
company-research-agent
An agentic company research tool powered by LangGraph and Tavily that conducts deep diligence on companies using a multi-agent framework. It leverages Google's Gemini 2.5 Flash and OpenAI's GPT-4.1 on the backend for inference.
Stars: 1442

Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
README:

A multi-agent tool that generates comprehensive company research reports. The platform uses a pipeline of AI agents to gather, curate, and synthesize information about any company.
✨Check it out online! https://companyresearcher.tavily.com ✨
https://github.com/user-attachments/assets/0e373146-26a7-4391-b973-224ded3182a9
- Multi-Source Research: Gathers data from various sources including company websites, news articles, financial reports, and industry analyses
- AI-Powered Content Filtering: Uses Tavily's relevance scoring for content curation
- Real-Time Progress Streaming: Uses WebSocket connections to stream research progress and results
-
Dual Model Architecture:
- Gemini 2.0 Flash for high-context research synthesis
- GPT-4.1 for precise report formatting and editing
- Modern React Frontend: Responsive UI with real-time updates, progress tracking, and download options
- Modular Architecture: Built using a pipeline of specialized research and processing nodes
The platform follows an agentic framework with specialized nodes that process data sequentially:
-
Research Nodes:
-
CompanyAnalyzer: Researches core business information -
IndustryAnalyzer: Analyzes market position and trends -
FinancialAnalyst: Gathers financial metrics and performance data -
NewsScanner: Collects recent news and developments
-
-
Processing Nodes:
-
Collector: Aggregates research data from all analyzers -
Curator: Implements content filtering and relevance scoring -
Briefing: Generates category-specific summaries using Gemini 2.0 Flash -
Editor: Compiles and formats the briefings into a final report using GPT-4.1-mini

-
The platform leverages separate models for optimal performance:
-
Gemini 2.0 Flash (
briefing.py):- Handles high-context research synthesis tasks
- Excels at processing and summarizing large volumes of data
- Used for generating initial category briefings
- Efficient at maintaining context across multiple documents
-
GPT-4.1 mini (
editor.py):- Specializes in precise formatting and editing tasks
- Handles markdown structure and consistency
- Superior at following exact formatting instructions
- Used for:
- Final report compilation
- Content deduplication
- Markdown formatting
- Real-time report streaming
This approach combines Gemini's strength in handling large context windows with GPT-4.1-mini's precision in following specific formatting instructions.
The platform uses a content filtering system in curator.py:
-
Relevance Scoring:
- Documents are scored by Tavily's AI-powered search
- A minimum threshold (default 0.4) is required to proceed
- Scores reflect relevance to the specific research query
- Higher scores indicate better matches to the research intent
-
Document Processing:
- Content is normalized and cleaned
- URLs are deduplicated and standardized
- Documents are sorted by relevance scores
- Real-time progress updates are sent via WebSocket
The platform implements a WebSocket-based real-time communication system:

-
Backend Implementation:
- Uses FastAPI's WebSocket support
- Maintains persistent connections per research job
- Sends structured status updates for various events:
await websocket_manager.send_status_update( job_id=job_id, status="processing", message=f"Generating {category} briefing", result={ "step": "Briefing", "category": category, "total_docs": len(docs) } )
-
Frontend Integration:
- React components subscribe to WebSocket updates
- Updates are processed and displayed in real-time
- Different UI components handle specific update types:
- Query generation progress
- Document curation statistics
- Briefing completion status
- Report generation progress
-
Status Types:
-
query_generating: Real-time query creation updates -
document_kept: Document curation progress -
briefing_start/complete: Briefing generation status -
report_chunk: Streaming report generation -
curation_complete: Final document statistics
-
The easiest way to get started is using the setup script, which automatically detects and uses uv for faster Python package installation when available:
- Clone the repository:
git clone https://github.com/pogjester/tavily-company-research.git
cd tavily-company-research- Make the setup script executable and run it:
chmod +x setup.sh
./setup.shThe setup script will:
- Detect and use
uvfor faster Python package installation (if available) - Check for required Python and Node.js versions
- Optionally create a Python virtual environment (recommended)
- Install all dependencies (Python and Node.js)
- Guide you through setting up your environment variables
- Optionally start both backend and frontend servers
💡 Pro Tip: Install uv for significantly faster Python package installation:
curl -LsSf https://astral.sh/uv/install.sh | sh
You'll need the following API keys ready:
- Tavily API Key
- Google Gemini API Key
- OpenAI API Key
- Google Maps API Key
- MongoDB URI (optional)
If you prefer to set up manually, follow these steps:
- Clone the repository:
git clone https://github.com/pogjester/tavily-company-research.git
cd tavily-company-research- Install backend dependencies:
# Optional: Create and activate virtual environment
# With uv (faster - recommended if available):
uv venv .venv
source .venv/bin/activate
# Or with standard Python:
# python -m venv .venv
# source .venv/bin/activate
# Install Python dependencies
# With uv (faster):
uv pip install -r requirements.txt
# Or with pip:
# pip install -r requirements.txt- Install frontend dependencies:
cd ui
npm install- Set up Environment Variables:
This project requires two separate .env files for the backend and frontend.
For the Backend:
Create a .env file in the project's root directory and add your backend API keys:
TAVILY_API_KEY=your_tavily_key
GEMINI_API_KEY=your_gemini_key
OPENAI_API_KEY=your_openai_key
# Optional: Enable MongoDB persistence
# MONGODB_URI=your_mongodb_connection_stringFor the Frontend:
Create a .env file inside the ui directory. You can copy the example file first:
cp ui/.env.development.example ui/.envThen, open ui/.env and add your frontend environment variables:
VITE_API_URL=http://localhost:8000
VITE_WS_URL=ws://localhost:8000
VITE_GOOGLE_MAPS_API_KEY=your_google_maps_api_key_hereThe application can be run using Docker and Docker Compose:
- Clone the repository:
git clone https://github.com/pogjester/tavily-company-research.git
cd tavily-company-research- Set up Environment Variables:
The Docker setup uses two separate .env files.
For the Backend:
Create a .env file in the project's root directory with your backend API keys:
TAVILY_API_KEY=your_tavily_key
GEMINI_API_KEY=your_gemini_key
OPENAI_API_KEY=your_openai_key
# Optional: Enable MongoDB persistence
# MONGODB_URI=your_mongodb_connection_stringFor the Frontend:
Create a .env file inside the ui directory. You can copy the example file first:
cp ui/.env.development.example ui/.envThen, open ui/.env and add your frontend environment variables:
VITE_API_URL=http://localhost:8000
VITE_WS_URL=ws://localhost:8000
VITE_GOOGLE_MAPS_API_KEY=your_google_maps_api_key_here- Build and start the containers:
docker compose up --buildThis will start both the backend and frontend services:
- Backend API will be available at
http://localhost:8000 - Frontend will be available at
http://localhost:5174
To stop the services:
docker compose downNote: When updating environment variables in .env, you'll need to restart the containers:
docker compose down && docker compose up- Start the backend server (choose one):
# Option 1: Direct Python Module
python -m application.py
# Option 2: FastAPI with Uvicorn
uvicorn application:app --reload --port 8000- In a new terminal, start the frontend:
cd ui
npm run dev- Access the application at
http://localhost:5173
-
Start the backend server (choose one option):
Option 1: Direct Python Module
python -m application.py
Option 2: FastAPI with Uvicorn
# Install uvicorn if not already installed # With uv (faster): uv pip install uvicorn # Or with pip: # pip install uvicorn # Run the FastAPI application with hot reload uvicorn application:app --reload --port 8000
The backend will be available at:
- API Endpoint:
http://localhost:8000 - WebSocket Endpoint:
ws://localhost:8000/research/ws/{job_id}
- API Endpoint:
-
Start the frontend development server:
cd ui npm run dev -
Access the application at
http://localhost:5173
⚡ Performance Note: If you used
uvduring setup, you'll benefit from significantly faster package installation and dependency resolution.uvis a modern Python package manager written in Rust that can be 10-100x faster than pip.
The application can be deployed to various cloud platforms. Here are some common options:
-
Install the EB CLI:
pip install awsebcli
-
Initialize EB application:
eb init -p python-3.11 tavily-research
-
Create and deploy:
eb create tavily-research-prod
- Docker: The application includes a Dockerfile for containerized deployment
- Heroku: Deploy directly from GitHub with the Python buildpack
- Google Cloud Run: Suitable for containerized deployment with automatic scaling
Choose the platform that best suits your needs. The application is platform-agnostic and can be hosted anywhere that supports Python web applications.
- Fork the repository
- Create a feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
- Tavily for the research API
- All other open-source libraries and their contributors
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for company-research-agent
Similar Open Source Tools
company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.
RA.Aid
RA.Aid is an AI software development agent powered by `aider` and advanced reasoning models like `o1`. It combines `aider`'s code editing capabilities with LangChain's agent-based task execution framework to provide an intelligent assistant for research, planning, and implementation of multi-step development tasks. It handles complex programming tasks by breaking them down into manageable steps, running shell commands automatically, and leveraging expert reasoning models like OpenAI's o1. RA.Aid is designed for everyday software development, offering features such as multi-step task planning, automated command execution, and the ability to handle complex programming tasks beyond single-shot code edits.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.
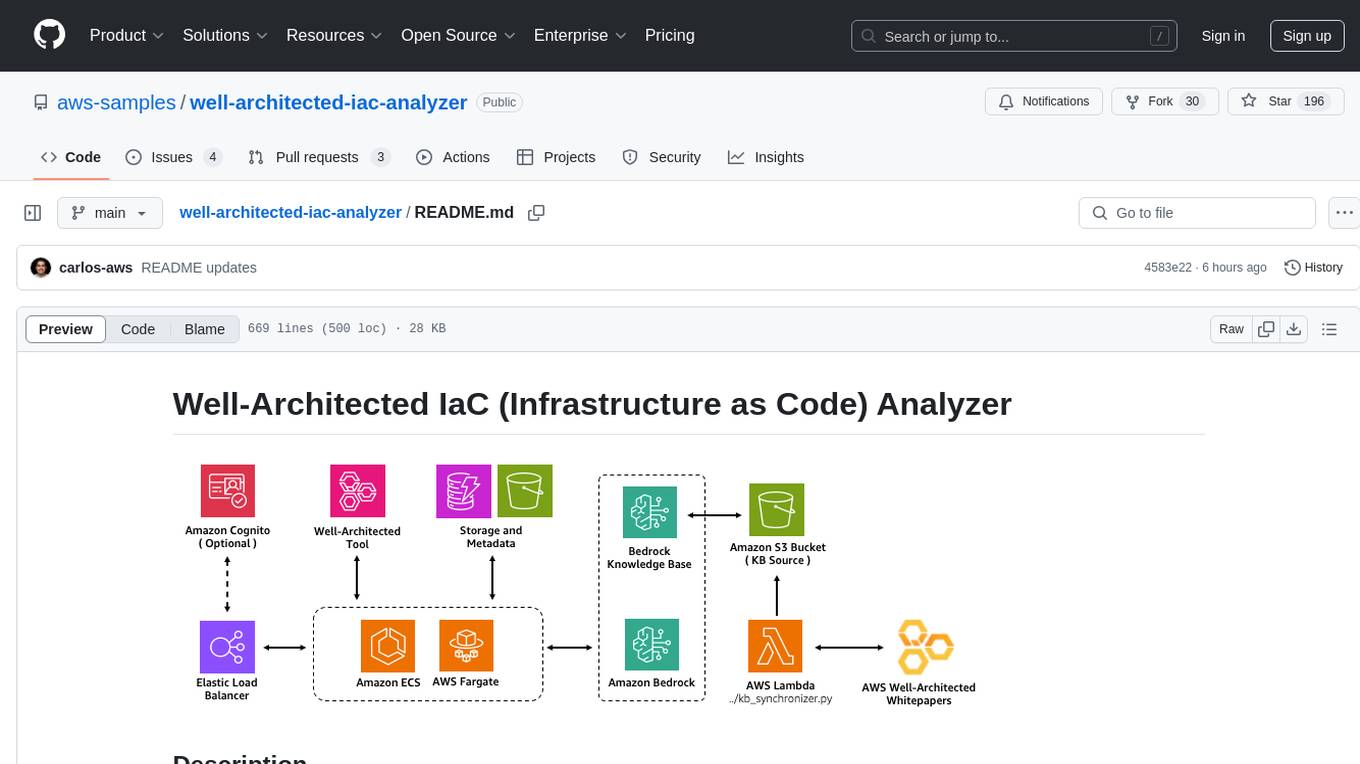
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
pipecat-flows
Pipecat Flows is a framework designed for building structured conversations in AI applications. It allows users to create both predefined conversation paths and dynamically generated flows, handling state management and LLM interactions. The framework includes a Python module for building conversation flows and a visual editor for designing and exporting flow configurations. Pipecat Flows is suitable for scenarios such as customer service scripts, intake forms, personalized experiences, and complex decision trees.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
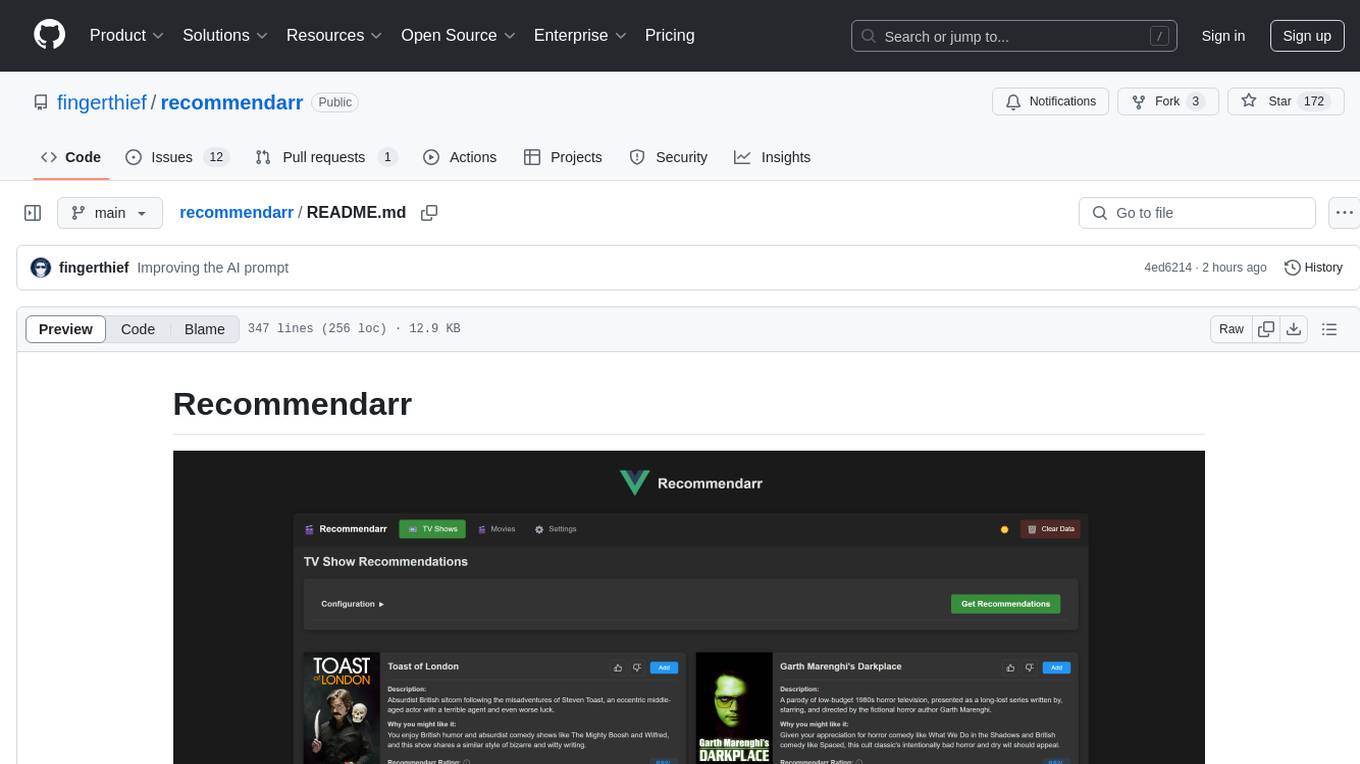
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
cursor-tools
cursor-tools is a CLI tool designed to enhance AI agents with advanced skills, such as web search, repository context, documentation generation, GitHub integration, Xcode tools, and browser automation. It provides features like Perplexity for web search, Gemini 2.0 for codebase context, and Stagehand for browser operations. The tool requires API keys for Perplexity AI and Google Gemini, and supports global installation for system-wide access. It offers various commands for different tasks and integrates with Cursor Composer for AI agent usage.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.
For similar tasks
company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
ollama-ebook-summary
The 'ollama-ebook-summary' repository is a Python project that creates bulleted notes summaries of books and long texts, particularly in epub and pdf formats with ToC metadata. It automates the extraction of chapters, splits them into ~2000 token chunks, and allows for asking arbitrary questions to parts of the text for improved granularity of response. The tool aims to provide summaries for each page of a book rather than a one-page summary of the entire document, enhancing content curation and knowledge sharing capabilities.

gpt-researcher
GPT Researcher is an autonomous agent designed for comprehensive online research on a variety of tasks. It can produce detailed, factual, and unbiased research reports with customization options. The tool addresses issues of speed, determinism, and reliability by leveraging parallelized agent work. The main idea involves running 'planner' and 'execution' agents to generate research questions, seek related information, and create research reports. GPT Researcher optimizes costs and completes tasks in around 3 minutes. Features include generating long research reports, aggregating web sources, an easy-to-use web interface, scraping web sources, and exporting reports to various formats.
awesome-ai-web-search
The 'awesome-ai-web-search' repository is a curated list of AI-powered web search software that focuses on the intersection of Large Language Models (LLMs) and web search capabilities. It contains a timeline of various software supporting web search with LLM summarization, chat capabilities, and agent-driven research. The repository showcases both open-source and closed-source tools, providing a comprehensive overview of AI web search solutions available in the market.
leettools
LeetTools is an AI search assistant that can perform highly customizable search workflows and generate customized format results based on both web and local knowledge bases. It provides an automated document pipeline for data ingestion, indexing, and storage, allowing users to focus on implementing workflows without worrying about infrastructure. LeetTools can run with minimal resource requirements on the command line with configurable LLM settings and supports different databases for various functions. Users can configure different functions in the same workflow to use different LLM providers and models.
deer-flow
DeerFlow is a community-driven Deep Research framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It supports FaaS deployment and one-click deployment based on Volcengine. The framework includes core capabilities like LLM integration, search and retrieval, RAG integration, MCP seamless integration, human collaboration, report post-editing, and content creation. The architecture is based on a modular multi-agent system with components like Coordinator, Planner, Research Team, and Text-to-Speech integration. DeerFlow also supports interactive mode, human-in-the-loop mechanism, and command-line arguments for customization.
For similar jobs

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.