
ebook2audiobook
Convert ebooks to audiobooks with chapters and metadata using dynamic AI models and voice cloning. Supports 1,107+ languages!
Stars: 9221

ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
README:
CPU/GPU Converter from eBooks to audiobooks with chapters and metadata
using XTTSv2, Bark, Vits, Fairseq, YourTTS and more. Supports voice cloning and +1110 languages!
[!IMPORTANT] This tool is intended for use with non-DRM, legally acquired eBooks only.
The authors are not responsible for any misuse of this software or any resulting legal consequences.
Use this tool responsibly and in accordance with all applicable laws.
Thanks to support ebook2audiobook developers!
![]()

Click to see images of Web GUI



- ara العربية (Arabic)
- zho 中文 (Chinese)
- eng English
- swe Svenska (Swedish)
- fas فارسی (Persian)
- kor 한국어 (Korean)
- ita Italiano (Italian)
- ebook2audiobook
- Features
- Docker GUI Interface
- Huggingface Space Demo
- Free Google Colab
- Pre-made Audio Demos
- Supported Languages
- Requirements
- Installation Instructions
- Usage
- Fine Tuned TTS models
- Using Docker
- Supported eBook Formats
- Output
- Common Issues
- Special Thanks
- Join Our Server!
- Legacy
- Table of Contents
- 📖 Converts eBooks to text format with Calibre.
- 📚 Splits eBook into chapters for organized audio.
- 🎙️ High-quality text-to-speech with Coqui XTTSv2 and Fairseq (and more).
- 🗣️ Optional voice cloning with your own voice file.
- 🌍 Supports +1110 languages (English by default). List of Supported languages
- 🖥️ Designed to run on 4GB RAM.
- Huggingface space is running on free cpu tier so expect very slow or timeout lol, just do not give it giant files is all
- Best to duplicate space or run locally.
| Arabic (ar) | Chinese (zh) | English (en) | Spanish (es) |
|---|---|---|---|
| French (fr) | German (de) | Italian (it) | Portuguese (pt) |
| Polish (pl) | Turkish (tr) | Russian (ru) | Dutch (nl) |
| Czech (cs) | Japanese (ja) | Hindi (hi) | Bengali (bn) |
| Hungarian (hu) | Korean (ko) | Vietnamese (vi) | Swedish (sv) |
| Persian (fa) | Yoruba (yo) | Swahili (sw) | Indonesian (id) |
| Slovak (sk) | Croatian (hr) | Tamil (ta) | Danish (da) |
- 4gb RAM minimum, 8GB recommended
- Virtualization enabled if running on windows (Docker only)
- CPU (intel, AMD, ARM), GPU (Nvidia, AMD*, Intel*) (Recommended), MPS (Apple Silicon CPU) *available very soon
[!IMPORTANT] Before to post an install or bug issue search carefully to the opened and closed issues TAB
to be sure your issue does not exist already.
[!NOTE] Lacking of any standards structure like what is a chapter, paragraph, preface etc.
you should first remove manually any text you don't want to be converted in audio.
- Clone repo
git clone https://github.com/DrewThomasson/ebook2audiobook.git-
Run ebook2audiobook:
-
Linux/MacOS
./ebook2audiobook.sh # Run launch script -
Mac Launcher
Double clickMac Ebook2Audiobook Launcher.command -
Windows
.\ebook2audiobook.cmd # Run launch script or double click on it
-
Windows Launcher
Double clickebook2audiobook.exe
-
Linux/MacOS
- Open the Web App: Click the URL provided in the terminal to access the web app and convert eBooks.
-
For Public Link:
python app.py --share(all OS)./ebook2audiobook.sh --share(Linux/MacOS)ebook2audiobook.cmd --share(Windows)
[!IMPORTANT] If the script is stopped and run again, you need to refresh your gradio GUI interface
to let the web page reconnect to the new connection socket.
-
Linux/MacOS:
./ebook2audiobook.sh --headless --ebook <path_to_ebook_file> \ --voice [path_to_voice_file] --language [language_code]
-
Windows
.\ebook2audiobook.cmd --headless --ebook <path_to_ebook_file> --voice [path_to_voice_file] --language [language_code]
-
[--ebook]: Path to your eBook file
-
[--voice]: Voice cloning file path (optional)
-
[--language]: Language code in ISO-639-3 (i.e.: ita for italian, eng for english, deu for german...).
Default language is eng and --language is optional for default language set in ./lib/lang.py.
The ISO-639-1 2 letters codes are also supported.
(must be a .zip file containing the mandatory model files. Example for XTTS: config.json, model.pth, vocab.json and ref.wav)
-
Linux/MacOS
./ebook2audiobook.sh --headless --ebook <ebook_file_path> \ --voice <target_voice_file_path> --language <language> --custom_model <custom_model_path>
-
Windows
.\ebook2audiobook.cmd --headless --ebook <ebook_file_path> \ --voice <target_voice_file_path> --language <language> --custom_model <custom_model_path>
-
<custom_model_path>: Path to
model_name.zipfile, which must contain (according to the tts engine) all the mandatory files
(see ./lib/models.py).
-
Linux/MacOS
./ebook2audiobook.sh --help
-
Windows
.\ebook2audiobook.cmd --help -
Or for all OS
python app.py --help
usage: app.py [-h] [--script_mode SCRIPT_MODE] [--session SESSION] [--share]
[--headless] [--ebook EBOOK] [--ebooks_dir EBOOKS_DIR]
[--language LANGUAGE] [--voice VOICE] [--device {cpu,gpu,mps}]
[--tts_engine {xtts,bark,vits,fairseq,yourtts}]
[--custom_model CUSTOM_MODEL] [--fine_tuned FINE_TUNED]
[--output_format OUTPUT_FORMAT] [--temperature TEMPERATURE]
[--length_penalty LENGTH_PENALTY] [--num_beams NUM_BEAMS]
[--repetition_penalty REPETITION_PENALTY] [--top_k TOP_K] [--top_p TOP_P]
[--speed SPEED] [--enable_text_splitting] [--output_dir OUTPUT_DIR]
[--version]
Convert eBooks to Audiobooks using a Text-to-Speech model. You can either launch the Gradio interface or run the script in headless mode for direct conversion.
options:
-h, --help show this help message and exit
--session SESSION Session to resume the conversion in case of interruption, crash,
or reuse of custom models and custom cloning voices.
**** The following option are for gradio/gui mode only:
Optional
--share Enable a public shareable Gradio link.
**** The following options are for --headless mode only:
--headless Run the script in headless mode
--ebook EBOOK Path to the ebook file for conversion. Cannot be used when --ebooks_dir is present.
--ebooks_dir EBOOKS_DIR
Relative or absolute path of the directory containing the files to convert.
Cannot be used when --ebook is present.
--language LANGUAGE Language of the e-book. Default language is set
in ./lib/lang.py sed as default if not present. All compatible language codes are in ./lib/lang.py
optional parameters:
--voice VOICE (Optional) Path to the voice cloning file for TTS engine.
Uses the default voice if not present.
--device {cpu,gpu,mps}
(Optional) Pprocessor unit type for the conversion.
Default is set in ./lib/conf.py if not present. Fall back to CPU if GPU not available.
--tts_engine {xtts,bark,vits,fairseq,yourtts}
(Optional) Preferred TTS engine (available are: ['xtts', 'bark', 'vits', 'fairseq', 'yourtts'].
Default depends on the selected language. The tts engine should be compatible with the chosen language
--custom_model CUSTOM_MODEL
(Optional) Path to the custom model zip file cntaining mandatory model files.
Please refer to ./lib/models.py
--fine_tuned FINE_TUNED
(Optional) Fine tuned model path. Default is builtin model.
--output_format OUTPUT_FORMAT
(Optional) Output audio format. Default is set in ./lib/conf.py
--temperature TEMPERATURE
(xtts only, optional) Temperature for the model.
Default to config.json model. Higher temperatures lead to more creative outputs.
--length_penalty LENGTH_PENALTY
(xtts only, optional) A length penalty applied to the autoregressive decoder.
Default to config.json model. Not applied to custom models.
--num_beams NUM_BEAMS
(xtts only, optional) Controls how many alternative sequences the model explores. Must be equal or greater than length penalty.
Default to config.json model.
--repetition_penalty REPETITION_PENALTY
(xtts only, optional) A penalty that prevents the autoregressive decoder from repeating itself.
Default to config.json model.
--top_k TOP_K (xtts only, optional) Top-k sampling.
Lower values mean more likely outputs and increased audio generation speed.
Default to config.json model.
--top_p TOP_P (xtts only, optional) Top-p sampling.
Lower values mean more likely outputs and increased audio generation speed. Default to 0.85
--speed SPEED (xtts only, optional) Speed factor for the speech generation.
Default to config.json model.
--enable_text_splitting
(xtts only, optional) Enable TTS text splitting. This option is known to not be very efficient.
Default to config.json model.
--output_dir OUTPUT_DIR
(Optional) Path to the output directory. Default is set in ./lib/conf.py
--version Show the version of the script and exit
Example usage:
Windows:
Gradio/GUI:
ebook2audiobook.cmd
Headless mode:
ebook2audiobook.cmd --headless --ebook '/path/to/file'
Linux/Mac:
Gradio/GUI:
./ebook2audiobook.sh
Headless mode:
./ebook2audiobook.sh --headless --ebook '/path/to/file'NOTE: in gradio/gui mode, to cancel a running conversion, just click on the [X] from the ebook upload component.
You can also use Docker to run the eBook to Audiobook converter. This method ensures consistency across different environments and simplifies setup.
To run the Docker container and start the Gradio interface, use the following command:
-Run with CPU only
docker run --rm -p 7860:7860 athomasson2/ebook2audiobook-Run with GPU Speedup (NVIDIA compatible only)
docker run --rm --gpus all -p 7860:7860 athomasson2/ebook2audiobook- You can build the docker image with the command:
docker build -t athomasson2/ebook2audiobook .This command will start the Gradio interface on port 7860.(localhost:7860)
- For more options add the parameter
--help
All ebook2audiobooks will have the base dir of /home/user/app/
For example:
tmp = /home/user/app/tmp
audiobooks = /home/user/app/audiobooks
first for a docker pull of the latest with
docker pull athomasson2/ebook2audiobook- Before you do run this you need to create a dir named "input-folder" in your current dir which will be linked, This is where you can put your input files for the docker image to see
mkdir input-folder && mkdir Audiobooks- In the command below swap out YOUR_INPUT_FILE.TXT with the name of your input file
docker run --rm \
-v $(pwd)/input-folder:/app/input_folder \
-v $(pwd)/audiobooks:/app/audiobooks \
athomasson2/ebook2audiobook \
--headless --ebook /input_folder/YOUR_EBOOK_FILE- And that should be it!
- The output Audiobooks will be found in the Audiobook folder which will also be located in your local dir you ran this docker command in
docker run --rm athomasson2/ebook2audiobook --help
and that will output this Help command output
This project uses Docker Compose to run locally. You can enable or disable GPU support
by setting either *gpu-enabled or *gpu-disabled in docker-compose.yml
-
Clone the Repository (if you haven't already):
git clone https://github.com/DrewThomasson/ebook2audiobook.git cd ebook2audiobook -
Set GPU Support (disabled by default)
To enable GPU support, modify
docker-compose.ymland change*gpu-disabledto*gpu-enabled -
Start the service:
docker-compose up -d
- Access the service: The service will be available at http://localhost:7860.
Click to see images of Web GUI
Don't have the hardware to run it or you want to rent a GPU?
(Be aware it will time out after a bit of your not messing with the google colab) Free Google Colab
-
python: can't open file '/home/user/app/app.py': [Errno 2] No such file or directory(Just remove all post arguments as I replaced theCMDwithENTRYPOINTin the Dockerfile)- Example:
docker run athomasson2/ebook2audiobook app.py --script_mode full_docker- > corrected - >docker run athomasson2/ebook2audiobook - Arguments can be easily added like this now
docker run athomasson2/ebook2audiobook --share
- Example:
-
Docker gets stuck downloading Fine-Tuned models. (This does not happen for every computer but some appear to run into this issue) Disabling the progress bar appears to fix the issue, as discussed here in #191 Example of adding this fix in the
docker runcommand
docker run --rm --gpus all -e HF_HUB_DISABLE_PROGRESS_BARS=1 -e HF_HUB_ENABLE_HF_TRANSFER=0 \
-p 7860:7860 athomasson2/ebook2audiobookYou can fine-tune your own xtts model easily with this repo xtts-finetune-webui
If you want to rent a GPU easily you can also duplicate this huggingface xtts-finetune-webui-space
A space you can use to de-noise the training data easily also denoise-huggingface-space
To find our collection of already fine-tuned TTS models, visit this Hugging Face link For an XTTS custom model a ref audio clip of the voice reference is mandatory:
Rainy day voice https://github.com/user-attachments/assets/d25034d9-c77f-43a9-8f14-0d167172b080
David Attenborough voice https://github.com/user-attachments/assets/0d437a41-0b0d-48ed-8c9b-02763d5e48ea
-
.epub,.pdf,.mobi,.txt,.html,.rtf,.chm,.lit,.pdb,.fb2,.odt,.cbr,.cbz,.prc,.lrf,.pml,.snb,.cbc,.rb,.tcr -
Best results:
.epubor.mobifor automatic chapter detection
- Creates a
['m4b', 'm4a', 'mp4', 'webm', 'mov', 'mp3', 'flac', 'wav', 'ogg', 'aac'](set in ./lib/conf.py) file with metadata and chapters. -
Example


- CPU is slow (better on server smp CPU) while NVIDIA GPU can have almost real time conversion. Discussion about this For faster multilingual generation I would suggest my other project that uses piper-tts instead (It doesn't have zero-shot voice cloning though, and is Siri quality voices, but it is much faster on cpu).
- "I'm having dependency issues" - Just use the docker, its fully self contained and has a headless mode,
add
--helpparameter at the end of the docker run command for more information. - "Im getting a truncated audio issue!" - PLEASE MAKE AN ISSUE OF THIS, we don't speak every language and need advise from users to fine tune the sentence splitting logic.😊
- Any help from people speaking any of the supported languages to help with proper sentence splitting methods
- Potentially creating readme Guides for Multiple languages(Becuase the only language I know is English 😔)
- Coqui TTS: Coqui TTS GitHub
- Calibre: Calibre Website
- FFmpeg: FFmpeg Website
- @shakenbake15 for better chapter saving method
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ebook2audiobook
Similar Open Source Tools
ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
AiR
AiR is an AI tool built entirely in Rust that delivers blazing speed and efficiency. It features accurate translation and seamless text rewriting to supercharge productivity. AiR is designed to assist non-native speakers by automatically fixing errors and polishing language to sound like a native speaker. The tool is under heavy development with more features on the horizon.
cog
Cog is an open-source tool that lets you package machine learning models in a standard, production-ready container. You can deploy your packaged model to your own infrastructure, or to Replicate.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐
swift-chat
SwiftChat is a fast and responsive AI chat application developed with React Native and powered by Amazon Bedrock. It offers real-time streaming conversations, AI image generation, multimodal support, conversation history management, and cross-platform compatibility across Android, iOS, and macOS. The app supports multiple AI models like Amazon Bedrock, Ollama, DeepSeek, and OpenAI, and features a customizable system prompt assistant. With a minimalist design philosophy and robust privacy protection, SwiftChat delivers a seamless chat experience with various features like rich Markdown support, comprehensive multimodal analysis, creative image suite, and quick access tools. The app prioritizes speed in launch, request, render, and storage, ensuring a fast and efficient user experience. SwiftChat also emphasizes app privacy and security by encrypting API key storage, minimal permission requirements, local-only data storage, and a privacy-first approach.
llm-x
LLM X is a ChatGPT-style UI for the niche group of folks who run Ollama (think of this like an offline chat gpt server) locally. It supports sending and receiving images and text and works offline through PWA (Progressive Web App) standards. The project utilizes React, Typescript, Lodash, Mobx State Tree, Tailwind css, DaisyUI, NextUI, Highlight.js, React Markdown, kbar, Yet Another React Lightbox, Vite, and Vite PWA plugin. It is inspired by ollama-ui's project and Perplexity.ai's UI advancements in the LLM UI space. The project is still under development, but it is already a great way to get started with building your own LLM UI.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
openai-chat-api-workflow
**OpenAI Chat API Workflow for Alfred** An Alfred 5 Workflow for using OpenAI Chat API to interact with GPT-3.5/GPT-4 🤖💬 It also allows image generation 🖼️, image understanding 👀, speech-to-text conversion 🎤, and text-to-speech synthesis 🔈 **Features:** * Execute all features using Alfred UI, selected text, or a dedicated web UI * Web UI is constructed by the workflow and runs locally on your Mac 💻 * API call is made directly between the workflow and OpenAI, ensuring your chat messages are not shared online with anyone other than OpenAI 🔒 * OpenAI does not use the data from the API Platform for training 🚫 * Export chat data to a simple JSON format external file 📄 * Continue the chat by importing the exported data later 🔄
DesktopCommanderMCP
Desktop Commander MCP is a server that allows the Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP). It is built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities. The tool enables users to execute terminal commands with output streaming, manage processes, perform full filesystem operations, and edit code with surgical text replacements or full file rewrites. It also supports vscode-ripgrep based recursive code or text search in folders.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.
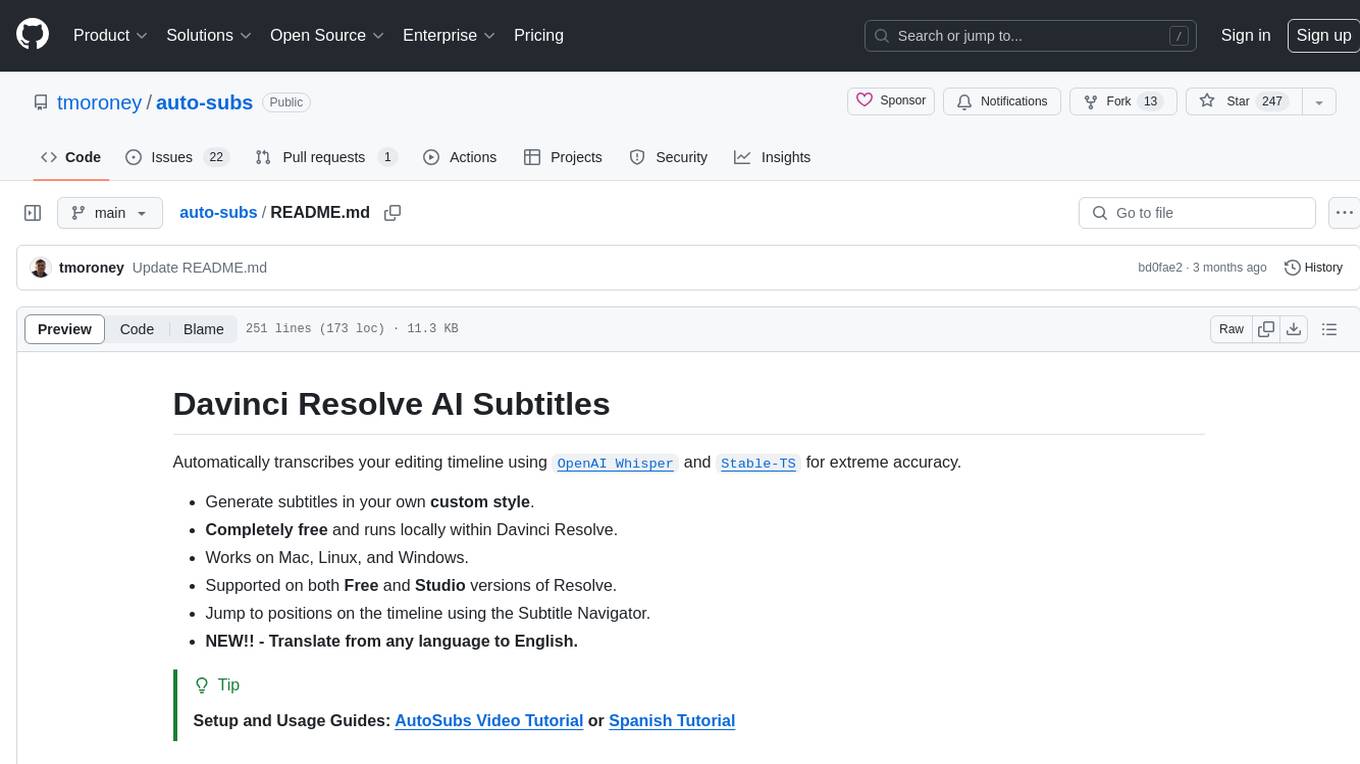
auto-subs
Auto-subs is a tool designed to automatically transcribe editing timelines using OpenAI Whisper and Stable-TS for extreme accuracy. It generates subtitles in a custom style, is completely free, and runs locally within Davinci Resolve. It works on Mac, Linux, and Windows, supporting both Free and Studio versions of Resolve. Users can jump to positions on the timeline using the Subtitle Navigator and translate from any language to English. The tool provides a user-friendly interface for creating and customizing subtitles for video content.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.
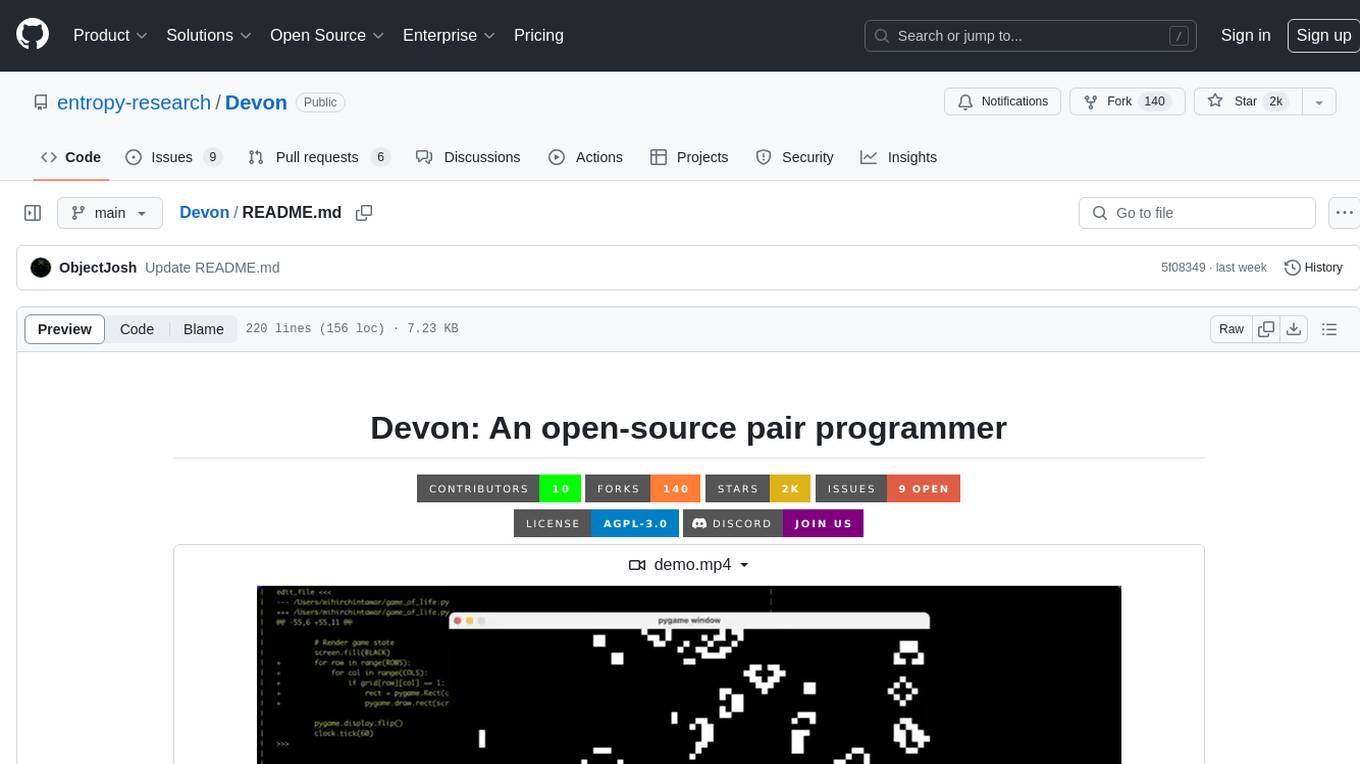
Devon
Devon is an open-source pair programmer tool designed to facilitate collaborative coding sessions. It provides features such as multi-file editing, codebase exploration, test writing, bug fixing, and architecture exploration. The tool supports Anthropic, OpenAI, and Groq APIs, with plans to add more models in the future. Devon is community-driven, with ongoing development goals including multi-model support, plugin system for tool builders, self-hostable Electron app, and setting SOTA on SWE-bench Lite. Users can contribute to the project by developing core functionality, conducting research on agent performance, providing feedback, and testing the tool.
For similar tasks

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
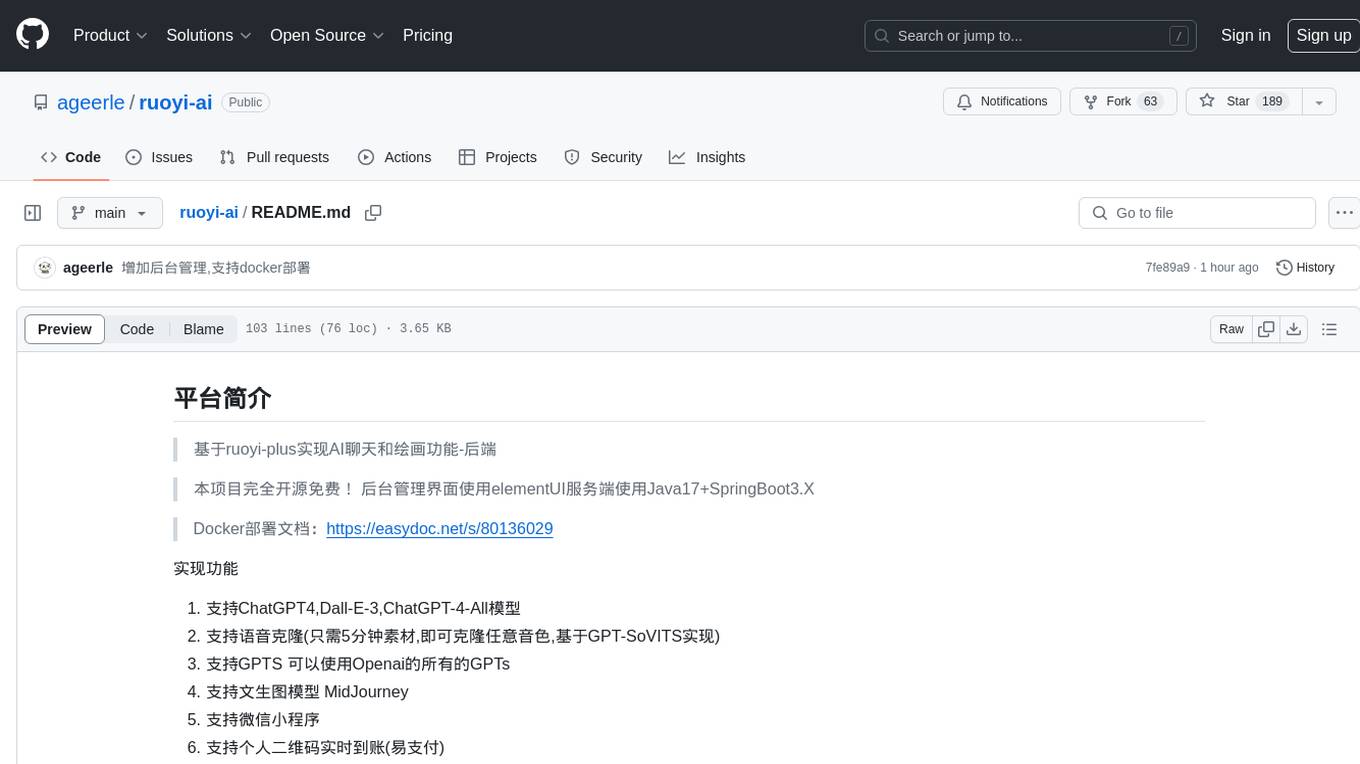
ruoyi-ai
ruoyi-ai is a platform built on top of ruoyi-plus to implement AI chat and drawing functionalities on the backend. The project is completely open source and free. The backend management interface uses elementUI, while the server side is built using Java 17 and SpringBoot 3.X. It supports various AI models such as ChatGPT4, Dall-E-3, ChatGPT-4-All, voice cloning based on GPT-SoVITS, GPTS, and MidJourney. Additionally, it supports WeChat mini programs, personal QR code real-time payments, monitoring and AI auto-reply in live streaming rooms like Douyu and Bilibili, and personal WeChat integration with ChatGPT. The platform also includes features like private knowledge base management and provides various demo interfaces for different platforms such as mobile, web, and PC.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.
ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
For similar jobs
ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.
Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
audiobook-creator
Audiobook Creator is an open-source tool that converts books in various text formats into fully voiced audiobooks with intelligent character voice attribution. It utilizes NLP, LLMs, and TTS technologies to provide an engaging audiobook experience. The project includes components for text cleaning and formatting, character identification, and audiobook generation. Key features include a Gradio UI app, M4B audiobook creation, multi-format support, Docker compatibility, customizable narration, progress tracking, and open-source licensing.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.
WebAI-to-API
This project implements a web API that offers a unified interface to Google Gemini and Claude 3. It provides a self-hosted, lightweight, and scalable solution for accessing these AI models through a streaming API. The API supports both Claude and Gemini models, allowing users to interact with them in real-time. The project includes a user-friendly web UI for configuration and documentation, making it easy to get started and explore the capabilities of the API.
openai-chat-api-workflow
**OpenAI Chat API Workflow for Alfred** An Alfred 5 Workflow for using OpenAI Chat API to interact with GPT-3.5/GPT-4 🤖💬 It also allows image generation 🖼️, image understanding 👀, speech-to-text conversion 🎤, and text-to-speech synthesis 🔈 **Features:** * Execute all features using Alfred UI, selected text, or a dedicated web UI * Web UI is constructed by the workflow and runs locally on your Mac 💻 * API call is made directly between the workflow and OpenAI, ensuring your chat messages are not shared online with anyone other than OpenAI 🔒 * OpenAI does not use the data from the API Platform for training 🚫 * Export chat data to a simple JSON format external file 📄 * Continue the chat by importing the exported data later 🔄
BlossomLM
BlossomLM is a series of open-source conversational large language models. This project aims to provide a high-quality general-purpose SFT dataset in both Chinese and English, making fine-tuning accessible while also providing pre-trained model weights. **Hint**: BlossomLM is a personal non-commercial project.