
llm_aided_ocr
Enhance Tesseract OCR output for scanned PDFs by applying Large Language Model (LLM) corrections.
Stars: 1449
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.
README:
The LLM-Aided OCR Project is an advanced system designed to significantly enhance the quality of Optical Character Recognition (OCR) output. By leveraging cutting-edge natural language processing techniques and large language models (LLMs), this project transforms raw OCR text into highly accurate, well-formatted, and readable documents.
To see what the LLM-Aided OCR Project can do, check out these example outputs:
- PDF to image conversion
- OCR using Tesseract
- Advanced error correction using LLMs (local or API-based)
- Smart text chunking for efficient processing
- Markdown formatting option
- Header and page number suppression (optional)
- Quality assessment of the final output
- Support for both local LLMs and cloud-based API providers (OpenAI, Anthropic)
- Asynchronous processing for improved performance
- Detailed logging for process tracking and debugging
- GPU acceleration for local LLM inference
-
PDF to Image Conversion
- Function:
convert_pdf_to_images() - Uses
pdf2imagelibrary to convert PDF pages into images - Supports processing a subset of pages with
max_pagesandskip_first_n_pagesparameters
- Function:
-
OCR Processing
- Function:
ocr_image() - Utilizes
pytesseractfor text extraction - Includes image preprocessing with
preprocess_image()function:- Converts image to grayscale
- Applies binary thresholding using Otsu's method
- Performs dilation to enhance text clarity
- Function:
-
Chunk Creation
- The
process_document()function splits the full text into manageable chunks - Uses sentence boundaries for natural splits
- Implements an overlap between chunks to maintain context
- The
-
Error Correction and Formatting
- Core function:
process_chunk() - Two-step process:
a. OCR Correction:
- Uses LLM to fix OCR-induced errors
- Maintains original structure and content b. Markdown Formatting (optional):
- Converts text to proper markdown format
- Handles headings, lists, emphasis, and more
- Core function:
-
Duplicate Content Removal
- Implemented within the markdown formatting step
- Identifies and removes exact or near-exact repeated paragraphs
- Preserves unique content and ensures text flow
-
Header and Page Number Suppression (Optional)
- Can be configured to remove or distinctly format headers, footers, and page numbers
-
Flexible LLM Support
- Supports both local LLMs and cloud-based API providers (OpenAI, Anthropic)
- Configurable through environment variables
-
Local LLM Handling
- Function:
generate_completion_from_local_llm() - Uses
llama_cpplibrary for local LLM inference - Supports custom grammars for structured output
- Function:
-
API-based LLM Handling
- Functions:
generate_completion_from_claude()andgenerate_completion_from_openai() - Implements proper error handling and retry logic
- Manages token limits and adjusts request sizes dynamically
- Functions:
-
Asynchronous Processing
- Uses
asynciofor concurrent processing of chunks when using API-based LLMs - Maintains order of processed chunks for coherent final output
- Uses
-
Token Estimation
- Function:
estimate_tokens() - Uses model-specific tokenizers when available
- Falls back to
approximate_tokens()for quick estimation
- Function:
-
Dynamic Token Adjustment
- Adjusts
max_tokensparameter based on prompt length and model limits - Implements
TOKEN_BUFFERandTOKEN_CUSHIONfor safe token management
- Adjusts
-
Output Quality Evaluation
- Function:
assess_output_quality() - Compares original OCR text with processed output
- Uses LLM to provide a quality score and explanation
- Function:
- Comprehensive logging throughout the codebase
- Detailed error messages and stack traces for debugging
- Suppresses HTTP request logs to reduce noise
The project uses a .env file for easy configuration. Key settings include:
- LLM selection (local or API-based)
- API provider selection
- Model selection for different providers
- Token limits and buffer sizes
- Markdown formatting options
-
Raw OCR Output: Saved as
{base_name}__raw_ocr_output.txt -
LLM Corrected Output: Saved as
{base_name}_llm_corrected.mdor.txt
The script generates detailed logs of the entire process, including timing information and quality assessments.
- Python 3.12+
- Tesseract OCR engine
- PDF2Image library
- PyTesseract
- OpenAI API (optional)
- Anthropic API (optional)
- Local LLM support (optional, requires compatible GGUF model)
- Install Pyenv and Python 3.12 (if needed):
# Install Pyenv and python 3.12 if needed and then use it to create venv:
if ! command -v pyenv &> /dev/null; then
sudo apt-get update
sudo apt-get install -y build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \
xz-utils tk-dev libffi-dev liblzma-dev python3-openssl git
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
echo 'eval "$(pyenv init --path)"' >> ~/.zshrc
source ~/.zshrc
fi
cd ~/.pyenv && git pull && cd -
pyenv install 3.12- Set up the project:
# Use pyenv to create virtual environment:
git clone https://github.com/Dicklesworthstone/llm_aided_ocr
cd llm_aided_ocr
pyenv local 3.12
python -m venv venv
source venv/bin/activate
python -m pip install --upgrade pip
python -m pip install wheel
python -m pip install --upgrade setuptools wheel
pip install -r requirements.txt-
Install Tesseract OCR engine (if not already installed):
- For Ubuntu:
sudo apt-get install tesseract-ocr - For macOS:
brew install tesseract - For Windows: Download and install from GitHub
- For Ubuntu:
-
Set up your environment variables in a
.envfile:USE_LOCAL_LLM=False API_PROVIDER=OPENAI OPENAI_API_KEY=your_openai_api_key ANTHROPIC_API_KEY=your_anthropic_api_key
-
Place your PDF file in the project directory.
-
Update the
input_pdf_file_pathvariable in themain()function with your PDF filename. -
Run the script:
python llm_aided_ocr.py -
The script will generate several output files, including the final post-processed text.
The LLM-Aided OCR project employs a multi-step process to transform raw OCR output into high-quality, readable text:
-
PDF Conversion: Converts input PDF into images using
pdf2image. -
OCR: Applies Tesseract OCR to extract text from images.
-
Text Chunking: Splits the raw OCR output into manageable chunks for processing.
-
Error Correction: Each chunk undergoes LLM-based processing to correct OCR errors and improve readability.
-
Markdown Formatting (Optional): Reformats the corrected text into clean, consistent Markdown.
-
Quality Assessment: An LLM-based evaluation compares the final output quality to the original OCR text.
- Concurrent Processing: When using API-based models, chunks are processed concurrently to improve speed.
- Context Preservation: Each chunk includes a small overlap with the previous chunk to maintain context.
- Adaptive Token Management: The system dynamically adjusts the number of tokens used for LLM requests based on input size and model constraints.
The project uses a .env file for configuration. Key settings include:
-
USE_LOCAL_LLM: Set toTrueto use a local LLM,Falsefor API-based LLMs. -
API_PROVIDER: Choose between "OPENAI" or "CLAUDE". -
OPENAI_API_KEY,ANTHROPIC_API_KEY: API keys for respective services. -
CLAUDE_MODEL_STRING,OPENAI_COMPLETION_MODEL: Specify the model to use for each provider. -
LOCAL_LLM_CONTEXT_SIZE_IN_TOKENS: Set the context size for local LLMs.
The script generates several output files:
-
{base_name}__raw_ocr_output.txt: Raw OCR output from Tesseract. -
{base_name}_llm_corrected.md: Final LLM-corrected and formatted text.
- The system's performance is heavily dependent on the quality of the LLM used.
- Processing very large documents can be time-consuming and may require significant computational resources.
Contributions to this project are welcome! Please fork the repository and submit a pull request with your proposed changes.
This project is licensed under the MIT License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm_aided_ocr
Similar Open Source Tools
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.

extension-gen-ai
The Looker GenAI Extension provides code examples and resources for building a Looker Extension that integrates with Vertex AI Large Language Models (LLMs). Users can leverage the power of LLMs to enhance data exploration and analysis within Looker. The extension offers generative explore functionality to ask natural language questions about data and generative insights on dashboards to analyze data by asking questions. It leverages components like BQML Remote Models, BQML Remote UDF with Vertex AI, and Custom Fine Tune Model for different integration options. Deployment involves setting up infrastructure with Terraform and deploying the Looker Extension by creating a Looker project, copying extension files, configuring BigQuery connection, connecting to Git, and testing the extension. Users can save example prompts and configure user settings for the extension. Development of the Looker Extension environment includes installing dependencies, starting the development server, and building for production.

company-research-agent
Agentic Company Researcher is a multi-agent tool that generates comprehensive company research reports by utilizing a pipeline of AI agents to gather, curate, and synthesize information from various sources. It features multi-source research, AI-powered content filtering, real-time progress streaming, dual model architecture, modern React frontend, and modular architecture. The tool follows an agentic framework with specialized research and processing nodes, leverages separate models for content generation, uses a content curation system for relevance scoring and document processing, and implements a real-time communication system via WebSocket connections. Users can set up the tool quickly using the provided setup script or manually, and it can also be deployed using Docker and Docker Compose. The application can be used for local development and deployed to various cloud platforms like AWS Elastic Beanstalk, Docker, Heroku, and Google Cloud Run.

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.
llms
LLMs is a universal LLM API transformation server designed to standardize requests and responses between different LLM providers such as Anthropic, Gemini, and Deepseek. It uses a modular transformer system to handle provider-specific API formats, supporting real-time streaming responses and converting data into standardized formats. The server transforms requests and responses to and from unified formats, enabling seamless communication between various LLM providers.

web-ui
WebUI is a user-friendly tool built on Gradio that enhances website accessibility for AI agents. It supports various Large Language Models (LLMs) and allows custom browser integration for seamless interaction. The tool eliminates the need for re-login and authentication challenges, offering high-definition screen recording capabilities.
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
gitdiagram
GitDiagram is a tool that turns any GitHub repository into an interactive diagram for visualization in seconds. It offers instant visualization, interactivity, fast generation, customization, and API access. The tool utilizes a tech stack including Next.js, FastAPI, PostgreSQL, Claude 3.5 Sonnet, Vercel, EC2, GitHub Actions, PostHog, and Api-Analytics. Users can self-host the tool for local development and contribute to its development. GitDiagram is inspired by Gitingest and has future plans to use larger context models, allow user API key input, implement RAG with Mermaid.js docs, and include font-awesome icons in diagrams.
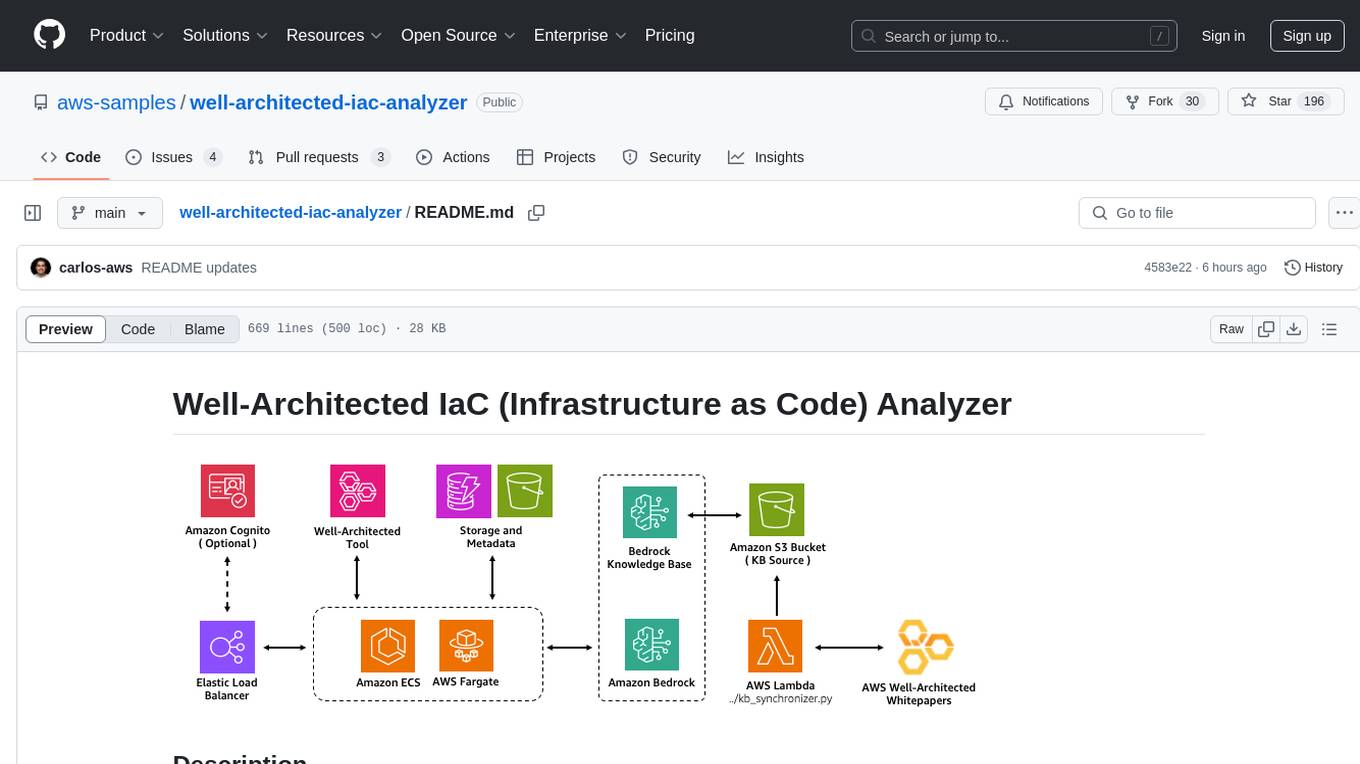
well-architected-iac-analyzer
Well-Architected Infrastructure as Code (IaC) Analyzer is a project demonstrating how generative AI can evaluate infrastructure code for alignment with best practices. It features a modern web application allowing users to upload IaC documents, complete IaC projects, or architecture diagrams for assessment. The tool provides insights into infrastructure code alignment with AWS best practices, offers suggestions for improving cloud architecture designs, and can generate IaC templates from architecture diagrams. Users can analyze CloudFormation, Terraform, or AWS CDK templates, architecture diagrams in PNG or JPEG format, and complete IaC projects with supporting documents. Real-time analysis against Well-Architected best practices, integration with AWS Well-Architected Tool, and export of analysis results and recommendations are included.
manifold
Manifold is a powerful platform for workflow automation using AI models. It supports text generation, image generation, and retrieval-augmented generation, integrating seamlessly with popular AI endpoints. Additionally, Manifold provides robust semantic search capabilities using PGVector combined with the SEFII engine. It is under active development and not production-ready.
Google_GenerativeAI
Google GenerativeAI (Gemini) is an unofficial C# .Net SDK based on REST APIs for accessing Google Gemini models. It offers a complete rewrite of the previous SDK with improved performance, flexibility, and ease of use. The SDK seamlessly integrates with LangChain.net, providing easy methods for JSON-based interactions and function calling with Google Gemini models. It includes features like enhanced JSON mode handling, function calling with code generator, multi-modal functionality, Vertex AI support, multimodal live API, image generation and captioning, retrieval-augmented generation with Vertex RAG Engine and Google AQA, easy JSON handling, Gemini tools and function calling, multimodal live API, and more.
utcp-specification
The Universal Tool Calling Protocol (UTCP) Specification repository contains the official documentation for a modern and scalable standard that enables AI systems and clients to discover and interact with tools across different communication protocols. It defines tool discovery mechanisms, call formats, provider configuration, authentication methods, and response handling.
action_mcp
Action MCP is a powerful tool for managing and automating your cloud infrastructure. It provides a user-friendly interface to easily create, update, and delete resources on popular cloud platforms. With Action MCP, you can streamline your deployment process, reduce manual errors, and improve overall efficiency. The tool supports various cloud providers and offers a wide range of features to meet your infrastructure management needs. Whether you are a developer, system administrator, or DevOps engineer, Action MCP can help you simplify and optimize your cloud operations.

code2prompt
Code2Prompt is a powerful command-line tool that generates comprehensive prompts from codebases, designed to streamline interactions between developers and Large Language Models (LLMs) for code analysis, documentation, and improvement tasks. It bridges the gap between codebases and LLMs by converting projects into AI-friendly prompts, enabling users to leverage AI for various software development tasks. The tool offers features like holistic codebase representation, intelligent source tree generation, customizable prompt templates, smart token management, Gitignore integration, flexible file handling, clipboard-ready output, multiple output options, and enhanced code readability.
For similar tasks
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.
mini.ai
This plugin extends and creates `a`/`i` textobjects in Neovim. It enhances some builtin textobjects (like `a(`, `a)`, `a'`, and more), creates new ones (like `a*`, `a
AiEditor
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.
blinko
Blinko is an innovative open-source project designed for individuals who want to quickly capture and organize their fleeting thoughts. It allows users to seamlessly jot down ideas the moment they strike, ensuring that no spark of creativity is lost. With advanced AI-powered note retrieval, data ownership, efficient and fast capturing, lightweight architecture, and open collaboration, Blinko offers a comprehensive solution for managing and accessing notes.
echo-editor
Echo Editor is a modern AI-powered WYSIWYG rich-text editor for Vue, featuring a beautiful UI with shadcn-vue components. It provides AI-powered writing assistance, Markdown support with real-time preview, rich text formatting, tables, code blocks, custom font sizes and styles, Word document import, I18n support, extensible architecture for creating extensions, TypeScript and Tailwind CSS support. The tool aims to enhance the writing experience by combining advanced features with user-friendly design.
LlamaPen
LlamaPen is a no-install needed GUI tool for Ollama, featuring a web-based interface accessible on both desktop and mobile. It allows easy setup and configuration, renders markdown, text, and LaTeX math, provides keyboard shortcuts for quick navigation, includes a built-in model and download manager, supports offline and PWA, and is 100% free and open-source. Users can chat with complete privacy as all chats are stored locally in the browser, ensuring near-instant chat load times. The tool also offers an optional cloud service, LlamaPen API, for running up-to-date models if unable to run locally, with a subscription option for increased rate limits and access to more expensive models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.