
chunkr
Vision infrastructure to turn complex documents into RAG/LLM-ready data
Stars: 2094
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
README:
Production-ready API service for document layout analysis, OCR, and semantic chunking.
Convert PDFs, PPTs, Word docs & images into RAG/LLM-ready chunks.
Layout Analysis | OCR + Bounding Boxes | Structured HTML and markdown | VLM Processing controls
Try it out!
·
Report Bug
·
Contact
·
Discord

- Table of Contents
- (Super) Quick Start
- Documentation
- Self-Hosted Deployment Options
- LLM Configuration
- Licensing
- Connect With Us
- Go to chunkr.ai
- Make an account and copy your API key
- Install our Python SDK:
pip install chunkr-ai- Use the SDK to process your documents:
from chunkr_ai import Chunkr
# Initialize with your API key from chunkr.ai
chunkr = Chunkr(api_key="your_api_key")
# Upload a document (URL or local file path)
url = "https://chunkr-web.s3.us-east-1.amazonaws.com/landing_page/input/science.pdf"
task = chunkr.upload(url)
# Export results in various formats
html = task.html(output_file="output.html")
markdown = task.markdown(output_file="output.md")
content = task.content(output_file="output.txt")
task.json(output_file="output.json")
# Clean up
chunkr.close()Visit our docs for more information and examples.
-
Prerequisites:
- Docker and Docker Compose
- NVIDIA Container Toolkit (for GPU support, optional)
-
Clone the repo:
git clone https://github.com/lumina-ai-inc/chunkr
cd chunkr- Set up environment variables:
# Copy the example environment file
cp .env.example .env
# Configure your environment variables
# Required: LLM__KEY as your OpenAI API keyFor more information on how to set up LLMs, see here.
- Start the services:
With GPU:
docker compose up -dAccess the services:
- Web UI:
http://localhost:5173 - API:
http://localhost:8000
Important:
- Requires an NVIDIA CUDA GPU
- CPU-only deployment via
compose-cpu.yamlis currently in development and not recommended for use- To use a CPU version run
docker compose -f compose-cpu.yaml up -d
- Stop the services when done:
docker compose downFor production environments, we provide a Helm chart and detailed deployment instructions:
- See our detailed guide at
kube/README.md - Includes configurations for high availability and scaling
For enterprise support and deployment assistance, contact us.
You can use any OpenAI API compatible endpoint by setting the following variables in your .env file:
LLM__KEY:
LLM__MODEL:
LLM__URL:
LLM__KEY=your_openai_api_key
LLM__MODEL=gpt-4o
LLM__URL=https://api.openai.com/v1/chat/completions
For getting a Google AI Studio API key, see here.
LLM__KEY=your_google_ai_studio_api_key
LLM__MODEL=gemini-2.0-flash-lite
LLM__URL=https://generativelanguage.googleapis.com/v1beta/openai/chat/completions
Check here for available models.
LLM__KEY=your_open_router_api_key
LLM__MODEL=google/gemini-pro-1.5
LLM__URL=https://openrouter.ai/api/v1/chat/completions
You can use any OpenAI API compatible endpoint. To host your own LLM you can use VLLM or Ollama.
LLM__KEY=your_api_key
LLM__MODEL=model_name
LLM__URL=http://localhost:8000/v1
The core of this project is dual-licensed:
- GNU Affero General Public License v3.0 (AGPL-3.0)
- Commercial License
To use Chunkr without complying with the AGPL-3.0 license terms you can contact us or visit our website.
- 📧 Email: [email protected]
- 📅 Schedule a call: Book a 30-minute meeting
- 🌐 Visit our website: chunkr.ai
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chunkr
Similar Open Source Tools
chunkr
Chunkr is an open-source document intelligence API that provides a production-ready service for document layout analysis, OCR, and semantic chunking. It allows users to convert PDFs, PPTs, Word docs, and images into RAG/LLM-ready chunks. The API offers features such as layout analysis, OCR with bounding boxes, structured HTML and markdown output, and VLM processing controls. Users can interact with Chunkr through a Python SDK, enabling them to upload documents, process them, and export results in various formats. The tool also supports self-hosted deployment options using Docker Compose or Kubernetes, with configurations for different AI models like OpenAI, Google AI Studio, and OpenRouter. Chunkr is dual-licensed under the GNU Affero General Public License v3.0 (AGPL-3.0) and a commercial license, providing flexibility for different usage scenarios.
youtube_summarizer
YouTube AI Summarizer is a modern Next.js-based tool for AI-powered YouTube video summarization. It allows users to generate concise summaries of YouTube videos using various AI models, with support for multiple languages and summary styles. The application features flexible API key requirements, multilingual support, flexible summary modes, a smart history system, modern UI/UX design, and more. Users can easily input a YouTube URL, select language, summary type, and AI model, and generate summaries with real-time progress tracking. The tool offers a clean, well-structured summary view, history dashboard, and detailed history view for past summaries. It also provides configuration options for API keys and database setup, along with technical highlights, performance improvements, and a modern tech stack.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.
better-chatbot
Better Chatbot is an open-source AI chatbot designed for individuals and teams, inspired by various AI models. It integrates major LLMs, offers powerful tools like MCP protocol and data visualization, supports automation with custom agents and visual workflows, enables collaboration by sharing configurations, provides a voice assistant feature, and ensures an intuitive user experience. The platform is built with Vercel AI SDK and Next.js, combining leading AI services into one platform for enhanced chatbot capabilities.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
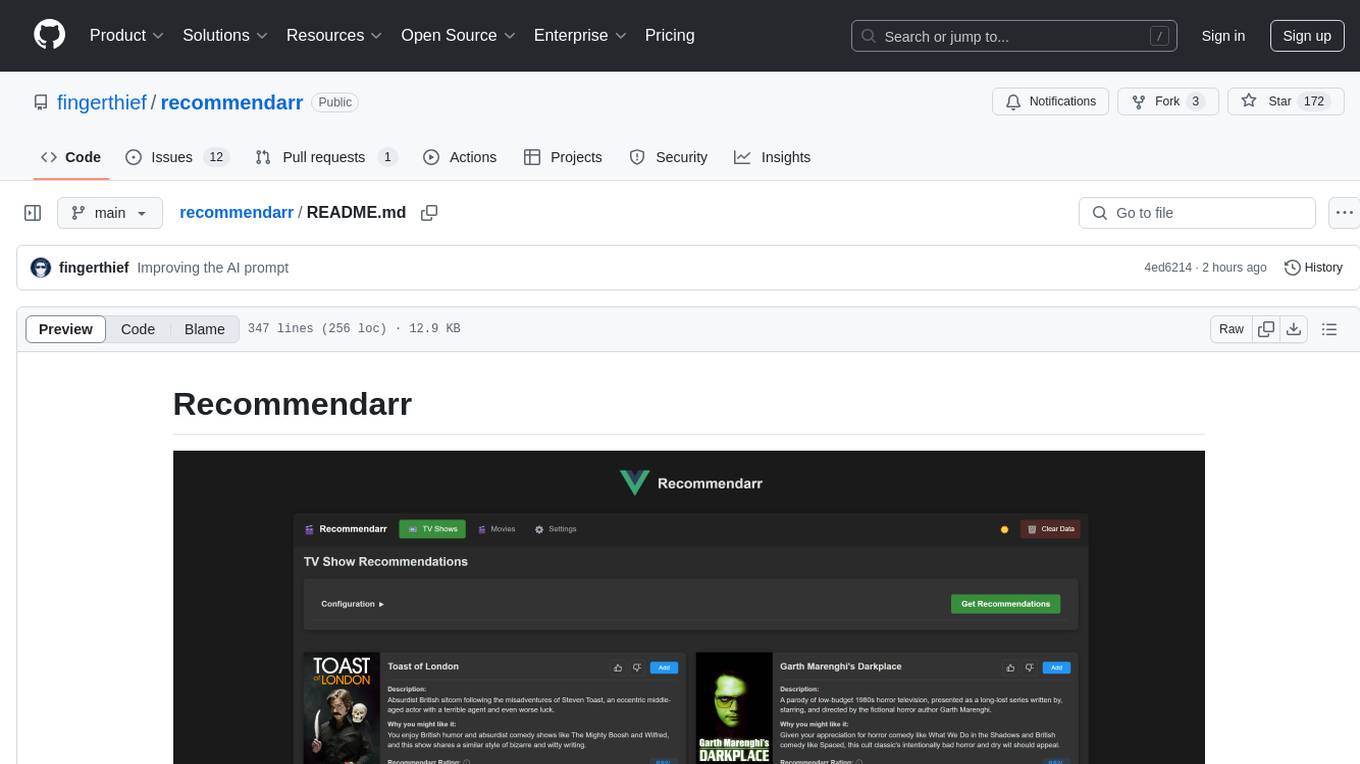
recommendarr
Recommendarr is a tool that generates personalized TV show and movie recommendations based on your Sonarr, Radarr, Plex, and Jellyfin libraries using AI. It offers AI-powered recommendations, media server integration, flexible AI support, watch history analysis, customization options, and dark/light mode toggle. Users can connect their media libraries and watch history services, configure AI service settings, and get personalized recommendations based on genre, language, and mood/vibe preferences. The tool works with any OpenAI-compatible API and offers various recommended models for different cost options and performance levels. It provides personalized suggestions, detailed information, filter options, watch history analysis, and one-click adding of recommended content to Sonarr/Radarr.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.
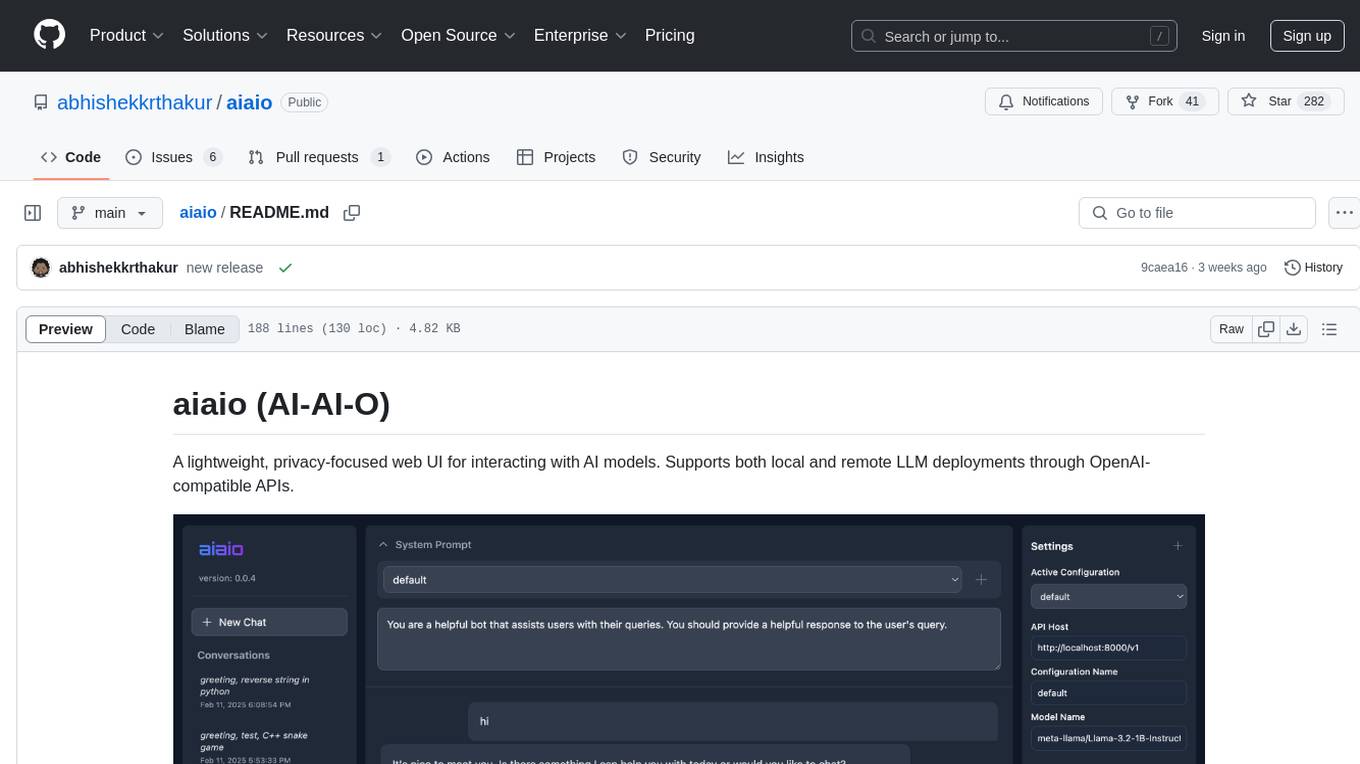
aiaio
aiaio (AI-AI-O) is a lightweight, privacy-focused web UI for interacting with AI models. It supports both local and remote LLM deployments through OpenAI-compatible APIs. The tool provides features such as dark/light mode support, local SQLite database for conversation storage, file upload and processing, configurable model parameters through UI, privacy-focused design, responsive design for mobile/desktop, syntax highlighting for code blocks, real-time conversation updates, automatic conversation summarization, customizable system prompts, WebSocket support for real-time updates, Docker support for deployment, multiple API endpoint support, and multiple system prompt support. Users can configure model parameters and API settings through the UI, handle file uploads, manage conversations, and use keyboard shortcuts for efficient interaction. The tool uses SQLite for storage with tables for conversations, messages, attachments, and settings. Contributions to the project are welcome under the Apache License 2.0.
UCAgent
UCAgent is an AI-powered automated UT verification agent for chip design. It automates chip verification workflow, supports functional and code coverage analysis, ensures consistency among documentation, code, and reports, and collaborates with mainstream Code Agents via MCP protocol. It offers three intelligent interaction modes and requires Python 3.11+, Linux/macOS OS, 4GB+ memory, and access to an AI model API. Users can clone the repository, install dependencies, configure qwen, and start verification. UCAgent supports various verification quality improvement options and basic operations through TUI shortcuts and stage color indicators. It also provides documentation build and preview using MkDocs, PDF manual build using Pandoc + XeLaTeX, and resources for further help and contribution.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.
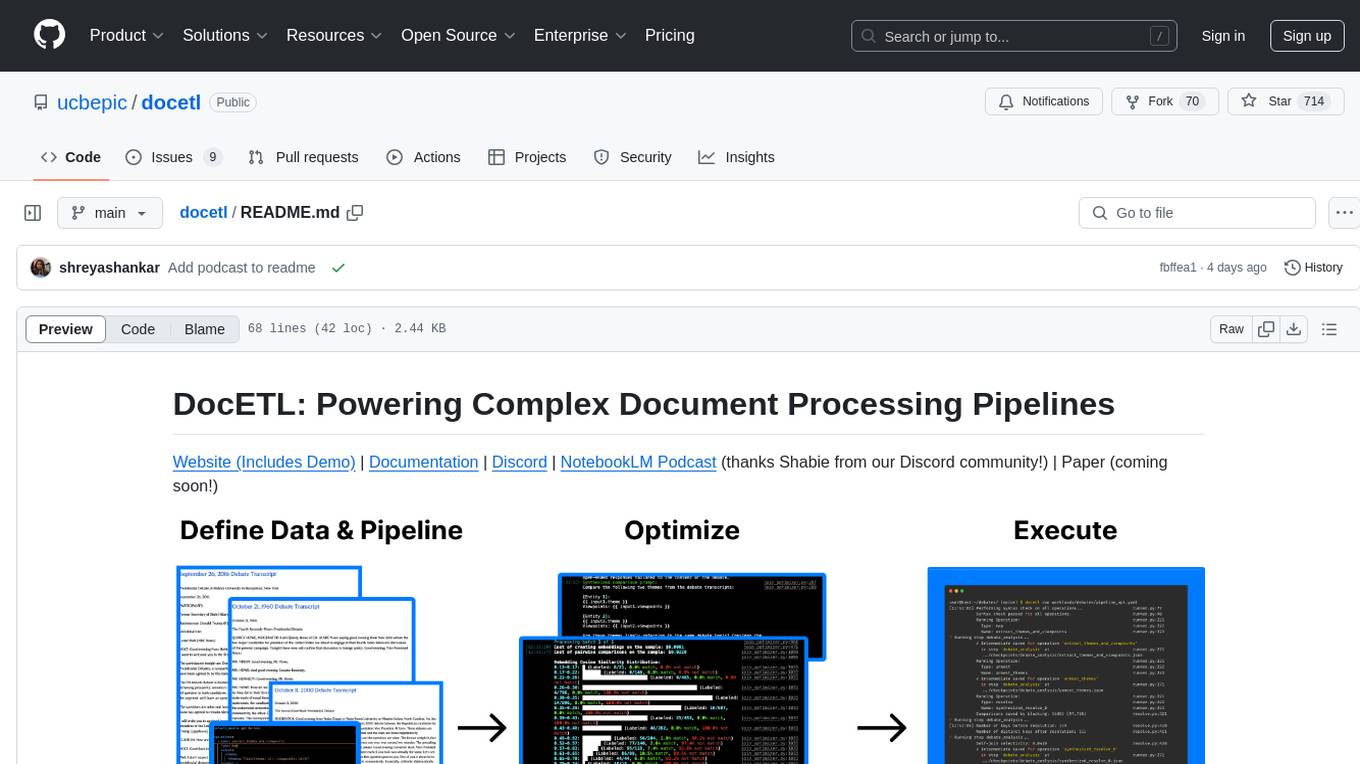
docetl
DocETL is a tool for creating and executing data processing pipelines, especially suited for complex document processing tasks. It offers a low-code, declarative YAML interface to define LLM-powered operations on complex data. Ideal for maximizing correctness and output quality for semantic processing on a collection of data, representing complex tasks via map-reduce, maximizing LLM accuracy, handling long documents, and automating task retries based on validation criteria.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.
AutoDocs
AutoDocs by Sita is a tool designed to automate documentation for any repository. It parses the repository using tree-sitter and SCIP, constructs a code dependency graph, and generates repository-wide, dependency-aware documentation and summaries. It provides a FastAPI backend for ingestion/search and a Next.js web UI for chat and exploration. Additionally, it includes an MCP server for deep search capabilities. The tool aims to simplify the process of generating accurate and high-signal documentation for codebases.
ChatGPT
The ChatGPT API Free Reverse Proxy provides free self-hosted API access to ChatGPT (`gpt-3.5-turbo`) with OpenAI's familiar structure, eliminating the need for code changes. It offers streaming response, API endpoint compatibility, and complimentary access without an API key. Installation options include Docker, PC/Server, and Termux on Android devices. The API can be accessed through a self-hosted local server or a pre-hosted API with an API key obtained from the Discord server. Usage examples are provided for Python and Node.js, and the project is licensed under AGPL-3.0.
For similar tasks

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.

step-free-api
The StepChat Free service provides high-speed streaming output, multi-turn dialogue support, online search support, long document interpretation, and image parsing. It offers zero-configuration deployment, multi-token support, and automatic session trace cleaning. It is fully compatible with the ChatGPT interface. Additionally, it provides seven other free APIs for various services. The repository includes a disclaimer about using reverse APIs and encourages users to avoid commercial use to prevent service pressure on the official platform. It offers online testing links, showcases different demos, and provides deployment guides for Docker, Docker-compose, Render, Vercel, and native deployments. The repository also includes information on using multiple accounts, optimizing Nginx reverse proxy, and checking the liveliness of refresh tokens.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
searchGPT
searchGPT is an open-source project that aims to build a search engine based on Large Language Model (LLM) technology to provide natural language answers. It supports web search with real-time results, file content search, and semantic search from sources like the Internet. The tool integrates LLM technologies such as OpenAI and GooseAI, and offers an easy-to-use frontend user interface. The project is designed to provide grounded answers by referencing real-time factual information, addressing the limitations of LLM's training data. Contributions, especially from frontend developers, are welcome under the MIT License.
LLMs-at-DoD
This repository contains tutorials for using Large Language Models (LLMs) in the U.S. Department of Defense. The tutorials utilize open-source frameworks and LLMs, allowing users to run them in their own cloud environments. The repository is maintained by the Defense Digital Service and welcomes contributions from users.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
erag
ERAG is an advanced system that combines lexical, semantic, text, and knowledge graph searches with conversation context to provide accurate and contextually relevant responses. This tool processes various document types, creates embeddings, builds knowledge graphs, and uses this information to answer user queries intelligently. It includes modules for interacting with web content, GitHub repositories, and performing exploratory data analysis using various language models.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.