
recommendarr
An LLM driven recommendation system based on Radarr and Sonarr library or watch history information
Stars: 516
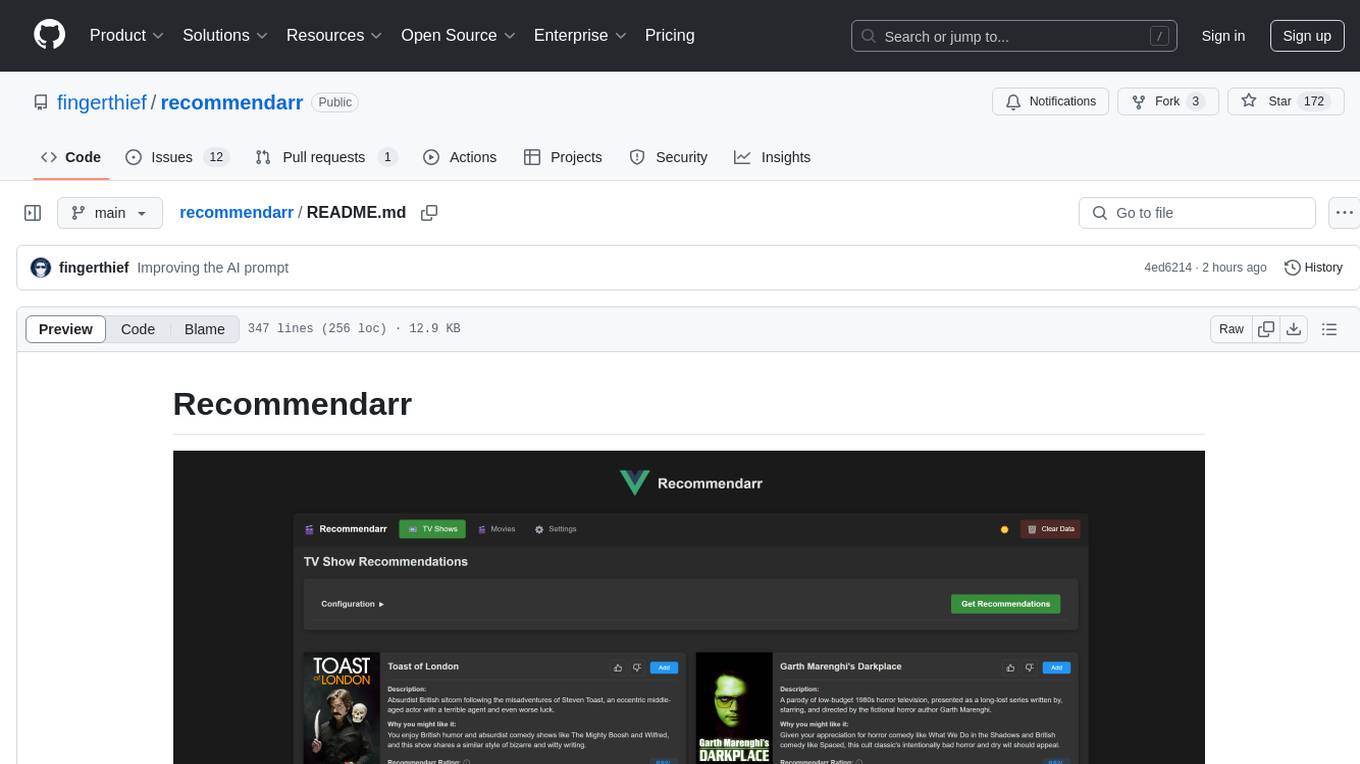
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
README:
Recommendarr is a web application that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI.
⚠️ IMPORTANT: When accessing this application from outside your network, you must open the application port on your router/firewall (default: 3000).
⚠️ PORT CONFIGURATION: The application now uses a single port (default: 3000) for both the frontend and API, configurable via thePORTenvironment variable.
- AI-Powered Recommendations: Get personalized TV show and movie suggestions based on your existing library
- Sonarr & Radarr Integration: Connects directly to your media servers to analyze your TV and movie collections
- Plex, Jellyfin, Tautulli & Trakt Integration: Analyzes your watch history to provide better recommendations based on what you've actually watched
- Flexible AI Support: Works with OpenAI, local models (Ollama/LM Studio), or any OpenAI-compatible API
- Customization Options: Adjust recommendation count, model parameters, and more
- Dark/Light Mode: Toggle between themes based on your preference
- Poster Images: Displays media posters with fallback generation
- Sonarr instance with API access (for TV recommendations)
- Radarr instance with API access (for movie recommendations)
- Plex, Jellyfin, Tautulli, or Trakt instance with API access (for watch history analysis) - optional
- An OpenAI API key or any OpenAI-compatible API (like local LLM servers)
- Docker (recommended) or Node.js (v14+) for manual installation
The simplest way to get started with Recommendarr:
# Pull and run with default port 3000
docker run -d \
--name recommendarr \
-p 3000:3000 \
-v recommendarr-data:/app/server/data \
tannermiddleton/recommendarr:latest
# Or run with a custom port (e.g., 8080)
docker run -d \
--name recommendarr \
-e PORT=8080 \
-p 8080:8080 \
-v recommendarr-data:/app/server/data \
tannermiddleton/recommendarr:latestThen visit http://localhost:3000 (or your custom port) in your browser.
Default Login:
- Username:
admin - Password:
1234
⚠️ IMPORTANT: Please change your password immediately after your first login for security reasons.
If you prefer using Docker Compose:
# Clone the repository (which includes the docker-compose.yml file)
git clone https://github.com/fingerthief/recommendarr.git
cd recommendarr
# Start the application
docker-compose up -dThis will:
- Pull the pre-built image from Docker Hub
- Configure proper networking and persistence
- Start the unified service
Then visit http://localhost:3000 (or your custom port if configured) in your browser.
You can customize the port by setting the PORT environment variable before running docker-compose:
PORT=8080 docker-compose up -dIf you want to build the Docker image yourself:
# Clone the repository
git clone https://github.com/fingerthief/recommendarr.git
cd recommendarr
# Build the Docker image
docker build -t recommendarr:local .
# Run the container with default port
docker run -d \
--name recommendarr \
-p 3000:3000 \
-v recommendarr-data:/app/server/data \
recommendarr:local
# Or run with custom port
docker run -d \
--name recommendarr \
-e PORT=8080 \
-p 8080:8080 \
-v recommendarr-data:/app/server/data \
recommendarr:localFor development or if you prefer not to use Docker:
- Clone the repository:
git clone https://github.com/fingerthief/recommendarr.git
cd recommendarr- Install dependencies:
npm install- Build the frontend:
npm run build- Start the unified server:
npm run unified- Visit
http://localhost:3000(or your custom port if configured) in your browser.
- When you first open Recommendarr, you'll be prompted to connect to your services
- For Sonarr (TV shows):
- Enter your Sonarr URL (e.g.,
http://localhost:8989orhttps://sonarr.yourdomain.com) - Enter your Sonarr API key (found in Sonarr under Settings → General)
- Click "Connect"
- Enter your Sonarr URL (e.g.,
- For Radarr (Movies):
- Enter your Radarr URL (e.g.,
http://localhost:7878orhttps://radarr.yourdomain.com) - Enter your Radarr API key (found in Radarr under Settings → General)
- Click "Connect"
- Enter your Radarr URL (e.g.,
- For Plex (Optional - Watch History):
- Enter your Plex URL (e.g.,
http://localhost:32400orhttps://plex.yourdomain.com) - Enter your Plex token (can be found by following these instructions)
- Click "Connect"
- Enter your Plex URL (e.g.,
- For Jellyfin (Optional - Watch History):
- Enter your Jellyfin URL (e.g.,
http://localhost:8096orhttps://jellyfin.yourdomain.com) - Enter your Jellyfin API key (found in Jellyfin under Dashboard → API Keys)
- Enter your Jellyfin user ID (found in Jellyfin user settings)
- Click "Connect"
- Enter your Jellyfin URL (e.g.,
- For Tautulli (Optional - Watch History):
- Enter your Tautulli URL (e.g.,
http://localhost:8181orhttps://tautulli.yourdomain.com) - Enter your Tautulli API key (found in Tautulli under Settings → Web Interface → API)
- Click "Connect"
- Enter your Tautulli URL (e.g.,
- For Trakt (Optional - Watch History):
- Click "Connect" on the Trakt connection page
- Authorize Recommendarr with your Trakt.tv account
- Complete the authentication process to connect your Trakt watch history
You can connect to any combination of these services based on your needs.
- Navigate to Settings
- Select the AI Service tab
- Enter your AI service details:
-
API URL: For OpenAI, use
https://api.openai.com/v1. For local models, use your server URL (e.g.,http://localhost:1234/v1) - API Key: Your OpenAI API key or appropriate key for other services (not needed for some local servers)
- Model: Select a model from the list or leave as default
- Parameters: Adjust max tokens and temperature as needed
-
API URL: For OpenAI, use
- Click "Save Settings"
- Navigate to TV Recommendations or Movie Recommendations page
- Adjust the number of recommendations you'd like to receive using the slider
- If connected to Plex, Jellyfin, or Tautulli, choose whether to include your watch history in the recommendations
- Click "Get Recommendations"
- View your personalized media suggestions with posters and descriptions
If you want to run Recommendarr behind a reverse proxy (like Nginx, Traefik, or Caddy), follow these steps:
- Build a custom image with your public URL:
# Build with your public URL
docker build -t recommendarr:custom \
--build-arg PUBLIC_URL=https://recommendarr.yourdomain.com \
--build-arg BASE_URL=/ \
.
# Run with reverse proxy configuration
docker run -d \
--name recommendarr \
-p 3000:3000 \
-e PUBLIC_URL=https://recommendarr.yourdomain.com \
-e FORCE_SECURE_COOKIES=true \
-v recommendarr-data:/app/server/data \
recommendarr:custom- Configure your reverse proxy to forward requests to Recommendarr:
For Nginx:
server {
listen 443 ssl;
server_name recommendarr.yourdomain.com;
# SSL configuration
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass http://localhost:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}For Docker Compose:
services:
recommendarr:
build:
context: .
args:
- PUBLIC_URL=https://recommendarr.yourdomain.com
- BASE_URL=/
ports:
- "3000:3000"
# This allows accessing services on the host machine
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- NODE_ENV=production
- DOCKER_ENV=true
- PORT=3000
- PUBLIC_URL=https://recommendarr.yourdomain.com
# Enable secure cookies when behind HTTPS reverse proxy
- FORCE_SECURE_COOKIES=true
volumes:
- recommendarr-data:/app/server/data
restart: unless-stopped
volumes:
recommendarr-data:| Variable | Description | Default |
|---|---|---|
PORT |
The port to run both frontend and API | 3000 |
PUBLIC_URL |
The public URL where the app is accessible | http://localhost:${PORT} |
BASE_URL |
Base path for the application (for sub-path deployment) | / |
FORCE_SECURE_COOKIES |
Force secure cookies even on HTTP (for HTTPS reverse proxies) | false |
NODE_ENV |
Node.js environment | production |
DOCKER_ENV |
Flag to enable Docker-specific features | true |
Recommendarr works with various AI services:
- OpenAI API: Standard integration with models like GPT-3.5 and GPT-4
- Ollama: Self-hosted models with OpenAI-compatible API
- LM Studio: Run models locally on your computer
- Anthropic Claude: Via OpenAI-compatible endpoints
- Self-hosted models: Any service with OpenAI-compatible chat completions API
Here are some recommendations for models that work well with Recommendarr:
- Meta Llama 3.3 70B Instruct: Great performance for free
- Gemini 2.0 models (Flash/Pro/Thinking): Excellent recommendation quality
- DeepSeek R1 models: Strong performance across variants
- Claude 3.7/3.5 Haiku: Exceptional for understanding your library preferences
- GPT-4o mini: Excellent balance of performance and cost
- Grok Beta: Good recommendations at reasonable prices
- Amazon Nova Pro: Strong media understanding capabilities
- DeepSeek R1 7B Qwen Distill: Good performance for a smaller model (via LM Studio)
For best results, try setting max tokens to 4000 and temperature between 0.6-0.8 depending on the model.
If you're using a reverse proxy with HTTPS and get errors like:
cookie "auth_token" has been rejected because a non-https cookie can't be set "secure"
This happens when your reverse proxy terminates HTTPS but forwards the request to the container as HTTP. To fix this:
- Add the
FORCE_SECURE_COOKIES=trueenvironment variable to your docker-compose.yml or docker run command:
environment:
- FORCE_SECURE_COOKIES=true- Make sure your reverse proxy forwards the correct headers. For Nginx, add:
proxy_set_header X-Forwarded-Proto $scheme;
- Always make sure the internal and external ports match (e.g., 3000:3000)
- When changing ports, update both the port mapping and PORT environment variable
For development purposes, you can run the frontend and backend separately:
# Run both frontend and backend in development mode
npm run dev
# Or run them separately:
# Frontend dev server with hot reloading
npm run serve
# Backend API server
npm run apiThe development server will use port 8080 for the frontend with hot reloading, and port 3050 for the API. In production, both run on a single port.
This project is licensed under the MIT License - see the LICENSE file for details.
- Vue.js - The progressive JavaScript framework
- Sonarr - For the amazing API that powers TV recommendations
- Radarr - For the API that enables movie recommendations
- Plex - For the API that provides watch history data
- Jellyfin - For the API that provides additional watch history data
- Tautulli - For the API that provides detailed Plex watch statistics
- Trakt - For the API that provides watch history and ratings data
- OpenRouter - For the API that powers AI-based suggestions
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for recommendarr
Similar Open Source Tools
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.

web-ui
WebUI is a user-friendly tool built on Gradio that enhances website accessibility for AI agents. It supports various Large Language Models (LLMs) and allows custom browser integration for seamless interaction. The tool eliminates the need for re-login and authentication challenges, offering high-definition screen recording capabilities.
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.
Groqqle
Groqqle 2.1 is a revolutionary, free AI web search and API that instantly returns ORIGINAL content derived from source articles, websites, videos, and even foreign language sources, for ANY target market of ANY reading comprehension level! It combines the power of large language models with advanced web and news search capabilities, offering a user-friendly web interface, a robust API, and now a powerful Groqqle_web_tool for seamless integration into your projects. Developers can instantly incorporate Groqqle into their applications, providing a powerful tool for content generation, research, and analysis across various domains and languages.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
rag-gpt
RAG-GPT is a tool that allows users to quickly launch an intelligent customer service system with Flask, LLM, and RAG. It includes frontend, backend, and admin console components. The tool supports cloud-based and local LLMs, enables deployment of conversational service robots in minutes, integrates diverse knowledge bases, offers flexible configuration options, and features an attractive user interface.

sim
Sim is a platform that allows users to build and deploy AI agent workflows quickly and easily. It provides cloud-hosted and self-hosted options, along with support for local AI models. Users can set up the application using Docker Compose, Dev Containers, or manual setup with PostgreSQL and pgvector extension. The platform utilizes technologies like Next.js, Bun, PostgreSQL with Drizzle ORM, Better Auth for authentication, Shadcn and Tailwind CSS for UI, Zustand for state management, ReactFlow for flow editor, Fumadocs for documentation, Turborepo for monorepo management, Socket.io for real-time communication, and Trigger.dev for background jobs.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
VibeSurf
VibeSurf is an open-source AI agentic browser that combines workflow automation with intelligent AI agents, offering faster, cheaper, and smarter browser automation. It allows users to create revolutionary browser workflows, run multiple AI agents in parallel, perform intelligent AI automation tasks, maintain privacy with local LLM support, and seamlessly integrate as a Chrome extension. Users can save on token costs, achieve efficiency gains, and enjoy deterministic workflows for consistent and accurate results. VibeSurf also provides a Docker image for easy deployment and offers pre-built workflow templates for common tasks.
kubewall
kubewall is an open-source, single-binary Kubernetes dashboard with multi-cluster management and AI integration. It provides a simple and rich real-time interface to manage and investigate your clusters. With features like multi-cluster management, AI-powered troubleshooting, real-time monitoring, single-binary deployment, in-depth resource views, browser-based access, search and filter capabilities, privacy by default, port forwarding, live refresh, aggregated pod logs, and clean resource management, kubewall offers a comprehensive solution for Kubernetes cluster management.

Zero
Zero is an open-source AI email solution that allows users to self-host their email app while integrating external services like Gmail. It aims to modernize and enhance emails through AI agents, offering features like open-source transparency, AI-driven enhancements, data privacy, self-hosting freedom, unified inbox, customizable UI, and developer-friendly extensibility. Built with modern technologies, Zero provides a reliable tech stack including Next.js, React, TypeScript, TailwindCSS, Node.js, Drizzle ORM, and PostgreSQL. Users can set up Zero using standard setup or Dev Container setup for VS Code users, with detailed environment setup instructions for Better Auth, Google OAuth, and optional GitHub OAuth. Database setup involves starting a local PostgreSQL instance, setting up database connection, and executing database commands for dependencies, tables, migrations, and content viewing.
For similar tasks
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.

sokuji
Sokuji is a desktop application that provides live speech translation using advanced AI models from OpenAI, Google Gemini, CometAPI, Palabra.ai, and Kizuna AI. It aims to bridge language barriers in live conversations by capturing audio input, processing it through AI models, and delivering real-time translated output. The tool goes beyond basic translation by offering audio routing solutions with virtual device management (Linux only) for seamless integration with other applications. It features a modern interface with real-time audio visualization, comprehensive logging, and support for multiple AI providers and models.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"
search_with_ai
Build your own conversation-based search with AI, a simple implementation with Node.js & Vue3. Live Demo Features: * Built-in support for LLM: OpenAI, Google, Lepton, Ollama(Free) * Built-in support for search engine: Bing, Sogou, Google, SearXNG(Free) * Customizable pretty UI interface * Support dark mode * Support mobile display * Support local LLM with Ollama * Support i18n * Support Continue Q&A with contexts.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.