
lector
Simple, fast primitives for building pdf viewers. maintained by @unriddle-ai
Stars: 213

Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.
README:
Simple primitives to compose powerful PDF viewing experiences.
powered by PDF.js and React
A composable, headless PDF viewer toolkit for React applications, powered by PDF.js. Build feature-rich PDF viewing experiences with full control over the UI and functionality.
npm install @unriddle-ai/lector pdfjs-dist
# or with yarn
yarn add @unriddle-ai/lector pdfjs-dist
# or with pnpm
pnpm add @unriddle-ai/lector pdfjs-distHere's a simple example of how to create a basic PDF viewer:
import { CanvasLayer, Page, Pages, Root, TextLayer } from "@unriddle-ai/lector";
import "pdfjs-dist/web/pdf_viewer.css";
export default function PDFViewer() {
return (
<Root
fileURL='/sample.pdf'
className='w-full h-[500px] border overflow-hidden rounded-lg'
loader={<div className='p-4'>Loading...</div>}>
<Pages className='p-4'>
<Page>
<CanvasLayer />
<TextLayer />
</Page>
</Pages>
</Root>
);
}- 📱 Responsive and mobile-friendly
- 🎨 Fully customizable UI components
- 🔍 Text selection and search functionality
- 📑 Page thumbnails and outline navigation
- 🌗 First-class dark mode support
- 🖱️ Pan and zoom controls
- 📝 Form filling support
- 🔗 Internal and external link handling
We welcome contributions! Key areas we're focusing on:
- Performance optimizations
- Accessibility improvements
- Mobile/touch interactions
- Documentation and examples
Special thanks to these open-source projects that provided inspiration:
MIT © Unriddle AI
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for lector
Similar Open Source Tools
lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.

aiscript
AIScript is a unique programming language and web framework written in Rust, designed to help developers effortlessly build AI applications. It combines the strengths of Python, JavaScript, and Rust to create an intuitive, powerful, and easy-to-use tool. The language features first-class functions, built-in AI primitives, dynamic typing with static type checking, data validation, error handling inspired by Rust, a rich standard library, and automatic garbage collection. The web framework offers an elegant route DSL, automatic parameter validation, OpenAPI schema generation, database modules, authentication capabilities, and more. AIScript excels in AI-powered APIs, prototyping, microservices, data validation, and building internal tools.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
nous
Nous is an open-source TypeScript platform for autonomous AI agents and LLM based workflows. It aims to automate processes, support requests, review code, assist with refactorings, and more. The platform supports various integrations, multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It offers advanced features like reasoning/planning, memory and function call history, hierarchical task decomposition, and control-loop function calling options. Nous is designed to be a flexible platform for the TypeScript community to expand and support different use cases and integrations.

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.
panda-etl
PandaETL is an open-source, no-code ETL tool designed to extract and parse data from various document types including PDFs, emails, websites, audio files, and more. With an intuitive interface and powerful backend, PandaETL simplifies the process of data extraction and transformation, making it accessible to users without programming skills.

UltraRAG
The UltraRAG framework is a researcher and developer-friendly RAG system solution that simplifies the process from data construction to model fine-tuning in domain adaptation. It introduces an automated knowledge adaptation technology system, supporting no-code programming, one-click synthesis and fine-tuning, multidimensional evaluation, and research-friendly exploration work integration. The architecture consists of Frontend, Service, and Backend components, offering flexibility in customization and optimization. Performance evaluation in the legal field shows improved results compared to VanillaRAG, with specific metrics provided. The repository is licensed under Apache-2.0 and encourages citation for support.
chainlit
Chainlit is an open-source async Python framework which allows developers to build scalable Conversational AI or agentic applications. It enables users to create ChatGPT-like applications, embedded chatbots, custom frontends, and API endpoints. The framework provides features such as multi-modal chats, chain of thought visualization, data persistence, human feedback, and an in-context prompt playground. Chainlit is compatible with various Python programs and libraries, including LangChain, Llama Index, Autogen, OpenAI Assistant, and Haystack. It offers a range of examples and a cookbook to showcase its capabilities and inspire users. Chainlit welcomes contributions and is licensed under the Apache 2.0 license.
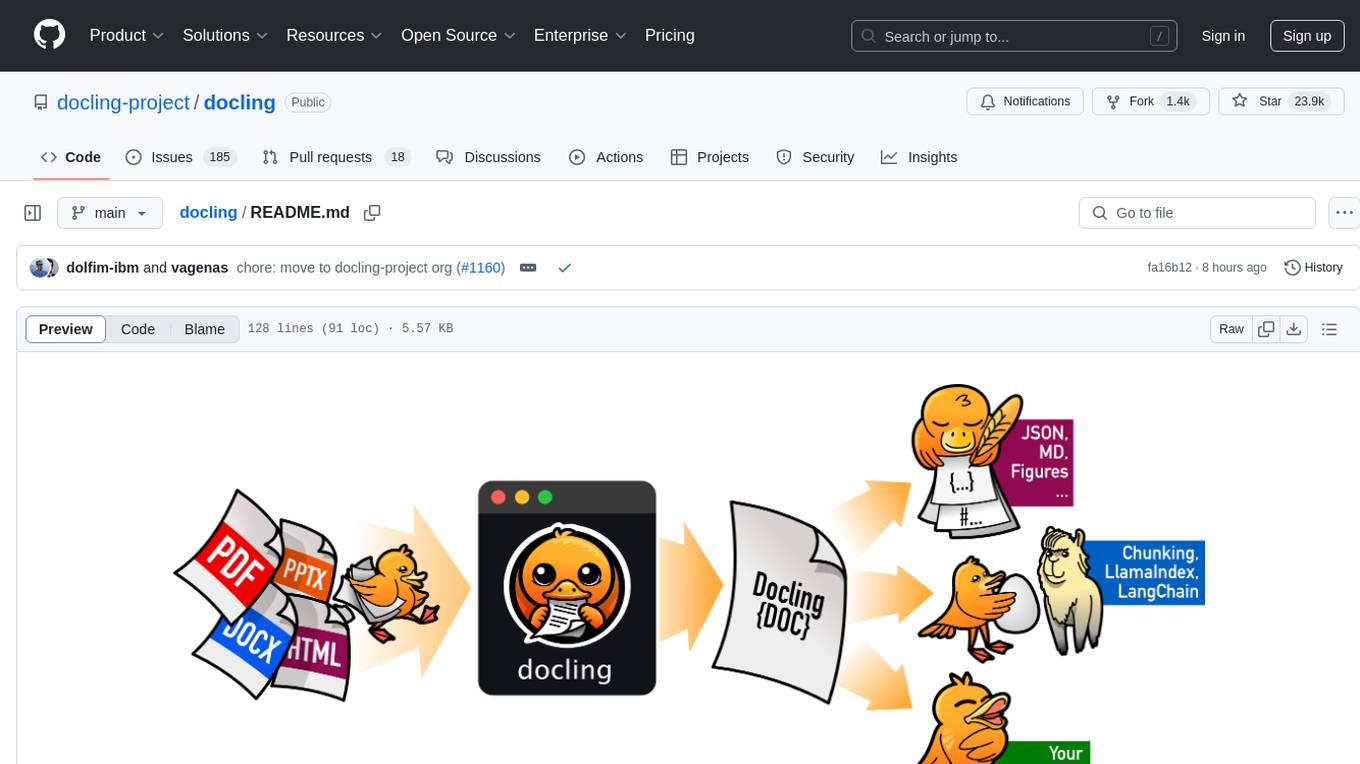
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.
gpt-rag-ingestion
The GPT-RAG Data Ingestion service automates processing of diverse document types for indexing in Azure AI Search. It uses intelligent chunking strategies tailored to each format, generates text and image embeddings, and enables rich, multimodal retrieval experiences for agent-based RAG applications. Supported data sources include Blob Storage, NL2SQL Metadata, and SharePoint. The service selects chunkers based on file extension, such as DocAnalysisChunker for PDF files, OCR for image files, LangChainChunker for text-based files, TranscriptionChunker for video transcripts, and SpreadsheetChunker for spreadsheets. Deployment requires provisioning infrastructure and assigning specific roles to the user or service principal.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
For similar tasks

comet-llm
CometLLM is a tool to log and visualize your LLM prompts and chains. Use CometLLM to identify effective prompt strategies, streamline your troubleshooting, and ensure reproducible workflows!

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.
lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.
read-frog
Read-frog is a powerful text analysis tool designed to help users extract valuable insights from text data. It offers a wide range of features including sentiment analysis, keyword extraction, entity recognition, and text summarization. With its user-friendly interface and robust algorithms, Read-frog is suitable for both beginners and advanced users looking to analyze text data for various purposes such as market research, social media monitoring, and content optimization. Whether you are a data scientist, marketer, researcher, or student, Read-frog can streamline your text analysis workflow and provide actionable insights to drive decision-making and enhance productivity.
ALwrity
ALwrity is a lightweight and user-friendly text analysis tool designed for developers and data scientists. It provides various functionalities for analyzing and processing text data, including sentiment analysis, keyword extraction, and text summarization. With ALwrity, users can easily gain insights from their text data and make informed decisions based on the analysis results. The tool is highly customizable and can be integrated into existing workflows seamlessly, making it a valuable asset for anyone working with text data in their projects.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.
ComfyUI_VLM_nodes
ComfyUI_VLM_nodes is a repository containing various nodes for utilizing Vision Language Models (VLMs) and Language Models (LLMs). The repository provides nodes for tasks such as structured output generation, image to music conversion, LLM prompt generation, automatic prompt generation, and more. Users can integrate different models like InternLM-XComposer2-VL, UForm-Gen2, Kosmos-2, moondream1, moondream2, JoyTag, and Chat Musician. The nodes support features like extracting keywords, generating prompts, suggesting prompts, and obtaining structured outputs. The repository includes examples and instructions for using the nodes effectively.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.