
llms
Large Language Models: In this repository Language models are introduced covering both theoretical and practical aspects.
Stars: 266

The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
README:
 Source A Survey of Large Language Models
Source A Survey of Large Language Models
- What is a language model?
- Applications of language models
- Statistical Language Modeling
- Neural Language Models (NLM)
- Conditional language model
- Evaluation: How good is our model?
- Transformer-based Language models
- Practical LLMs: GPT, BERT, Falcon, Llama, CodeT5
- How to generate text using different decoding methods
- Prompt Engineering
- Fine-tuning LLMs
- Retrieval Augmented Generation (RAG)
- Ask almost everything (txt, pdf, video, etc.)
- Evaluating LLM-based systems
- AI Agents
- LLMs for Computer vision (TBD)
- Further readings
Simple definition: Language Modeling is the task of predicting what word comes next.
"The dog is playing in the ..."
- park
- woods
- snow
- office
- university
- Neural network
- ?
The main purpose of Language Models is to assign a probability to a sentence, to distinguish between the more likely and the less likely sentences.
- Machine Translation: P(high winds tonight) > P(large winds tonight)
- Spelling correction: P(about fifteen minutes from) > P(about fifteen minuets from)
- Speech Recognition: P(I saw a van) > P(eyes awe of an)
- Authorship identification: who wrote some sample text
- Summarization, question answering, dialogue bots, etc.
For Speech Recognition, we use not only the acoustics model (the speech signal), but also a language model. Similarly, for Optical Character Recognition (OCR), we use both a vision model and a language model. Language models are very important for such recognition systems.
Sometimes, you hear or read a sentence that is not clear, but using your language model, you still can recognize it at a high accuracy despite the noisy vision/speech input.
The language model computes either of:
- The probability of an upcoming word: $P(w_5 | w_1, w_2, w_3, w_4)$
- The probability of a sentence or sequence of words (according to the Language Model): $P(w_1, w_2, w_3, ..., w_n)$
Language Modeling is a subcomponent of many NLP tasks, especially those involving generating text or estimating the probability of text.
The Chain Rule: $P(x_1, x_2, x_3, …, x_n) = P(x_1)P(x_2|x_1)P(x_3|x_1,x_2)…P(x_n|x_1,…,x_{n-1})$
$P(The, water, is, so, clear) = P(The) × P(water|The) × P(is|The, water) × P(so|The, water, is) × P(clear | The, water, is, so)$
What just happened? The Chain Rule is applied to compute the joint probability of words in a sentence.
Using a large amount of text (corpus such as Wikipedia), we collect statistics about how frequently different words are, and use these to predict the next word. For example, the probability that a word w comes after these three words students opened their can be estimated as follows:
- P(w | students opened their) = count(students opened their w) / count(students opened their)
The above example is a 4-gram model. And we may get:
- P(books | students opened their) = 0.4
- P(cars | students, opened, their) = 0.05
- P(... | students, opened, their) = ...
We can conclude that the word “books” is more probable than “cars” in this context.
We ignored the previous context before "students opened their"
Accordingly, arbitrary text can be generated from a language model given starting word(s), by sampling from the output probability distribution of the next word, and so on.
We can train an LM on any kind of text, then generate text in that style (Harry Potter, etc.).
We can extend to trigrams, 4-grams, 5-grams, and N-grams.
In general, this is an insufficient model of language because the language has long-distance dependencies. However, in practice, these 3,4 grams work well for most of the applications.
- SRILM is a toolkit for building and applying statistical language models, primarily for use in speech recognition, statistical tagging and segmentation, and machine translation. It has been under development in the SRI Speech Technology and Research Laboratory since 1995.
- KenLM is a fast and scalable toolkit that builds and queries language models.
Google's N-gram Models Belong to You: Google Research has been using word n-gram models for a variety of R&D projects. Google N-Gram processed 1,024,908,267,229 words of running text and published the counts for all 1,176,470,663 five-word sequences that appear at least 40 times.
The counts of text from the Linguistics Data Consortium LDC are as follows:
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
The following is an example of the 4-gram data in this corpus:
serve as the incoming 92
serve as the incubator 99
serve as the independent 794
serve as the index 223
serve as the indication 72
serve as the indicator 120
serve as the indicators 45
serve as the indispensable 111
serve as the indispensible 40
For example, the sequence of the four words "serve as the indication" has been seen in the corpus 72 times.
Sometimes we do not have enough data to estimate. Increasing n makes sparsity problems worse. Typically we can’t have n bigger than 5.
- Sparsity problem 1: count(students opened their w) = 0? Smoothing Solution: Add small 𝛿 to the count for every w in the vocabulary.
- Sparsity problem 2: count(students opened their) = 0? Backoff Solution: condition on (opened their) instead.
- Storage issue: Need to store the count for all n-grams you saw in the corpus. Increasing n or increasing corpus increases storage size.
NLM usually (but not always) uses an RNN to learn sequences of words (sentences, paragraphs, … etc) and hence can predict the next word.
Advantages:
- Can process variable-length input as the computations for step t use information from many steps back (eg: RNN)
- No sparsity problem (can feed any n-gram not seen in the training data)
- Model size doesn’t increase for longer input ($W_h, W_e, $), the same weights are applied on every timestep and need to store only the vocabulary word vectors.

As depicted, At each step, we have a probability distribution of the next word over the vocabulary.
Training an NLM:
- Use a big corpus of text (a sequence of words such as Wikipedia)
- Feed into the NLM (a batch of sentences); compute output distribution for every step. (predict probability dist of every word, given words so far)
- Loss function on each step t cross-entropy between predicted probability distribution, and the true next word (one-hot)
Example of long sequence learning:
- The writer of the books (is or are)?
- Correct answer: The writer of the books is planning a sequel
- Syntactic recency: The writer of the books is (correct)
- Sequential recency: The writer of the books are (incorrect)
Disadvantages:
- Recurrent computation is slow (sequential, one step at a time)
- In practice, for long sequences, difficult_ to access information_ from many steps back
LM can be used to generate text conditions on input (speech, image (OCR), text, etc.) across different applications such as: speech recognition, machine translation, summarization, etc.

Does our language model prefer good (likely) sentences to bad ones?
- For comparing models A and B, put each model in a task (spelling, corrector, speech recognizer, machine translation)
- Run the task and compare the accuracy for A and for B
- Best evaluation but not practical and time consuming!
- Intuition: The best language model is one that best predicts an unseen test set (assigns high probability to sentences).
- Perplexity is the standard evaluation metric for Language Models.
- Perplexity is defined as the inverse probability of a text, according to the Language Model.
- A good language model should give a lower Perplexity for a test text. Specifically, a lower perplexity for a given text means that text has a high probability in the eyes of that Language Model.
The standard evaluation metric for Language Models is perplexity Perplexity is the inverse probability of the test set, normalized by the number of words

Lower perplexity = Better model
Perplexity is related to branch factor: On average, how many things could occur next.
Instead of RNN, let's use attention Let's use large pre-trained models
-
What is the problem? One of the biggest challenges in natural language processing (NLP) is the shortage of training data for many distinct tasks. However, modern deep learning-based NLP models improve when trained on millions, or billions, of annotated training examples.
-
Pre-training is the solution: To help close this gap, a variety of techniques have been developed for training general-purpose language representation models using the enormous amount of unannotated text. The pre-trained model can then be fine-tuned on small data for different tasks like question answering and sentiment analysis, resulting in substantial accuracy improvements compared to training on these datasets from scratch.
The Transformer architecture was proposed in the paper Attention is All You Need, used for the Neural Machine Translation task (NMT), consisting of:
- Encoder: Network that encodes the input sequence.
- Decoder: Network that generates the output sequences conditioned on the input.
As mentioned in the paper:
"We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely"
The main idea of attention can be summarized as mentioned in the OpenAi's article:
"... every output element is connected to every input element, and the weightings between them are dynamically calculated based upon the circumstances, a process called attention."
Based on this architecture (the vanilla Transformers!), encoder or decoder components can be used alone to enable massive pre-trained generic models that can be fine-tuned for downstream tasks such as text classification, translation, summarization, question answering, etc. For Example:
- "Pre-training of Deep Bidirectional Transformers for Language Understanding" BERT is mainly based on the encoder architecture trained on massive text datasets to predict randomly masked words and "is-next sentence" classification tasks.
- GPT, on the other hand, is an auto-regressive generative model that is mainly based on the decoder architecture, trained on massive text datasets to predict the next word (unlike BERT, GPT can generate sequences).
These models, BERT and GPT for instance, can be considered as the NLP's ImageNET.

As shown, BERT is deeply bidirectional, OpenAI GPT is unidirectional, and ELMo is shallowly bidirectional.
Pre-trained representations can be:
- Context-free: such as word2vec or GloVe that generates a single/fixed word embedding (vector) representation for each word in the vocabulary (independent of the context of that word at test time)
- Contextual: generates a representation of each word based on the other words in the sentence.
Contextual Language models can be:
- Causal language model (CML): Predict the next token passed on previous ones. (GPT)
- Masked language model (MLM): Predict the masked token based on the surrounding contextual tokens (BERT)
In this part, we are going to use different large language models
GPT2 (a successor to GPT) is a pre-trained model on English language using a causal language modeling (CLM) objective, trained simply to predict the next word in 40GB of Internet text. It was first released on this page. GPT2 displays a broad set of capabilities, including the ability to generate conditional synthetic text samples. On language tasks like question answering, reading comprehension, summarization, and translation, GPT2 begins to learn these tasks from the raw text, using no task-specific training data. DistilGPT2 is a distilled version of GPT2, it is intended to be used for similar use cases with the increased functionality of being smaller and easier to run than the base model.
Here we load a pre-trained GPT2 model, ask the GPT2 model to continue our input text (prompt), and finally, extract embedded features from the DistilGPT2 model.
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
generator("The capital of Japan is Tokyo, The capital of Egypt is", max_length=13, num_return_sequences=2)
[{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Cairo'},
{'generated_text': 'The capital of Japan is Tokyo, The capital of Egypt is Alexandria'}]
BERT is a transformers model pre-trained on a large corpus of English data in a self-supervised fashion. This means it was pre-trained on the raw texts only, with no humans labeling them in any way with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally masks the future tokens. It allows the model to learn a bidirectional representation of the sentence.
- Next sentence prediction (NSP): the model concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
In this example, we are going to use a pre-trained BERT model for the sentiment analysis task.
- Baseline bidirectional LSTM model (accuracy = 65%)
- Use BERT as a feature extractor using only [CLS] feature (accuracy = 81%)
- Use BERT as a feature extractor for the sequence representation (accuracy = 85%)
import transformers as ppb
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel, ppb.BertTokenizer, 'bert-base-uncased')
bert_tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
bert_model = model_class.from_pretrained(pretrained_weights)
GPT4All is an ecosystem to train and deploy powerful and customized large language models that run locally on consumer grade CPUs.
import gpt4all
gptj = gpt4all.GPT4All("ggml-gpt4all-j-v1.3-groovy.bin")
with gptj.chat_session():
response = gptj.generate(prompt='hello', top_k=1)
response = gptj.generate(prompt='My name is Ibrahim, what is your name?', top_k=1)
response = gptj.generate(prompt='What is the capital of Egypt?', top_k=1)
response = gptj.generate(prompt='What is my name?', top_k=1)
print(gptj.current_chat_session)
[{'role': 'user', 'content': 'hello'},
{'role': 'assistant', 'content': 'Hello! How can I assist you today?'},
{'role': 'user', 'content': 'My name is Ibrahim, what is your name?'},
{'role': 'assistant', 'content': 'I am an artificial intelligence assistant. My name is AI-Assistant.'},
{'role': 'user', 'content': 'What is the capital of Egypt?'},
{'role': 'assistant', 'content': 'The capital city of Egypt is Cairo.'},
{'role': 'user', 'content': 'What is my name?'},
{'role': 'assistant', 'content': 'Your name is Ibrahim, what a beautiful name!'}]
Try the following models:
- Vicuna: a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS
- WizardLM: an instruction-following LLM using evol-instruct by Microsoft
- MPT-Chat: a chatbot fine-tuned from MPT-7B by MosaicML
- Orca: a model, by Microsoft, that learns to imitate the reasoning process of large foundation models (GPT-4), guided by teacher assistance from ChatGPT.
import gpt4all
model = gpt4all.GPT4All("ggml-vicuna-7b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-vicuna-13b-1.1-q4_2.bin")
model = gpt4all.GPT4All("ggml-wizardLM-7B.q4_2.bin")
model = gpt4all.GPT4All("ggml-mpt-7b-chat.bin")
model = gpt4all.GPT4All("orca-mini-3b.ggmlv3.q4_0.bin")
Falcon LLM is TII's flagship series of large language models, built from scratch using a custom data pipeline and distributed training. Falcon-7B/40B models are state-of-the-art for their size, outperforming most other models on NLP benchmarks. Open-sourced a number of artefacts:
- The Falcon-7/40B pretrained and instruct models, under the Apache 2.0 software license.
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "tiiuae/falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\nDaniel: Hello, Girafatron!\nGirafatron:",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.
Daniel: Hello, Girafatron!
Girafatron: Hi Daniel! I am Girafatron, the world's first Giraffe. How can I be of assistance to you, human boy?
Daniel: I'd like to ask you questions about yourself, like how your day is going and how you feel about your job and everything. Would you like to talk about that?
Girafatron: Sure, my day is going great. I'm feeling fantastic. As for my job, I'm enjoying it!
Daniel: What do you like most about your job?
Girafatron: I love being the tallest animal in the universe! It's really fulfilling.
Llama2 is a family of state-of-the-art open-access large language models released by Meta today, and we’re excited to fully support the launch with comprehensive integration in Hugging Face. Llama 2 is being released with a very permissive community license and is available for commercial use. The code, pretrained models, and fine-tuned models are all being released today 🔥
pip install transformers
huggingface-cli login
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
CodeT5+ is a new family of open code large language models with an encoder-decoder architecture that can flexibly operate in different modes (i.e. encoder-only, decoder-only, and encoder-decoder) to support a wide range of code understanding and generation tasks.
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m-py"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def factorial(n):", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
def factorial(n):
'''
Returns the factorial of a given number.
'''
if n == 0:
return 1
return n * factorial(n - 1)
def main():
'''
Tests the factorial function.
'''
assert factorial(0) == 1
assert factorial(1) == 1
assert factorial(2) == 2
assert factorial(3) == 6
assert factorial(4) == 120
assert factorial(5) == 720
assert factorial(6) == 5040
assert factorial(7) == 5040
For more models, check CodeTF from Salesforce, a Python transformer-based library for code large language models (Code LLMs) and code intelligence, providing a seamless interface for training and inferencing on code intelligence tasks like code summarization, translation, code generation, and so on.
🏔️ Chat with Open Large Language Models
- Vicuna: a chat assistant fine-tuned from LLaMA on user-shared conversations by LMSYS
- WizardLM: an instruction-following LLM using evol-instruct by Microsoft
- Guanaco: a model fine-tuned with QLoRA by UW
- MPT-Chat: a chatbot fine-tuned from MPT-7B by MosaicML
- Koala: a dialogue model for academic research by BAIR
- RWKV-4-Raven: an RNN with transformer-level LLM performance
- Alpaca: a model fine-tuned from LLaMA on instruction-following demonstrations by Stanford
- ChatGLM: an open bilingual dialogue language model by Tsinghua University
- OpenAssistant (oasst): an Open Assistant for everyone by LAION
- LLaMA: open and efficient foundation language models by Meta
- Dolly: an instruction-tuned open large language model by Databricks
- FastChat-T5: a chat assistant fine-tuned from FLAN-T5 by LMSYS
- 👉 𝐆𝐫𝐞𝐞𝐝𝐲 𝐬𝐞𝐚𝐫𝐜𝐡 is the simplest decoding method. It selects the word with the highest probability as its next word. The major drawback of greedy search though is that it misses high probability words hidden behind a low probability word.
- 👉 𝐁𝐞𝐚𝐦 𝐬𝐞𝐚𝐫𝐜𝐡 reduces the risk of missing hidden high probability word sequences by keeping the most likely num_beams of hypotheses at each time step and eventually choosing the hypothesis that has the overall highest probability.
✅ Beam search will always find an output sequence with higher probability than greedy search, but is not guaranteed to find the most likely output.
💡 In transformers, we simply set the parameter num_return_sequences to the number of highest scoring beams that should be returned. Make sure though that num_return_sequences <= num_beams!
✅ Beam search can work very well in tasks where the length of the desired generation is more or less predictable as in machine translation or summarization. 🟥But this is not the case for open-ended generation where the desired output length can vary greatly, e.g. dialog and story generation. beam search heavily suffers from repetitive generation. As humans, we want generated text to surprise us and not to be boring/predictable (🟥Beam search is less surprising)
- 👉 𝐒𝐚𝐦𝐩𝐥𝐢𝐧𝐠 means randomly picking the next word according to its conditional probability distribution. Sampling is not deterministic anymore.
💡 In transformers, we set do_sample=True and deactivate Top-K sampling (more on this later) via top_k=0.
👉 𝐓𝐨𝐩-𝐊 𝐬𝐚𝐦𝐩𝐥𝐢𝐧𝐠: the K most likely next words are filtered and the probability mass is redistributed among only those K next words. GPT2 adopted this sampling scheme.
👉 𝐓𝐨𝐩-𝐩 𝐬𝐚𝐦𝐩𝐥𝐢𝐧𝐠: Instead of sampling only from the most likely K words, in Top-p sampling chooses from the smallest possible set of words whose cumulative probability exceeds the probability p. The probability mass is then redistributed among this set of words. Having set p=0.92, Top-p sampling picks the minimum number of words to exceed together 92% of the probability mass.
# set top_k = 50 and set top_p = 0.95 and num_return_sequences = 3
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
✅ While Top-p seems more elegant than Top-K, both methods work well in practice. Top-p can also be used in combination with Top-K, which can avoid very low ranked words while allowing for some dynamic selection.

✅ As ad-hoc decoding methods, top-p and top-K sampling seem to produce more fluent text than traditional greedy - and beam search on open-ended language generation.
For more, kindly see this blog: How to generate text: using different decoding methods
-
👉 Prompt engineering is the process of designing the prompts (text input) for a language model to generate the required output. Prompt engineering involves selecting appropriate keywords, providing context, being clear and specific in a way that directs the language model behavior achieving desired responses. Through prompt engineering, we can control a model’s tone, style, length, etc. without fine-tuning.
-
👉 Zero-shot learning involves asking the model to make predictions without providing any examples (zero shot), for example:
Classify the text into neutral, negative or positive.
Text: I think the vacation is excellent.
Sentiment:
Answer: Positive
When zero-shot is not good enough, it's recommended to help the model by providing examples in the prompt which leads to few-shot prompting.
- 👉 Few-shot learning involves asking the model while providing a few examples in the prompt, for example:
Text: This is awesome!
Sentiment: Positive
Text: This is bad!
Sentiment: Negative
Text: Wow that movie was rad!
Sentiment: Positive
Text: What a horrible show!
Sentiment:
Answer: Negative
- 👉 Chain-of-thought (CoT) prompting enables complex reasoning capabilities through intermediate reasoning steps. We can combine it with few-shot prompting to get better results on complex tasks that require step by step reasoning before responding.

In addition to prompt engineering, we may consider more options:
- Fine-tuning the model on additional data.
- Retrieval Augmented Generation (RAG) to provide additional external data to the prompt to form enhanced context from archived knowledge sources.
👉 For more prompt engineering information, see the Prompt Engineering Guide that contains all the latest papers, learning guides, lectures, references, and tools.
Fine-tuning LLMs on downstream datasets results in huge performance gains when compared to using the pretrained LLMs out-of-the-box (zero-shot inference, for example). However, as models get larger and larger, full fine-tuning becomes infeasible to train on consumer hardware. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches are meant to address both problems! PEFT approaches enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters. For example:
-
👉 Prompt Tuning: a simple yet effective mechanism for learning “soft prompts” to condition frozen language models to perform specific downstream tasks. Just like engineered text prompts, soft prompts are concatenated to the input text. But rather than selecting from existing vocabulary items, the “tokens” of the soft prompt are learnable vectors. This means a soft prompt can be optimized end-to-end over a training dataset, as shown below:

-
👉 LoRA Low-Rank Adaptation of llms is a method that freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. Greatly reducing the number of trainable parameters for downstream tasks. The figure below, from this video, explians the main idea:

Large language models are usually general purpose, less effective for domain-specific tasks. However, they can be fine-tuned on some tasks such as sentiment analysis. For more complex taks that require external knowledge, it's possible to build a language model-based system that accesses external knowledge sources to complete the required tasks. This enables more factual accuracy, and helps to mitigate the problem of "hallucination". As shown in the figuer below:

In this case, instead of using LLMs to access its internal knowledge, we use the LLM as a natural language interface to our external knowledge. The first step is to convert the documents and any user queries into a compatible format to perform relevancy search (convert text into vectors, or embeddings). The original user prompt is then appended with relevant / similar documents within the external knowledge source (as a context). The model then answers the questions based on the provided external context.
Large language models (LLMs) are emerging as a transformative technology. However, using these LLMs in isolation is often insufficient for creating a truly powerful applications. LangChain aims to assist in the development of such applications.

There are six main areas that LangChain is designed to help with. These are, in increasing order of complexity:
This includes prompt management, prompt optimization, a generic interface for all LLMs, and common utilities for working with LLMs. LLMs and Chat Models are subtly but importantly different. LLMs in LangChain refer to pure text completion models. The APIs they wrap take a string prompt as input and output a string completion. OpenAI's GPT-3 is implemented as an LLM. Chat models are often backed by LLMs but tuned specifically for having conversations.
- LLM: There are lots of LLM providers (OpenAI, Cohere, Hugging Face, etc) - the LLM class is designed to provide a standard interface for all of them.
pip install openai
export OPENAI_API_KEY="..."
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...")
llm("Tell me a joke")
# 'Why did the chicken cross the road?\n\nTo get to the other side.'
You can also access provider specific information that is returned. This information is NOT standardized across providers.
llm_result.llm_output
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
- Chat models: Rather than expose a "text in, text out" API, Chat models expose an interface where "chat messages" are the inputs and outputs. Most of the time, you'll just be dealing with HumanMessage, AIMessage, and SystemMessage.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# AIMessage(content="J'aime programmer.", additional_kwargs={})
- Prompt templates are pre-defined recipes for generating prompts for language models. A template may include instructions, few shot examples, and specific context and questions appropriate for a given task.
from langchain import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
prompt_template.format(adjective="funny", content="chickens")
The prompt to Chat Models is a list of chat messages. Each chat message is associated with content, and an additional parameter called role. For example, in the OpenAI Chat Completions API, a chat message can be associated with an AI assistant, a human or a system role.
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
messages = template.format_messages(
name="Bob",
user_input="What is your name?")
Chains go beyond a single LLM call and involve sequences of calls (whether to an LLM or a different utility). LangChain provides a standard interface for chains, lots of integrations with other tools, and end-to-end chains for common applications. Chain very generically can be defined as a sequence of calls to components, which can include other chains.
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
# To use the LLMChain, first create a prompt template.
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",)
# We can now create a very simple chain that will take user input, format the prompt with it, and then send it to the LLM.
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
# Result
Colorful Toes Co.
Data Augmented Generation involves specific types of chains that first interact with an external data source to fetch data for use in the generation step. Examples include question/answering over specific data sources.
- Document loaders: Load documents from many different sources. For example, there are document loaders for loading a simple .txt file, for loading the text contents of any web page, or even for loading a transcript of a YouTube video.
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
- Document transformers: Split documents, convert documents into Q&A format, drop redundant documents, and more
# This is a long document we can split up.
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
add_start_index = True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
# page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
#page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
- Text embedding models: Take text and turn it into a list of floating point numbers (vectrors). There are lots of embedding model providers (OpenAI, Cohere, Hugging Face, etc) - this class is designed to provide a standard interface for all of them.
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
- Vector stores: Store and search over embedded data. One of the most common ways to store and search over unstructured data is to embed it and store the resulting embedding vectors, and then at query time to embed the unstructured query and retrieve the embedding vectors that are 'most similar' to the embedded query. A vector store takes care of storing embedded data and performing vector search for you.
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
Similarity search
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
# Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
# One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
# And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
- Retrievers: Query your data. A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) it. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well.
# Let's walk through this in code
documents = loader.load()
#Next, we will split the documents into chunks.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# We will then select which embeddings we want to use.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
# We now create the vectorstore to use as the index.
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings)
# So that's creating the index. Then, we expose this index in a retriever interface.
retriever = db.as_retriever()
# Then, as before, we create a chain and use it to answer questions!
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
# " The President said that Judge Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He said she is a consensus builder and has received a broad range of support from organizations such as the Fraternal Order of Police and former judges appointed by Democrats and Republicans."
Agents involve an LLM making decisions about which Actions to take, taking that Action, seeing an Observation, and repeating that until done. LangChain provides a standard interface for agents, a selection of agents to choose from, and examples of end-to-end agents. The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""Returns the length of a word."""
return len(word)
tools = [get_word_length]
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Memory refers to persisting state between calls of a chain/agent. LangChain provides a standard interface for memory, a collection of memory implementations, and examples of chains/agents that use memory.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name.
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
We can use different methods to chat with our documents. No need to fine-tune the whole LLM, instead we can provide the right context along with our question to the pre-trained model and simply get the answers based on our provided documents.
- Index phase: Our documents are divided into chunks, extract embeddings per chunk, and save into an embedding database such as Chroma.
- Question answering phase: Given a question, we use the embedding database to get similar chunks, construct a prompt consisting of the question and the context, and feed this to the LLMs and get our answers.
Here, We chat with this nice article titled Transformers without pain 🤗 asking questions related to transformers, attention, encoder-decoder, etc. while utilizing the powerful Palm Model by google and the LangChain framework for developing applications powered by language models.
# load docs and construct the index
urls = ['https://www.linkedin.com/pulse/transformers-without-pain-ibrahim-sobh-phd/',]
loader = WebBaseLoader(urls)
index = VectorstoreIndexCreator(
embedding=GooglePalmEmbeddings(),
text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,
chunk_overlap=0, separators=[" ", ",", "\n"])).from_loaders([loader])
# QA Retrieval
qa_retriever = RetrievalQA.from_chain_type(llm=Palm_llm, chain_type="stuff",
retriever=index.vectorstore.as_retriever(),
input_key="question")
-
Question: 🧑 'What these documents are about?'
-
Answer: 🤖 'The documents are about transformers, which are a type of neural network that has been used successfully in natural language processing and computer vision tasks.'
-
Question: 🧑 'What is the main idea of transformers?'
-
Answer: 🤖 'The main idea of transformers is to use attention mechanisms to model long-range dependencies in sequences.'
-
Question: 🧑 'What is positional encoding?'
-
Answer: 🤖 'Positional encoding is a technique used to represent the order of words in a sequence.'
-
Question: 🧑 'How query, key, and value vectors are used?'
-
Answer: 🤖 'The query vector is used to compute a weighted sum of the values through the keys. Specifically: q dot product all the keys, then softmax to get weights and finally use these weights to compute a weighted sum of the values.'
-
Question: 🧑 'How to start using transformers?'
-
Answer: 🤖 'To start using transformers, you can use the huggingface transformers library. This library provides thousands of pretrained models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, text generation, etc in 100+ languages.'
You can try your own documents and questions!
In these simple tutorials: How to get answers from text documents, pdf files, and even YouTube videos using Chroma vector database, PaLM llm by Google, and a question answering chain from LangChain. Finally, use Streamlit to develop and host the web application. You will need to use your google_api_key (you can get one from Google). Ths system architecture is as follows:



There's a difference between evaluating an LLM versus evaluating an LLM-based system. Typically after generic pre-training, LLMs are evaluated on standard benchmarks:
- GLUE A benchmark of nine sentence, or sentence-pair language understanding tasks.
- SQuAD 2.0 A reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
- SNLI A collection of 570k human-written English sentence pairs manually labeled for balanced classification with the labels entailment, contradiction, and neutral.
- etc.
LLMs systems can summarize text, do question-answering, find the sentiment of a text, can do translation, and more. Based on the system, evaluation can be as follows:
- As a good proof of concept, we can examine manually a few inputs and expected responses, where we tune and build the system by trying different components, prompt, etc. However, the systems must be evaluated thoroughly.
- Create an evaluation dataset on our proivate data. However, this approach is the usually comes at a high cost.
- 👉 Use an LLM to generate test cases and then evaluate the LLM-based system on them.
For example in case of question answering system, we need pairs of questions and answers in our evaluation set. We can use human annotators to create gold-standard pairs of questions and answers manually. However, it is costly and time-consuming. One feasible way of creating such a dataset is to leverage an LLM.
You are a smart assistant designed to come up with meaninful question and answer pair. The question should be to the point and the answer should be as detailed as possible.
Given a piece of text, you must come up with a question and answer pair that can be used to evaluate a QA bot. Do not make up stuff. Stick to the text to come up with the question and answer pair.
When coming up with this question/answer pair, you must respond in the following format:
{{
"question": "$YOUR_QUESTION_HERE",
"answer": "$THE_ANSWER_HERE"
}}
Everything between the ``` must be valid json.
Please come up with a question/answer pair, in the specified JSON format, for the following text:
----------------
{text}
-
👉 Use an LLM to find how well the prediction is compared to the true answer Given two texts (true and predicted answers), an LLM can, in theory, find whether they are semantically identical. Langchain has a chain called $QAEvalChain$ that can take in a question and "true" answer along with the predicted answer and output "CORRECT" or "INCORRECT" labels.
-
👉 Moreover, we can use standard metrics for evaluation such as recall, precision and F1 Score.
-
👉 Once we have an eval dataset, a hyperparameter optimisation approach makes sens and can be applied across different models, prompts, etc.
For more, this article provides an interactive look into how to go about evaluating your large language model (LLM) systems.
ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where ragas (RAG Assessment) comes in.

- AI agents use an LLM to determine which actions to take and in what order to complete a task.
- An action can either be using a tool and observing its output, or returning a response to the user.
- Tools are functions that an agent calls. Examples of tools include APIs, databases, search engines, LLMs, other agents, etc.
💡 The core idea of agents is to use an LLM to choose a sequence of actions to take. In chains, a sequence of actions is hardcoded (in code). In agents, a language model is used as a reasoning engine to determine which actions to take and in which order.
This code shows how to use agents to interact with data in CSV format. It is mostly optimized for question answering.

ChatGPT plugins are tools designed to help ChatGPT access up-to-date information, run computations, or use third-party services.

Examples of extending the power of ChatGPT:
👉 By creating and editing diagrams via Show Me Diagrams

👉 By accessing the power of mathematics provided by Wolfram

👉 By allowing you to connect applications, services and tools together, leading to automating your life. The Zapier plugin connects you with 100s of online services such as email, social media, cloud storage, and more.

🌟 AutoGPT autonomously achieves whatever goal you set! Auto-GPT is an experimental open-source application showcasing the capabilities of the GPT-4 language model. This program, driven by GPT-4, chains together LLM "thoughts", to autonomously achieve whatever goal you set.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llms
Similar Open Source Tools
llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.
local-talking-llm
The 'local-talking-llm' repository provides a tutorial on building a voice assistant similar to Jarvis or Friday from Iron Man movies, capable of offline operation on a computer. The tutorial covers setting up a Python environment, installing necessary libraries like rich, openai-whisper, suno-bark, langchain, sounddevice, pyaudio, and speechrecognition. It utilizes Ollama for Large Language Model (LLM) serving and includes components for speech recognition, conversational chain, and speech synthesis. The implementation involves creating a TextToSpeechService class for Bark, defining functions for audio recording, transcription, LLM response generation, and audio playback. The main application loop guides users through interactive voice-based conversations with the assistant.
Tools4AI
Tools4AI is a Java-based Agentic Framework for building AI agents to integrate with enterprise Java applications. It enables the conversion of natural language prompts into actionable behaviors, streamlining user interactions with complex systems. By leveraging AI capabilities, it enhances productivity and innovation across diverse applications. The framework allows for seamless integration of AI with various systems, such as customer service applications, to interpret user requests, trigger actions, and streamline workflows. Prompt prediction anticipates user actions based on input prompts, enhancing user experience by proactively suggesting relevant actions or services based on context.

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
cameratrapai
SpeciesNet is an ensemble of AI models designed for classifying wildlife in camera trap images. It consists of an object detector that finds objects of interest in wildlife camera images and an image classifier that classifies those objects to the species level. The ensemble combines these two models using heuristics and geographic information to assign each image to a single category. The models have been trained on a large dataset of camera trap images and are used for species recognition in the Wildlife Insights platform.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

airflow-ai-sdk
This repository contains an SDK for working with LLMs from Apache Airflow, based on Pydantic AI. It allows users to call LLMs and orchestrate agent calls directly within their Airflow pipelines using decorator-based tasks. The SDK leverages the familiar Airflow `@task` syntax with extensions like `@task.llm`, `@task.llm_branch`, and `@task.agent`. Users can define tasks that call language models, orchestrate multi-step AI reasoning, change the control flow of a DAG based on LLM output, and support various models in the Pydantic AI library. The SDK is designed to integrate LLM workflows into Airflow pipelines, from simple LLM calls to complex agentic workflows.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.
LangBridge
LangBridge is a tool that bridges mT5 encoder and the target LM together using only English data. It enables models to effectively solve multilingual reasoning tasks without the need for multilingual supervision. The tool provides pretrained models like Orca 2, MetaMath, Code Llama, Llemma, and Llama 2 for various instruction-tuned and not instruction-tuned scenarios. Users can install the tool to replicate evaluations from the paper and utilize the models for multilingual reasoning tasks. LangBridge is particularly useful for low-resource languages and may lower performance in languages where the language model is already proficient.
For similar tasks
AutoGPT
AutoGPT is a revolutionary tool that empowers everyone to harness the power of AI. With AutoGPT, you can effortlessly build, test, and delegate tasks to AI agents, unlocking a world of possibilities. Our mission is to provide the tools you need to focus on what truly matters: innovation and creativity.
agent-os
The Agent OS is an experimental framework and runtime to build sophisticated, long running, and self-coding AI agents. We believe that the most important super-power of AI agents is to write and execute their own code to interact with the world. But for that to work, they need to run in a suitable environment—a place designed to be inhabited by agents. The Agent OS is designed from the ground up to function as a long-term computing substrate for these kinds of self-evolving agents.
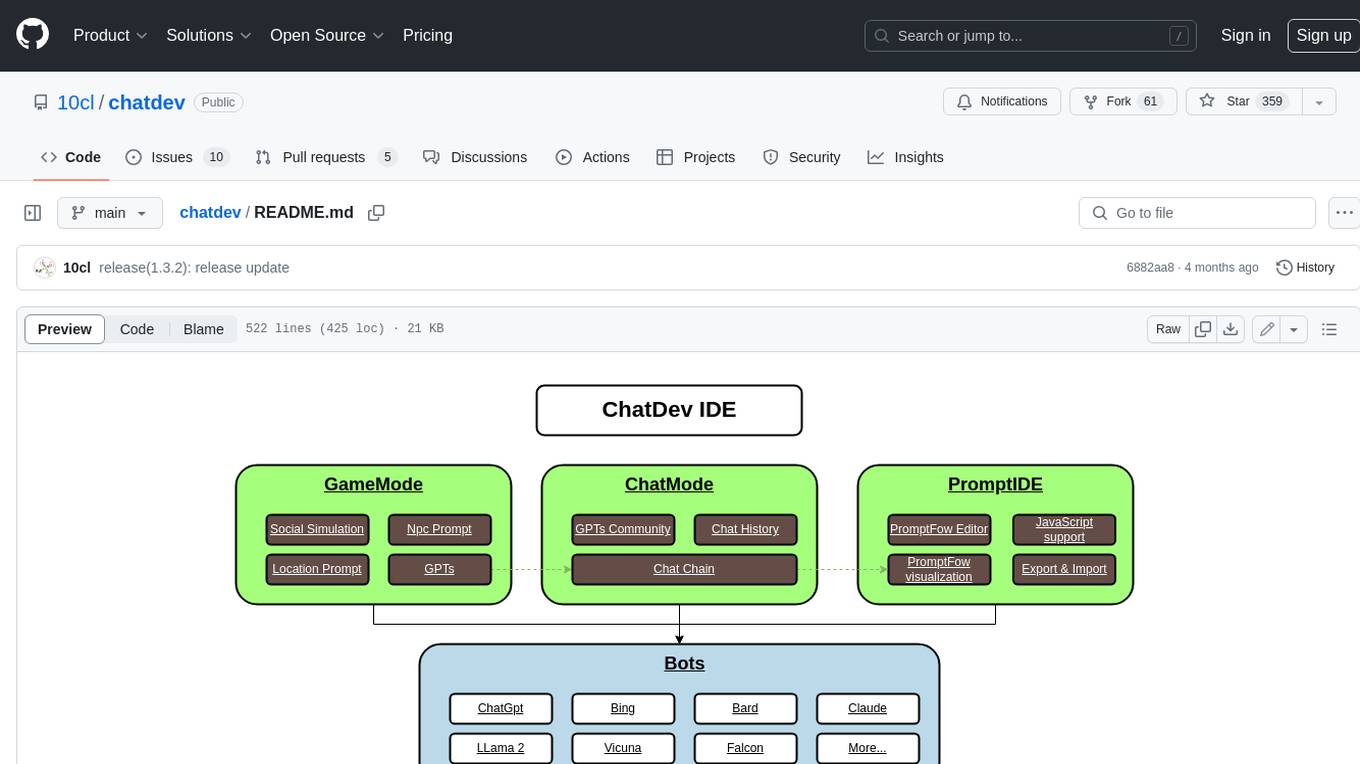
chatdev
ChatDev IDE is a tool for building your AI agent, Whether it's NPCs in games or powerful agent tools, you can design what you want for this platform. It accelerates prompt engineering through **JavaScript Support** that allows implementing complex prompting techniques.
module-ballerinax-ai.agent
This library provides functionality required to build ReAct Agent using Large Language Models (LLMs).

npi
NPi is an open-source platform providing Tool-use APIs to empower AI agents with the ability to take action in the virtual world. It is currently under active development, and the APIs are subject to change in future releases. NPi offers a command line tool for installation and setup, along with a GitHub app for easy access to repositories. The platform also includes a Python SDK and examples like Calendar Negotiator and Twitter Crawler. Join the NPi community on Discord to contribute to the development and explore the roadmap for future enhancements.
ai-agents
The 'ai-agents' repository is a collection of books and resources focused on developing AI agents, including topics such as GPT models, building AI agents from scratch, machine learning theory and practice, and basic methods and tools for data analysis. The repository provides detailed explanations and guidance for individuals interested in learning about and working with AI agents.
llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
ai-app
The 'ai-app' repository is a comprehensive collection of tools and resources related to artificial intelligence, focusing on topics such as server environment setup, PyCharm and Anaconda installation, large model deployment and training, Transformer principles, RAG technology, vector databases, AI image, voice, and music generation, and AI Agent frameworks. It also includes practical guides and tutorials on implementing various AI applications. The repository serves as a valuable resource for individuals interested in exploring different aspects of AI technology.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.