
svelte-bench
An LLM benchmark for Svelte 5 based on the OpenAI methodology from OpenAIs paper "Evaluating Large Language Models Trained on Code".
Stars: 70
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
README:
An LLM benchmark for Svelte 5 based on the OpenAI methodology from OpenAIs paper "Evaluating Large Language Models Trained on Code", using a similar structure to the HumanEval dataset.
Work in progress
SvelteBench evaluates LLM-generated Svelte components by testing them against predefined test suites. It works by sending prompts to LLMs, generating Svelte components, and verifying their functionality through automated tests.
SvelteBench supports multiple LLM providers:
- OpenAI - GPT-4, GPT-4o, o1, o3, o4 models
- Anthropic - Claude 3.5, Claude 4 models
- Google - Gemini 2.5 models
- OpenRouter - Access to multiple providers through a single API
nvm use
npm install
# Create .env file from example
cp .env.example .envThen edit the .env file and add your API keys:
# OpenAI (optional)
OPENAI_API_KEY=your_openai_api_key_here
# Anthropic (optional)
ANTHROPIC_API_KEY=your_anthropic_api_key_here
# Google Gemini (optional)
GEMINI_API_KEY=your_gemini_api_key_here
# OpenRouter (optional)
OPENROUTER_API_KEY=your_openrouter_api_key_here
OPENROUTER_SITE_URL=https://github.com/khromov/svelte-bench # Optional
OPENROUTER_SITE_NAME=SvelteBench # OptionalYou only need to configure the providers you want to test with.
# Run the benchmark with settings from .env file
npm startNOTE: This will run all providers and models that are available!
For faster development, or to run just one provider/model, you can enable debug mode in your .env file:
DEBUG_MODE=true
DEBUG_PROVIDER=anthropic
DEBUG_MODEL=claude-3-7-sonnet-20250219
DEBUG_TEST=counter
Debug mode runs only one provider/model combination, making it much faster for testing during development.
You can now specify multiple models to test in debug mode by providing a comma-separated list:
DEBUG_MODE=true
DEBUG_PROVIDER=anthropic
DEBUG_MODEL=claude-3-7-sonnet-20250219,claude-opus-4-20250514,claude-sonnet-4-20250514
This will run tests with all three models sequentially while still staying within the same provider.
You can provide a context file (like Svelte documentation) to help the LLM generate better components:
# Run with a context file
npm run run-tests -- --context ./context/svelte.dev/llms-small.txt && npm run buildThe context file will be included in the prompt to the LLM, providing additional information for generating components.
After running the benchmark, you can visualize the results using the built-in visualization tool:
npm run buildYou can now find the visualization in the dist directory.
To add a new test:
- Create a new directory in
src/tests/with the name of your test - Add a
prompt.mdfile with instructions for the LLM - Add a
test.tsfile with Vitest tests for the generated component
Example structure:
src/tests/your-test/
├── prompt.md # Instructions for the LLM
└── test.ts # Tests for the generated component
After running the benchmark, results are saved to a JSON file in the benchmarks directory. The file is named benchmark-results-{timestamp}.json.
When running with a context file, the results filename will include "with-context" in the name: benchmark-results-with-context-{timestamp}.json.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for svelte-bench
Similar Open Source Tools
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.

honcho
Honcho is a platform for creating personalized AI agents and LLM powered applications for end users. The repository is a monorepo containing the server/API for managing database interactions and storing application state, along with a Python SDK. It utilizes FastAPI for user context management and Poetry for dependency management. The API can be run using Docker or manually by setting environment variables. The client SDK can be installed using pip or Poetry. The project is open source and welcomes contributions, following a fork and PR workflow. Honcho is licensed under the AGPL-3.0 License.
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.

log10
Log10 is a one-line Python integration to manage your LLM data. It helps you log both closed and open-source LLM calls, compare and identify the best models and prompts, store feedback for fine-tuning, collect performance metrics such as latency and usage, and perform analytics and monitor compliance for LLM powered applications. Log10 offers various integration methods, including a python LLM library wrapper, the Log10 LLM abstraction, and callbacks, to facilitate its use in both existing production environments and new projects. Pick the one that works best for you. Log10 also provides a copilot that can help you with suggestions on how to optimize your prompt, and a feedback feature that allows you to add feedback to your completions. Additionally, Log10 provides prompt provenance, session tracking and call stack functionality to help debug prompt chains. With Log10, you can use your data and feedback from users to fine-tune custom models with RLHF, and build and deploy more reliable, accurate and efficient self-hosted models. Log10 also supports collaboration, allowing you to create flexible groups to share and collaborate over all of the above features.
cover-agent
CodiumAI Cover Agent is a tool designed to help increase code coverage by automatically generating qualified tests to enhance existing test suites. It utilizes Generative AI to streamline development workflows and is part of a suite of utilities aimed at automating the creation of unit tests for software projects. The system includes components like Test Runner, Coverage Parser, Prompt Builder, and AI Caller to simplify and expedite the testing process, ensuring high-quality software development. Cover Agent can be run via a terminal and is planned to be integrated into popular CI platforms. The tool outputs debug files locally, such as generated_prompt.md, run.log, and test_results.html, providing detailed information on generated tests and their status. It supports multiple LLMs and allows users to specify the model to use for test generation.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.
web-codegen-scorer
Web Codegen Scorer is a tool designed to evaluate the quality of web code generated by Large Language Models (LLMs). It allows users to make evidence-based decisions related to AI-generated code by iterating on system prompts, comparing code quality from different models, and monitoring code quality over time. The tool focuses specifically on web code and offers various features such as configuring evaluations, specifying system instructions, using built-in checks for code quality, automatically repairing issues, and viewing results with an intuitive report viewer UI.

safety-tooling
This repository, safety-tooling, is designed to be shared across various AI Safety projects. It provides an LLM API with a common interface for OpenAI, Anthropic, and Google models. The aim is to facilitate collaboration among AI Safety researchers, especially those with limited software engineering backgrounds, by offering a platform for contributing to a larger codebase. The repo can be used as a git submodule for easy collaboration and updates. It also supports pip installation for convenience. The repository includes features for installation, secrets management, linting, formatting, Redis configuration, testing, dependency management, inference, finetuning, API usage tracking, and various utilities for data processing and experimentation.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.

SWELancer-Benchmark
SWE-Lancer is a benchmark repository containing datasets and code for the paper 'SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering?'. It provides instructions for package management, building Docker images, configuring environment variables, and running evaluations. Users can use this tool to assess the performance of language models in real-world freelance software engineering tasks.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
GraphRAG-Local-UI
GraphRAG Local with Interactive UI is an adaptation of Microsoft's GraphRAG, tailored to support local models and featuring a comprehensive interactive user interface. It allows users to leverage local models for LLM and embeddings, visualize knowledge graphs in 2D or 3D, manage files, settings, and queries, and explore indexing outputs. The tool aims to be cost-effective by eliminating dependency on costly cloud-based models and offers flexible querying options for global, local, and direct chat queries.

ai-starter-kit
SambaNova AI Starter Kits is a collection of open-source examples and guides designed to facilitate the deployment of AI-driven use cases for developers and enterprises. The kits cover various categories such as Data Ingestion & Preparation, Model Development & Optimization, Intelligent Information Retrieval, and Advanced AI Capabilities. Users can obtain a free API key using SambaNova Cloud or deploy models using SambaStudio. Most examples are written in Python but can be applied to any programming language. The kits provide resources for tasks like text extraction, fine-tuning embeddings, prompt engineering, question-answering, image search, post-call analysis, and more.
For similar tasks
svelte-bench
SvelteBench is an LLM benchmark tool for evaluating Svelte components generated by large language models. It supports multiple LLM providers such as OpenAI, Anthropic, Google, and OpenRouter. Users can run predefined test suites to verify the functionality of the generated components. The tool allows configuration of API keys for different providers and offers debug mode for faster development. Users can provide a context file to improve component generation. Benchmark results are saved in JSON format for analysis and visualization.
ai-cli-lib
The ai-cli-lib is a library designed to enhance interactive command-line editing programs by integrating with GPT large language model servers. It allows users to obtain AI help from servers like Anthropic's or OpenAI's, or a llama.cpp server. The library acts as a command line copilot, providing natural language prompts and responses to enhance user experience and productivity. It supports various platforms such as Debian GNU/Linux, macOS, and Cygwin, and requires specific packages for installation and operation. Users can configure the library to activate during shell startup and interact with command-line programs like bash, mysql, psql, gdb, sqlite3, and bc. Additionally, the library provides options for configuring API keys, setting up llama.cpp servers, and ensuring data privacy by managing context settings.
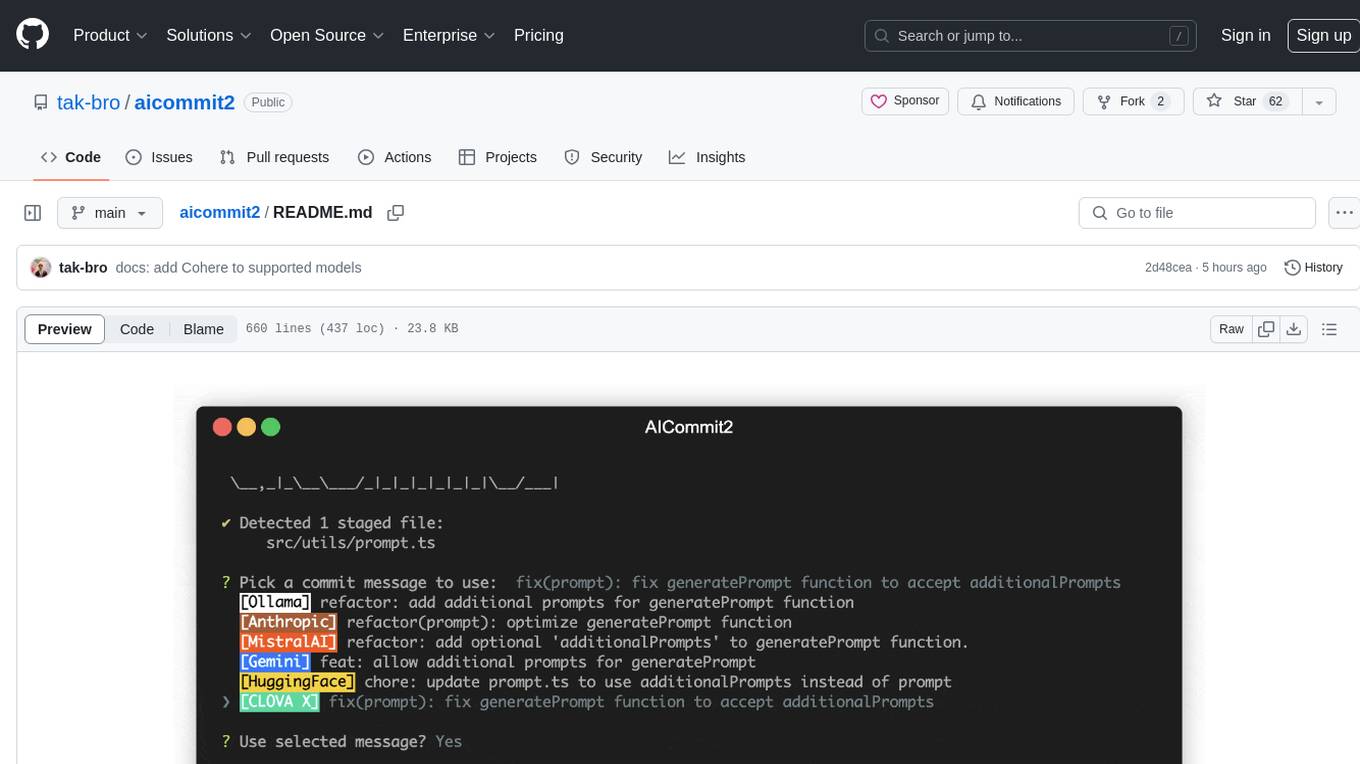
aicommit2
AICommit2 is a Reactive CLI tool that streamlines interactions with various AI providers such as OpenAI, Anthropic Claude, Gemini, Mistral AI, Cohere, and unofficial providers like Huggingface and Clova X. Users can request multiple AI simultaneously to generate git commit messages without waiting for all AI responses. The tool runs 'git diff' to grab code changes, sends them to configured AI, and returns the AI-generated commit message. Users can set API keys or Cookies for different providers and configure options like locale, generate number of messages, commit type, proxy, timeout, max-length, and more. AICommit2 can be used both locally with Ollama and remotely with supported providers, offering flexibility and efficiency in generating commit messages.

TrustEval-toolkit
TrustEval-toolkit is a dynamic and comprehensive framework for evaluating the trustworthiness of Generative Foundation Models (GenFMs) across dimensions such as safety, fairness, robustness, privacy, and more. It offers features like dynamic dataset generation, multi-model compatibility, customizable metrics, metadata-driven pipelines, comprehensive evaluation dimensions, optimized inference, and detailed reports.
prompt-optimizer
Prompt Optimizer is a powerful AI prompt optimization tool that helps you write better AI prompts, improving AI output quality. It supports both web application and Chrome extension usage. The tool features intelligent optimization for prompt words, real-time testing to compare before and after optimization, integration with multiple mainstream AI models, client-side processing for security, encrypted local storage for data privacy, responsive design for user experience, and more.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
OpenClawChineseTranslation
OpenClaw Chinese Translation is a localization project that provides a fully Chinese interface for the OpenClaw open-source personal AI assistant platform. It allows users to interact with their AI assistant through chat applications like WhatsApp, Telegram, and Discord to manage daily tasks such as emails, calendars, and files. The project includes both CLI command-line and dashboard web interface fully translated into Chinese.
openwhispr
OpenWhispr is an open source desktop dictation application that converts speech to text using OpenAI Whisper. It features both local and cloud processing options for maximum flexibility and privacy. The application supports multiple AI providers, customizable hotkeys, agent naming, and various AI processing models. It offers a modern UI built with React 19, TypeScript, and Tailwind CSS v4, and is optimized for speed using Vite and modern tooling. Users can manage settings, view history, configure API keys, and download/manage local Whisper models. The application is cross-platform, supporting macOS, Windows, and Linux, and offers features like automatic pasting, draggable interface, global hotkeys, and compound hotkeys.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.