
ragdoll-studio
The creative suite for character-driven AI experiences.
Stars: 156
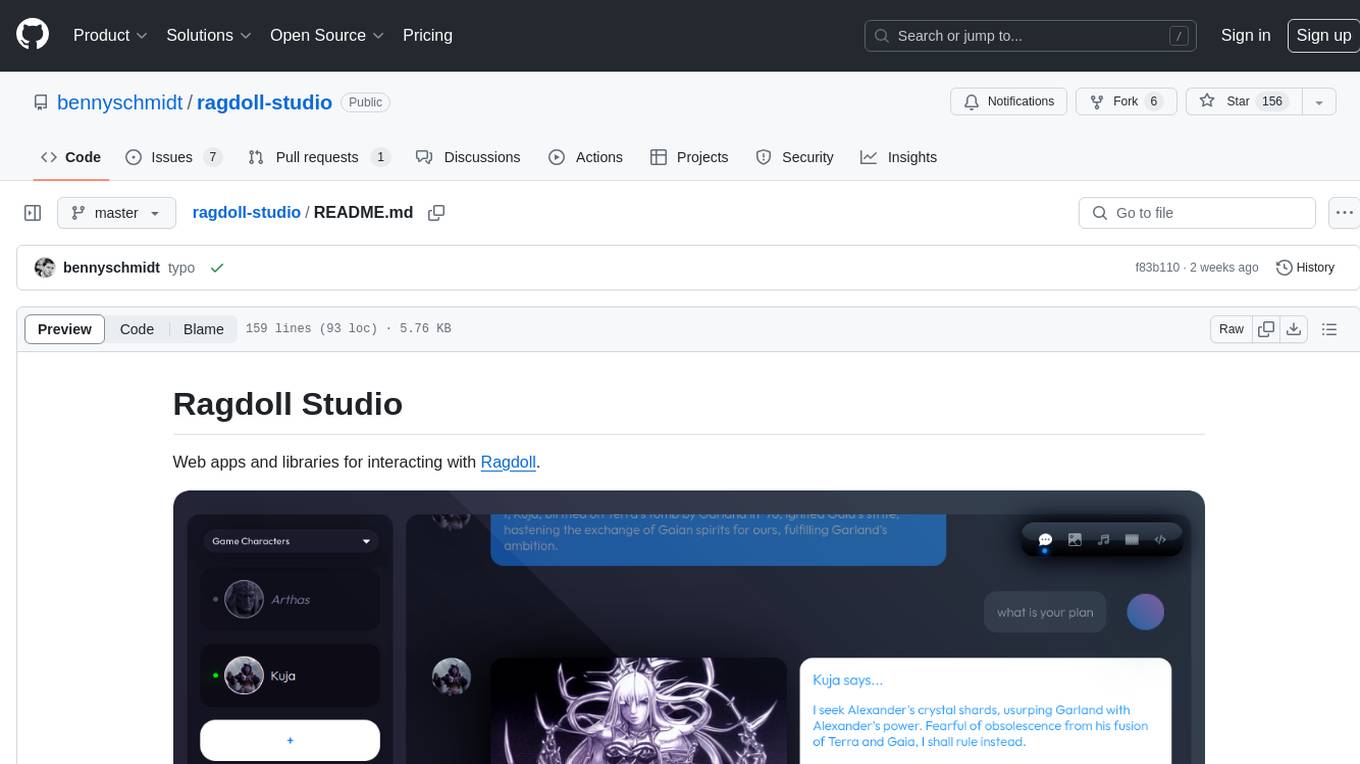
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
README:
Web apps and libraries for interacting with Ragdoll.
Go beyond fine-tuning to produce flawless creative deliverables, rich multimedia, and engaging experiences.
Create and chat with characters that have scoped knowledge and distinct personalities.
Define their source of knowledge at a URL (e.g. Wikipedia page).
✨ Focus: Upload additional documents to extend their knowledge.
https://github.com/bennyschmidt/ragdoll-studio/assets/45407493/cd7464fe-9984-4ae3-8911-1da104f68e8c
The above video shows the case of a storyteller (Arthas Menethil, from World of Warcraft) who was created with limited knowledge, so he doesn't know as much as he should. This demonstration shows the ragdoll's knowledge being extended by uploading a text file containing additional information about his domain. After that, he knows and is able to talk about the new information and even renders images that are more on-brand.
Produce vector art (icons, logos, animations) in a specific style.
✨ Inspire: Upload source images to inspire compositional features of a new image.
Produce raster art (photos, illustrations, concept art) in a specific style.
✨ Inspire: Upload source images to inspire compositional features of a new image.
https://github.com/bennyschmidt/ragdoll-studio/assets/45407493/20427f0b-7e64-449d-b9e2-d881f867dd5a
The above video shows how Ragdoll uses Stable Diffusion's img2img feature through the lens of different ragdolls to produce a variety of different image results. Optionally check "True to original" to keep the overall structure of the source image in place while still applying stylistic attributes of the ragdoll. The initial
artStyleset when creating a ragdoll defines the overall kind of image (photorealistic, concept art, pixel art, etc.) but because the ragdoll promptsimg2imgitself, some of its own speech patterns can influence the resulting image too.
Produce videos (shows, podcasts, cinematics, cutscenes, films, animations) of a certain style or genre.
✨ Stage: Upload an image to set the stage for a new video clip.
Coming soon!
Produce audio (music, sound effects, speech) of a certain style or genre.
✨ Cue: Upload an audio clip to cue a specific style or sound.
Coming soon!
Produce 3D objects (scenes, characters, animations) in a specific style.
✨ Inspire: Upload source 3D objects to inspire compositional features of a new one.
Coming soon!
✨ Download Content: When you're happy with a result, download your generated content in a variety of formats, or clear the channel to start over.
The above image shows the Download button highlighted in the bottom-right. The output format depends on which app mode you're currently in, see #14.
✨ Community Site: Export & publish collections of ragdolls, or "casts", and download others.
The above image shows casts of characters, or dolls, on the community site. If you want to share characters you've created or download others, you can do so through sharing casts. There's also an apps section that's coming soon for the purpose of sharing different apps created with the Ragdoll software (using Ragdoll core and/or the node or react libraries).
- Configure the API
cd ragdoll-api
See the API README.md.
- Install dependencies
nvm use && npm i
- Start the server
npm start
You should see something like this:
A worker has spawned.
A worker has spawned.
A worker has spawned.
A worker has spawned.
A worker has spawned.
A worker has spawned.
A worker has spawned.
A worker has spawned.
Cluster is online at http://localhost:8000
Worker online (#1).
Worker online (#2).
Worker online (#3).
Worker online (#4).
Worker online (#5).
Worker (#1) is listening for messages.
Worker (#3) is listening for messages.
Worker (#2) is listening for messages.
Worker (#5) is listening for messages.
Worker online (#6).
Worker online (#8).
Worker (#4) is listening for messages.
Worker online (#7).
Worker (#6) is listening for messages.
Worker (#8) is listening for messages.
Worker (#7) is listening for messages.
This means the server is running and handling concurrent requests on all CPU cores.
Ragdoll API is now listening on http://localhost:8000/.
- Set up the front-end
cd ../ragdoll-react
See the React README.md.
nvm use && npm i
- Start the front-end
npm start
You should see the default UI:
See CaseStudies.md.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ragdoll-studio
Similar Open Source Tools
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.
Ollama-SwiftUI
Ollama-SwiftUI is a user-friendly interface for Ollama.ai created in Swift. It allows seamless chatting with local Large Language Models on Mac. Users can change models mid-conversation, restart conversations, send system prompts, and use multimodal models with image + text. The app supports managing models, including downloading, deleting, and duplicating them. It offers light and dark mode, multiple conversation tabs, and a localized interface in English and Arabic.
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.

FunClip
FunClip is an open-source, locally deployed automated video clipping tool that leverages Alibaba TONGYI speech lab's FunASR Paraformer series models for speech recognition on videos. Users can select text segments or speakers from recognition results to obtain corresponding video clips. It integrates industrial-grade models for accurate predictions and offers hotword customization and speaker recognition features. The tool is user-friendly with Gradio interaction, supporting multi-segment clipping and providing full video and target segment subtitles. FunClip is suitable for users looking to automate video clipping tasks with advanced AI capabilities.
FunClip
FunClip is an open-source, locally deployable automated video editing tool that utilizes the FunASR Paraformer series models from Alibaba DAMO Academy for speech recognition in videos. Users can select text segments or speakers from the recognition results and click the clip button to obtain the corresponding video segments. FunClip integrates advanced features such as the Paraformer-Large model for accurate Chinese ASR, SeACo-Paraformer for customized hotword recognition, CAM++ speaker recognition model, Gradio interactive interface for easy usage, support for multiple free edits with automatic SRT subtitles generation, and segment-specific SRT subtitles.
llocal
LLocal is an Electron application focused on providing a seamless and privacy-driven chatting experience using open-sourced technologies, particularly open-sourced LLM's. It allows users to store chats locally, switch between models, pull new models, upload images, perform web searches, and render responses as markdown. The tool also offers multiple themes, seamless integration with Ollama, and upcoming features like chat with images, web search improvements, retrieval augmented generation, multiple PDF chat, text to speech models, community wallpapers, lofi music, speech to text, and more. LLocal's builds are currently unsigned, requiring manual builds or using the universal build for stability.

gptme
GPTMe is a tool that allows users to interact with an LLM assistant directly in their terminal in a chat-style interface. The tool provides features for the assistant to run shell commands, execute code, read/write files, and more, making it suitable for various development and terminal-based tasks. It serves as a local alternative to ChatGPT's 'Code Interpreter,' offering flexibility and privacy when using a local model. GPTMe supports code execution, file manipulation, context passing, self-correction, and works with various AI models like GPT-4. It also includes a GitHub Bot for requesting changes and operates entirely in GitHub Actions. In progress features include handling long contexts intelligently, a web UI and API for conversations, web and desktop vision, and a tree-based conversation structure.
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
upscayl
Upscayl is a free and open-source AI image upscaler that uses advanced AI algorithms to enlarge and enhance low-resolution images without losing quality. It is a cross-platform application built with the Linux-first philosophy, available on all major desktop operating systems. Upscayl utilizes Real-ESRGAN and Vulkan architecture for image enhancement, and its backend is fully open-source under the AGPLv3 license. It is important to note that a Vulkan compatible GPU is required for Upscayl to function effectively.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

chroma
Chroma is an open-source embedding database that provides a simple, scalable, and feature-rich way to build Python or JavaScript LLM apps with memory. It offers a fully-typed, fully-tested, and fully-documented API that makes it easy to get started and scale your applications. Chroma also integrates with popular tools like LangChain and LlamaIndex, and supports a variety of embedding models, including Sentence Transformers, OpenAI embeddings, and Cohere embeddings. With Chroma, you can easily add documents to your database, query relevant documents with natural language, and compose documents into the context window of an LLM like GPT3 for additional summarization or analysis.

beehave
Beehave is a powerful addon for Godot Engine that enables users to create robust AI systems using behavior trees. It simplifies the design of complex NPC behaviors, challenging boss battles, and other advanced setups. Beehave allows for the creation of highly adaptive AI that responds to changes in the game world and overcomes unexpected obstacles, catering to both beginners and experienced developers. The tool is currently in development for version 3.0.
machinascript-for-robots
MachinaScript For Robots is a dynamic set of tools and a LLM-JSON-based language designed to empower humans in the creation of their own robots. It facilitates the animation of generative movements, the integration of personality, and the teaching of new skills with a high degree of autonomy. With MachinaScript, users can control a wide range of electronic components, including Arduinos, Raspberry Pis, servo motors, cameras, sensors, and more. The tool enables the creation of intelligent robots accessible to everyone, allowing for complex tasks to be performed with elegance and precision.
For similar tasks

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.
LLMUnity
LLM for Unity enables seamless integration of Large Language Models (LLMs) within the Unity engine, allowing users to create intelligent characters for immersive player interactions. The tool supports major LLM models, runs locally without internet access, offers fast inference on CPU and GPU, and is easy to set up with a single line of code. It is free for both personal and commercial use, tested on Unity 2021 LTS, 2022 LTS, and 2023. Users can build multiple AI characters efficiently, use remote servers for processing, and customize model settings for text generation.
character-factory
Character Factory is a Python script designed to generate detailed character cards for SillyTavern, TavernAI, TextGenerationWebUI, and more using Large Language Model (LLM) and Stable Diffusion. It streamlines character generation by leveraging deep learning models to create names, summaries, personalities, greeting messages, and avatars for characters. The tool provides an easy way to create unique and imaginative characters for storytelling, chatting, and other purposes.
ai-anime-art-generator
AI Anime Art Generator is an AI-driven cutting-edge tool for anime arts creation. Perfect for beginners to easily create stunning anime art without any prior experience. It allows users to create detailed character designs, custom avatars for social media, and explore new artistic styles and ideas. Built on Next.js, TailwindCSS, Google Analytics, Vercel, Replicate, CloudFlare R2, and Clerk.
TavernAI
TavernAI is an atmospheric frontend tool for chat and storywriting, compatible with various backends. It offers features like character creation, online character database, group chat, story mode, world info, message swiping, configurable settings, interface themes, backgrounds, message editing, GPT-4.5, and Claude picture recognition. The tool supports backends like Kobold series, Oobabooga's Text Generation Web UI, OpenAI, NovelAI, and Claude. Users can easily install TavernAI on different operating systems and start using it for interactive storytelling and chat experiences.
Character-Engine-Discord
Character Engine is a Discord bot that aggregates various online platforms to create AI-driven characters using Discord Webhooks and LLM chatbots. It allows users to bring life and joy to their server by spawning characters, exploring embedded characters, and configuring settings on a per-server, per-channel, and per-character basis.
For similar jobs
ragdoll-studio
Ragdoll Studio is a platform offering web apps and libraries for interacting with Ragdoll, enabling users to go beyond fine-tuning and create flawless creative deliverables, rich multimedia, and engaging experiences. It provides various modes such as Story Mode for creating and chatting with characters, Vector Mode for producing vector art, Raster Mode for producing raster art, Video Mode for producing videos, Audio Mode for producing audio, and 3D Mode for producing 3D objects. Users can export their content in various formats and share their creations on the community site. The platform consists of a Ragdoll API and a front-end React application for seamless usage.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.
SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.