
AiEditor
AiEditor is a next-generation rich text editor for AI.
Stars: 1192
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.
README:


Give us a star so that you can be notified in time when we release new versions.

AiEditor is a next-generation rich text editor for AI. It is based on Web Component and supports almost any front-end framework such as Vue, React, Angular, etc. It is compatible with PC Web and mobiles, and provides two themes: light and dark. In addition, it also provides flexible configuration, and developers can easily use it to develop any text editing application.
For more information about AiEditor, please visit the official website: https://aieditor.dev
The goal of AIEditor is to create a rich text editor that is completely driven by AI, and supports docking with any large model, including private large models. Allow users to use their own private large model ApiKey. Not only that, all AI functions of AIEditor allow users to customize their own prompts and extended AI menus.
AIEditor is developed based on Web Component and supports integration with any mainstream front-end framework. AIEditor uses the more friendly LGPL open source protocol and is used through npm i aieditor,
without worrying about the GPL infection problem that may be caused by the GPL protocol.
In addition to the open source version, we also provide a more powerful commercial version, which does not limit the number of users or the number of applications. For more comparisons of commercial versions, please refer to here: https://aieditor.dev/price
- Classic/traditional style: https://aieditor.dev/demo
- Modern style: http://doc.aieditor.com.cn
- [x] Basics: Title, body, font, font size, bold, italic, underline, strikethrough, link, inline code, superscript, subscript, dividing line, quote, print
- [x] Enhanced: Undo, Redo, Format brush, Eraser, To-do list, font color, background color, Emoji expression, alignment, line height, ordered (unordered) list, paragraph indent, forced line break
- [x] Attachment: Supports image, video, file functions, supports select upload, paste upload, drag upload, support drag resize...
- [x] Code: Inline code, code block, language type selection, AI automatic comment, AI code explanation...
- [x] Table: Left increase right increase, left decrease right decrease, top increase and bottom increase, top decrease and bottom decrease, merge cells, unmerge
- [x] Markdown: Title, quote, table, image, code block, Highlight block (similar to vuepress :::), various lists, bold, italic, strikethrough...
- [x] AI: AI continuation, AI optimization, AI proofreading, AI translation, custom AI menu and prompts
- [x] More: internationalization, light theme, dark theme, mobile phone adaptation, full screen editing, @XXX (mention)...
- [x] Modern UI style similar to Tencent Documents
- [x] Notion-like content block dragging function
- [x] Word import, Word export
- [x] PDF export
- [x] Latex mathematical formula editing
- [x] Team collaboration (multiple people editing a document at the same time)
- [x] Annotation function, similar to the function of selecting a paragraph of text to annotate and comment on it in Word
- [ ] AI image insertion (AI text-to-image)
- [ ] AI image generation (AI image-to-image)
- [ ] AI one-click typesetting
- [ ] Further enhance the paste function
- [ ] Automatically obtain thumbnails when uploading videos
Visit the official website: https://aieditor.dev
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AiEditor
Similar Open Source Tools
AiEditor
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

PPTist
PPTist is a web-based presentation application that replicates most features of Microsoft Office PowerPoint. It supports various elements like text, images, shapes, charts, tables, videos, audio, and formulas. Users can edit and present slides directly in a web browser. It offers easy development with Vue 3.x and TypeScript, user-friendly experience with context menu and keyboard shortcuts, and feature-rich functionalities including AI-generated PPTs and mobile editing. PPTist aims to provide a desktop application-level experience for creating presentations.
tuff
Tuff is a local-first, AI-native, and infinitely extensible desktop command center designed to enhance workflow efficiency. It offers a seamless integration of core utilities, AI-powered search, contextual intelligence, and extensibility through custom plugins. With a beautiful UI design, rich functionality, simple operations, and a focus on security and reliability, Tuff provides users with a cross-platform desktop software that is easy to use and offers a good user experience.
MarkFlowy
MarkFlowy is a lightweight and feature-rich Markdown editor with built-in AI capabilities. It supports one-click export of conversations, translation of articles, and obtaining article abstracts. Users can leverage large AI models like DeepSeek and Chatgpt as intelligent assistants. The editor provides high availability with multiple editing modes and custom themes. Available for Linux, macOS, and Windows, MarkFlowy aims to offer an efficient, beautiful, and data-safe Markdown editing experience for users.
narratrix
NarratrixAI is an AI-powered tabletop roleplaying platform that leverages AI to create dynamic, responsive, and immersive storytelling experiences. It allows users to create their own stories, use it as character chat, or as a full tabletop RPG experience. The platform features a powerful chat system, flexible AI integration, rich character management, powerful storytelling tools, and developer-friendly customization options. Narratrix supports various AI providers through a manifest system and is built with Tauri for native performance across Windows, macOS, and Linux platforms.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

rowboat
Rowboat is a tool that allows users to build AI agents instantly with natural language, connect tools with one-click integrations, power workflows with knowledge by adding documents for RAG, automate workflows by setting up triggers and actions, and deploy anywhere via API or SDK. Users can access a hosted version to start building agents right away. The tool provides features such as native RAG support, custom LLM providers, tools & triggers for automation, and API & SDK integration. Users can refer to the documentation to learn how to start building agents with Rowboat.
kilocode
Kilo Code is an open-source VS Code AI agent that allows users to generate code from natural language, check its own work, run terminal commands, automate the browser, and utilize the latest AI models. It offers features like task automation, automated refactoring, and integration with MCP servers. Users can access 400+ AI models and benefit from transparent pricing. Kilo Code is a fork of Roo Code and Cline, with improvements and unique features developed independently.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing features like local data storage, multiple LLM provider support, image generation, enhanced prompting, keyboard shortcuts, and more. It offers a user-friendly interface with dark theme, team collaboration, cross-platform availability, web version access, iOS & Android apps, multilingual support, and ongoing feature enhancements. Developed for prompt and API debugging, it has gained popularity for daily chatting and professional role-playing with AI assistance.
autonomous-intelligence
Tau is an autonomous robot project inspired by Pi.AI, designed for continual conversation with a single context. It features speech-based interaction, memory management, and integration with vision services. The project aims to create a local AI companion with personality, suitable for experimentation and development. Key components include long and immediate memory, speech-to-text and text-to-speech capabilities, and integration with Nvidia Jetson and Hailo vision services. Tau is open-source and encourages community contributions and experimentation.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
chatbox
Chatbox is a desktop client for ChatGPT, Claude, and other LLMs, providing a user-friendly interface for AI copilot assistance on Windows, Mac, and Linux. It offers features like local data storage, multiple LLM provider support, image generation with Dall-E-3, enhanced prompting, keyboard shortcuts, and more. Users can collaborate, access the tool on various platforms, and enjoy multilingual support. Chatbox is constantly evolving with new features to enhance the user experience.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.
kelivo
Kelivo is a Flutter LLM Chat Client with modern design, dark mode, multi-language support, multi-provider support, custom assistants, multimodal input, markdown rendering, voice functionality, MCP support, web search integration, prompt variables, QR code sharing, data backup, and custom requests. It is built with Flutter and Dart, utilizes Provider for state management, Hive for local data storage, and supports dynamic theming and Markdown rendering. Kelivo is a versatile tool for creating and managing personalized AI assistants, supporting various input formats, and integrating with multiple search engines and AI providers.
For similar tasks
AiEditor
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.
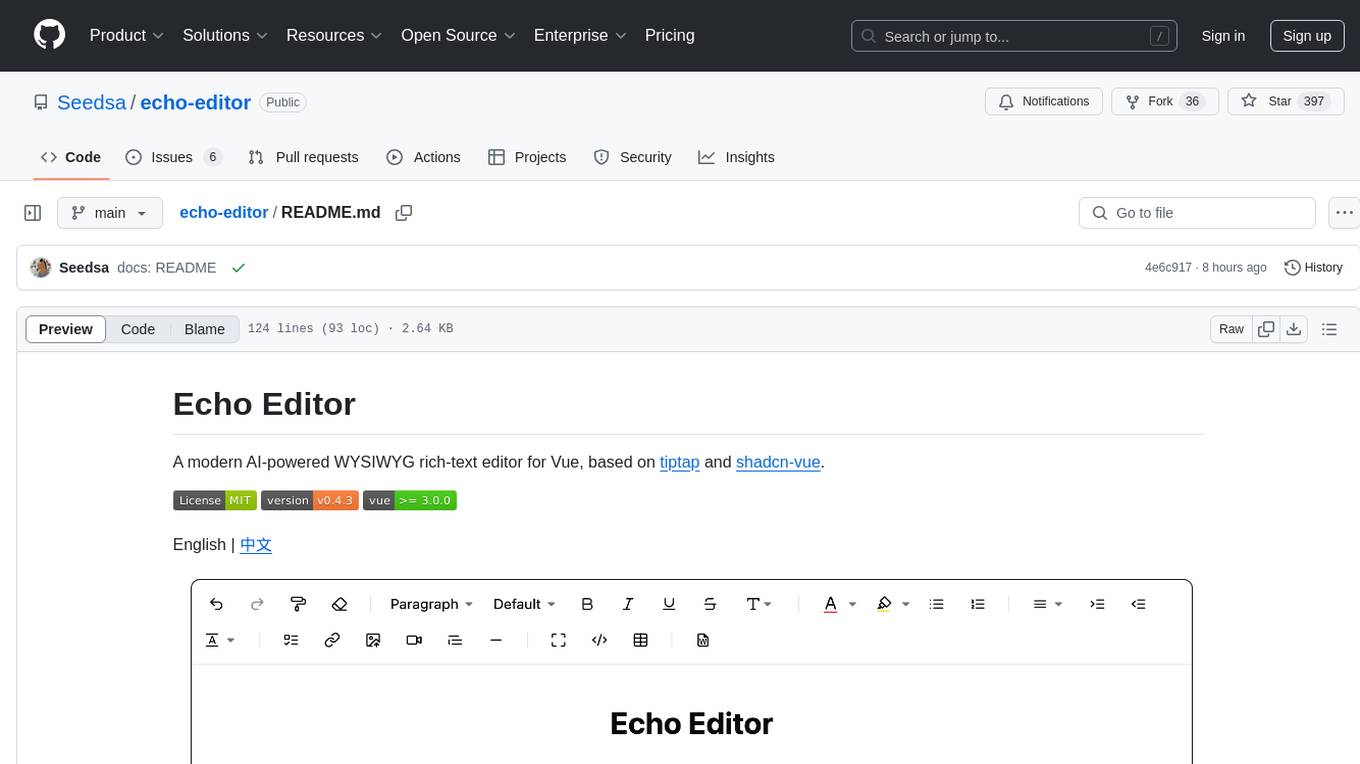
echo-editor
Echo Editor is a modern AI-powered WYSIWYG rich-text editor for Vue, featuring a beautiful UI with shadcn-vue components. It provides AI-powered writing assistance, Markdown support with real-time preview, rich text formatting, tables, code blocks, custom font sizes and styles, Word document import, I18n support, extensible architecture for creating extensions, TypeScript and Tailwind CSS support. The tool aims to enhance the writing experience by combining advanced features with user-friendly design.
mini.ai
This plugin extends and creates `a`/`i` textobjects in Neovim. It enhances some builtin textobjects (like `a(`, `a)`, `a'`, and more), creates new ones (like `a*`, `a
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.
blinko
Blinko is an innovative open-source project designed for individuals who want to quickly capture and organize their fleeting thoughts. It allows users to seamlessly jot down ideas the moment they strike, ensuring that no spark of creativity is lost. With advanced AI-powered note retrieval, data ownership, efficient and fast capturing, lightweight architecture, and open collaboration, Blinko offers a comprehensive solution for managing and accessing notes.
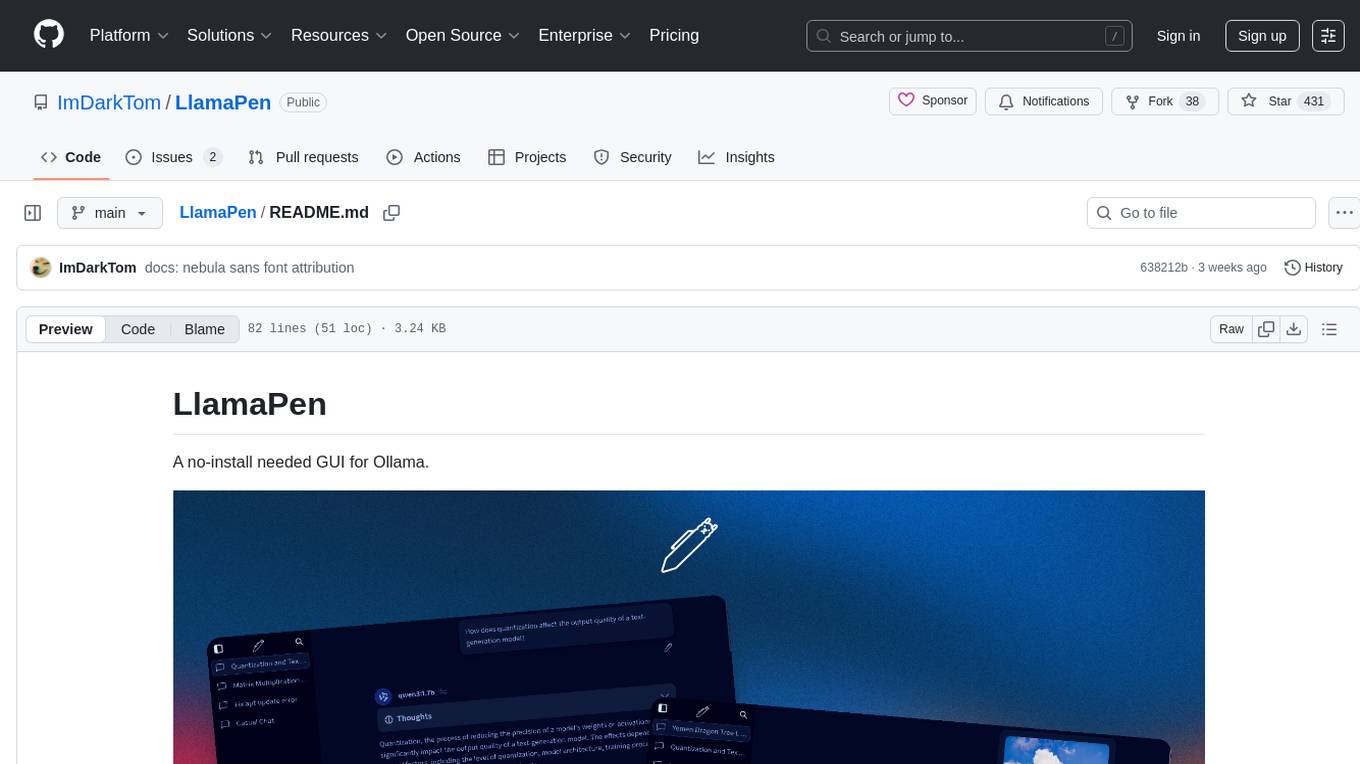
LlamaPen
LlamaPen is a no-install needed GUI tool for Ollama, featuring a web-based interface accessible on both desktop and mobile. It allows easy setup and configuration, renders markdown, text, and LaTeX math, provides keyboard shortcuts for quick navigation, includes a built-in model and download manager, supports offline and PWA, and is 100% free and open-source. Users can chat with complete privacy as all chats are stored locally in the browser, ensuring near-instant chat load times. The tool also offers an optional cloud service, LlamaPen API, for running up-to-date models if unable to run locally, with a subscription option for increased rate limits and access to more expensive models.
video2blog
video2blog is an open-source project aimed at converting videos into textual notes. The tool follows a process of extracting video information using yt-dlp, downloading the video, downloading subtitles if available, translating subtitles if not in Chinese, generating Chinese subtitles using whisper if no subtitles exist, converting subtitles to articles using gemini, and manually inserting images from the video into the article. The tool provides a solution for creating blog content from video resources, enhancing accessibility and content creation efficiency.

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.