
llm-answer-engine
Build a Perplexity-Inspired Answer Engine Using Next.js, Groq, Llama-3, Langchain, OpenAI, Upstash, Brave & Serper
Stars: 4497

This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.
README:
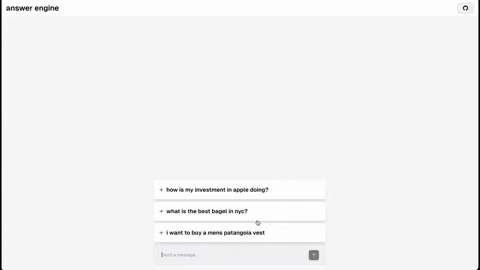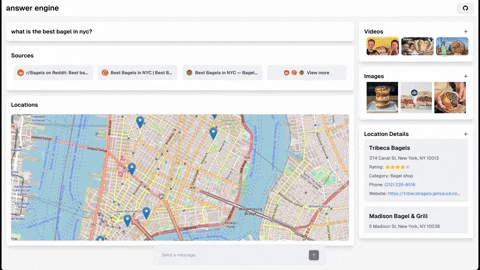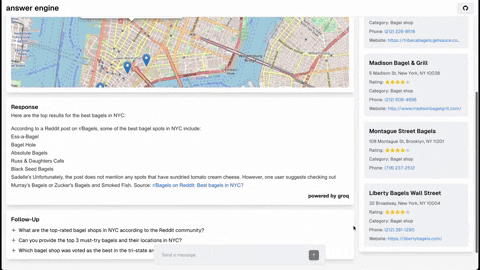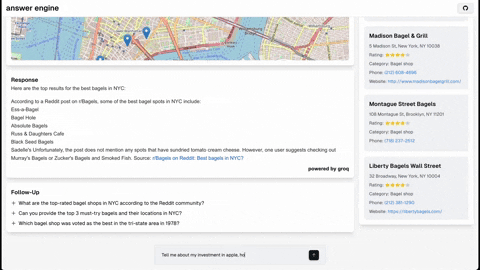
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.




- Next.js: A React framework for building server-side rendered and static web applications.
- Tailwind CSS: A utility-first CSS framework for rapidly building custom user interfaces.
- Vercel AI SDK: The Vercel AI SDK is a library for building AI-powered streaming text and chat UIs.
- Groq & Mixtral: Technologies for processing and understanding user queries.
- Langchain.JS: A JavaScript library focused on text operations, such as text splitting and embeddings.
- Brave Search: A privacy-focused search engine used for sourcing relevant content and images.
- Serper API: Used for fetching relevant video and image results based on the user's query.
- OpenAI Embeddings: Used for creating vector representations of text chunks.
- Cheerio: Utilized for HTML parsing, allowing the extraction of content from web pages.
- Ollama (Optional): Used for streaming inference and embeddings.
- Upstash Redis Rate Limiting (Optional): Used for setting up rate limiting for the application.
- Upstash Semantic Cache (Optional): Used for caching data for faster response times.
- Ensure Node.js and npm are installed on your machine.
- Obtain API keys from OpenAI, Groq, Brave Search, and Serper.
- OpenAI API Key: Generate your OpenAI API key here.
- Groq API Key: Get your Groq API key here.
- Brave Search API Key: Obtain your Brave Search API key here.
- Serper API Key: Get your Serper API key here.
- Clone the repository:
git clone https://github.com/developersdigest/llm-answer-engine.git - Install the required dependencies:
ornpm installbun install - Create a
.envfile in the root of your project and add your API keys:OPENAI_API_KEY=your_openai_api_key GROQ_API_KEY=your_groq_api_key BRAVE_SEARCH_API_KEY=your_brave_search_api_key SERPER_API=your_serper_api_key
To start the server, execute:
npm run dev
or
bun run dev
the server will be listening on the specified port.
The configuration file is located in the app/config.tsx file. You can modify the following values
- useOllamaInference: false,
- useOllamaEmbeddings: false,
- inferenceModel: 'mixtral-8x7b-32768',
- inferenceAPIKey: process.env.GROQ_API_KEY,
- embeddingsModel: 'text-embedding-3-small',
- textChunkSize: 800,
- textChunkOverlap: 200,
- numberOfSimilarityResults: 2,
- numberOfPagesToScan: 10,
- nonOllamaBaseURL: 'https://api.groq.com/openai/v1'
- useFunctionCalling: true
- useRateLimiting: false
- useSemanticCache: false
- usePortkey: false
Currently, function calling is supported with the following capabilities:
- Maps and Locations (Serper Locations API)
- Shopping (Serper Shopping API)
- TradingView Stock Data (Free Widget)
- Spotify (Free API)
- Any functionality that you would like to see here, please open an issue or submit a PR.
- To enable function calling and conditional streaming UI (currently in beta), ensure useFunctionCalling is set to true in the config file.
Currently, streaming text responses are supported for Ollama, but follow-up questions are not yet supported.
Embeddings are supported, however, time-to-first-token can be quite long when using both a local embedding model as well as a local model for the streaming inference. I recommended decreasing a number of the RAG values specified in the app/config.tsx file to decrease the time-to-first-token when using Ollama.
To get started, make sure you have the Ollama running model on your local machine and set within the config the model you would like to use and set use OllamaInference and/or useOllamaEmbeddings to true.
Note: When 'useOllamaInference' is set to true, the model will be used for both text generation, but it will skip the follow-up questions inference step when using Ollama.
More info: https://ollama.com/blog/openai-compatibility
- [] Add document upload + RAG for document search/retrieval
- [] Add a settings component to allow users to select the model, embeddings model, and other parameters from the UI
- [] Add support for follow-up questions when using Ollama
- [Complete] Add support diffusion models (Fal.AI SD3 to start), accessible via '@ mention'
- [Complete] Add AI Gateway to support multiple models and embeddings. (OpenAI, Azure OpenAI, Anyscale, Google Gemini & Palm, Anthropic, Cohere, Together AI, Perplexity, Mistral, Nomic, AI21, Stability AI, DeepInfra, Ollama, etc)
https://github.com/Portkey-AI/gateway - [Complete] Add support for semantic caching to improve response times
- [Complete] Add support for dynamic and conditionally rendered UI components based on the user's query
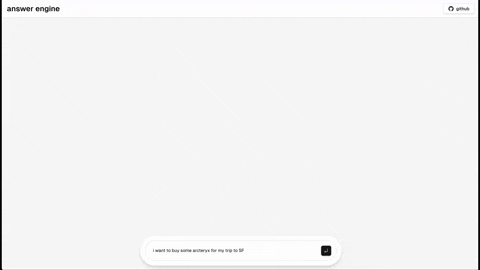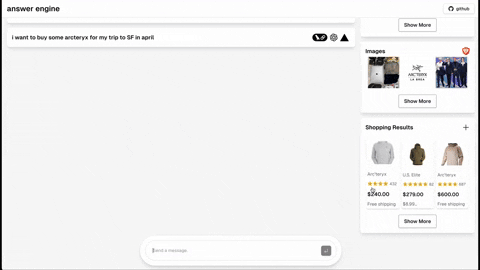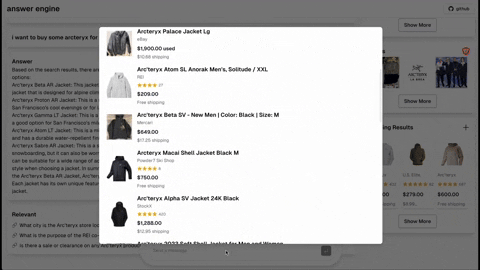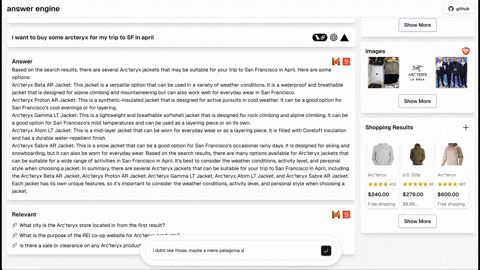
- [Completed] Add dark mode support based on the user's system preference
Watch the express tutorial here for a detailed guide on setting up and running this project. In addition to the Next.JS version of the project, there is a backend only version that uses Node.js and Express. Which is located in the 'express-api' directory. This is a standalone version of the project that can be used as a reference for building a similar API. There is also a readme file in the 'express-api' directory that explains how to run the backend version.
Watch the Upstash Redis Rate Limiting tutorial here for a detailed guide on setting up and running this project. Upstash Redis Rate Limiting is a free tier service that allows you to set up rate limiting for your application. It provides a simple and easy-to-use interface for configuring and managing rate limits. With Upstash, you can easily set limits on the number of requests per user, IP address, or other criteria. This can help prevent abuse and ensure that your application is not overwhelmed with requests.
Contributions to the project are welcome. Feel free to fork the repository, make your changes, and submit a pull request. You can also open issues to suggest improvements or report bugs.
This project is licensed under the MIT License.
I'm the developer behind Developers Digest. If you find my work helpful or enjoy what I do, consider supporting me. Here are a few ways you can do that:
- Patreon: Support me on Patreon at patreon.com/DevelopersDigest
- Buy Me A Coffee: You can buy me a coffee at buymeacoffee.com/developersdigest
- Website: Check out my website at developersdigest.tech
- Github: Follow me on GitHub at github.com/developersdigest
- Twitter: Follow me on Twitter at twitter.com/dev__digest
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for llm-answer-engine
Similar Open Source Tools
llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

comfyui_LLM_Polymath
LLM Polymath Chat Node is an advanced Chat Node for ComfyUI that integrates large language models to build text-driven applications and automate data processes, enhancing prompt responses by incorporating real-time web search, linked content extraction, and custom agent instructions. It supports both OpenAI’s GPT-like models and alternative models served via a local Ollama API. The core functionalities include Comfy Node Finder and Smart Assistant, along with additional agents like Flux Prompter, Custom Instructors, Python debugger, and scripter. The tool offers features for prompt processing, web search integration, model & API integration, custom instructions, image handling, logging & debugging, output compression, and more.
gemini-android
Gemini Android is a repository showcasing Google's Generative AI on Android using Stream Chat SDK for Compose. It demonstrates the Gemini API for Android, implements UI elements with Jetpack Compose, utilizes Android architecture components like Hilt and AppStartup, performs background tasks with Kotlin Coroutines, and integrates chat systems with Stream Chat Compose SDK for real-time event handling. The project also provides technical content, instructions on building the project, tech stack details, architecture overview, modularization strategies, and a contribution guideline. It follows Google's official architecture guidance and offers a real-world example of app architecture implementation.
ai-chat-android
AI Chat Android demonstrates Google's Generative AI on Android with Firebase Realtime Database. It showcases Gemini API integration, Jetpack Compose UI elements, Android architecture components with Hilt, Kotlin Coroutines for background tasks, and Firebase Realtime Database integration for real-time events. The project follows Google's official architecture guidance with a modularized structure for reusability, parallel building, and decentralized focusing.

kollektiv
Kollektiv is a Retrieval-Augmented Generation (RAG) system designed to enable users to chat with their favorite documentation easily. It aims to provide LLMs with access to the most up-to-date knowledge, reducing inaccuracies and improving productivity. The system utilizes intelligent web crawling, advanced document processing, vector search, multi-query expansion, smart re-ranking, AI-powered responses, and dynamic system prompts. The technical stack includes Python/FastAPI for backend, Supabase, ChromaDB, and Redis for storage, OpenAI and Anthropic Claude 3.5 Sonnet for AI/ML, and Chainlit for UI. Kollektiv is licensed under a modified version of the Apache License 2.0, allowing free use for non-commercial purposes.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.
AiTextDetectionBypass
ParaGenie is a script designed to automate the process of paraphrasing articles using the undetectable.ai platform. It allows users to convert lengthy content into unique paraphrased versions by splitting the input text into manageable chunks and processing each chunk individually. The script offers features such as automated paraphrasing, multi-file support for TXT, DOCX, and PDF formats, customizable chunk splitting methods, Gmail-based registration for seamless paraphrasing, purpose-specific writing support, readability level customization, anonymity features for user privacy, error handling and recovery, and output management for easy access and organization of paraphrased content.
code2prompt
code2prompt is a command-line tool that converts your codebase into a single LLM prompt with a source tree, prompt templating, and token counting. It automates generating LLM prompts from codebases of any size, customizing prompt generation with Handlebars templates, respecting .gitignore, filtering and excluding files using glob patterns, displaying token count, including Git diff output, copying prompt to clipboard, saving prompt to an output file, excluding files and folders, adding line numbers to source code blocks, and more. It helps streamline the process of creating LLM prompts for code analysis, generation, and other tasks.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.
WritingTools
Writing Tools is an Apple Intelligence-inspired application for Windows, Linux, and macOS that supercharges your writing with an AI LLM. It allows users to instantly proofread, optimize text, and summarize content from webpages, YouTube videos, documents, etc. The tool is privacy-focused, open-source, and supports multiple languages. It offers powerful features like grammar correction, content summarization, and LLM chat mode, making it a versatile writing assistant for various tasks.
restai
RestAI is an AIaaS (AI as a Service) platform that allows users to create and consume AI agents (projects) using a simple REST API. It supports various types of agents, including RAG (Retrieval-Augmented Generation), RAGSQL (RAG for SQL), inference, vision, and router. RestAI features automatic VRAM management, support for any public LLM supported by LlamaIndex or any local LLM supported by Ollama, a user-friendly API with Swagger documentation, and a frontend for easy access. It also provides evaluation capabilities for RAG agents using deepeval.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.

LLMstudio
LLMstudio by TensorOps is a platform that offers prompt engineering tools for accessing models from providers like OpenAI, VertexAI, and Bedrock. It provides features such as Python Client Gateway, Prompt Editing UI, History Management, and Context Limit Adaptability. Users can track past runs, log costs and latency, and export history to CSV. The tool also supports automatic switching to larger-context models when needed. Coming soon features include side-by-side comparison of LLMs, automated testing, API key administration, project organization, and resilience against rate limits. LLMstudio aims to streamline prompt engineering, provide execution history tracking, and enable effortless data export, offering an evolving environment for teams to experiment with advanced language models.

indexify
Indexify is an open-source engine for building fast data pipelines for unstructured data (video, audio, images, and documents) using reusable extractors for embedding, transformation, and feature extraction. LLM Applications can query transformed content friendly to LLMs by semantic search and SQL queries. Indexify keeps vector databases and structured databases (PostgreSQL) updated by automatically invoking the pipelines as new data is ingested into the system from external data sources. **Why use Indexify** * Makes Unstructured Data **Queryable** with **SQL** and **Semantic Search** * **Real-Time** Extraction Engine to keep indexes **automatically** updated as new data is ingested. * Create **Extraction Graph** to describe **data transformation** and extraction of **embedding** and **structured extraction**. * **Incremental Extraction** and **Selective Deletion** when content is deleted or updated. * **Extractor SDK** allows adding new extraction capabilities, and many readily available extractors for **PDF**, **Image**, and **Video** indexing and extraction. * Works with **any LLM Framework** including **Langchain**, **DSPy**, etc. * Runs on your laptop during **prototyping** and also scales to **1000s of machines** on the cloud. * Works with many **Blob Stores**, **Vector Stores**, and **Structured Databases** * We have even **Open Sourced Automation** to deploy to Kubernetes in production.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

firecrawl
Firecrawl is an API service that takes a URL, crawls it, and converts it into clean markdown. It crawls all accessible subpages and provides clean markdown for each, without requiring a sitemap. The API is easy to use and can be self-hosted. It also integrates with Langchain and Llama Index. The Python SDK makes it easy to crawl and scrape websites in Python code.