
WavCraft
Official repo for WavCraft, an AI agent for audio creation and editing
Stars: 347

WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.
README:
Generate and edit the audio with a simple sentence.
This repo currently support:
- text-guided audio editing: edit the content of given audio clip(s) conditioned on text input
- text-guided audio generation: create an audio clip given text input
- audio scriptwriting: get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound for you.
- check if your audio file is synthesized by WavCraft
2024-05-06: Support openLLMs (MistralAI family) for WavCraft.
2024-03-20: Add watermarking to the system
source scripts/setup_envs.sh
export OPENAI_KEY=YOUR_OPENAI_KEY
export HF_KEY=YOUR_HF_KEYpython3 WavCraft.py basic -f \
--input-wav assets/duck_quacking_in_water.wav \
--input-text "Add dog barking."
python3 WavCraft-chat.py basic -f -c
[New session is create]
Add audio files(s) (each file starts with '+'): +assets/duck_quacking_in_water.wav
Enter your instruction (input `EXIT` to exit the process): "Add dog barking"
python3 check_watermark.py --wav-path /path/to/audio/file
python3 WavCraft.py basic -f \
--input-wav assets/duck_quacking_in_water.wav \
--input-text "Add dog barking." \
--model 'mistralai/Mistral-7B-Instruct-v0.2'
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. An overview of WavCraft architecture can be found bellow:

This repository is for research purpose only. We are not responsible for audio generated/edited using semantics created by this model. Also, everyone use WavCraft must NOT disable the watermarking techniques in anyway.
We appreciate WavJourney, AudioCraft, AudioSep, AudioSR, AudioLDM, WavMark for their amazing code work.
If you found our work is helpful, please cite our work:
@misc{liang2024wavcraft,
title={WavCraft: Audio Editing and Generation with Large Language Models},
author={Jinhua Liang and Huan Zhang and Haohe Liu and Yin Cao and Qiuqiang Kong and Xubo Liu and Wenwu Wang and Mark D. Plumbley and Huy Phan and Emmanouil Benetos},
year={2024},
eprint={2403.09527},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WavCraft
Similar Open Source Tools
WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.
Scriberr
Scriberr is a self-hostable AI audio transcription app that utilizes open-source Whisper models from OpenAI for transcribing audio files locally on user's hardware. It offers fast transcription with customizable compute settings, local transcription on device, API endpoints for automation, and integration with other tools. Users can optionally summarize transcripts using ChatGPT or Ollama, with support for custom prompts. The app is mobile-ready, simple, and easy to use, with planned features including speaker diarization, audio recording, file actions, full text fuzzy search, tag-based organization, follow-along text with playback, edit summaries, export options, and support for other languages. Despite being in beta, Scriberr is functional and usable, albeit with some rough edges and minor bugs.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
KrillinAI
KrillinAI is a video subtitle translation and dubbing tool based on AI large models, featuring speech recognition, intelligent sentence segmentation, professional translation, and one-click deployment of the entire process. It provides a one-stop workflow from video downloading to the final product, empowering cross-language cultural communication with AI. The tool supports multiple languages for input and translation, integrates features like automatic dependency installation, video downloading from platforms like YouTube and Bilibili, high-speed subtitle recognition, intelligent subtitle segmentation and alignment, custom vocabulary replacement, professional-level translation engine, and diverse external service selection for speech and large model services.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
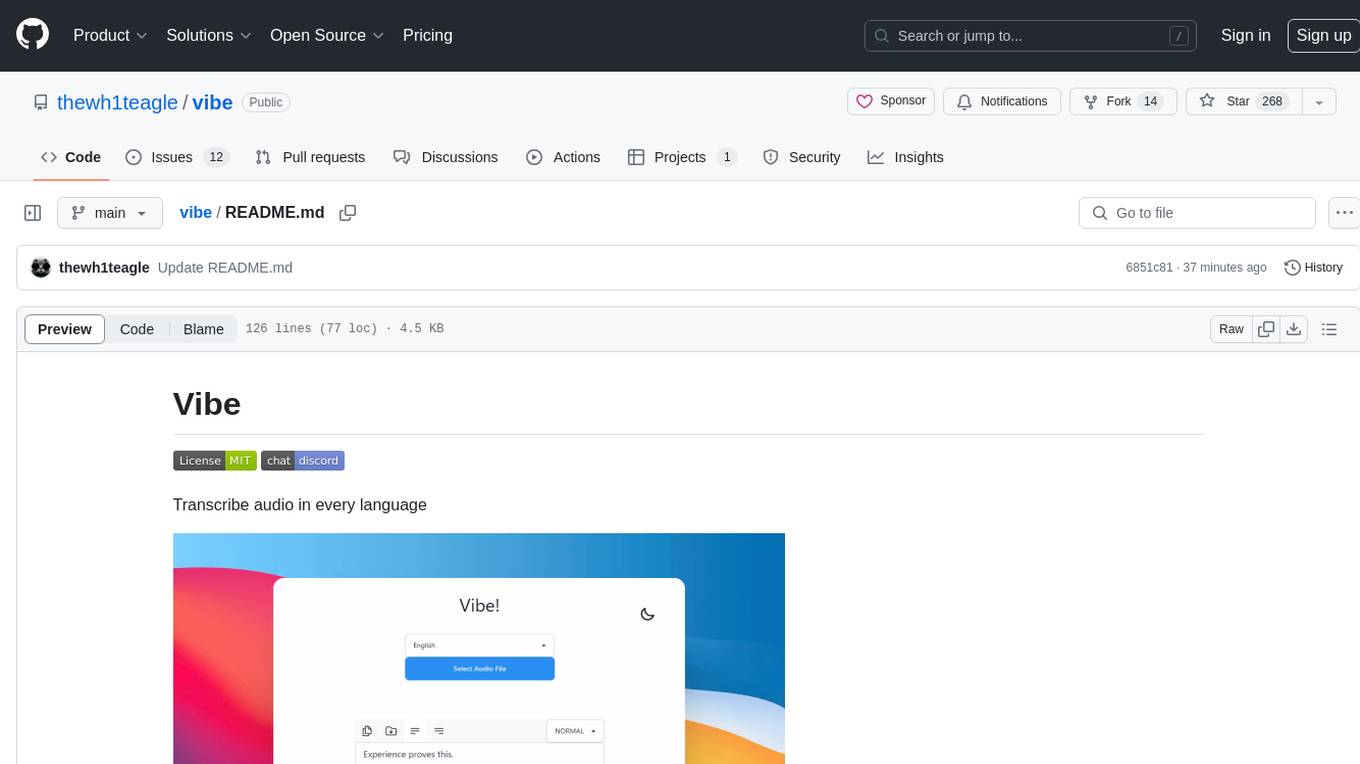
vibe
Vibe is a tool designed to transcribe audio in multiple languages with features such as offline functionality, user-friendly design, support for various file formats, automatic updates, and translation. It is optimized for different platforms and hardware, offering total freedom to customize models easily. The tool is ideal for transcribing audio and video files, with upcoming features like transcribing system audio and audio from microphone. Vibe is a versatile and efficient transcription tool suitable for various users.
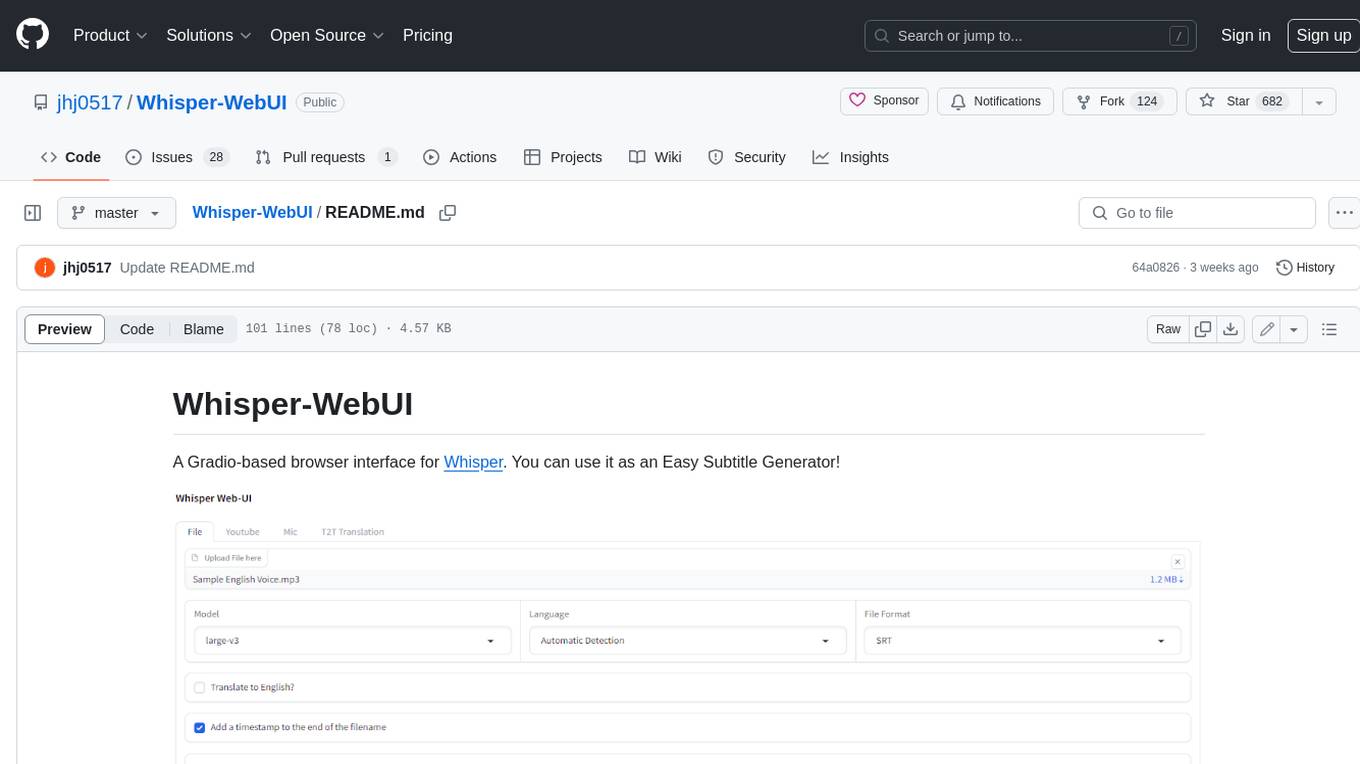
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.

mmore
MMORE is an open-source, end-to-end pipeline for ingesting, processing, indexing, and retrieving knowledge from various file types such as PDFs, Office docs, images, audio, video, and web pages. It standardizes content into a unified multimodal format, supports distributed CPU/GPU processing, and offers hybrid dense+sparse retrieval with an integrated RAG service through CLI and APIs.
ComfyUI_VLM_nodes
ComfyUI_VLM_nodes is a repository containing various nodes for utilizing Vision Language Models (VLMs) and Language Models (LLMs). The repository provides nodes for tasks such as structured output generation, image to music conversion, LLM prompt generation, automatic prompt generation, and more. Users can integrate different models like InternLM-XComposer2-VL, UForm-Gen2, Kosmos-2, moondream1, moondream2, JoyTag, and Chat Musician. The nodes support features like extracting keywords, generating prompts, suggesting prompts, and obtaining structured outputs. The repository includes examples and instructions for using the nodes effectively.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.
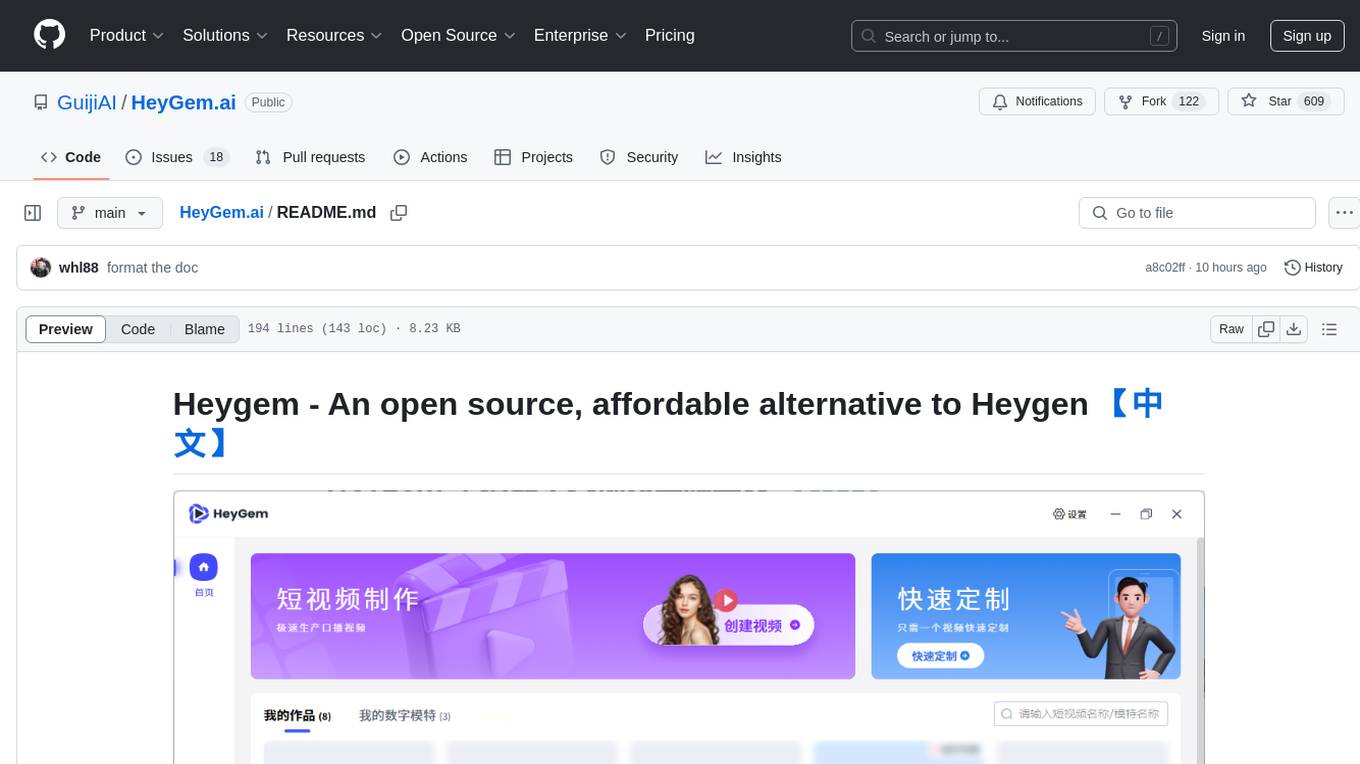
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
obsidian-ai-assistant
Obsidian AI Assistant is a simple plugin that enables interactions with various AI models such as OpenAI ChatGPT, Anthropic Claude, OpenAI DALL·E, and OpenAI Whisper directly from Obsidian notes. The plugin offers features like text assistance, image generation, and speech-to-text functionality. Users can chat with the AI assistant, generate images for notes, and dictate notes using speech-to-text. The plugin allows customization of text models, image generation options, and language settings for speech-to-text. It requires official API keys for using OpenAI and Anthropic Claude models.
For similar tasks
WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.
ai-collective-tools
ai-collective-tools is an open-source community dedicated to creating a comprehensive collection of AI tools for developers, researchers, and enthusiasts. The repository provides a curated selection of AI tools and resources across various categories such as 3D, Agriculture, Art, Audio Editing, Avatars, Chatbots, Code Assistant, Cooking, Copywriting, Crypto, Customer Support, Dating, Design Assistant, Design Generator, Developer, E-Commerce, Education, Email Assistant, Experiments, Fashion, Finance, Fitness, Fun Tools, Gaming, General Writing, Gift Ideas, HealthCare, Human Resources, Image Classification, Image Editing, Image Generator, Interior Designing, Legal Assistant, Logo Generator, Low Code, Models, Music, Paraphraser, Personal Assistant, Presentations, Productivity, Prompt Generator, Psychology, Real Estate, Religion, Research, Resume, Sales, Search Engine, SEO, Shopping, Social Media, Spreadsheets, SQL, Startup Tools, Story Teller, Summarizer, Testing, Text to Speech, Text to Image, Transcriber, Travel, Video Editing, Video Generator, Weather, Writing Generator, and Other Resources.
collective-ai-tools
The 'collective-ai-tools' repository is an open-source community dedicated to curating a comprehensive collection of AI tools and resources for developers, researchers, and enthusiasts. The repository provides a curated selection of AI tools across various categories such as 3D modeling, app building, agriculture, art, audio editing, avatars, chatbots, code assistance, cooking, copywriting, crypto, customer support, dating, design assistance, design generation, developer tools, e-commerce, education, email assistance, experiments, fashion, finance, fitness, fun tools, gaming, general writing, gift ideas, healthcare, human resources, image classification, image editing, image generation, interior designing, legal assistance, logo generation, low code development, models, music, paraphrasing, personal assistance, presentations, productivity tools, prompt generation, psychology, real estate, religion, research, resume building, sales, search engine, SEO, shopping, social media, spreadsheets, SQL, startup tools, storytelling, summarization, testing, text-to-speech, text-to-image, transcription, travel, video editing, video generation, writing generation, weather, and other resources.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.
For similar jobs

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio
WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
transcriptionstream
Transcription Stream is a self-hosted diarization service that works offline, allowing users to easily transcribe and summarize audio files. It includes a web interface for file management, Ollama for complex operations on transcriptions, and Meilisearch for fast full-text search. Users can upload files via SSH or web interface, with output stored in named folders. The tool requires a NVIDIA GPU and provides various scripts for installation and running. Ports for SSH, HTTP, Ollama, and Meilisearch are specified, along with access details for SSH server and web interface. Customization options and troubleshooting tips are provided in the documentation.
podscript
Podscript is a tool designed to generate transcripts for podcasts and similar audio files using Language Model Models (LLMs) and Speech-to-Text (STT) APIs. It provides a command-line interface (CLI) for transcribing audio from various sources, including YouTube videos and audio files, using different speech-to-text services like Deepgram, Assembly AI, and Groq. Additionally, Podscript offers a web-based user interface for convenience. Users can configure keys for supported services, transcribe audio, and customize the transcription models. The tool aims to simplify the process of creating accurate transcripts for audio content.
alexandria-audiobook
Alexandria Audiobook Generator is a tool that transforms any book or novel into a fully-voiced audiobook using AI-powered script annotation and text-to-speech. It features a built-in Qwen3-TTS engine with batch processing and a browser-based editor for fine-tuning every line before final export. The tool offers AI-powered pipeline for automatic script annotation, smart chunking, and context preservation. It also provides voice generation capabilities with built-in TTS engine, multi-language support, custom voices, voice cloning, and LoRA voice training. The web UI editor allows users to edit, preview, and export the audiobook. Export options include combined audiobook, individual voicelines, and Audacity export for DAW editing.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

suno-api
Suno AI API is an open-source project that allows developers to integrate the music generation capabilities of Suno.ai into their own applications. The API provides a simple and convenient way to generate music, lyrics, and other audio content using Suno.ai's powerful AI models. With Suno AI API, developers can easily add music generation functionality to their apps, websites, and other projects.