
obsei
Obsei is a low code AI powered automation tool. It can be used in various business flows like social listening, AI based alerting, brand image analysis, comparative study and more .
Stars: 1204

Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.
README:


![]()






![]()


Note: Obsei is still in alpha stage hence carefully use it in Production. Also, as it is constantly undergoing development hence master branch may contain many breaking changes. Please use released version.
Obsei (pronounced "Ob see" | /əb-'sē/) is an open-source, low-code, AI powered automation tool. Obsei consists of -
- Observer: Collect unstructured data from various sources like tweets from Twitter, Subreddit comments on Reddit, page post's comments from Facebook, App Stores reviews, Google reviews, Amazon reviews, News, Website, etc.
- Analyzer: Analyze unstructured data collected with various AI tasks like classification, sentiment analysis, translation, PII, etc.
- Informer: Send analyzed data to various destinations like ticketing platforms, data storage, dataframe, etc so that the user can take further actions and perform analysis on the data.
All the Observers can store their state in databases (Sqlite, Postgres, MySQL, etc.), making Obsei suitable for scheduled jobs or serverless applications.
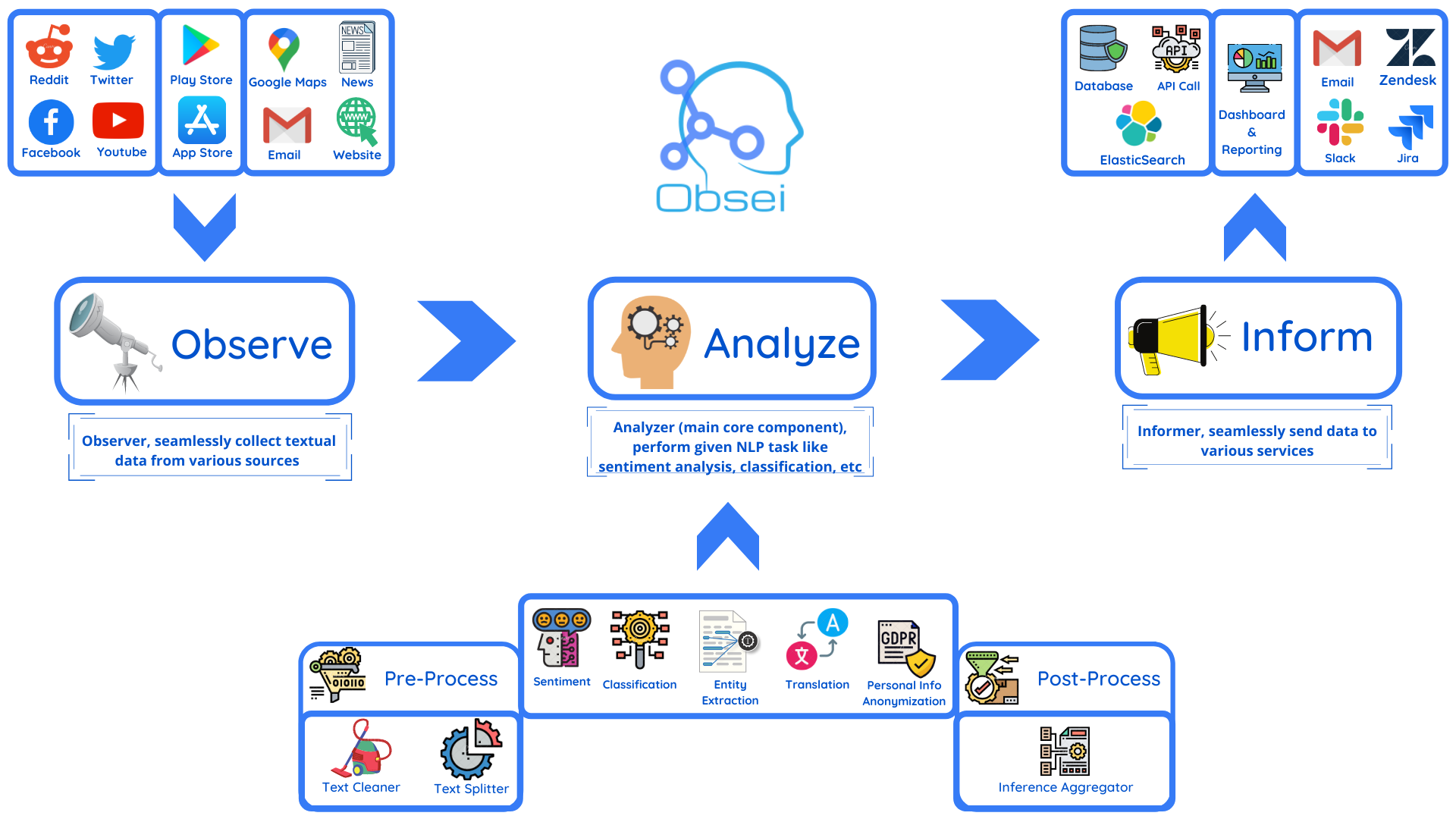
- Text, Image, Audio, Documents and Video oriented workflows
- Collect data from every possible private and public channels
- Add every possible workflow to an AI downstream application to automate manual cognitive workflows
Obsei use cases are following, but not limited to -
- Social listening: Listening about social media posts, comments, customer feedback, etc.
- Alerting/Notification: To get auto-alerts for events such as customer complaints, qualified sales leads, etc.
- Automatic customer issue creation based on customer complaints on Social Media, Email, etc.
- Automatic assignment of proper tags to tickets based content of customer complaint for example login issue, sign up issue, delivery issue, etc.
- Extraction of deeper insight from feedbacks on various platforms
- Market research
- Creation of dataset for various AI tasks
- Many more based on creativity 💡
Install the following (if not present already) -
- Install Python 3.7+
- Install PIP
You can install Obsei either via PIP or Conda based on your preference. To install latest released version -
pip install obsei[all]Install from master branch (if you want to try the latest features) -
git clone https://github.com/obsei/obsei.git
cd obsei
pip install --editable .[all]Note: all option will install all the dependencies which might not be needed for your workflow, alternatively
following options are available to install minimal dependencies as per need -
-
pip install obsei[source]: To install dependencies related to all observers -
pip install obsei[sink]: To install dependencies related to all informers -
pip install obsei[analyzer]: To install dependencies related to all analyzers, it will install pytorch as well -
pip install obsei[twitter-api]: To install dependencies related to Twitter observer -
pip install obsei[google-play-scraper]: To install dependencies related to Play Store review scrapper observer -
pip install obsei[google-play-api]: To install dependencies related to Google official play store review API based observer -
pip install obsei[app-store-scraper]: To install dependencies related to Apple App Store review scrapper observer -
pip install obsei[reddit-scraper]: To install dependencies related to Reddit post and comment scrapper observer -
pip install obsei[reddit-api]: To install dependencies related to Reddit official api based observer -
pip install obsei[pandas]: To install dependencies related to TSV/CSV/Pandas based observer and informer -
pip install obsei[google-news-scraper]: To install dependencies related to Google news scrapper observer -
pip install obsei[facebook-api]: To install dependencies related to Facebook official page post and comments api based observer -
pip install obsei[atlassian-api]: To install dependencies related to Jira official api based informer -
pip install obsei[elasticsearch]: To install dependencies related to elasticsearch informer -
pip install obsei[slack-api]:To install dependencies related to Slack official api based informer
You can also mix multiple dependencies together in single installation command. For example to install dependencies Twitter observer, all analyzer, and Slack informer use following command -
pip install obsei[twitter-api, analyzer, slack-api]Expand the following steps and create a workflow -
Step 1: Configure Source/Observer
|
|
|
|
|
|
|
|
|
|
|
|
Step 2: Configure Analyzer
Note: To run transformers in an offline mode, check transformers offline mode.
Some analyzer support GPU and to utilize pass device parameter. List of possible values of device parameter (default value auto):
- auto: GPU (cuda:0) will be used if available otherwise CPU will be used
- cpu: CPU will be used
- cuda:{id} - GPU will be used with provided CUDA device id
|
|
|
|
|
|
Step 3: Configure Sink/Informer
|
|
|
|
|
|
|
Step 4: Join and create workflow
source will fetch data from the selected source, then feed it to the analyzer for processing, whose output we feed into a sink to get notified at that sink.
# Uncomment if you want logger
# import logging
# import sys
# logger = logging.getLogger(__name__)
# logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# This will fetch information from configured source ie twitter, app store etc
source_response_list = source.lookup(source_config)
# Uncomment if you want to log source response
# for idx, source_response in enumerate(source_response_list):
# logger.info(f"source_response#'{idx}'='{source_response.__dict__}'")
# This will execute analyzer (Sentiment, classification etc) on source data with provided analyzer_config
analyzer_response_list = text_analyzer.analyze_input(
source_response_list=source_response_list,
analyzer_config=analyzer_config
)
# Uncomment if you want to log analyzer response
# for idx, an_response in enumerate(analyzer_response_list):
# logger.info(f"analyzer_response#'{idx}'='{an_response.__dict__}'")
# Analyzer output added to segmented_data
# Uncomment to log it
# for idx, an_response in enumerate(analyzer_response_list):
# logger.info(f"analyzed_data#'{idx}'='{an_response.segmented_data.__dict__}'")
# This will send analyzed output to configure sink ie Slack, Zendesk etc
sink_response_list = sink.send_data(analyzer_response_list, sink_config)
# Uncomment if you want to log sink response
# for sink_response in sink_response_list:
# if sink_response is not None:
# logger.info(f"sink_response='{sink_response}'")Step 5: Execute workflow
Copy the code snippets from Steps 1 to 4 into a python file, for exampleexample.py and execute the following command -
python example.pyWe have a minimal streamlit based UI that you can use to test Obsei.
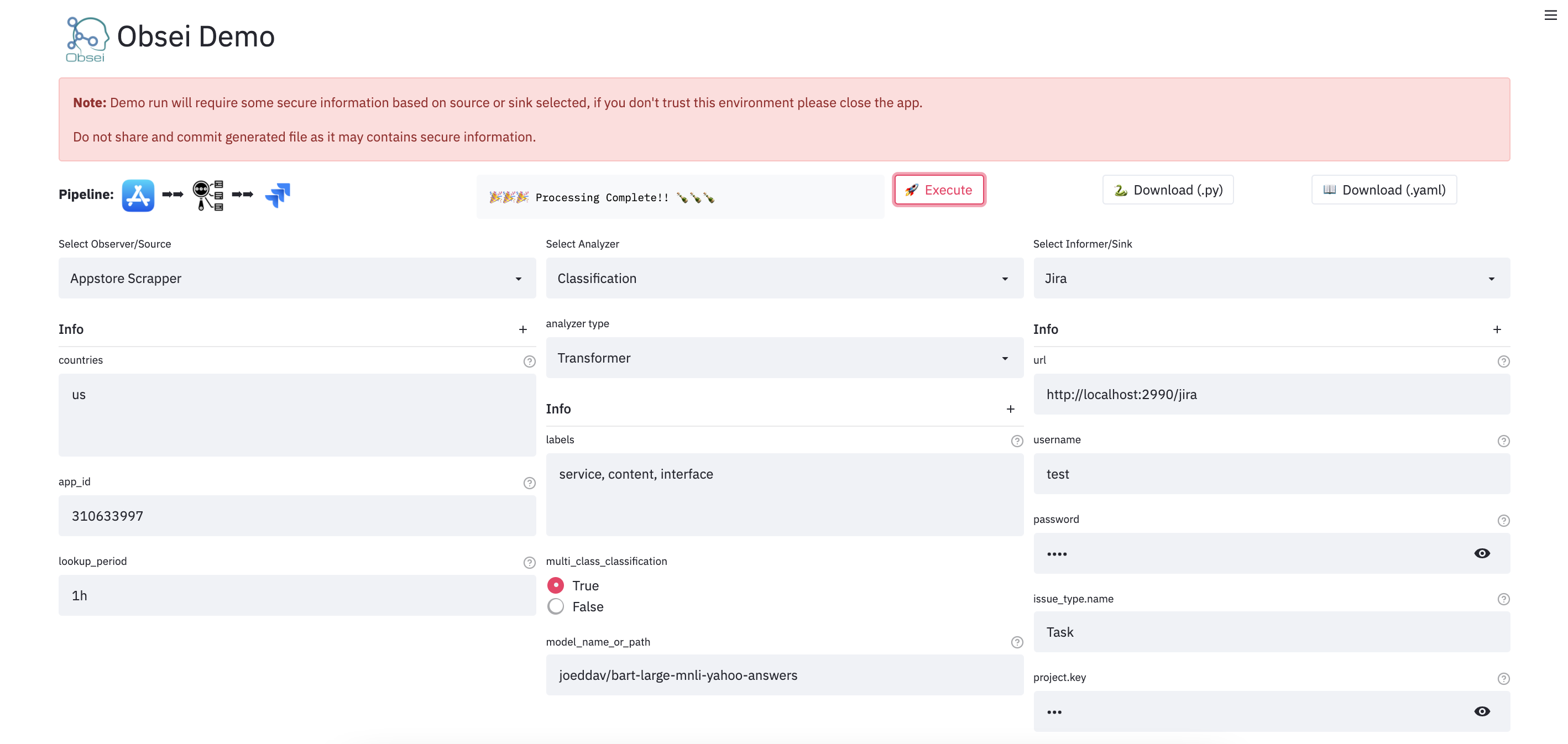
Check demo at
(Note: Sometimes the Streamlit demo might not work due to rate limiting, use the docker image (locally) in such cases.)
To test locally, just run
docker run -d --name obesi-ui -p 8501:8501 obsei/obsei-ui-demo
# You can find the UI at http://localhost:8501
To run Obsei workflow easily using GitHub Actions (no sign ups and cloud hosting required), refer to this repo.
Here are some companies/projects (alphabetical order) using Obsei. To add your company/project to the list, please raise a PR or contact us via email.
- Oraika: Contextually understand customer feedback
- 1Page: Giving a better context in meetings and calls
- Spacepulse: The operating system for spaces
- Superblog: A blazing fast alternative to WordPress and Medium
- Zolve: Creating a financial world beyond borders
- Utilize: No-code app builder for businesses with a deskless workforce
| Sr. No. | Title | Author |
|---|---|---|
| 1 | AI based Comparative Customer Feedback Analysis Using Obsei | Reena Bapna |
| 2 | LinkedIn App - User Feedback Analysis | Himanshu Sharma |
| Sr. No. | Workflow | Colab | Binder |
|---|---|---|---|
| 1 | Observe app reviews from Google play store, Analyze them by performing text classification and then Inform them on console via logger | ||
| PlayStore Reviews → Classification → Logger |
|
|
|
| 2 | Observe app reviews from Google play store, PreProcess text via various text cleaning functions, Analyze them by performing text classification, Inform them to Pandas DataFrame and store resultant CSV to Google Drive | ||
| PlayStore Reviews → PreProcessing → Classification → Pandas DataFrame → CSV in Google Drive |
|
|
|
| 3 | Observe app reviews from Apple app store, PreProcess text via various text cleaning function, Analyze them by performing text classification, Inform them to Pandas DataFrame and store resultant CSV to Google Drive | ||
| AppStore Reviews → PreProcessing → Classification → Pandas DataFrame → CSV in Google Drive |
|
|
|
| 4 | Observe news article from Google news, PreProcess text via various text cleaning function, Analyze them via performing text classification while splitting text in small chunks and later computing final inference using given formula | ||
| Google News → Text Cleaner → Text Splitter → Classification → Inference Aggregator |
|
|
|
💡Tips: Handle large text classification via Obsei

For detailed installation instructions, usages and examples, refer to our documentation.
| Linux | Mac | Windows | Remark | |
|---|---|---|---|---|
| Tests | ✅ | ✅ | ✅ | Low Coverage as difficult to test 3rd party libs |
| PIP | ✅ | ✅ | ✅ | Fully Supported |
| Conda | ❌ | ❌ | ❌ | Not Supported |
Discussion about Obsei can be done at community forum
Refer releases for changelogs
For any security issue please contact us via email

This project is being maintained by Oraika Technologies. Lalit Pagaria and Girish Patel are maintainers of this project.
- Copyright holder: Oraika Technologies
- Overall Apache 2.0 and you can read License file.
- Multiple other secondary permissive or weak copyleft licenses (LGPL, MIT, BSD etc.) for third-party components refer Attribution.
- To make project more commercial friendly, we void third party components which have strong copyleft licenses (GPL, AGPL etc.) into the project.
This could not have been possible without these open source softwares.
First off, thank you for even considering contributing to this package, every contribution big or small is greatly appreciated. Please refer our Contribution Guideline and Code of Conduct.
Thanks so much to all our contributors
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for obsei
Similar Open Source Tools
obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
UnrealGenAISupport
The Unreal Engine Generative AI Support Plugin is a tool designed to integrate various cutting-edge LLM/GenAI models into Unreal Engine for game development. It aims to simplify the process of using AI models for game development tasks, such as controlling scene objects, generating blueprints, running Python scripts, and more. The plugin currently supports models from organizations like OpenAI, Anthropic, XAI, Google Gemini, Meta AI, Deepseek, and Baidu. It provides features like API support, model control, generative AI capabilities, UI generation, project file management, and more. The plugin is still under development but offers a promising solution for integrating AI models into game development workflows.
NextChat
NextChat is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro. It offers a compact client for Linux, Windows, and MacOS, with features like self-deployed LLMs compatibility, privacy-first data storage, markdown support, responsive design, and fast loading speed. Users can create, share, and debug chat tools with prompt templates, access various prompts, compress chat history, and use multiple languages. The tool also supports enterprise-level privatization and customization deployment, with features like brand customization, resource integration, permission control, knowledge integration, security auditing, private deployment, and continuous updates.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐

context7
Context7 is a powerful tool for analyzing and visualizing data in various formats. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With advanced features such as data filtering, aggregation, and customization, Context7 is suitable for both beginners and experienced data analysts. The tool supports a wide range of data sources and formats, making it versatile for different use cases. Whether you are working on exploratory data analysis, data visualization, or data storytelling, Context7 can help you uncover valuable insights and communicate your findings effectively.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.

ragflow
RAGFlow is an open-source Retrieval-Augmented Generation (RAG) engine that combines deep document understanding with Large Language Models (LLMs) to provide accurate question-answering capabilities. It offers a streamlined RAG workflow for businesses of all sizes, enabling them to extract knowledge from unstructured data in various formats, including Word documents, slides, Excel files, images, and more. RAGFlow's key features include deep document understanding, template-based chunking, grounded citations with reduced hallucinations, compatibility with heterogeneous data sources, and an automated and effortless RAG workflow. It supports multiple recall paired with fused re-ranking, configurable LLMs and embedding models, and intuitive APIs for seamless integration with business applications.
Free-GPT4-WEB-API
FreeGPT4-WEB-API is a Python server that allows you to have a self-hosted GPT-4 Unlimited and Free WEB API, via the latest Bing's AI. It uses Flask and GPT4Free libraries. GPT4Free provides an interface to the Bing's GPT-4. The server can be configured by editing the `FreeGPT4_Server.py` file. You can change the server's port, host, and other settings. The only cookie needed for the Bing model is `_U`.
AutoRAG
AutoRAG is an AutoML tool designed to automatically find the optimal RAG pipeline for your data. It simplifies the process of evaluating various RAG modules to identify the best pipeline for your specific use-case. The tool supports easy evaluation of different module combinations, making it efficient to find the most suitable RAG pipeline for your needs. AutoRAG also offers a cloud beta version to assist users in running and optimizing the tool, along with building RAG evaluation datasets for a starting price of $9.99 per optimization.
docutranslate
Docutranslate is a versatile tool for translating documents efficiently. It supports multiple file formats and languages, making it ideal for businesses and individuals needing quick and accurate translations. The tool uses advanced algorithms to ensure high-quality translations while maintaining the original document's formatting. With its user-friendly interface, Docutranslate simplifies the translation process and saves time for users. Whether you need to translate legal documents, technical manuals, or personal letters, Docutranslate is the go-to solution for all your document translation needs.
catai
CatAI is a tool that allows users to run GGUF models on their computer with a chat UI. It serves as a local AI assistant inspired by Node-Llama-Cpp and Llama.cpp. The tool provides features such as auto-detecting programming language, showing original messages by clicking on user icons, real-time text streaming, and fast model downloads. Users can interact with the tool through a CLI that supports commands for installing, listing, setting, serving, updating, and removing models. CatAI is cross-platform and supports Windows, Linux, and Mac. It utilizes node-llama-cpp and offers a simple API for asking model questions. Additionally, developers can integrate the tool with node-llama-cpp@beta for model management and chatting. The configuration can be edited via the web UI, and contributions to the project are welcome. The tool is licensed under Llama.cpp's license.
gpt-translate
Markdown Translation BOT is a GitHub action that translates markdown files into multiple languages using various AI models. It supports markdown, markdown-jsx, and json files only. The action can be executed by individuals with write permissions to the repository, preventing API abuse by non-trusted parties. Users can set up the action by providing their API key and configuring the workflow settings. The tool allows users to create comments with specific commands to trigger translations and automatically generate pull requests or add translated files to existing pull requests. It supports multiple file translations and can interpret any language supported by GPT-4 or GPT-3.5.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.
repomix
Repomix is a powerful tool that packs your entire repository into a single, AI-friendly file. It is designed to format your codebase for easy understanding by AI tools like Large Language Models (LLMs), Claude, ChatGPT, and Gemini. Repomix offers features such as AI optimization, token counting, simplicity in usage, customization options, Git awareness, and security-focused checks using Secretlint. It allows users to pack their entire repository or specific directories/files using glob patterns, and even supports processing remote Git repositories. The tool generates output in plain text, XML, or Markdown formats, with options for including/excluding files, removing comments, and performing security checks. Repomix also provides a global configuration option, custom instructions for AI context, and a security check feature to detect sensitive information in files.
For similar tasks

comet-llm
CometLLM is a tool to log and visualize your LLM prompts and chains. Use CometLLM to identify effective prompt strategies, streamline your troubleshooting, and ensure reproducible workflows!
obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.
read-frog
Read-frog is a powerful text analysis tool designed to help users extract valuable insights from text data. It offers a wide range of features including sentiment analysis, keyword extraction, entity recognition, and text summarization. With its user-friendly interface and robust algorithms, Read-frog is suitable for both beginners and advanced users looking to analyze text data for various purposes such as market research, social media monitoring, and content optimization. Whether you are a data scientist, marketer, researcher, or student, Read-frog can streamline your text analysis workflow and provide actionable insights to drive decision-making and enhance productivity.
ALwrity
ALwrity is a lightweight and user-friendly text analysis tool designed for developers and data scientists. It provides various functionalities for analyzing and processing text data, including sentiment analysis, keyword extraction, and text summarization. With ALwrity, users can easily gain insights from their text data and make informed decisions based on the analysis results. The tool is highly customizable and can be integrated into existing workflows seamlessly, making it a valuable asset for anyone working with text data in their projects.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.
LLM-Alchemy-Chamber
LLM Alchemy Chamber is a repository dedicated to exploring the world of Language Models (LLMs) through various experiments and projects. It contains scripts, notebooks, and experiments focused on tasks such as fine-tuning different LLM models, quantization for performance optimization, dataset generation for instruction/QA tasks, and more. The repository offers a collection of resources for beginners and enthusiasts interested in delving into the mystical realm of LLMs.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.