple quantizations and engine management. The tool is under active development, promising rapid improvements for users.
foul-play
Foul Play is a Pokémon battle-bot that can play single battles in all generations on Pokemon Showdown. It requires Python 3.10+. The bot uses environment variables for configuration and supports different game modes and battle strategies. Users can specify teams and choose between algorithms like Monte-Carlo Tree Search and Expectiminimax. Foul Play can be run locally or with Docker, and the engine used for battles must be built from source. The tool provides flexibility in gameplay and strategy for Pokémon battles.

wa_llm
WhatsApp Group Summary Bot is an AI-powered tool that joins WhatsApp groups, tracks conversations, and generates intelligent summaries. It features automated group chat responses, LLM-based conversation summaries, knowledge base integration, persistent message history with PostgreSQL, support for multiple message types, group management, and a REST API with Swagger docs. Prerequisites include Docker, Python 3.12+, PostgreSQL with pgvector extension, Voyage AI API key, and a WhatsApp account for the bot. The tool can be quickly set up by cloning the repository, configuring environment variables, starting services, and connecting devices. It offers API usage for loading new knowledge base topics and generating & dispatching summaries to managed groups. The project architecture includes FastAPI backend, WhatsApp Web API client, PostgreSQL database with vector storage, and AI-powered message processing.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
VASA-1-hack
VASA-1-hack is a repository containing the VASA implementation separated from EMOPortraits, with all components properly configured for standalone training. It provides detailed setup instructions, prerequisites, project structure, configuration details, running training modes, troubleshooting tips, monitoring training progress, development information, and acknowledgments. The repository aims to facilitate training volumetric avatar models with configurable parameters and logging levels for efficient debugging and testing.
scrape-it-now
Scrape It Now is a versatile tool for scraping websites with features like decoupled architecture, CLI functionality, idempotent operations, and content storage options. The tool includes a scraper component for efficient scraping, ad blocking, link detection, markdown extraction, dynamic content loading, and anonymity features. It also offers an indexer component for creating AI search indexes, chunking content, embedding chunks, and enabling semantic search. The tool supports various configurations for Azure services and local storage, providing flexibility and scalability for web scraping and indexing tasks.
code-graph-rag
Graph-Code is an accurate Retrieval-Augmented Generation (RAG) system that analyzes multi-language codebases using Tree-sitter. It builds comprehensive knowledge graphs, enabling natural language querying of codebase structure and relationships, along with editing capabilities. The system supports various languages, uses Tree-sitter for parsing, Memgraph for storage, and AI models for natural language to Cypher translation. It offers features like code snippet retrieval, advanced file editing, shell command execution, interactive code optimization, reference-guided optimization, dependency analysis, and more. The architecture consists of a multi-language parser and an interactive CLI for querying the knowledge graph.
SwiftAI
SwiftAI is a modern, type-safe Swift library for building AI-powered apps. It provides a unified API that works seamlessly across different AI models, including Apple's on-device models and cloud-based services like OpenAI. With features like model agnosticism, structured output, agent tool loop, conversations, extensibility, and Swift-native design, SwiftAI offers a powerful toolset for developers to integrate AI capabilities into their applications. The library supports easy installation via Swift Package Manager and offers detailed guidance on getting started, structured responses, tool use, model switching, conversations, and advanced constraints. SwiftAI aims to simplify AI integration by providing a type-safe and versatile solution for various AI tasks.

comp
Comp AI is an open-source compliance automation platform designed to assist companies in achieving compliance with standards like SOC 2, ISO 27001, and GDPR. It transforms compliance into an engineering problem solved through code, automating evidence collection, policy management, and control implementation while maintaining data and infrastructure control.
paperless-gpt
paperless-gpt is a tool designed to generate accurate and meaningful document titles and tags for paperless-ngx using Large Language Models (LLMs). It supports multiple LLM providers, including OpenAI and Ollama. With paperless-gpt, you can streamline your document management by automatically suggesting appropriate titles and tags based on the content of your scanned documents. The tool offers features like multiple LLM support, customizable prompts, easy integration with paperless-ngx, user-friendly interface for reviewing and applying suggestions, dockerized deployment, automatic document processing, and an experimental OCR feature.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students
aiosmb
aiosmb is a fully asynchronous SMB library written in pure Python, supporting Python 3.7 and above. It offers various authentication methods such as Kerberos, NTLM, SSPI, and NEGOEX. The library supports connections over TCP and QUIC protocols, with proxy support for SOCKS4 and SOCKS5. Users can specify an SMB connection using a URL format, making it easier to authenticate and connect to SMB hosts. The project aims to implement DCERPC features, VSS mountpoint operations, and other enhancements in the future. It is inspired by Impacket and AzureADJoinedMachinePTC projects.
For similar tasks
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
prompt-optimizer
Prompt Optimizer is a powerful AI prompt optimization tool that helps you write better AI prompts, improving AI output quality. It supports both web application and Chrome extension usage. The tool features intelligent optimization for prompt words, real-time testing to compare before and after optimization, integration with multiple mainstream AI models, client-side processing for security, encrypted local storage for data privacy, responsive design for user experience, and more.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
OpenClawChineseTranslation
OpenClaw Chinese Translation is a localization project that provides a fully Chinese interface for the OpenClaw open-source personal AI assistant platform. It allows users to interact with their AI assistant through chat applications like WhatsApp, Telegram, and Discord to manage daily tasks such as emails, calendars, and files. The project includes both CLI command-line and dashboard web interface fully translated into Chinese.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.