
quadratic
Spreadsheet with AI, Code, Connections
Stars: 3828

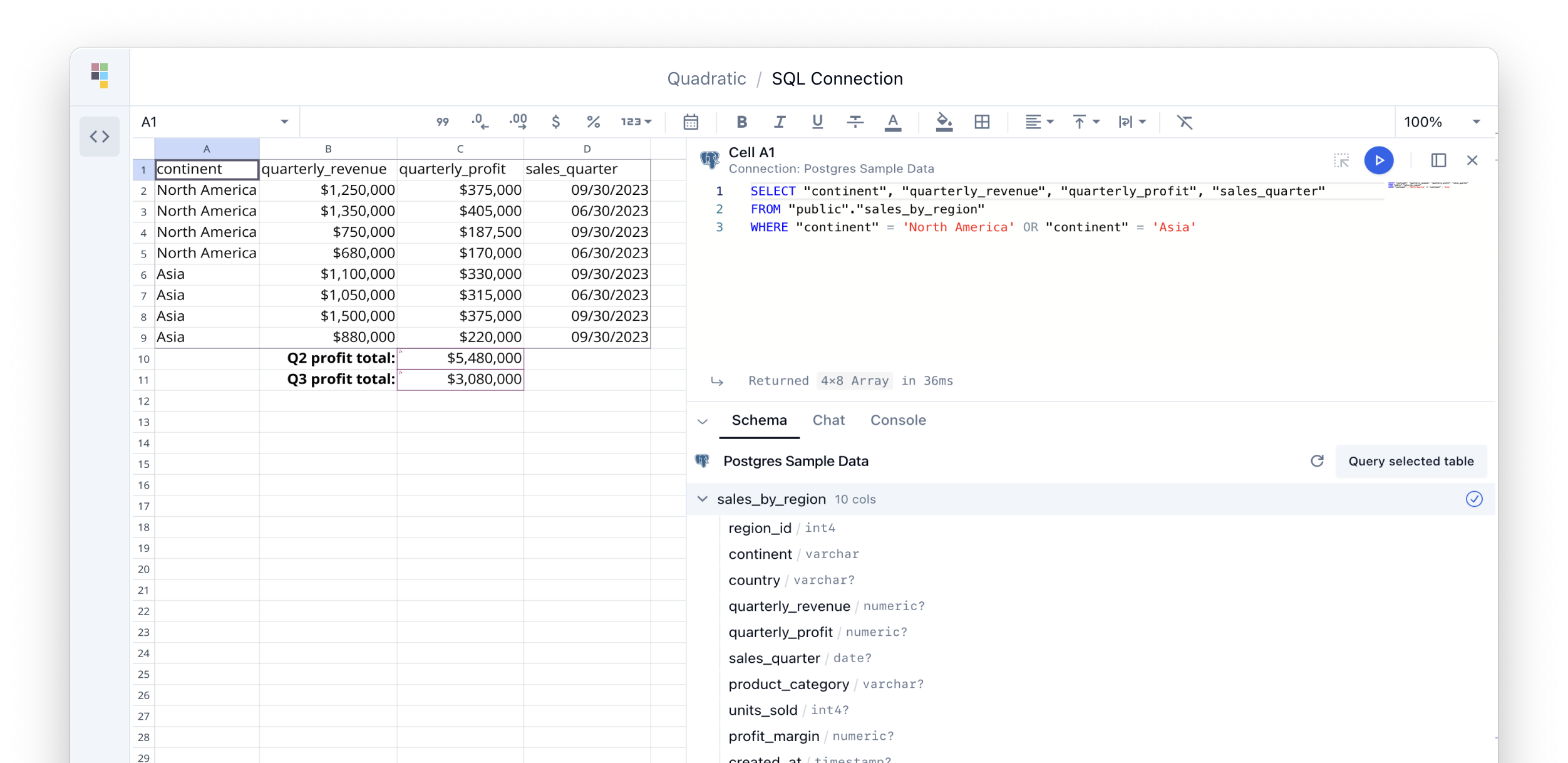
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.
README:
![]()
![]()


Learn more QuadraticHQ.com
Open Quadratic app.QuadraticHQ.com
Read the documentation docs.QuadraticHQ.com
Feature request or bug report? Submit a Github Issue
Want to contribute? Read our Contributing Guide
Check out our open roles ⟶ careers.quadratichq.com
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for quadratic
Similar Open Source Tools
quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.

embedJs
EmbedJs is a NodeJS framework that simplifies RAG application development by efficiently processing unstructured data. It segments data, creates relevant embeddings, and stores them in a vector database for quick retrieval.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
voidpulse
Voidpulse is an open-source Mixpanel alternative with AI capabilities. It is currently in private beta and being used in production for the Voidpet app. The project aims to provide analytics functionalities without the high cost associated with other tools. It is built using React, Typescript, Next.js on the frontend, and Node.js with TRPC & Drizzle ORM on the backend. Data is stored in Postgresql, Clickhouse is used for storing/querying events, Kafka for batch event insertion, and Redis for caching.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.
psychic
Finic is an open source python-based integration platform designed to simplify integration workflows for both business users and developers. It offers a drag-and-drop UI, a dedicated Python environment for each workflow, and generative AI features to streamline transformation tasks. With a focus on decoupling integration from product code, Finic aims to provide faster and more flexible integrations by supporting custom connectors. The tool is open source and allows deployment to users' own cloud environments with minimal legal friction.
finic
Finic is an open source python-based integration platform designed for business users to create v1 integrations with minimal code, while also being flexible for developers to build complex integrations directly in python. It offers a low-code web UI, a dedicated Python environment for each workflow, and generative AI features. Finic decouples integration from product code, supports custom connectors, and is open source. It is not an ETL tool but focuses on integrating functionality between applications via APIs or SFTP, and it is not a workflow automation tool optimized for complex use cases.
dbeaver
DBeaver is a free multi-platform database tool designed for developers, SQL programmers, database administrators, and analysts. It offers a wide range of features including schema editor, SQL editor, data editor, AI integration, ER diagrams, data export/import/migration, SQL execution plans, database administration tools, database dashboards, Spatial data viewer, proxy and SSH tunnelling, custom database drivers editor, etc. It supports over 100 database drivers out of the box and is compatible with any database that has a JDBC or ODBC driver. DBeaver also supports smart AI completion and code generation with OpenAI or Copilot.
goose
Codename Goose is an open-source, extensible AI agent designed to provide functionalities beyond code suggestions. Users can install, execute, edit, and test with any LLM. The tool aims to enhance the coding experience by offering advanced features and capabilities. Stay updated for the upcoming 1.0 release scheduled by the end of January 2025. Explore the v0.X documentation available on the project's GitHub pages.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.
baserow
Baserow is a secure, open-source platform that allows users to build databases, applications, automations, and AI agents without writing any code. With enterprise-grade security compliance and both cloud and self-hosted deployment options, Baserow empowers teams to structure data, automate processes, create internal tools, and build custom dashboards. It features a spreadsheet database hybrid, AI Assistant for natural language database creation, GDPR, HIPAA, and SOC 2 Type II compliance, and seamless integration with existing tools. Baserow is API-first, extensible, and uses frameworks like Django, Vue.js, and PostgreSQL.
rowfill
Rowfill is an open-source document processing platform designed for knowledge workers. It offers advanced AI capabilities to extract, analyze, and process data from complex documents, images, and PDFs. The platform features advanced OCR and processing functionalities, auto-schema generation, and custom actions for creating tailored workflows. It prioritizes privacy and security by supporting Local LLMs like Llama and Mistral, syncing with company data while maintaining privacy, and being open source with AGPLv3 licensing. Rowfill is a versatile tool that aims to streamline document processing tasks for users in various industries.
For similar tasks

supersonic
SuperSonic is a next-generation BI platform that integrates Chat BI (powered by LLM) and Headless BI (powered by semantic layer) paradigms. This integration ensures that Chat BI has access to the same curated and governed semantic data models as traditional BI. Furthermore, the implementation of both paradigms benefits from the integration: * Chat BI's Text2SQL gets augmented with context-retrieval from semantic models. * Headless BI's query interface gets extended with natural language API. SuperSonic provides a Chat BI interface that empowers users to query data using natural language and visualize the results with suitable charts. To enable such experience, the only thing necessary is to build logical semantic models (definition of metric/dimension/tag, along with their meaning and relationships) through a Headless BI interface. Meanwhile, SuperSonic is designed to be extensible and composable, allowing custom implementations to be added and configured with Java SPI. The integration of Chat BI and Headless BI has the potential to enhance the Text2SQL generation in two dimensions: 1. Incorporate data semantics (such as business terms, column values, etc.) into the prompt, enabling LLM to better understand the semantics and reduce hallucination. 2. Offload the generation of advanced SQL syntax (such as join, formula, etc.) from LLM to the semantic layer to reduce complexity. With these ideas in mind, we develop SuperSonic as a practical reference implementation and use it to power our real-world products. Additionally, to facilitate further development we decide to open source SuperSonic as an extensible framework.

sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.
quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.
buster
Buster is a modern analytics platform designed with AI in mind, focusing on self-serve experiences powered by Large Language Models. It addresses pain points in existing tools by advocating for AI-centric app development, cost-effective data warehousing, improved CI/CD processes, and empowering data teams to create powerful, user-friendly data experiences. The platform aims to revolutionize AI analytics by enabling data teams to build deep integrations and own their entire analytics stack.
Ivy-Framework
Ivy-Framework is a powerful tool for building internal applications with AI assistance using C# codebase. It provides a CLI for project initialization, authentication integrations, database support, LLM code generation, secrets management, container deployment, hot reload, dependency injection, state management, routing, and external widget framework. Users can easily create data tables for sorting, filtering, and pagination. The framework offers a seamless integration of front-end and back-end development, making it ideal for developing robust internal tools and dashboards.

doris
Doris is a lightweight and user-friendly data visualization tool designed for quick and easy exploration of datasets. It provides a simple interface for users to upload their data and generate interactive visualizations without the need for coding. With Doris, users can easily create charts, graphs, and dashboards to analyze and present their data in a visually appealing way. The tool supports various data formats and offers customization options to tailor visualizations to specific needs. Whether you are a data analyst, researcher, or student, Doris simplifies the process of data exploration and presentation.
langchat
LangChat is an enterprise AIGC project solution in the Java ecosystem. It integrates AIGC large model functionality on top of the RBAC permission system to help enterprises quickly customize AI knowledge bases and enterprise AI robots. It supports integration with various large models such as OpenAI, Gemini, Ollama, Azure, Zhifu, Alibaba Tongyi, Baidu Qianfan, etc. The project is developed solely by TyCoding and is continuously evolving. It features multi-modality, dynamic configuration, knowledge base support, advanced RAG capabilities, function call customization, multi-channel deployment, workflows visualization, AIGC client application, and more.
StepWise
StepWise is a code-first, event-driven workflow framework for .NET designed to help users build complex workflows in a simple and efficient way. It allows users to define workflows using C# code, visualize and execute workflows from a browser, execute steps in parallel, and resolve dependencies automatically. StepWise also features an AI assistant called `Geeno` in its WebUI to help users run and analyze workflows with ease.
For similar jobs

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
sqlcoder
Defog's SQLCoder is a family of state-of-the-art large language models (LLMs) designed for converting natural language questions into SQL queries. It outperforms popular open-source models like gpt-4 and gpt-4-turbo on SQL generation tasks. SQLCoder has been trained on more than 20,000 human-curated questions based on 10 different schemas, and the model weights are licensed under CC BY-SA 4.0. Users can interact with SQLCoder through the 'transformers' library and run queries using the 'sqlcoder launch' command in the terminal. The tool has been tested on NVIDIA GPUs with more than 16GB VRAM and Apple Silicon devices with some limitations. SQLCoder offers a demo on their website and supports quantized versions of the model for consumer GPUs with sufficient memory.

TableLLM
TableLLM is a large language model designed for efficient tabular data manipulation tasks in real office scenarios. It can generate code solutions or direct text answers for tasks like insert, delete, update, query, merge, and chart operations on tables embedded in spreadsheets or documents. The model has been fine-tuned based on CodeLlama-7B and 13B, offering two scales: TableLLM-7B and TableLLM-13B. Evaluation results show its performance on benchmarks like WikiSQL, Spider, and self-created table operation benchmark. Users can use TableLLM for code and text generation tasks on tabular data.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.
quadratic
Quadratic is a modern multiplayer spreadsheet application that integrates Python, AI, and SQL functionalities. It aims to streamline team collaboration and data analysis by enabling users to pull data from various sources and utilize popular data science tools. The application supports building dashboards, creating internal tools, mixing data from different sources, exploring data for insights, visualizing Python workflows, and facilitating collaboration between technical and non-technical team members. Quadratic is built with Rust + WASM + WebGL to ensure seamless performance in the browser, and it offers features like WebGL Grid, local file management, Python and Pandas support, Excel formula support, multiplayer capabilities, charts and graphs, and team support. The tool is currently in Beta with ongoing development for additional features like JS support, SQL database support, and AI auto-complete.