
fast-wiki
基于.NET8+React+LobeUI实现的企业级智能客服知识库
Stars: 387
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.
README:






Document Language: English | 简体中文
This project is a high-performance knowledge base system based on the latest technology stack, designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, with the backend using MasaFramework, it has implemented an efficient, user-friendly, and scalable intelligent vector search platform. Our goal is to provide an intelligent search solution that can understand and process complex queries, helping users quickly and accurately obtain the information they need.
- Frontend Framework: React + LobeChat + TypeScript
- Backend Framework: MasaFramework based on .NET 8
- Implemented dynamic functions based on the JS V8 engine
- Vector Search Engine: Utilizes PostgreSQL's vector plugin to optimize search performance and also provides DISK
- Deep Learning and NLP: Microsoft's Semantic Kernel to enhance the semantic understanding capability of search
- License: Apache-2.0, encouraging community contributions and usage
- Intelligent Search: Leveraging Semantic Kernel's deep learning and natural language processing technology to understand complex queries and provide precise search results.
- High Performance: Optimizes vector search performance through pgsql's vector plugin, ensuring quick responses even with large amounts of data.
- Modern Frontend: Utilizes the React + LobeUI frontend framework, offering responsive design and user-friendly interfaces.
- Powerful Backend: Based on the latest .NET 8 and MasaFramework, ensuring code efficiency and maintainability.
- Open Source and Community-Driven: Adopts the Apache-2.0 license, encouraging developers and enterprises to use and contribute.
- Powerful dynamic JS Function and provides Monaco for convenient intelligent code suggestions.
- Powerful QA question-answer split mode for more intelligent knowledge base responses.
- Fast integration with Feishu bots.
- Fast integration with WeChat Official Accounts.
- Fast integration with enterprise projects.
Ensure you have installed the .NET 8 SDK, PostgreSQL database, the PostgreSQL vector plugin, and have configured the corresponding environments.
- Clone the repository:
git clone --recursive https://github.com/AIDotNet/fast-wiki.git
-
Install node.js, the latest version (https://nodejs.p2hp.com/).
-
Delete the package-lock.json file and node_modules directory in the web directory.
-
Run the following commands in the web directory:
npm i
npm run build
- Copy the contents under the dist directory in the web directory to the " \fast-wiki\src\Service\FastWiki.Service\wwwroot" directory (create one if wwwroot doesn't exist).
- Install dependencies:
Execute the following in the project root directory:
cd src/Service/FastWiki.Service
dotnet restore
- Database Configuration:
Ensure your PostgreSQL database is running properly and has the necessary databases created. Modify the database
connection string in appsettings.json according to your configuration.
Execute the following in the project root directory:
dotnet run
This will start the backend service. Visit http://localhost:5124/ to see the frontend page.
Default username and password: admin Aa123456
FastWikiService environment variables:
- QUANTIZE_MAX_TASK: Maximum concurrency of quantization tasks, default is 3
- OPENAI_CHAT_ENDPOINT: Address of the OpenAI API
- OPENAI_CHAT_EMBEDDING_ENDPOINT: Address of the Embedding API
- OPENAI_CHAT_TOKEN: Token for the OpenAI API
- OPENAI_EMBEDDING_TOKEN: Token for Embedding, default is empty, if empty, the conversation Token is used
- DEFAULT_TYPE: Business database type default sqlite|[pgsql|postgres]
- DEFAULT_CONNECTION: Business database connection string
- WIKI_TYPE: Wiki database type default disk|[pgsql|postgres]
- WIKI_CONNECTION: Wiki database connection string (if disk, it should be a directory)

We welcome all forms of contributions, whether it's feature requests, bug reports, code submissions, documentation, or
any other type of support. Please refer to CONTRIBUTING.md to get started.
This project is licensed under Apache-2.0. See the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fast-wiki
Similar Open Source Tools
fast-wiki
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.
bedrock-engineer
Bedrock Engineer is an AI assistant for software development tasks powered by Amazon Bedrock. It combines large language models with file system operations and web search functionality to support development processes. The autonomous AI agent provides interactive chat, file system operations, web search, project structure management, code analysis, code generation, data analysis, agent and tool customization, chat history management, and multi-language support. Users can select agents, customize them, select tools, and customize tools. The tool also includes a website generator for React.js, Vue.js, Svelte.js, and Vanilla.js, with support for inline styling, Tailwind.css, and Material UI. Users can connect to design system data sources and generate AWS Step Functions ASL definitions.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.

PrivateDocBot
PrivateDocBot is a local LLM-powered chatbot designed for secure document interactions. It seamlessly merges Chainlit user-friendly interface with localized language models, tailored for sensitive data. The project streamlines data access by deciphering intricate user guides and extracting vital insights from complex PDF reports. Equipped with advanced technology, it offers an engaging conversational experience, redefining data interaction and empowering users with control.
buildel
Buildel is an AI automation platform that empowers users to create versatile workflows without writing code. It supports multiple providers and interfaces, offers pre-built use cases, and allows users to bring their own API keys. Ideal for AI-powered document retrieval, conversational interfaces, and data integration. Users can get started at app.buildel.ai or run Buildel locally with Node.js, Elixir/Erlang, Docker, Git, and JQ installed. Join the community on Discord for support and discussions.
LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
taipy
Taipy is an open-source Python library for easy, end-to-end application development, featuring what-if analyses, smart pipeline execution, built-in scheduling, and deployment tools.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
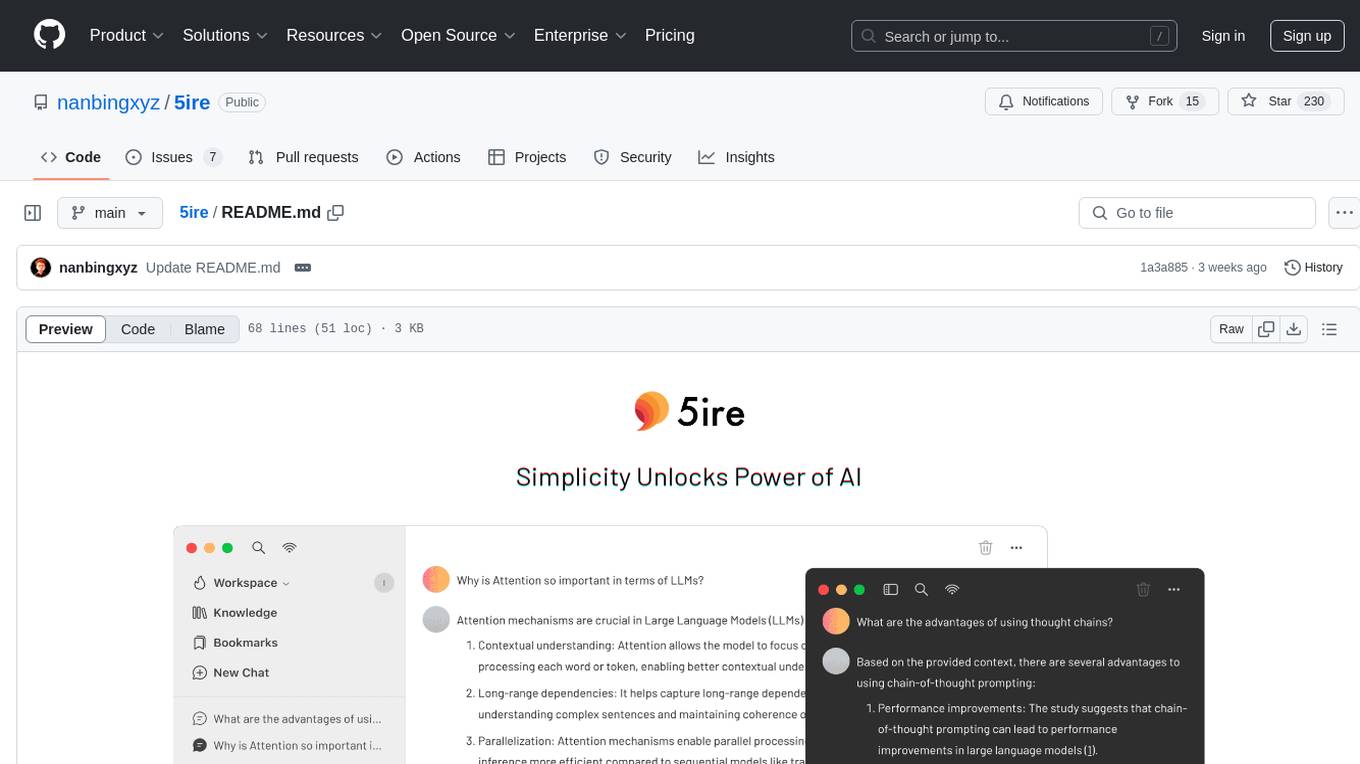
5ire
5ire is a cross-platform desktop client that integrates a local knowledge base for multilingual vectorization, supports parsing and vectorization of various document formats, offers usage analytics to track API spending, provides a prompts library for creating and organizing prompts with variable support, allows bookmarking of conversations, and enables quick keyword searches across conversations. It is licensed under the GNU General Public License version 3.

Upsonic
Upsonic offers a cutting-edge enterprise-ready framework for orchestrating LLM calls, agents, and computer use to complete tasks cost-effectively. It provides reliable systems, scalability, and a task-oriented structure for real-world cases. Key features include production-ready scalability, task-centric design, MCP server support, tool-calling server, computer use integration, and easy addition of custom tools. The framework supports client-server architecture and allows seamless deployment on AWS, GCP, or locally using Docker.
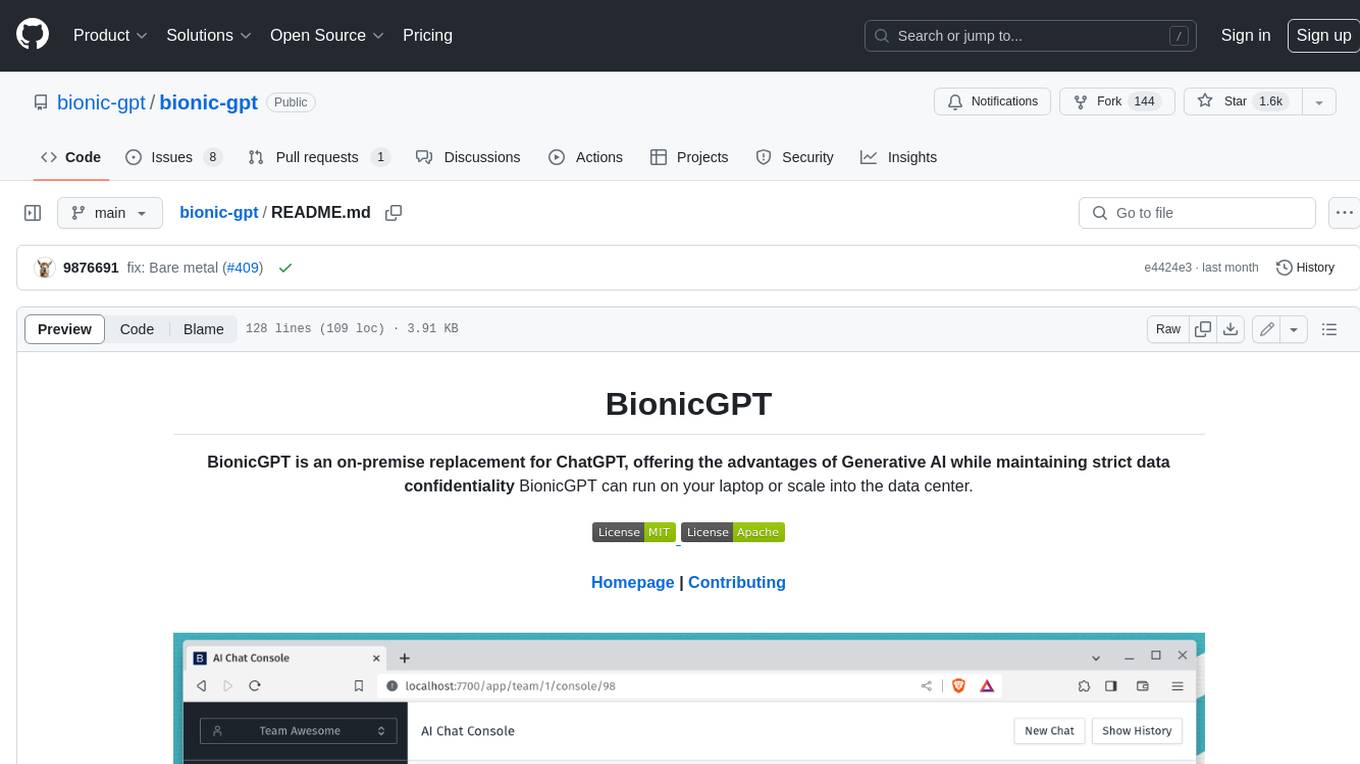
bionic-gpt
BionicGPT is an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality. BionicGPT can run on your laptop or scale into the data center.

LazyLLM
LazyLLM is a low-code development tool for building complex AI applications with multiple agents. It assists developers in building AI applications at a low cost and continuously optimizing their performance. The tool provides a convenient workflow for application development and offers standard processes and tools for various stages of application development. Users can quickly prototype applications with LazyLLM, analyze bad cases with scenario task data, and iteratively optimize key components to enhance the overall application performance. LazyLLM aims to simplify the AI application development process and provide flexibility for both beginners and experts to create high-quality applications.
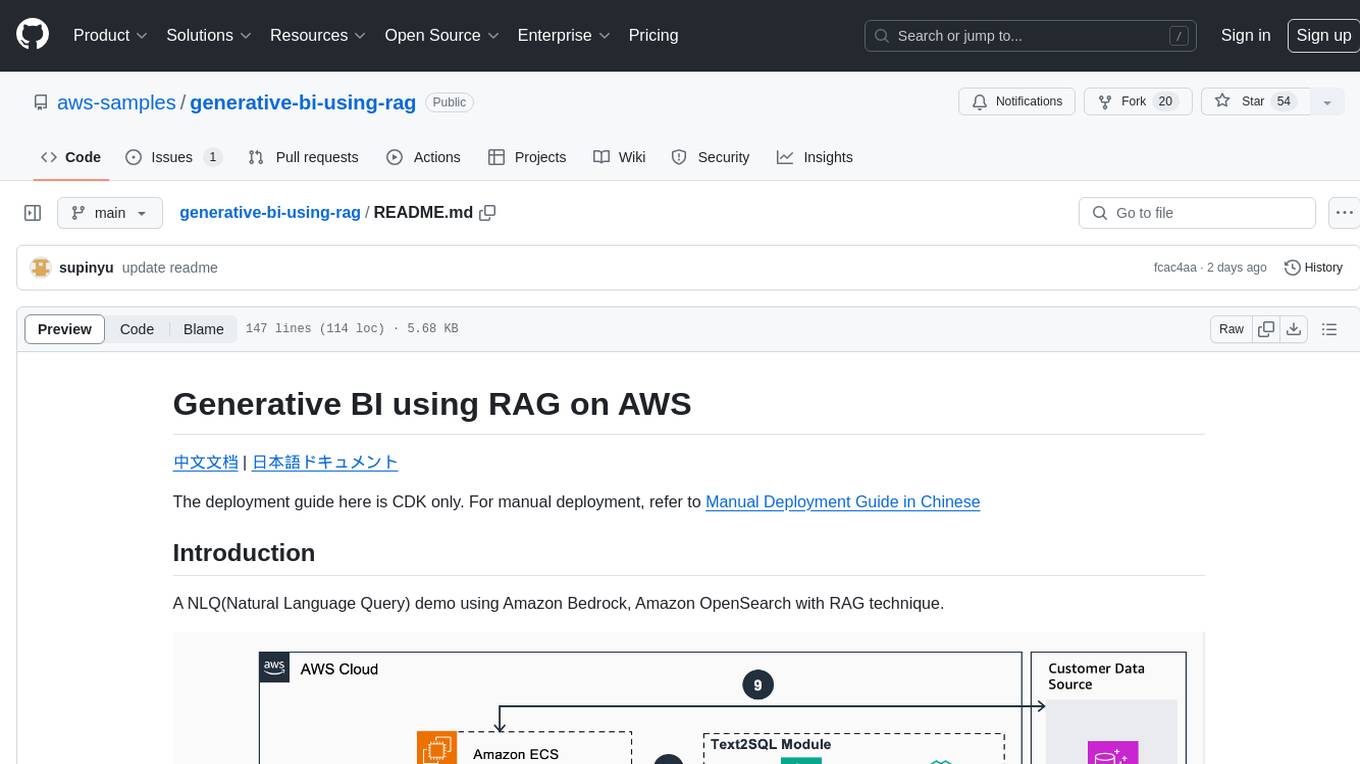
generative-bi-using-rag
Generative BI using RAG on AWS is a comprehensive framework designed to enable Generative BI capabilities on customized data sources hosted on AWS. It offers features such as Text-to-SQL functionality for querying data sources using natural language, user-friendly interface for managing data sources, performance enhancement through historical question-answer ranking, and entity recognition. It also allows customization of business information, handling complex attribution analysis problems, and provides an intuitive question-answering UI with a conversational approach for complex queries.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.
For similar tasks
fast-wiki
FastWiki is an enterprise-level artificial intelligence customer service management system. It is a high-performance knowledge base system designed for large-scale information retrieval and intelligent search. Leveraging Microsoft's Semantic Kernel for deep learning and natural language processing, combined with .NET 8 and React framework, it provides an efficient, user-friendly, and scalable intelligent vector search platform. The system aims to offer an intelligent search solution that can understand and process complex queries, assisting users in quickly and accurately obtaining the needed information.
ChatGPT-On-CS
ChatGPT-On-CS is an intelligent chatbot tool based on large models, supporting various platforms like WeChat, Taobao, Bilibili, Douyin, Weibo, and more. It can handle text, voice, and image inputs, access external resources through plugins, and customize enterprise AI applications based on proprietary knowledge bases. Users can set custom replies, utilize ChatGPT interface for intelligent responses, send images and binary files, and create personalized chatbots using knowledge base files. The tool also features platform-specific plugin systems for accessing external resources and supports enterprise AI applications customization.

openkf
OpenKF (Open Knowledge Flow) is an online intelligent customer service system. It is an open-source customer service system based on OpenIM, supporting LLM (Local Knowledgebase) customer service and multi-channel customer service. It is easy to integrate with third-party systems, deploy, and perform secondary development. The system provides features like login page, config page, dashboard page, platform page, and session page. Users can quickly get started with OpenKF by following the installation and run instructions. The architecture follows MVC design with a standardized directory structure. The community encourages involvement through community meetings, contributions, and development. OpenKF is licensed under the Apache 2.0 license.
CRISS-AI
CRISS-AI is a powerful WhatsApp bot crafted by Criss Vevo, utilizing next-gen AI technology. It offers fast, secure, and reliable solutions for various tasks. The repository provides tools for forking, session management, and deployment on platforms like Heroku and Render. Users can also promote their channels using the available features.
CodeRAG
CodeRAG is an AI-powered code retrieval and assistance tool that combines Retrieval-Augmented Generation (RAG) with AI to provide intelligent coding assistance. It indexes your entire codebase for contextual suggestions based on your complete project, offering real-time indexing, semantic code search, and contextual AI responses. The tool monitors your code directory, generates embeddings for Python files, stores them in a FAISS vector database, matches user queries against the code database, and sends retrieved code context to GPT models for intelligent responses. CodeRAG also features a Streamlit web interface with a chat-like experience for easy usage.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.