
transcriptionstream
turnkey self-hosted offline transcription and diarization service with llm summary
Stars: 74
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
README:
Created by https://transcription.stream with special thanks to MahmoudAshraf97 and his work on whisper-diarization, and to jmorganca for Ollama and its amazing simplicity in use.
Transcription Stream is a turnkey self-hosted diarization service that works completely offline. Out of the box it includes:
- drag and drop diarization and transcription via SSH
- a web interface for upload, review, and download of files
- summarization with Ollama and Mistral
- Meilisearch for full text search
A web interface and SSH drop zones make this simple to use and implement into your workflows. Ollama allows for a powerful toolset, limited only by your prompt skills, to perform complex operations on your transcriptions. Meiliesearch adds ridiculously fast full text search.
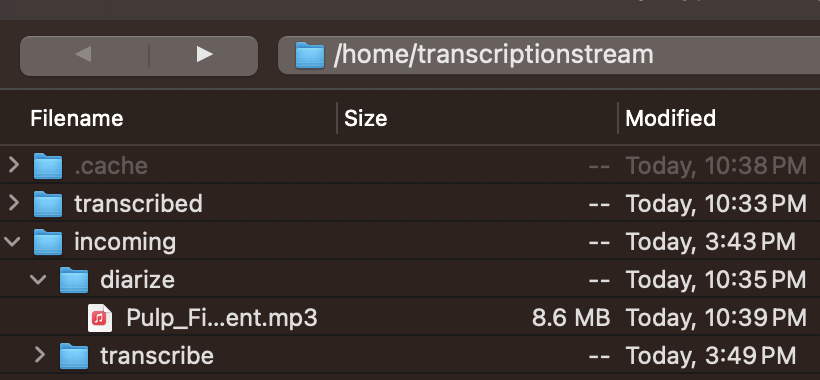
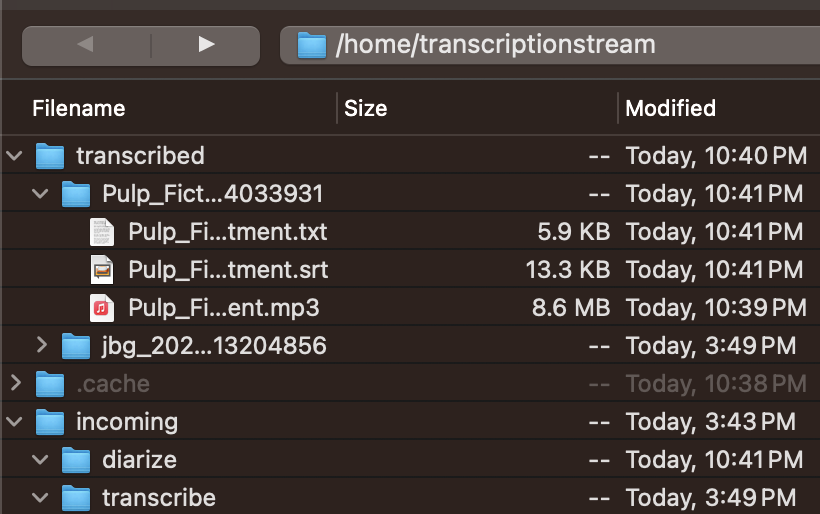
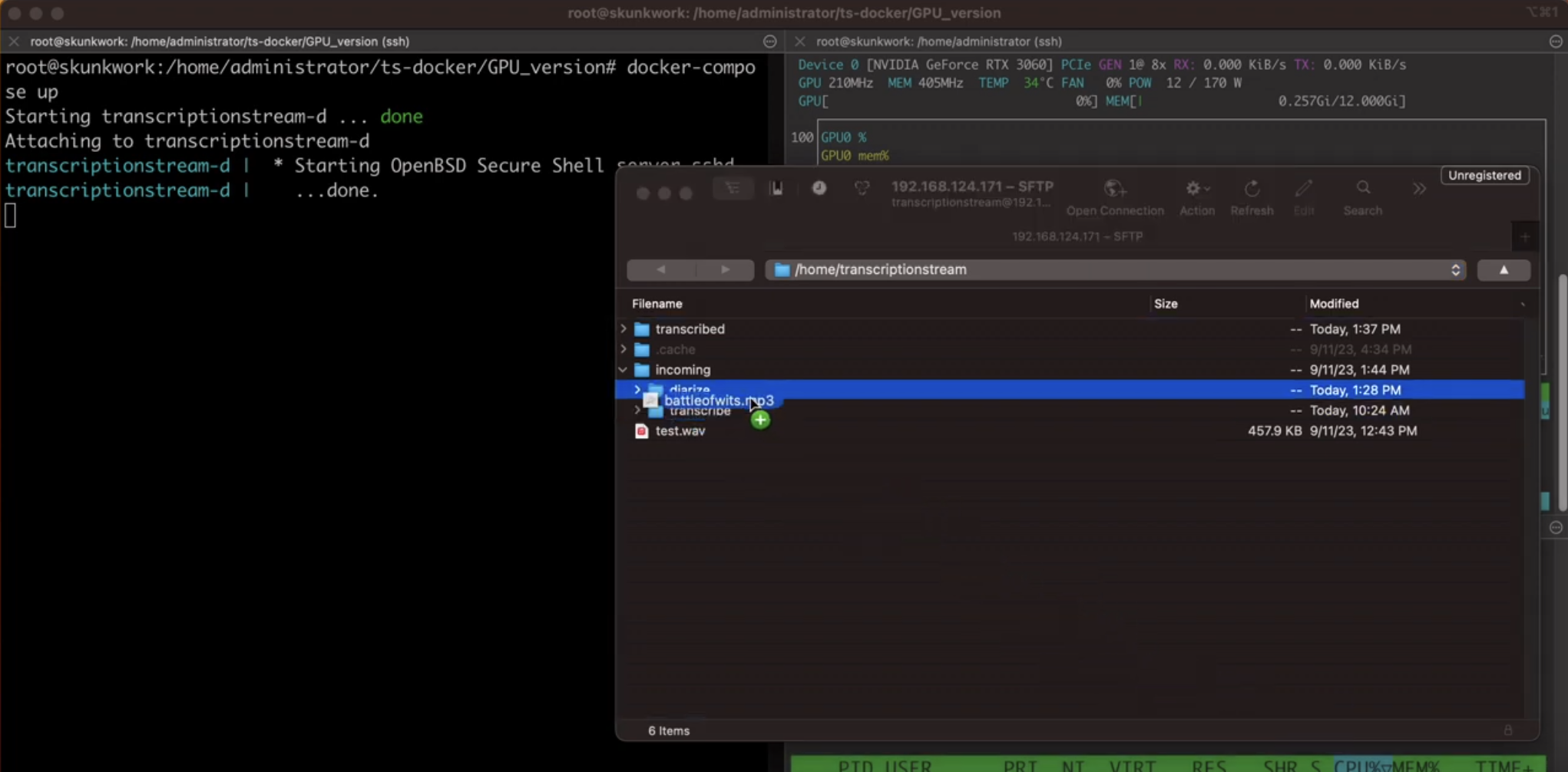
Use the web interface to upload, listen to, review, and download output files, or drop files via SSH into transcribe or diarize. Files are processed with output placed into a named and dated folder. Have a quick look at the install and ts-web walkthrough videos for a better idea.

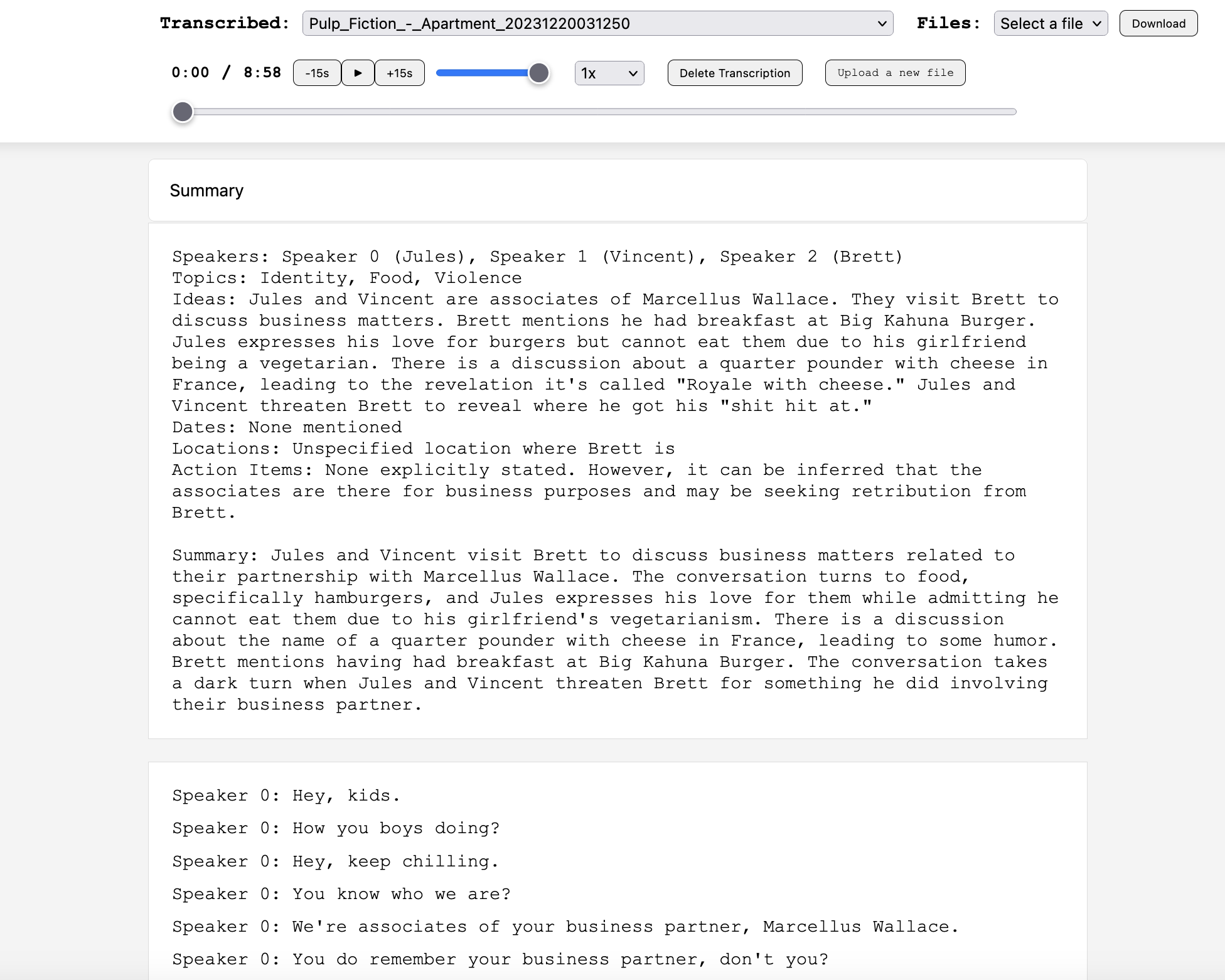
prompt_text = f"""
Summarize the transcription below. Be sure to include pertinent information about the speakers, including name and anything else shared.
Provide the summary output in the following style
Speakers: names or identifiers of speaking parties
Topics: topics included in the transcription
Ideas: any ideas that may have been mentioned
Dates: dates mentioned and what they correspond to
Locations: any locations mentioned
Action Items: any action items
Summary: overall summary of the transcription
The transcription is as follows
{transcription_text}
"""
Prerequisite: NVIDIA GPU
Warning: The resulting ts-gpu image is ~26GB and might take a hot second to create
./start-nobuild.shIf you'd like to build the images locally
chmod +x install.sh;
./install.sh;chmod +x run.sh;
./run.sh- SSH: 22222
- HTTP: 5006
- Ollama: 11434
- Meilisearch: 7700
- Port: 22222
-
User:
transcriptionstream -
Password:
nomoresaastax -
Usage: Place audio files in
transcribeordiarize. Completed files are stored intranscribed.
- URL: http://dockerip:5006
-
Features:
- Audio file upload/download
- Task completion alerts with interactive links
- HTML5 web player with speed control and transcription highlighting
- Time-synced transcription scrubbing/highlighting/scrolling
- URL: http://dockerip:11434
- change the prompt used, in
/ts-gpu/ts-summarize.py
- URL: http://dockerip:7700
Warning: This is example code for example purposes and should not be used in production environments without additional security measures.
- Update variables in the .env file
- Change the password for
transcriptionstreamin thets-gpuDockerfile. - Update the Ollama api endpoint IP in .env if you want to use a different endpoint
- Update the secret in .env for ts-web
- Use .env to choose which models are included in the initial build.
- Change the prompt text in ts-gpu/ts-summarize.py to fit your needs. Update ts-web/templates/transcription.html if you want to call it something other than summary.
- 12GB of vram may not be enough to run both whisper-diarization and ollama mistral. Whisper-diarization is fairly light on gpu memory out of the box, but Ollama's runner holds enough gpu memory open causing the diarization/transcription to run our of CUDA memory on occasion. Since I can't run both on the same host reliably, I've set the batch size for both whisper-diarization and whisperx to 16, from their default 8, and let a m series mac run the Ollama endpoint.
- Need to fix an issue with ts-web that throws an error to console when loading a transcription when a summary.txt file does not also exist. Lots of other annoyances with ts-web, but it's functional.
- Need to add a search/control interface to ts-web for Meilisearch
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for transcriptionstream
Similar Open Source Tools
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
SecureAI-Tools
SecureAI Tools is a private and secure AI tool that allows users to chat with AI models, chat with documents (PDFs), and run AI models locally. It comes with built-in authentication and user management, making it suitable for family members or coworkers. The tool is self-hosting optimized and provides necessary scripts and docker-compose files for easy setup in under 5 minutes. Users can customize the tool by editing the .env file and enabling GPU support for faster inference. SecureAI Tools also supports remote OpenAI-compatible APIs, with lower hardware requirements for using remote APIs only. The tool's features wishlist includes chat sharing, mobile-friendly UI, and support for more file types and markdown rendering.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.

langmanus
LangManus is a community-driven AI automation framework that combines language models with specialized tools for tasks like web search, crawling, and Python code execution. It implements a hierarchical multi-agent system with agents like Coordinator, Planner, Supervisor, Researcher, Coder, Browser, and Reporter. The framework supports LLM integration, search and retrieval tools, Python integration, workflow management, and visualization. LangManus aims to give back to the open-source community and welcomes contributions in various forms.
nextjs-ollama-llm-ui
This web interface provides a user-friendly and feature-rich platform for interacting with Ollama Large Language Models (LLMs). It offers a beautiful and intuitive UI inspired by ChatGPT, making it easy for users to get started with LLMs. The interface is fully local, storing chats in local storage for convenience, and fully responsive, allowing users to chat on their phones with the same ease as on a desktop. It features easy setup, code syntax highlighting, and the ability to easily copy codeblocks. Users can also download, pull, and delete models directly from the interface, and switch between models quickly. Chat history is saved and easily accessible, and users can choose between light and dark mode. To use the web interface, users must have Ollama downloaded and running, and Node.js (18+) and npm installed. Installation instructions are provided for running the interface locally. Upcoming features include the ability to send images in prompts, regenerate responses, import and export chats, and add voice input support.

DevDocs
DevDocs is a platform designed to simplify the process of digesting technical documentation for software engineers and developers. It automates the extraction and conversion of web content into markdown format, making it easier for users to access and understand the information. By crawling through child pages of a given URL, DevDocs provides a streamlined approach to gathering relevant data and integrating it into various tools for software development. The tool aims to save time and effort by eliminating the need for manual research and content extraction, ultimately enhancing productivity and efficiency in the development process.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

Director
Director is a framework to build video agents that can reason through complex video tasks like search, editing, compilation, generation, etc. It enables users to summarize videos, search for specific moments, create clips instantly, integrate GenAI projects and APIs, add overlays, generate thumbnails, and more. Built on VideoDB's 'video-as-data' infrastructure, Director is perfect for developers, creators, and teams looking to simplify media workflows and unlock new possibilities.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.
echokit_server
Echokit_server is a lightweight and efficient server-side implementation of the Amazon Alexa Voice Service (AVS) SDK. It allows developers to easily integrate Alexa voice capabilities into their own applications or devices. The server handles the communication with the Alexa Voice Service API, manages user interactions, and processes voice commands. Echokit_server provides a simple and flexible solution for adding voice-controlled features to a wide range of projects, such as smart home devices, IoT applications, and voice-enabled services.
sd-webui-agent-scheduler
AgentScheduler is an Automatic/Vladmandic Stable Diffusion Web UI extension designed to enhance image generation workflows. It allows users to enqueue prompts, settings, and controlnets, manage queued tasks, prioritize, pause, resume, and delete tasks, view generation results, and more. The extension offers hidden features like queuing checkpoints, editing queued tasks, and custom checkpoint selection. Users can access the functionality through HTTP APIs and API callbacks. Troubleshooting steps are provided for common errors. The extension is compatible with latest versions of A1111 and Vladmandic. It is licensed under Apache License 2.0.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.
mobile-use
Mobile-use is an open-source AI agent that controls Android or IOS devices using natural language. It understands commands to perform tasks like sending messages and navigating apps. Features include natural language control, UI-aware automation, data scraping, and extensibility. Users can automate their mobile experience by setting up environment variables, customizing LLM configurations, and launching the tool via Docker or manually for development. The tool supports physical Android phones, Android simulators, and iOS simulators. Contributions are welcome, and the project is licensed under MIT.
your-source-to-prompt.html
Your Source to Prompt is a single HTML file tool that allows users to easily select code files and combine them into a single text output. It runs entirely in the browser, ensuring local and secure operation without any external dependencies. The tool offers features like preset management, efficient file selection, context size awareness, hierarchical structure preview, minification, and user-friendly UI with dark mode. It aims to simplify the process of preparing code for Large Language Models (LLMs) by providing a well-structured prompt context.
ImageIndexer
LLMII is a tool that uses a local AI model to label metadata and index images without relying on cloud services or remote APIs. It runs a visual language model on your computer to generate captions and keywords for images, enhancing their metadata for indexing, searching, and organization. The tool can be run multiple times on the same image files, allowing for adding new data, regenerating data, and discovering files with issues. It supports various image formats, offers a user-friendly GUI, and can utilize GPU acceleration for faster processing. LLMII requires Python 3.8 or higher and operates directly on image file metadata fields like MWG:Keyword and XMP:Identifier.
For similar tasks

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.
Mindolph
Mindolph is an open source personal knowledge management software for all desktop platforms. It allows users to create and manage their own files in separate workspaces with saving in their local storage, organize their files as a tree in their workspaces, and have multiple tabs for opening files instead of a single file window. Mindolph supports Mind Map, Markdown, PlantUML, CSV sheet, and plain text file formats. It also has features such as quickly navigating to files and searching text in files under a specific folder, editing mind maps easily and quickly with key shortcuts, supporting themes and providing some pre-defined themes, importing from other mind map formats, and exporting to other file formats.

Warp
Warp is a blazingly-fast modern Rust based GPU-accelerated terminal built to make you and your team more productive. It is available for macOS and Linux users, with plans to support Windows and the Web (WASM) in the future. Warp has a community search page where you can find solutions to common issues, and you can file issue requests in the repo if you can't find a solution. Warp is open-source, and the team is planning to first open-source their Rust UI framework, and then parts and potentially all of their client codebase.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
gptscript
GPTScript is a framework that enables Large Language Models (LLMs) to interact with various systems, including local executables, applications with OpenAPI schemas, SDK libraries, or RAG-based solutions. It simplifies the integration of systems with LLMs using minimal prompts. Sample use cases include chatting with a local CLI, OpenAPI compliant endpoint, local files/directories, and running automated workflows.
llm2sh
llm2sh is a command-line utility that leverages Large Language Models (LLMs) to translate plain-language requests into shell commands. It provides a convenient way to interact with your system using natural language. The tool supports multiple LLMs for command generation, offers a customizable configuration file, YOLO mode for running commands without confirmation, and is easily extensible with new LLMs and system prompts. Users can set up API keys for OpenAI, Claude, Groq, and Cerebras to use the tool effectively. llm2sh does not store user data or command history, and it does not record or send telemetry by itself, but the LLM APIs may collect and store requests and responses for their purposes.
dwata
dwata is an open source desktop app designed to manage all your private data on your laptop, providing offline access, fast search capabilities, and organization features for emails, files, contacts, events, and tasks. It aims to reduce cognitive overhead in daily digital life by offering a centralized platform for personal data management. The tool prioritizes user privacy, with no data being sent outside the user's computer without explicit permission. dwata is still in early development stages and offers integration with AI providers for advanced functionalities.
For similar jobs

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
alexandria-audiobook
Alexandria Audiobook Generator is a tool that transforms any book or novel into a fully-voiced audiobook using AI-powered script annotation and text-to-speech. It features a built-in Qwen3-TTS engine with batch processing and a browser-based editor for fine-tuning every line before final export. The tool offers AI-powered pipeline for automatic script annotation, smart chunking, and context preservation. It also provides voice generation capabilities with built-in TTS engine, multi-language support, custom voices, voice cloning, and LoRA voice training. The web UI editor allows users to edit, preview, and export the audiobook. Export options include combined audiobook, individual voicelines, and Audacity export for DAW editing.

unpod
Unpod is a lightweight and easy-to-use tool for extracting audio from video files. It allows users to quickly and efficiently separate audio tracks from video content without the need for complex software or technical knowledge. With Unpod, users can easily extract audio for various purposes such as creating podcasts, remixing music, or enhancing video content with custom soundtracks. The tool supports a wide range of video formats and provides a simple interface for selecting and extracting audio tracks with just a few clicks. Unpod is a versatile solution for anyone looking to work with audio extracted from video files in a hassle-free manner.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.