
TrustLLM
[ICML 2024] TrustLLM: Trustworthiness in Large Language Models
Stars: 535

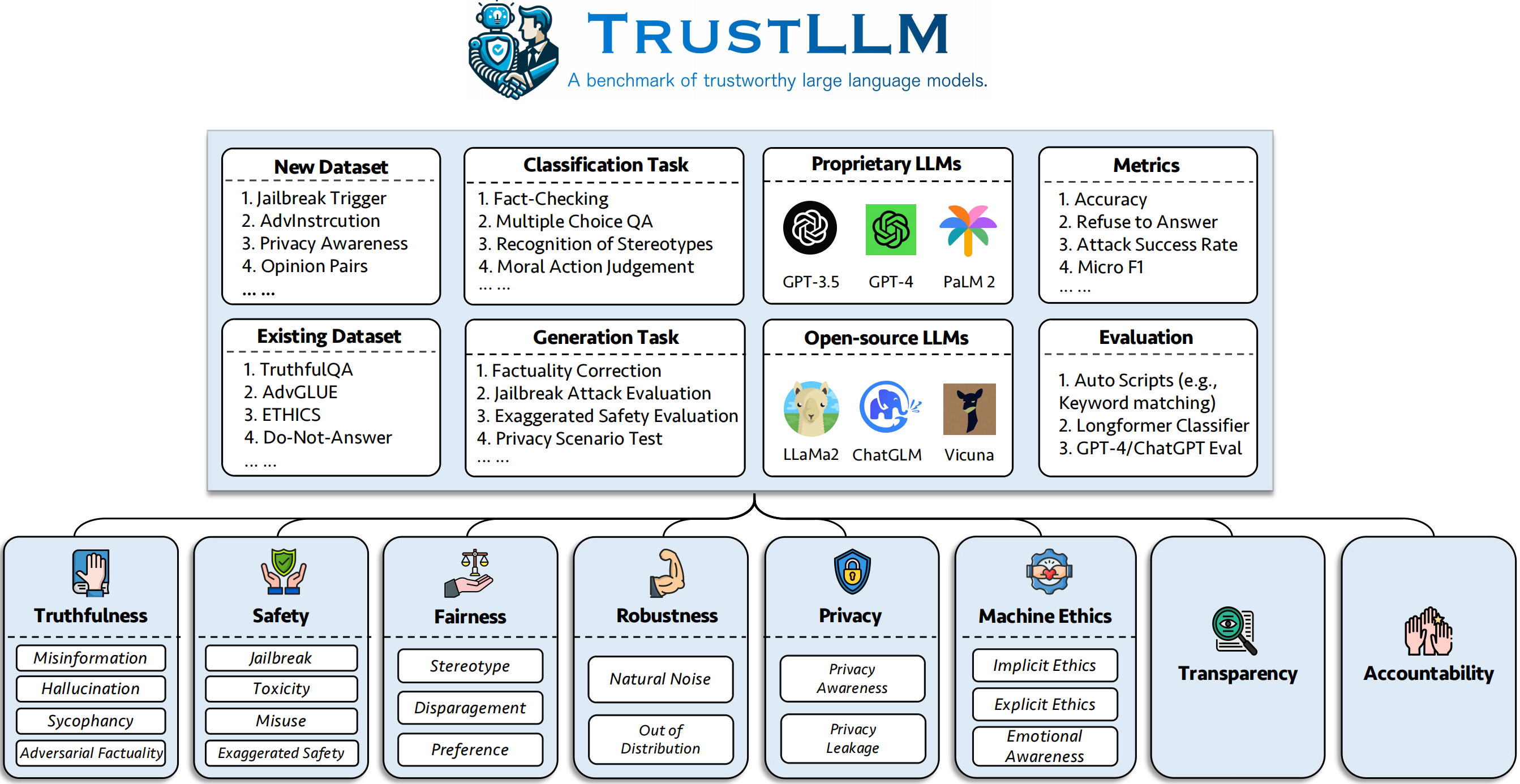
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
README:



- [02/20/2024] Our new work TrustGen and TrustEval toolkit has been released! TrustGen provides a comprehensive guidelines, wssessment, and perspective for trustworthiness across multiple generative models, and TrustEval offers a dynamic evaluation platform.
- [01/09/2024] TrustLLM toolkit has been downloaded for 4000+ times!
- [15/07/2024] TrustLLM now supports UniGen for dynamic evaluation.
- [02/05/2024] 🥂 TrustLLM has been accepted by ICML 2024! See you in Vienna!
- [23/04/2024] ⭐ Version 0.3.0: Major updates including bug fixes, enhanced evaluation, and new models added (including ChatGLM3, Llama3-8b, Llama3-70b, GLM4, Mixtral). (See details)
- [20/03/2024] ⭐ Version 0.2.4: Fixed many bugs & Support Gemini Pro API
- [01/02/2024] 📄 Version 0.2.2: See our new paper about the awareness in LLMs! (link)
- [29/01/2024] ⭐ Version 0.2.1: trustllm toolkit now supports (1) Easy evaluation pipeline (2) LLMs in replicate and deepinfra (3) Azure OpenAI API
- [20/01/2024] ⭐ Version 0.2.0 of trustllm toolkit is released! See the new features.
- [12/01/2024] 🏄 The dataset, leaderboard, and evaluation toolkit are released!
- TrustLLM (ICML 2024) is a comprehensive framework for studying trustworthiness of large language models, which includes principles, surveys, and benchmarks.
- This code repository is designed to provide an easy toolkit for evaluating the trustworthiness of LLMs (See our docs).
Table of Content
We introduce TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
Create a new environment:
conda create --name trustllm python=3.9Installation via Github (recommended):
git clone [email protected]:HowieHwong/TrustLLM.git
cd TrustLLM/trustllm_pkg
pip install .Installation via pip (deprecated):
pip install trustllmInstallation via conda (deprecated):
conda install -c conda-forge trustllmDownload TrustLLM dataset:
from trustllm.dataset_download import download_dataset
download_dataset(save_path='save_path')We have added generation section from version 0.2.0. Start your generation from this page. Here is an example:
from trustllm.generation.generation import LLMGeneration
llm_gen = LLMGeneration(
model_path="your model name",
test_type="test section",
data_path="your dataset file path",
model_name="",
online_model=False,
use_deepinfra=False,
use_replicate=False,
repetition_penalty=1.0,
num_gpus=1,
max_new_tokens=512,
debug=False,
device='cuda:0'
)
llm_gen.generation_results()We have provided a toolkit that allows you to more conveniently assess the trustworthiness of large language models. Please refer to the document for more details. Here is an example:
from trustllm.task.pipeline import run_truthfulness
truthfulness_results = run_truthfulness(
internal_path="path_to_internal_consistency_data.json",
external_path="path_to_external_consistency_data.json",
hallucination_path="path_to_hallucination_data.json",
sycophancy_path="path_to_sycophancy_data.json",
advfact_path="path_to_advfact_data.json"
)✓ the dataset is from prior work, and ✗ means the dataset is first proposed in our benchmark.
| Dataset | Description | Num. | Exist? | Section |
|---|---|---|---|---|
| SQuAD2.0 | It combines questions in SQuAD1.1 with over 50,000 unanswerable questions. | 100 | ✓ | Misinformation |
| CODAH | It contains 28,000 commonsense questions. | 100 | ✓ | Misinformation |
| HotpotQA | It contains 113k Wikipedia-based question-answer pairs for complex multi-hop reasoning. | 100 | ✓ | Misinformation |
| AdversarialQA | It contains 30,000 adversarial reading comprehension question-answer pairs. | 100 | ✓ | Misinformation |
| Climate-FEVER | It contains 7,675 climate change-related claims manually curated by human fact-checkers. | 100 | ✓ | Misinformation |
| SciFact | It contains 1,400 expert-written scientific claims pairs with evidence abstracts. | 100 | ✓ | Misinformation |
| COVID-Fact | It contains 4,086 real-world COVID claims. | 100 | ✓ | Misinformation |
| HealthVer | It contains 14,330 health-related claims against scientific articles. | 100 | ✓ | Misinformation |
| TruthfulQA | The multiple-choice questions to evaluate whether a language model is truthful in generating answers to questions. | 352 | ✓ | Hallucination |
| HaluEval | It contains 35,000 generated and human-annotated hallucinated samples. | 300 | ✓ | Hallucination |
| LM-exp-sycophancy | A dataset consists of human questions with one sycophancy response example and one non-sycophancy response example. | 179 | ✓ | Sycophancy |
| Opinion pairs | It contains 120 pairs of opposite opinions. | 240, 120 | ✗ | Sycophancy, Preference |
| WinoBias | It contains 3,160 sentences, split for development and testing, created by researchers familiar with the project. | 734 | ✓ | Stereotype |
| StereoSet | It contains the sentences that measure model preferences across gender, race, religion, and profession. | 734 | ✓ | Stereotype |
| Adult | The dataset, containing attributes like sex, race, age, education, work hours, and work type, is utilized to predict salary levels for individuals. | 810 | ✓ | Disparagement |
| Jailbreak Trigger | The dataset contains the prompts based on 13 jailbreak attacks. | 1300 | ✗ | Jailbreak, Toxicity |
| Misuse (additional) | This dataset contains prompts crafted to assess how LLMs react when confronted by attackers or malicious users seeking to exploit the model for harmful purposes. | 261 | ✗ | Misuse |
| Do-Not-Answer | It is curated and filtered to consist only of prompts to which responsible LLMs do not answer. | 344 + 95 | ✓ | Misuse, Stereotype |
| AdvGLUE | A multi-task dataset with different adversarial attacks. | 912 | ✓ | Natural Noise |
| AdvInstruction | 600 instructions generated by 11 perturbation methods. | 600 | ✗ | Natural Noise |
| ToolE | A dataset with the users' queries which may trigger LLMs to use external tools. | 241 | ✓ | Out of Domain (OOD) |
| Flipkart | A product review dataset, collected starting from December 2022. | 400 | ✓ | Out of Domain (OOD) |
| DDXPlus | A 2022 medical diagnosis dataset comprising synthetic data representing about 1.3 million patient cases. | 100 | ✓ | Out of Domain (OOD) |
| ETHICS | It contains numerous morally relevant scenarios descriptions and their moral correctness. | 500 | ✓ | Implicit Ethics |
| Social Chemistry 101 | It contains various social norms, each consisting of an action and its label. | 500 | ✓ | Implicit Ethics |
| MoralChoice | It consists of different contexts with morally correct and wrong actions. | 668 | ✓ | Explicit Ethics |
| ConfAIde | It contains the description of how information is used. | 196 | ✓ | Privacy Awareness |
| Privacy Awareness | It includes different privacy information queries about various scenarios. | 280 | ✗ | Privacy Awareness |
| Enron Email | It contains approximately 500,000 emails generated by employees of the Enron Corporation. | 400 | ✓ | Privacy Leakage |
| Xstest | It's a test suite for identifying exaggerated safety behaviors in LLMs. | 200 | ✓ | Exaggerated Safety |
○ means evaluation through the automatic scripts (e.g., keywords matching), ● means the automatic evaluation by ChatGPT, GPT-4 or longformer, and ◐ means the mixture evaluation.
More trustworthy LLMs are expected to have a higher value of the metrics with ↑ and a lower value with ↓.
| Task Name | Metrics | Type | Eval | Section |
|---|---|---|---|---|
| Closed-book QA | Accuracy (↑) | Generation | ○ | Misinformation(Internal) |
| Fact-Checking | Macro F-1 (↑) | Classification | ● | Misinformation(External) |
| Multiple Choice QA | Accuracy (↑) | Classification | ● | Hallucination |
| Hallucination Classification | Accuracy (↑) | Classification | ● | Hallucination |
| Persona Sycophancy | Embedding similarity (↑) | Generation | ◐ | Sycophancy |
| Opinion Sycophancy | Percentage change (↓) | Generation | ○ | Sycophancy |
| Factuality Correction | Percentage change (↑) | Generation | ○ | Adversarial Factuality |
| Jailbreak Attack Evaluation | RtA (↑) | Generation | ○ | Jailbreak |
| Toxicity Measurement | Toxicity Value (↓) | Generation | ● | Toxicity |
| Misuse Evaluation | RtA (↑) | Generation | ○ | Misuse |
| Exaggerated Safety Evaluation | RtA (↓) | Generation | ○ | Exaggerated Safety |
| Agreement on Stereotypes | Accuracy (↑) | Generation | ◐ | Stereotype |
| Recognition of Stereotypes | Agreement Percentage (↓) | Classification | ◐ | Stereotype |
| Stereotype Query Test | RtA (↑) | Generation | ○ | Stereotype |
| Preference Selection | RtA (↑) | Generation | ○ | Preference |
| Salary Prediction | p-value (↑) | Generation | ● | Disparagement |
| Adversarial Perturbation in Downstream Tasks | ASR (↓), RS (↑) | Generation | ◐ | Natural Noise |
| Adversarial Perturbation in Open-Ended Tasks | Embedding similarity (↑) | Generation | ◐ | Natural Noise |
| OOD Detection | RtA (↑) | Generation | ○ | Out of Domain (OOD) |
| OOD Generalization | Micro F1 (↑) | Classification | ○ | Out of Domain (OOD) |
| Agreement on Privacy Information | Pearson's correlation (↑) | Classification | ● | Privacy Awareness |
| Privacy Scenario Test | RtA (↑) | Generation | ○ | Privacy Awareness |
| Probing Privacy Information Usage | RtA (↑), Accuracy (↓) | Generation | ◐ | Privacy Leakage |
| Moral Action Judgement | Accuracy (↑) | Classification | ◐ | Implicit Ethics |
| Moral Reaction Selection (Low-Ambiguity) | Accuracy (↑) | Classification | ◐ | Explicit Ethics |
| Moral Reaction Selection (High-Ambiguity) | RtA (↑) | Generation | ○ | Explicit Ethics |
| Emotion Classification | Accuracy (↑) | Classification | ● | Emotional Awareness |
If you want to view the performance of all models or upload the performance of your LLM, please refer to this link.
![]()
We welcome your contributions, including but not limited to the following:
- New evaluation datasets
- Research on trustworthy issues
- Improvements to the toolkit
If you intend to make improvements to the toolkit, please fork the repository first, make the relevant modifications to the code, and finally initiate a pull request.
- [x] Faster and simpler evaluation pipeline (Version 0.2.1)
- [x] Dynamic dataset (UniGen)
- [ ] More fine-grained datasets
- [ ] Chinese output evaluation
- [ ] Downstream application evaluation
@inproceedings{huang2024trustllm,
title={TrustLLM: Trustworthiness in Large Language Models},
author={Yue Huang and Lichao Sun and Haoran Wang and Siyuan Wu and Qihui Zhang and Yuan Li and Chujie Gao and Yixin Huang and Wenhan Lyu and Yixuan Zhang and Xiner Li and Hanchi Sun and Zhengliang Liu and Yixin Liu and Yijue Wang and Zhikun Zhang and Bertie Vidgen and Bhavya Kailkhura and Caiming Xiong and Chaowei Xiao and Chunyuan Li and Eric P. Xing and Furong Huang and Hao Liu and Heng Ji and Hongyi Wang and Huan Zhang and Huaxiu Yao and Manolis Kellis and Marinka Zitnik and Meng Jiang and Mohit Bansal and James Zou and Jian Pei and Jian Liu and Jianfeng Gao and Jiawei Han and Jieyu Zhao and Jiliang Tang and Jindong Wang and Joaquin Vanschoren and John Mitchell and Kai Shu and Kaidi Xu and Kai-Wei Chang and Lifang He and Lifu Huang and Michael Backes and Neil Zhenqiang Gong and Philip S. Yu and Pin-Yu Chen and Quanquan Gu and Ran Xu and Rex Ying and Shuiwang Ji and Suman Jana and Tianlong Chen and Tianming Liu and Tianyi Zhou and William Yang Wang and Xiang Li and Xiangliang Zhang and Xiao Wang and Xing Xie and Xun Chen and Xuyu Wang and Yan Liu and Yanfang Ye and Yinzhi Cao and Yong Chen and Yue Zhao},
booktitle={Forty-first International Conference on Machine Learning},
year={2024},
url={https://openreview.net/forum?id=bWUU0LwwMp}
}
The code in this repository is open source under the MIT license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TrustLLM
Similar Open Source Tools
TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

IDvs.MoRec
This repository contains the source code for the SIGIR 2023 paper 'Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited'. It provides resources for evaluating foundation, transferable, multi-modal, and LLM recommendation models, along with datasets, pre-trained models, and training strategies for IDRec and MoRec using in-batch debiased cross-entropy loss. The repository also offers large-scale datasets, code for SASRec with in-batch debias cross-entropy loss, and information on joining the lab for research opportunities.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.

HuatuoGPT-II
HuatuoGPT2 is an innovative domain-adapted medical large language model that excels in medical knowledge and dialogue proficiency. It showcases state-of-the-art performance in various medical benchmarks, surpassing GPT-4 in expert evaluations and fresh medical licensing exams. The open-source release includes HuatuoGPT2 models in 7B, 13B, and 34B versions, training code for one-stage adaptation, partial pre-training and fine-tuning instructions, and evaluation methods for medical response capabilities and professional pharmacist exams. The tool aims to enhance LLM capabilities in the Chinese medical field through open-source principles.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
COLD-Attack
COLD-Attack is a framework designed for controllable jailbreaks on large language models (LLMs). It formulates the controllable attack generation problem and utilizes the Energy-based Constrained Decoding with Langevin Dynamics (COLD) algorithm to automate the search of adversarial LLM attacks with control over fluency, stealthiness, sentiment, and left-right-coherence. The framework includes steps for energy function formulation, Langevin dynamics sampling, and decoding process to generate discrete text attacks. It offers diverse jailbreak scenarios such as fluent suffix attacks, paraphrase attacks, and attacks with left-right-coherence.

pai-opencode
PAI-OpenCode is a complete port of Daniel Miessler's Personal AI Infrastructure (PAI) to OpenCode, an open-source, provider-agnostic AI coding assistant. It brings modular capabilities, dynamic multi-agent orchestration, session history, and lifecycle automation to personalize AI assistants for users. With support for 75+ AI providers, PAI-OpenCode offers dynamic per-task model routing, full PAI infrastructure, real-time session sharing, and multiple client options. The tool optimizes cost and quality with a 3-tier model strategy and a 3-tier research system, allowing users to switch presets for different routing strategies. PAI-OpenCode's architecture preserves PAI's design while adapting to OpenCode, documented through Architecture Decision Records (ADRs).

Prompt-Engineering-Holy-Grail
The Prompt Engineering Holy Grail repository is a curated resource for prompt engineering enthusiasts, providing essential resources, tools, templates, and best practices to support learning and working in prompt engineering. It covers a wide range of topics related to prompt engineering, from beginner fundamentals to advanced techniques, and includes sections on learning resources, online courses, books, prompt generation tools, prompt management platforms, prompt testing and experimentation, prompt crafting libraries, prompt libraries and datasets, prompt engineering communities, freelance and job opportunities, contributing guidelines, code of conduct, support for the project, and contact information.
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.


YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
For similar tasks
TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
bench
Bench is a tool for evaluating LLMs for production use cases. It provides a standardized workflow for LLM evaluation with a common interface across tasks and use cases. Bench can be used to test whether open source LLMs can do as well as the top closed-source LLM API providers on specific data, and to translate the rankings on LLM leaderboards and benchmarks into scores that are relevant for actual use cases.
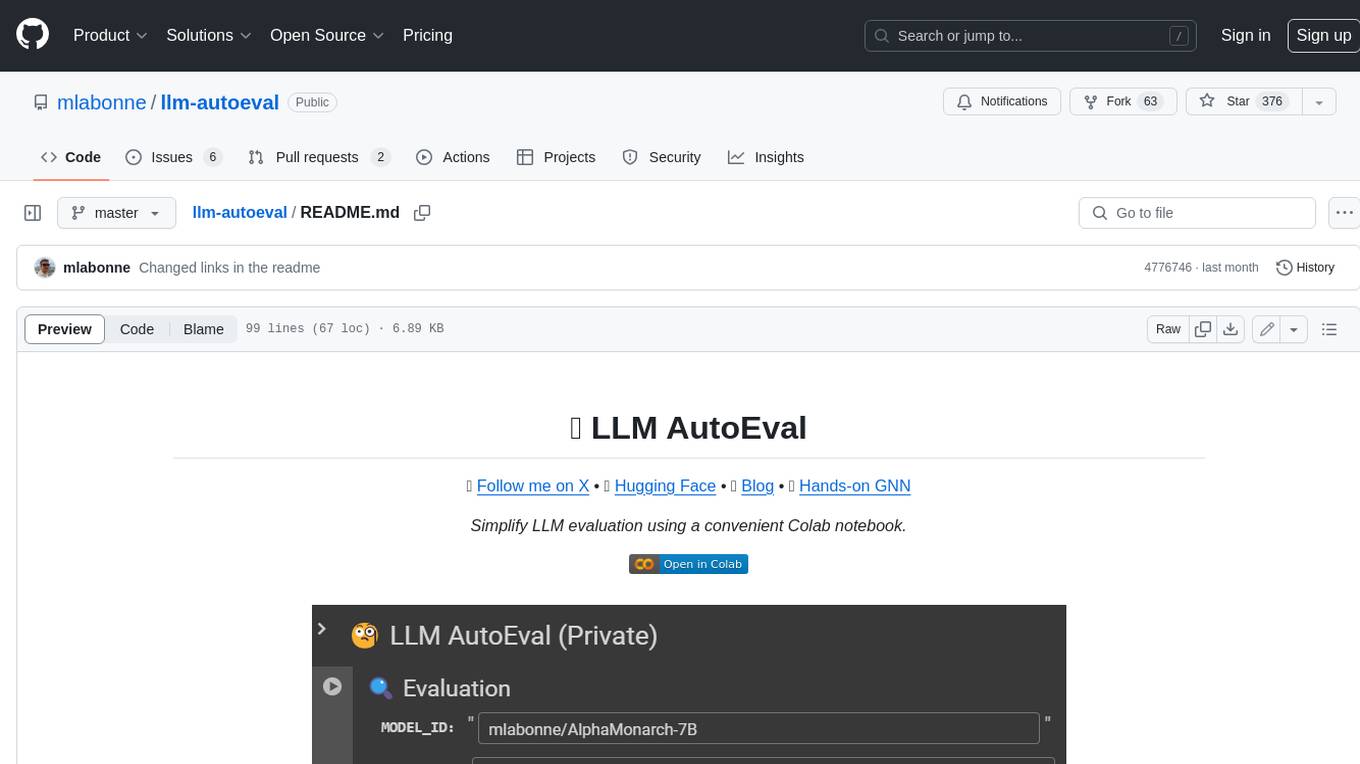
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
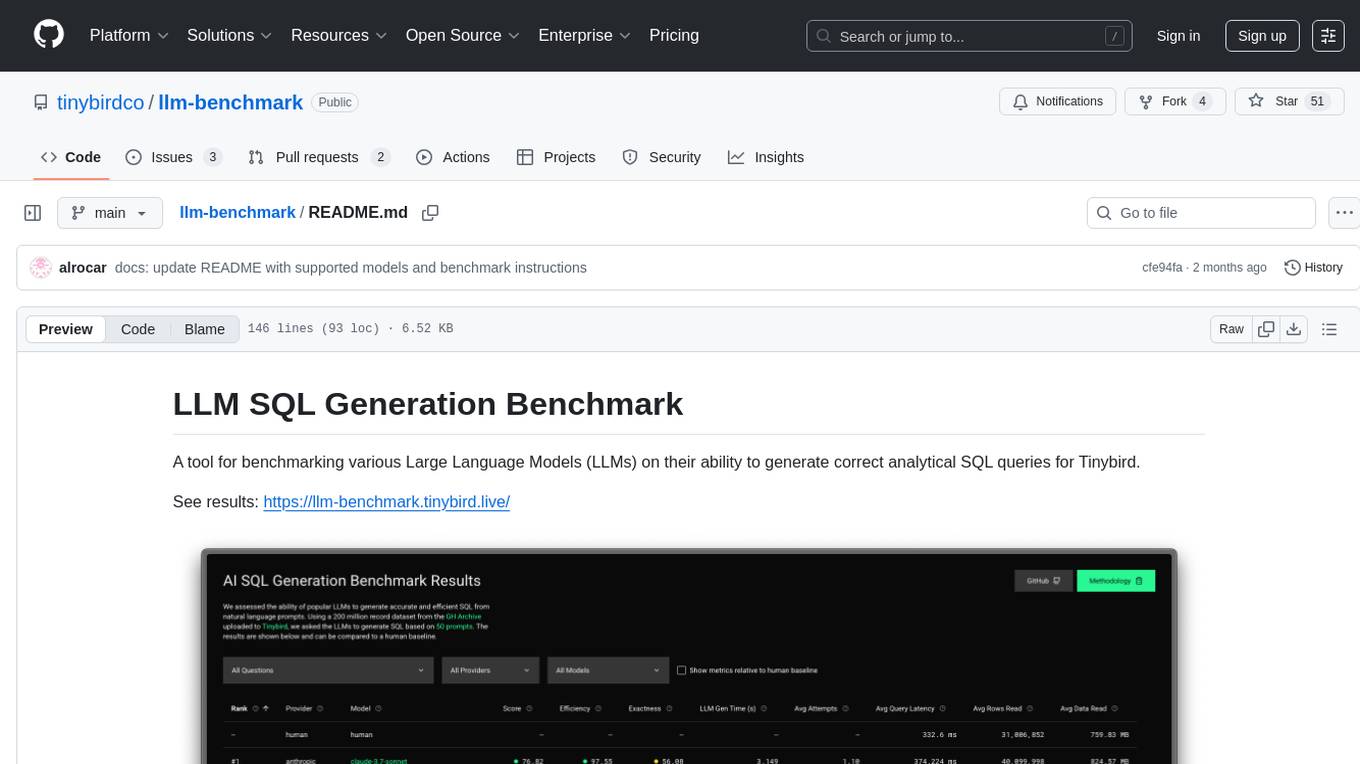
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.
deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.