
llm-autoeval
Automatically evaluate your LLMs in Google Colab
Stars: 398
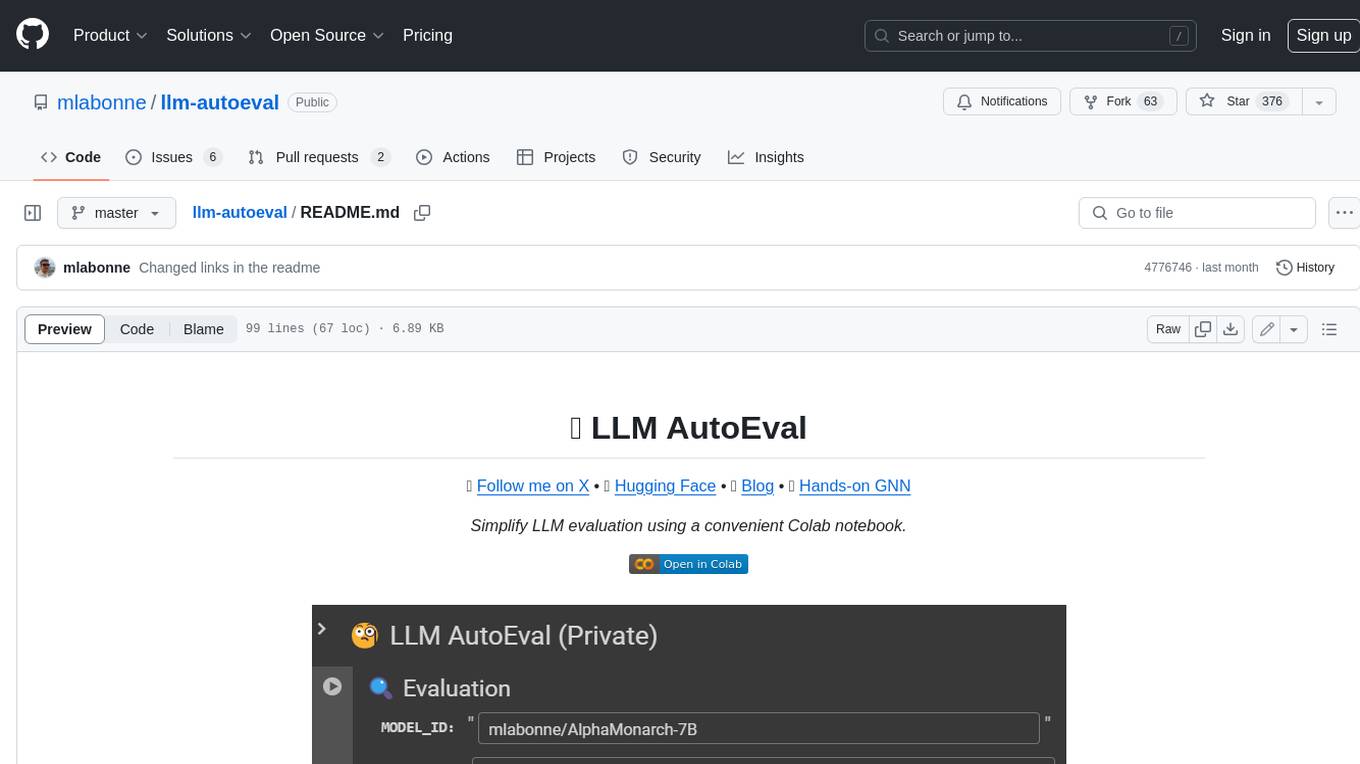
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.
README:
🐦 Follow me on X • 🤗 Hugging Face • 💻 Blog • 📙 Hands-on GNN
Simplify LLM evaluation using a convenient Colab notebook.


LLM AutoEval simplifies the process of evaluating LLMs using a convenient Colab notebook. You just need to specify the name of your model, a benchmark, a GPU, and press run!
- Automated setup and execution using RunPod.
- Customizable evaluation parameters for tailored benchmarking.
- Summary generation and upload to GitHub Gist for easy sharing and reference.
Note: This project is in the early stages and primarily designed for personal use. Use it carefully and feel free to contribute.
-
MODEL_ID: Enter the model id from Hugging Face. -
BENCHMARK:-
nous: List of tasks: AGIEval, GPT4ALL, TruthfulQA, and Bigbench (popularized by Teknium and NousResearch). This is recommended. -
lighteval: This is a new library from Hugging Face. It allows you to specify your tasks as shown in the readme. Check the list of recommended tasks to see what you can use (e.g., HELM, PIQA, GSM8K, MATH, etc.) -
openllm: List of tasks: ARC, HellaSwag, MMLU, Winogrande, GSM8K, and TruthfulQA (like the Open LLM Leaderboard). It uses the vllm implementation to enhance speed (note that the results will not be identical to those obtained without using vllm). "mmlu" is currently missing because of a problem with vllm.
-
-
LIGHTEVAL_TASK: You can select one or several tasks as specified in the readme or in the list of recommended tasks.
-
GPU: Select the GPU you want for evaluation (see prices here). I recommend using beefy GPUs (RTX 3090 or higher), especially for the Open LLM benchmark suite. -
Number of GPUs: Self-explanatory (more cost-efficient than bigger GPUs if you need more VRAM). -
CONTAINER_DISK: Size of the disk in GB. -
CLOUD_TYPE: RunPod offers a community cloud (cheaper) and a secure cloud (more reliable). -
REPO: If you made a fork of this repo, you can specify its URL here (the image only runsrunpod.sh). -
TRUST_REMOTE_CODE: Models like Phi require this flag to run them. -
PRIVATE_GIST: (W.I.P.) Make the Gist with the results private (true) or public (false). -
DEBUG: The pod will not be destroyed at the end of the run (not recommended).
Tokens use Colab's Secrets tab. Create two secrets called "runpod" and "github" and add the corresponding tokens you can find as follows:
-
RUNPOD_TOKEN: Please consider using my referral link if you don't have an account yet. You can create your token here under "API keys" (read & write permission). You'll also need to transfer some money there to start a pod. -
GITHUB_TOKEN: You can create your token here (read & write, can be restricted to "gist" only). -
HF_TOKEN: Optional. You can find your Hugging Face token here if you have an account.
You can compare your results with:
- YALL - Yet Another LLM Leaderboard, my leaderboard made with the gists produced by LLM AutoEval.
- Models like OpenHermes-2.5-Mistral-7B, Nous-Hermes-2-SOLAR-10.7B, or Nous-Hermes-2-Yi-34B.
- Teknium stores his evaluations in his LLM-Benchmark-Logs.
You can compare your results on a case-by-case basis, depending on the tasks you have selected.
You can compare your results with those listed on the Open LLM Leaderboard.
I use the summaries produced by LLM AutoEval to created YALL - Yet Another LLM Leaderboard with plots as follows:
Let me know if you're interested in creating your own leaderboard with your gists in one click. This can be easily converted into a small notebook to create this space.
- "Error: File does not exist": This task didn't produce the JSON file that is parsed for the summary. Activate debug mode and rerun the evaluation to inspect the issue in the logs.
- "700 Killed" Error: The hardware is not powerful enough for the evaluation. This happens when you try to run the Open LLM benchmark suite on an RTX 3070 for example.
- Outdated CUDA Drivers: That's unlucky. You'll need to start a new pod in this case.
- "triu_tril_cuda_template" not implemented for 'BFloat16': Switch the image as explained in this issue.
Special thanks to burtenshaw for integrating lighteval, EleutherAI for the lm-evaluation-harness, dmahan93 for his fork that adds agieval to the lm-evaluation-harness, Hugging Face for the lighteval library, NousResearch and Teknium for the Nous benchmark suite, and vllm for the additional inference speed.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-autoeval
Similar Open Source Tools
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together
uxie
Uxie is a PDF reader app designed to revolutionize the learning experience. It offers features such as annotation, note-taking, collaboration tools, integration with LLM for enhanced learning, and flashcard generation with LLM feedback. Built using Nextjs, tRPC, Zod, TypeScript, Tailwind CSS, React Query, React Hook Form, Supabase, Prisma, and various other tools. Users can take notes, summarize PDFs, chat and collaborate with others, create custom blocks in the editor, and use AI-powered text autocompletion. The tool allows users to craft simple flashcards, test knowledge, answer questions, and receive instant feedback through AI evaluation.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
WDoc
WDoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It supports querying tens of thousands of documents simultaneously, offers tailored summaries to efficiently manage large amounts of information, and includes features like supporting multiple file types, various LLMs, local and private LLMs, advanced RAG capabilities, advanced summaries, trust verification, markdown formatted answers, sophisticated embeddings, extensive documentation, scriptability, type checking, lazy imports, caching, fast processing, shell autocompletion, notification callbacks, and more. WDoc is ideal for researchers, students, and professionals dealing with extensive information sources.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.
merlinn
Merlinn is an open-source AI-powered on-call engineer that automatically jumps into incidents & alerts, providing useful insights and RCA in real time. It integrates with popular observability tools, lives inside Slack, offers an intuitive UX, and prioritizes security. Users can self-host Merlinn, use it for free, and benefit from automatic RCA, Slack integration, integrations with various tools, intuitive UX, and security features.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
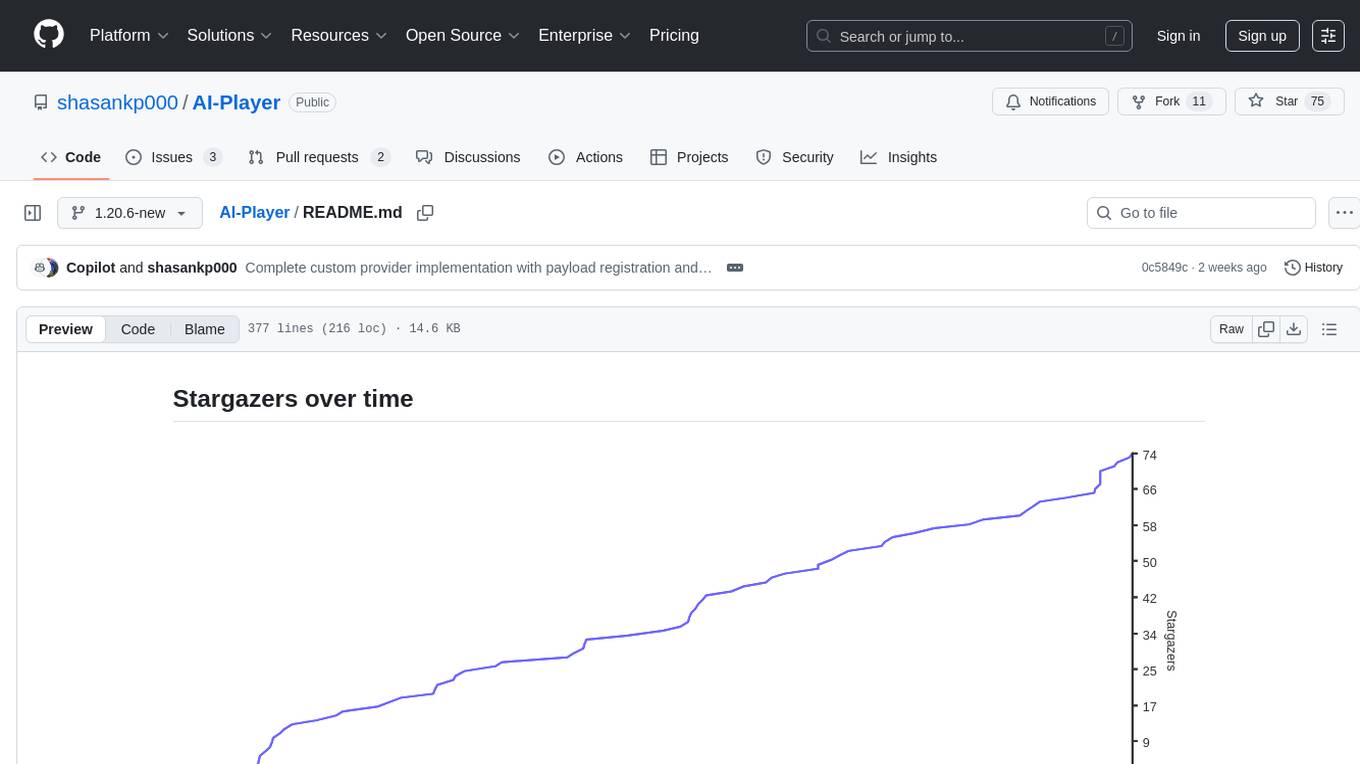
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.
hal-9100
This repository is now archived and the code is privately maintained. If you are interested in this infrastructure, please contact the maintainer directly.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.
For similar tasks
deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
bench
Bench is a tool for evaluating LLMs for production use cases. It provides a standardized workflow for LLM evaluation with a common interface across tasks and use cases. Bench can be used to test whether open source LLMs can do as well as the top closed-source LLM API providers on specific data, and to translate the rankings on LLM leaderboards and benchmarks into scores that are relevant for actual use cases.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
llm-autoeval
LLM AutoEval is a tool that simplifies the process of evaluating Large Language Models (LLMs) using a convenient Colab notebook. It automates the setup and execution of evaluations using RunPod, allowing users to customize evaluation parameters and generate summaries that can be uploaded to GitHub Gist for easy sharing and reference. LLM AutoEval supports various benchmark suites, including Nous, Lighteval, and Open LLM, enabling users to compare their results with existing models and leaderboards.

moonshot
Moonshot is a simple and modular tool developed by the AI Verify Foundation to evaluate Language Model Models (LLMs) and LLM applications. It brings Benchmarking and Red-Teaming together to assist AI developers, compliance teams, and AI system owners in assessing LLM performance. Moonshot can be accessed through various interfaces including User-friendly Web UI, Interactive Command Line Interface, and seamless integration into MLOps workflows via Library APIs or Web APIs. It offers features like benchmarking LLMs from popular model providers, running relevant tests, creating custom cookbooks and recipes, and automating Red Teaming to identify vulnerabilities in AI systems.

llm_client
llm_client is a Rust interface designed for Local Large Language Models (LLMs) that offers automated build support for CPU, CUDA, MacOS, easy model presets, and a novel cascading prompt workflow for controlled generation. It provides a breadth of configuration options and API support for various OpenAI compatible APIs. The tool is primarily focused on deterministic signals from probabilistic LLM vibes, enabling specialized workflows for specific tasks and reproducible outcomes.
LLM-Synthetic-Data
LLM-Synthetic-Data is a repository focused on real-time, fine-grained LLM-Synthetic-Data generation. It includes methods, surveys, and application areas related to synthetic data for language models. The repository covers topics like pre-training, instruction tuning, model collapse, LLM benchmarking, evaluation, and distillation. It also explores application areas such as mathematical reasoning, code generation, text-to-SQL, alignment, reward modeling, long context, weak-to-strong generalization, agent and tool use, vision and language, factuality, federated learning, generative design, and safety.
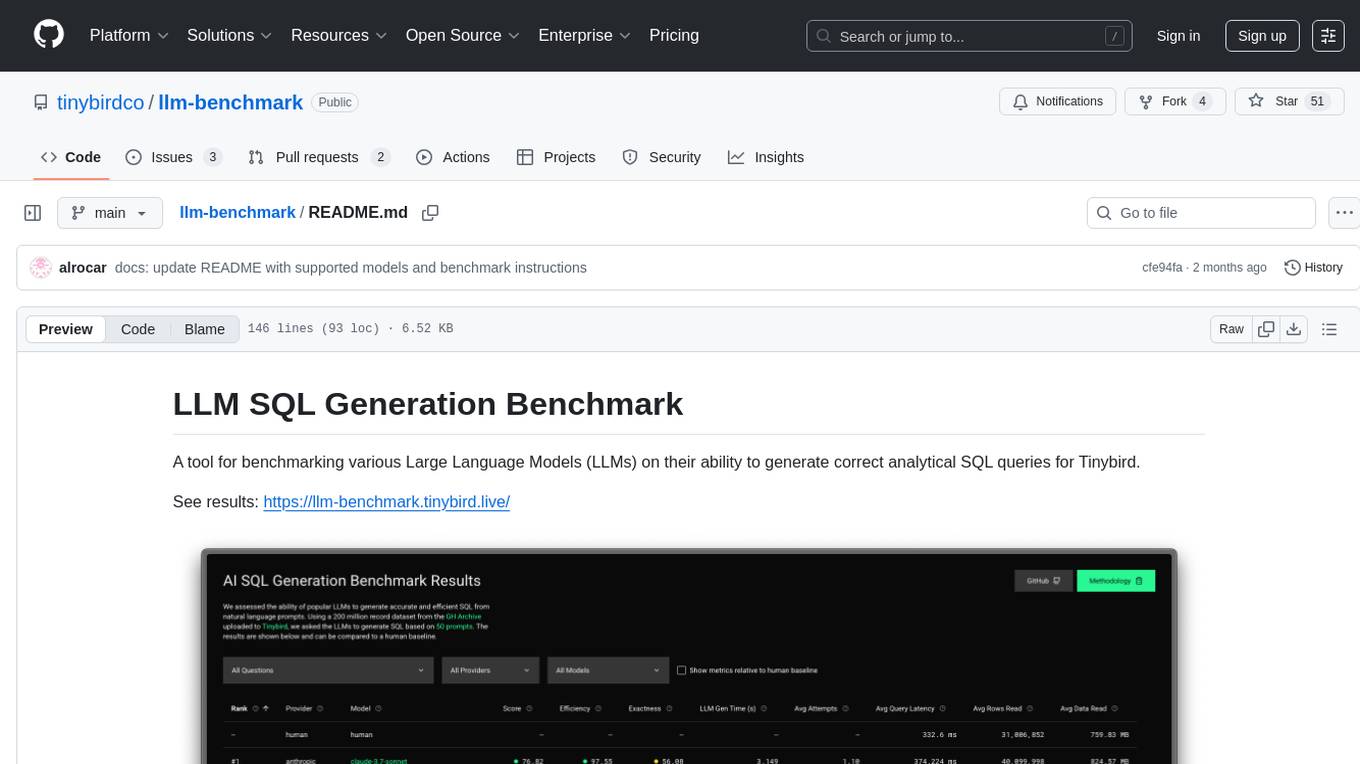
llm-benchmark
LLM SQL Generation Benchmark is a tool for evaluating different Large Language Models (LLMs) on their ability to generate accurate analytical SQL queries for Tinybird. It measures SQL query correctness, execution success, performance metrics, error handling, and recovery. The benchmark includes an automated retry mechanism for error correction. It supports various providers and models through OpenRouter and can be extended to other models. The benchmark is based on a GitHub dataset with 200M rows, where each LLM must produce SQL from 50 natural language prompts. Results are stored in JSON files and presented in a web application. Users can benchmark new models by following provided instructions.
For similar jobs

LLM-FineTuning-Large-Language-Models
This repository contains projects and notes on common practical techniques for fine-tuning Large Language Models (LLMs). It includes fine-tuning LLM notebooks, Colab links, LLM techniques and utils, and other smaller language models. The repository also provides links to YouTube videos explaining the concepts and techniques discussed in the notebooks.

lloco
LLoCO is a technique that learns documents offline through context compression and in-domain parameter-efficient finetuning using LoRA, which enables LLMs to handle long context efficiently.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
llm-baselines
LLM-baselines is a modular codebase to experiment with transformers, inspired from NanoGPT. It provides a quick and easy way to train and evaluate transformer models on a variety of datasets. The codebase is well-documented and easy to use, making it a great resource for researchers and practitioners alike.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
EvalAI
EvalAI is an open-source platform for evaluating and comparing machine learning (ML) and artificial intelligence (AI) algorithms at scale. It provides a central leaderboard and submission interface, making it easier for researchers to reproduce results mentioned in papers and perform reliable & accurate quantitative analysis. EvalAI also offers features such as custom evaluation protocols and phases, remote evaluation, evaluation inside environments, CLI support, portability, and faster evaluation.
Weekly-Top-LLM-Papers
This repository provides a curated list of weekly published Large Language Model (LLM) papers. It includes top important LLM papers for each week, organized by month and year. The papers are categorized into different time periods, making it easy to find the most recent and relevant research in the field of LLM.
self-llm
This project is a Chinese tutorial for domestic beginners based on the AutoDL platform, providing full-process guidance for various open-source large models, including environment configuration, local deployment, and efficient fine-tuning. It simplifies the deployment, use, and application process of open-source large models, enabling more ordinary students and researchers to better use open-source large models and helping open and free large models integrate into the lives of ordinary learners faster.