Best AI tools for< Develop Llms >
20 - AI tool Sites
AI Builders Summit
AI Builders Summit is a 4-week virtual training event designed to equip data scientists, ML and AI engineers, and innovators with the latest advancements in large language models (LLMs), AI agents, and Retrieval-Augmented Generation (RAG). The summit emphasizes hands-on learning and real-world applications, with interactive workshops, platform credits, and direct exposure to industry-leading tools. Attendees can learn progressively over four weeks, building practical skills through expert-led sessions, cutting-edge tools, and industry insights.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.
YourGPT
YourGPT is a suite of next-generation AI products designed to empower businesses with the potential of Large Language Models (LLMs). Its products include a no-code AI Chatbot solution for customer support and LLM Spark, a developer platform for building and deploying production-ready LLM applications. YourGPT prioritizes data security and is GDPR compliant, ensuring the privacy and protection of customer data. With over 2,000 satisfied customers, YourGPT has earned trust through its commitment to quality and customer satisfaction.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.

Dify.AI
Dify.AI is a generative AI application development platform that allows users to create AI agents, chatbots, and other AI-powered applications. It provides a variety of tools and services to help developers build, deploy, and manage their AI applications. Dify.AI is designed to be easy to use, even for those with no prior experience in AI development.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
Placeholder Website
The website is a simple and straightforward platform that seems to lack content or functionality. It appears to be a placeholder or under construction. There is no specific information available on the site, and it seems to be in a basic state of development.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.
Focus Group Simulator
Focus Group Simulator is an AI tool designed to generate market insights instantly by simulating focus groups. By combining the power of LLMs to personate target segments with marketing quants analysis and best marketing frameworks, the tool provides valuable insights for businesses, especially startups. It helps identify low-hanging-fruit segments and offers guidance on product development, pricing, and promotion strategies to create more value and avoid waste. Users can customize simulations and engage with the team for further enhancements.
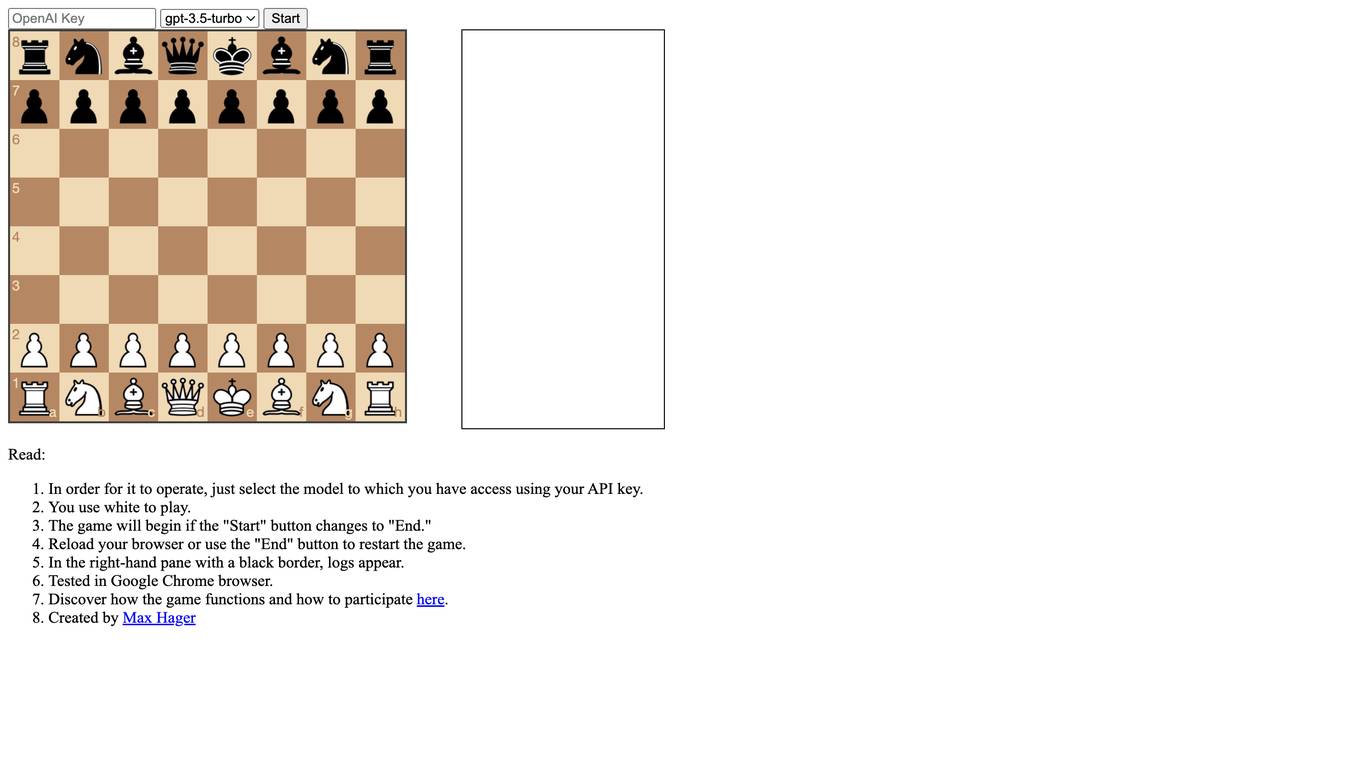
LLMChess
LLMChess is a web-based chess game that utilizes large language models (LLMs) to power the gameplay. Players can select the LLM model they wish to play against, and the game will commence once the "Start" button is clicked. The game logs are displayed in a black-bordered pane on the right-hand side of the screen. LLMChess is compatible with the Google Chrome browser. For more information on the game's functionality and participation guidelines, please refer to the provided link.
Elastic
Elastic is a Search AI Company that offers a platform for building tailored experiences, search and analytics, data ingestion, visualization, and generative AI solutions. The company provides services like Elastic Cloud for real-time insights, Elastic AI Assistant for retrieval and generation, and Search AI Lake for faster integration with LLMs. Elastic aims to help businesses scale with low-latency search AI and accelerate problem resolution with observability powered by advanced ML and analytics.
Digital Sense
Digital Sense is an AI tool that offers a wide range of AI, Machine Learning, and Computer Vision services. The company specializes in custom AI development, AI consulting services, biometrics solutions, NLP & LLMs development services, data science consulting services, remote sensing services, machine learning development services, generative AI development services, and computer vision development services. With over a decade of experience, Digital Sense helps businesses leverage cutting-edge AI technologies to solve complex technological challenges.
Weam
Weam is an AI adoption platform designed for digital agencies to supercharge their operations with collaborative AI. It offers a comprehensive suite of tools for simplifying AI implementation, including project management, resource allocation, training modules, and ongoing support to ensure successful AI integration. Weam enables teams to interact and collaborate over their preferred LLMs, facilitating scalability, time-saving, and widespread AI adoption across the organization.
Prompt Engineering
Prompt Engineering is a discipline focused on developing and optimizing prompts to efficiently utilize language models (LMs) for various applications and research topics. It involves skills to understand the capabilities and limitations of large language models, improving their performance on tasks like question answering and arithmetic reasoning. Prompt engineering is essential for designing robust prompting techniques that interact with LLMs and other tools, enhancing safety and building new capabilities by augmenting LLMs with domain knowledge and external tools.
Retell AI
Retell AI provides a Conversational Voice API that enables developers to integrate human-like voice interactions into their applications. With Retell AI's API, developers can easily connect their own Large Language Models (LLMs) to create AI-powered voice agents that can engage in natural and engaging conversations. Retell AI's API offers a range of features, including ultra-low latency, realistic voices with emotions, interruption handling, and end-of-turn detection, ensuring seamless and lifelike conversations. Developers can also customize various aspects of the conversation experience, such as voice stability, backchanneling, and custom voice cloning, to tailor the AI agent to their specific needs. Retell AI's API is designed to be easy to integrate with existing LLMs and frontend applications, making it accessible to developers of all levels.
Athina AI Hub
Athina AI Hub is an ultimate resource for AI development teams, offering a wide range of AI development blogs, research papers, and original content. It provides valuable insights into cutting-edge technologies such as Large Language Models (LLMs), Retrieval-Augmented Generation (RAG), and AI agents. Athina AI Hub aims to empower AI engineers, researchers, data scientists, and product developers by offering comprehensive resources and fostering innovation in the field of Artificial Intelligence.

WeGPT.ai
WeGPT.ai is an AI tool that focuses on enhancing Generative AI capabilities through Retrieval Augmented Generation (RAG). It provides versatile tools for web browsing, REST APIs, image generation, and coding playgrounds. The platform offers consumer and enterprise solutions, multi-vendor support, and access to major frontier LLMs. With a comprehensive approach, WeGPT.ai aims to deliver better results, user experience, and cost efficiency by keeping AI models up-to-date with the latest data.
UnfoldAI
UnfoldAI is a website offering articles, strategies, and tutorials for building production-grade ML systems. Authored by Simeon Emanuilov, the site covers topics such as deep learning, computer vision, LLMs, programming, MLOps, performance, scalability, and AI consulting. It aims to provide insights and best practices for professionals in the field of machine learning to create robust, efficient, and scalable systems.
FutureSmart AI
FutureSmart AI is a platform that provides custom Natural Language Processing (NLP) solutions. The platform focuses on integrating Mem0 with LangChain to enhance AI Assistants with Intelligent Memory. It offers tutorials, guides, and practical tips for building applications with large language models (LLMs) to create sophisticated and interactive systems. FutureSmart AI also features internship journeys and practical guides for mastering RAG with LangChain, catering to developers and enthusiasts in the realm of NLP and AI.
3 - Open Source AI Tools
llm-random
This repository contains code for research conducted by the LLM-Random research group at IDEAS NCBR in Warsaw, Poland. The group focuses on developing and using this repository to conduct research. For more information about the group and its research, refer to their blog, llm-random.github.io.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

trainer
Kubeflow Trainer is a Kubernetes-native project for fine-tuning large language models (LLMs) and enabling scalable, distributed training of machine learning (ML) models across various frameworks. It allows integration with ML libraries like HuggingFace, DeepSpeed, or Megatron-LM to orchestrate ML training on Kubernetes. Develop LLMs effortlessly with the Kubeflow Python SDK and build Kubernetes-native Training Runtimes with Kubernetes Custom Resources APIs.
20 - OpenAI Gpts

Algorithm Expert
I develop and optimize algorithms with a technical and analytical approach.
Gastronomica
Develop recipes with a deep knowledge of food and culinary science, the art of gastronomy, as well as a sense of aesthetics.
ConsultorIA
I develop AI implementation proposals based on your specific needs, focusing on value and affordability.

Training Innovator
Helps develop training modules in Business, Management, Leadership, and HRM.
AI Assistant for Writers and Creatives
Organize and develop ideas, respecting privacy and copyright laws.

Python Code Refactor and Developer
I refactor and develop Python code for clarity and functionality.

IdeasGPT
AI to help expand and develop ideas. Start a conversation with: IdeaGPT or Here is an idea or I have an idea, followed by your idea.
Teacher Mentor
I will provide mentoring and advice to help you develop your teaching practice and expertise.
Plot Breaker
Start with a genre and I'll help you develop a rough story outline. You can handle the rest

Seabiscuit Business Model Master
Discover A More Robust Business: Craft tailored value proposition statements, develop a comprehensive business model canvas, conduct detailed PESTLE analysis, and gain strategic insights on enhancing business model elements like scalability, cost structure, and market competition strategies. (v1.18)