
LLM-Synthetic-Data
Real-time, fine-grained LLM synthetic data involves data of, by, and for LLMs.
Stars: 101
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
README:



This repo, inspired by Awesome-LLM-Synthetic-Data, which focuses on real-time, fine-grained LLM-Synthetic-Data.
If you find this useful, feel free to follow us and star both repos.
Thanks to all the great contributors on GitHub! 🔥⚡🔥
- Synthetic data: save money, time and carbon with open source. Moritz Laurer. Feb 16, 2024.
- Synthetic data generation (Part 1). Dylan Royan Almeida. Apr 10, 2024
- Synthetic dataset generation techniques: Self-Instruct. Daniel van Strien. May 15, 2024.
- CodecLM: Aligning language models with tailored synthetic data Zifeng Wang and Chen-Yu Lee. May 30, 2024.
- The Rise of Agentic Data Generation. Maxime Labonne. July 15, 2024.
- LLM-Driven Synthetic Data Generation, Curation & Evaluation. Cobus Greyling. Aug 2, 2024.
- Using LLMs for Synthetic Data Generation: The Definitive Guide Kritin Vongthongsri. November 8, 2024.
- Best Practices and Lessons Learned on Synthetic Data for Language Models. Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai. COLM 2024.
- On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey. Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang. ACL Findings 2024.
- Large Language Models for Data Annotation: A Survey Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, Huan Liu. EMNLP 2024.
- Generative AI for Synthetic Data Generation: Methods, Challenges and the Future. Xu Guo, Yiqiang Chen. Arxiv 2024.
- Comprehensive Exploration of Synthetic Data Generation: A Survey. André Bauer, Simon Trapp, Michael Stenger, Robert Leppich, Samuel Kounev, Mark Leznik, Kyle Chard, Ian Foster. Arxiv 2024.
- Phi-4 Technical Report Microsoft Research. Arxiv 2024.
- Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Arxiv 2024
- MAmmoTH2: Scaling Instructions from the Web. Xiang Yue, Tuney Zheng, Ge Zhang, Wenhu Chen. Neurips 2024.
- Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent Tecent Hunyuan Team. Arxiv 2024.
- STaR: Bootstrapping Reasoning With Reasoning Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman. NeurIPS 2022.
- Generating Training Data with Language Models: Towards Zero-Shot Language Understanding Yu Meng, Jiaxin Huang, Yu Zhang, Jiawei Han. NeurIPS 2022.
- ZeroGen: Efficient Zero-shot Learning via Dataset Generation Jiacheng Ye, Jiahui Gao, Qintong Li, Hang Xu, Jiangtao Feng, Zhiyong Wu, Tao Yu, Lingpeng Kong. EMNLP 2022.
- Symbolic Knowledge Distillation: from General Language Models to Commonsense Models Peter West, Chandra Bhagavatula, Jack Hessel, Jena D. Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, Yejin Choi. NAACL 2022.
- Large Language Model as Attributed Training Data Generator: A Tale of Diversity and Bias Yue Yu, Yuchen Zhuang, Jieyu Zhang, Yu Meng, Alexander Ratner, Ranjay Krishna, Jiaming Shen, Chao Zhang. NeurIPS D&B 2023.
- Self-instruct: Aligning language models with self-generated instructions. Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, Hannaneh Hajishirzi. ACL 2023.
- Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions John Joon Young Chung, Ece Kamar, Saleema Amershi. ACL 2023.
- Large Language Models Can Self-Improve Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, Jiawei Han. EMNLP 2023.
- Making Large Language Models Better Data Creators Dong-Ho Lee, Jay Pujara, Mohit Sewak, Ryen W. White, Sujay Kumar Jauhar. EMNLP 2023.
- Generating Faithful Synthetic Data with Large Language Models: A Case Study in Computational Social Science Veniamin Veselovsky, Manoel Horta Ribeiro, Akhil Arora, Martin Josifoski, Ashton Anderson, Robert West, Arxiv 2023.
- Self-Rewarding Language Models. Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, Jason Weston. ICML 2024.
- Scaling Synthetic Data Creation with 1,000,000,000 Personas. Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, Dong Yu. Arxiv 2024.
- Learning to Generate Instruction Tuning Datasets for Zero-Shot Task Adaptation Nihal V. Nayak, Yiyang Nan, Avi Trost, Stephen H. Bach. ACL Findings 2024.
- Rephrasing theWeb A Recipe for Compute and Data-Efficient Language Modeling Pratyush Maini, Skyler Seto, He Bai, David Grangier, Yizhe Zhang, Navdeep Jaitly. ACL 2024.
- Automatic Instruction Evolving for Large Language Models. Weihao Zeng, Can Xu, Yingxiu Zhao, Jian-Guang Lou, Weizhu Chen. EMNLP 2024.
- Self-playing Adversarial Language Game Enhances LLM Reasoning Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, Nan Du. Neurips 2024.
- WizardLM: Empowering Large Language Models to Follow Complex Instructions. Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Daxin Jiang. ICLR 2024.
- CodecLM: Aligning Language Models with Tailored Synthetic Data. Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister. NAACL Findings 2024.
- TarGEN: Targeted Data Generation with Large Language Models Himanshu Gupta, Kevin Scaria, Ujjwala Anantheswaran, Shreyas Verma, Mihir Parmar, Saurabh Arjun Sawant, Chitta Baral, Swaroop Mishra. COLM 2024.
- Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models Haoran Li, Qingxiu Dong, Zhengyang Tang, Chaojun Wang, Xingxing Zhang, Haoyang Huang, Shaohan Huang, Xiaolong Huang, Zeqiang Huang, Dongdong Zhang, Yuxian Gu, Xin Cheng, Xun Wang, Si-Qing Chen, Li Dong, Wei Lu, Zhifang Sui, Benyou Wang, Wai Lam, Furu Wei. Submit to ICLR 2025.
- Forewarned is Forearmed: Harnessing LLMs for Data Synthesis via Failure-induced Exploration. Submit to ICLR 2025.
- Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, Bill Yuchen Lin. Submit to ICLR 2025.
- Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources Alisia Lupidi, Carlos Gemmell, Nicola Cancedda, Jane Dwivedi-Yu, Jason Weston, Jakob Foerster, Roberta Raileanu, Maria Lomeli. Submit to ICLR 2025.
- AI models collapse when trained on recursively generated data Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson & Yarin Gal, Nature 2024.
- How bad is training on synthetic data? A statistical analysis of language model collapse. Mohamed El Amine Seddik, Suei-Wen Chen, Soufiane Hayou, Pierre Youssef, Merouane Abdelkader DEBBAH. COLM 2024.
- ToEdit: How to Synthesize Text Data to Avoid Model Collapse? Submit to ICLR 2025.
- Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement Yunzhen Feqng, Elvis Dohmatob, Pu Yang, Francois Charton, Julia Kempe. Submit to ICLR 2025.
- DataGen: Unified Synthetic Dataset Generation via Large Language Models Submit to ICLR 2025.
- On the Diversity of Synthetic Data and its Impact on Training Large Language Models Hao Chen, Abdul Waheed, Xiang Li, Yidong Wang, Jindong Wang, Bhiksha Raj, Marah I. Abdin. Submit to ICLR 2025.
- FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models, Ruixuan Xiao, Yiwen Dong, Junbo Zhao, Runze Wu, Minmin Lin, Gang Chen, Haobo Wang. EMNLP 2023.
- Let's Synthesize Step by Step: Iterative Dataset Synthesis with Large Language Models by Extrapolating Errors from Small Models Ruida Wang, Wangchunshu Zhou, Mrinmaya Sachan, EMNLP finding2023
- Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations, Zhuoyan Li, Hangxiao Zhu, Zhuoran Lu, Ming Yin. EMNLP finding2023.
- Distilling LLMs' Decomposition Abilities into Compact Language Models Denis Tarasov, Kumar Shridhar. AutoRL@ICML 2024.
- MuggleMath: Assessing the Impact of Query and Response Augmentation on Math Reasoning Chengpeng Li, Zheng Yuan, Hongyi Yuan, Guanting Dong, Keming Lu, Jiancan Wu, Chuanqi Tan, Xiang Wang, Chang Zhou. ACL 2024.
- MathGenie: Generating Synthetic Data with Question Back-translation for Enhancing Mathematical Reasoning of LLMs Zimu Lu, Aojun Zhou, Houxing Ren, Ke Wang, Weikang Shi, Junting Pan, Mingjie Zhan, Hongsheng Li. ACL 2024.
- MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, Weiyang Liu. ICLR 2024.
- Augmenting Math Word Problems via Iterative Question Composing Haoxiong Liu, Yifan Zhang, Yifan Luo, Andrew Chi-Chih Yao. DPFM@ICLR 2024.
- Key-Point-Driven Data Synthesis with its Enhancement on Mathematical Reasoning Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, Weizhu Chen. Arxiv 2024.
- Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, Junxian He. NeurIPS 2024.
- Program Synthesis with Large Language Models Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, Charles Sutton. Arxiv 2021.
- CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi. NeurIPS 2022.
- InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback John Yang, Akshara Prabhakar, Karthik Narasimhan, Shunyu Yao. Arxiv 2023.
- Language Models Can Teach Themselves to Program Better Patrick Haluptzok, Matthew Bowers, Adam Tauman Kalai. ICLR 2023.
- CODEGEN: AN OPEN LARGE LANGUAGE MODEL FOR CODE WITH MULTI-TURN PROGRAM SYNTHESIS. ICLR2023.
- Code Alpaca: An Instruction-following LLaMA Model trained on code generation instructions Sahil Chaudhary. GitHub 2023.
- Genetic Instruct: Scaling up Synthetic Generation of Coding Instructions for Large Language Models Somshubra Majumdar, Vahid Noroozi, Sean Narenthiran, Aleksander Ficek, Jagadeesh Balam, Boris Ginsburg. Arxiv 2024.
- Magicoder: Empowering Code Generation with OSS-Instruct Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, Lingming Zhang. ICML 2024.
- WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning Zhaojian Yu, Xin Zhang, Ning Shang, Yangyu Huang, Can Xu, Yishujie Zhao, Wenxiang Hu, Qiufeng Yin. ACL 2024.
- WizardCoder: Empowering Code Large Language Models with Evol-Instruct Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, Daxin Jiang. ICLR 2024.
- Learning Performance-Improving Code Edits Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, Amir Yazdanbakhsh. ICLR 2024.
- InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct Yutong Wu, Di Huang, Wenxuan Shi, Wei Wang, Lingzhe Gao, Shihao Liu, Ziyuan Nan, Kaizhao Yuan, Rui Zhang, Xishan Zhang, Zidong Du, Qi Guo, Yewen Pu, Dawei Yin, Xing Hu, Yunji Chen. Arxiv 2024.
- OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, Xiang Yue. Arxiv 2024.
- AutoCoder: Enhancing Code Large Language Model with AIEV-Instruct Bin Lei, Yuchen Li, Qiuwu Chen. Arxiv 2024.
- How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data Yejie Wang, Keqing He, Dayuan Fu, Zhuoma Gongque, Heyang Xu, Yanxu Chen, Zhexu Wang, Yujia Fu, Guanting Dong, Muxi Diao, Jingang Wang, Mengdi Zhang, Xunliang Cai, Weiran Xu. Arxiv 2024.
- SelfCodeAlign: Self-Alignment for Code Generation Yuxiang Wei, Federico Cassano, Jiawei Liu, Yifeng Ding, Naman Jain, Zachary Mueller, Harm de Vries, Leandro von Werra, Arjun Guha, Lingming Zhang. Arxiv 2024.
- Synthesizing Text-to-SQL Data from Weak and Strong LLMs Jiaxi Yang, Binyuan Hui, Min Yang, Jian Yang, Junyang Lin, Chang Zhou. ACL 2024.
- Synthetic-Text-To-SQL: A synthetic dataset for training language models to generate SQL queries from natural language prompts Meyer, Yev and Emadi, Marjan and Nathawani, Dhruv and Ramaswamy, Lipika and Boyd, Kendrick and Van Segbroeck, Maarten and Grossman, Matthew and Mlocek, Piotr and Newberry, Drew. Huggingface 2024.
- Constitutional AI: Harmlessness from AI Feedback Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, Jared Kaplan. Arxiv 2022.
- Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan. NeurIPS 2023.
- SALMON: Self-Alignment with Instructable Reward Models Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan. ICLR 2024.
- Refined Direct Preference Optimization with Synthetic Data for Behavioral Alignment of LLMs V´ıctor Gallego. Arxiv 2024.
- Self-play with Execution Feedback: Improving Instruction-following Capabilities of Large Language Models. Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, Jingren Zhou. Submit to ICLR 2025.
- Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, Roberta Raileanu. NeurIPS 2024.
- Self-Alignment with Instruction Backtranslation Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Omer Levy, Luke Zettlemoyer, Jason Weston, Mike Lewis. ICLR 2024.
- West-of-N: Synthetic Preference Generation for Improved Reward Modeling. Alizée Pace, Jonathan Mallinson, Eric Malmi, Sebastian Krause, Aliaksei Severyn. Arxiv 2024.
- Make Your LLM Fully Utilize the Context. Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou. Arxiv 2024.
- From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data. Zheyang Xiong, Vasilis Papageorgiou, Kangwook Lee, Dimitris Papailiopoulos. Submit to ICLR 2025.
- Scaling Instruction-tuned LLMs to Million-token Contexts via Hierarchical Synthetic Data Generation Submit to ICLR 2025.
- Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, Jeffrey Wu. ICML 2024.
- Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models. Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu. ICML 2024.
- Impossible Distillation for Paraphrasing and Summarization: How to Make High-quality Lemonade out of Small, Low-quality Models Jaehun Jung, Peter West, Liwei Jiang, Faeze Brahman, Ximing Lu, Jillian Fisher, Taylor Sorensen, Yejin Choi. NAACL 2024.
- ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases. Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, Le Sun. Arxiv 2023.
- Toolformer: Language Models Can Teach Themselves to Use Tools. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. NeurIPS 2023.
- GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction. Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, Ying Shan. Neurips 2023.
- Gorilla: Large Language Model Connected with Massive APIs. Shishir G. Patil, Tianjun Zhang, Xin Wang, Joseph E. Gonzalez. NeurIPS 2024.
- Quality Matters: Evaluating Synthetic Data for Tool-Using LLMs. Shadi Iskander, Nachshon Cohen, Zohar Karnin, Ori Shapira, Sofia Tolmach. EMNLP 2024.
- Voyager: An Open-Ended Embodied Agent with Large Language Models. Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar. TMLR 2024.
- Visual Instruction Tuning Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee. NeurIPS 2023.
- Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, Jingren Zhou. Arxiv 2023.
- G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model Jiahui Gao, Renjie Pi, Jipeng Zhang, Jiacheng Ye, Wanjun Zhong, Yufei Wang, Lanqing Hong, Jianhua Han, Hang Xu, Zhenguo Li, Lingpeng Kong. Sumit to ICLR 2025.
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny. ICLR 2024.
- Enhancing Large Vision Language Models with Self-Training on Image Comprehension Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, James Zou, Kai-Wei Chang, Wei Wang. NeurIPS 2024.
- LLaVA-OneVision: Easy Visual Task Transfer Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, Chunyuan Li. Submit to TMLR.
- MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents Liyan Tang, Philippe Laban, Greg Durrett. EMNLP 2024.
- Fine-tuning Language Models for Factuality Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D. Manning, Chelsea Finn. ICLR 2024.
- Prompt Public Large Language Models to Synthesize Data for Private On-device Applications. Shanshan Wu, Zheng Xu, Yanxiang Zhang, Yuanbo Zhang, Daniel Ramage. COLM 2024.
- Harnessing large-language models to generate private synthetic text. Alexey Kurakin, Natalia Ponomareva, Umar Syed, Liam MacDermed, Andreas Terzis. Arxiv 2024.
- Generative Design through Quality-Diversity Data Synthesis and Language Models. Adam Gaier, James Stoddart, Lorenzo Villaggi, Shyam Sudhakaran. GECCO 2024.
- SynthPAI: A Synthetic Dataset for Personal Attribute Inference Hanna Yukhymenko, Robin Staab, Mark Vero, Martin Vechev. NeurIPS D&B 2024.
- DataDreamer: A Tool for Synthetic Data Generation and Reproducible LLM Workflows. Ajay Patel, Colin Raffel, Chris Callison-Burch. ACL 2024.
- AgentInstruct: Toward Generative Teaching with Agentic Flows. Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei-ge Chen, Olga Vrousgos, Corby Rosset, Fillipe Silva, Hamed Khanpour, Yash Lara, Ahmed Awadallah. Arxiv 2024.
- Distilabel: An AI Feedback (AIF) Framework for Building Datasets with and for LLMs. Álvaro Bartolomé Del Canto, Gabriel Martín Blázquez, Agustín Piqueres Lajarín and Daniel Vila Suero. GitHub 2024.
- Fuxion: Synthetic Data Generation and Normalization Functions using Langchain + LLMs.
- Open Artificial Knowledge Vadim Borisov, Richard Schreiber. ICML Workshop 2024.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-Synthetic-Data
Similar Open Source Tools
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
awesome-ai-llm4education
The 'awesome-ai-llm4education' repository is a curated list of papers related to artificial intelligence (AI) and large language models (LLM) for education. It collects papers from top conferences, journals, and specialized domain-specific conferences, categorizing them based on specific tasks for better organization. The repository covers a wide range of topics including tutoring, personalized learning, assessment, material preparation, specific scenarios like computer science, language, math, and medicine, aided teaching, as well as datasets and benchmarks for educational research.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.

llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.
xgen
XGen is a research release for the family of XGen models (7B) by Salesforce AI Research. It includes models with support for different sequence lengths and tokenization using the OpenAI Tiktoken package. The models can be used for auto-regressive sampling in natural language generation tasks.
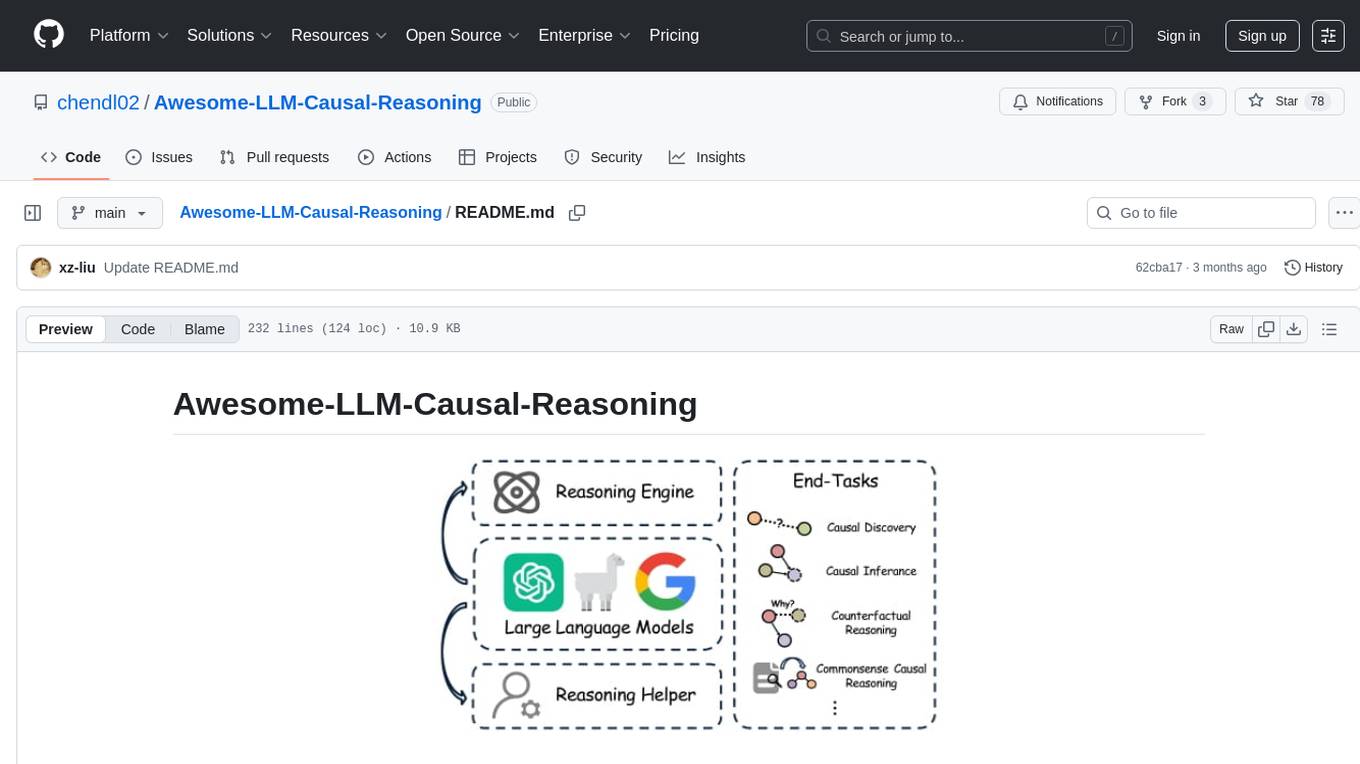
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
AI-PhD-S24
AI-PhD-S24 is a mono-repo for the PhD course 'AI for Business Research' at CUHK Business School in Spring 2024. The course aims to provide a basic understanding of machine learning and artificial intelligence concepts/methods used in business research, showcase how ML/AI is utilized in business research, and introduce state-of-the-art AI/ML technologies. The course includes scribed lecture notes, class recordings, and covers topics like AI/ML fundamentals, DL, NLP, CV, unsupervised learning, and diffusion models.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.

Awesome-LLM-Watermark
This repository contains a collection of research papers related to watermarking techniques for text and images, specifically focusing on large language models (LLMs). The papers cover various aspects of watermarking LLM-generated content, including robustness, statistical understanding, topic-based watermarks, quality-detection trade-offs, dual watermarks, watermark collision, and more. Researchers have explored different methods and frameworks for watermarking LLMs to protect intellectual property, detect machine-generated text, improve generation quality, and evaluate watermarking techniques. The repository serves as a valuable resource for those interested in the field of watermarking for LLMs.

SLAM-LLM
SLAM-LLM is a deep learning toolkit for training custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports various tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). Users can easily extend to new models and tasks, utilize mixed precision training for faster training with less GPU memory, and perform multi-GPU training with data and model parallelism. Configuration is flexible based on Hydra and dataclass, allowing different configuration methods.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
CodeGen
CodeGen is an official release of models for Program Synthesis by Salesforce AI Research. It includes CodeGen1 and CodeGen2 models with varying parameters. The latest version, CodeGen2.5, outperforms previous models. The tool is designed for code generation tasks using large language models trained on programming and natural languages. Users can access the models through the Hugging Face Hub and utilize them for program synthesis and infill sampling. The accompanying Jaxformer library provides support for data pre-processing, training, and fine-tuning of the CodeGen models.
AIRS
AIRS is a collection of open-source software tools, datasets, and benchmarks focused on Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. The goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources to advance the field of AI for Science. The current resources include tools for Quantum Mechanics, Density Functional Theory, Small Molecules, Protein Science, Materials Science, Molecular Interactions, and Partial Differential Equations.
For similar tasks
alignment-handbook
The Alignment Handbook provides robust training recipes for continuing pretraining and aligning language models with human and AI preferences. It includes techniques such as continued pretraining, supervised fine-tuning, reward modeling, rejection sampling, and direct preference optimization (DPO). The handbook aims to fill the gap in public resources on training these models, collecting data, and measuring metrics for optimal downstream performance.

Xwin-LM
Xwin-LM is a powerful and stable open-source tool for aligning large language models, offering various alignment technologies like supervised fine-tuning, reward models, reject sampling, and reinforcement learning from human feedback. It has achieved top rankings in benchmarks like AlpacaEval and surpassed GPT-4. The tool is continuously updated with new models and features.

Awesome-LLM-Preference-Learning
The repository 'Awesome-LLM-Preference-Learning' is the official repository of a survey paper titled 'Towards a Unified View of Preference Learning for Large Language Models: A Survey'. It contains a curated list of papers related to preference learning for Large Language Models (LLMs). The repository covers various aspects of preference learning, including on-policy and off-policy methods, feedback mechanisms, reward models, algorithms, evaluation techniques, and more. The papers included in the repository explore different approaches to aligning LLMs with human preferences, improving mathematical reasoning in LLMs, enhancing code generation, and optimizing language model performance.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
bench
Bench is a tool for evaluating LLMs for production use cases. It provides a standardized workflow for LLM evaluation with a common interface across tasks and use cases. Bench can be used to test whether open source LLMs can do as well as the top closed-source LLM API providers on specific data, and to translate the rankings on LLM leaderboards and benchmarks into scores that are relevant for actual use cases.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.