
HeyGem.ai
None
Stars: 2548
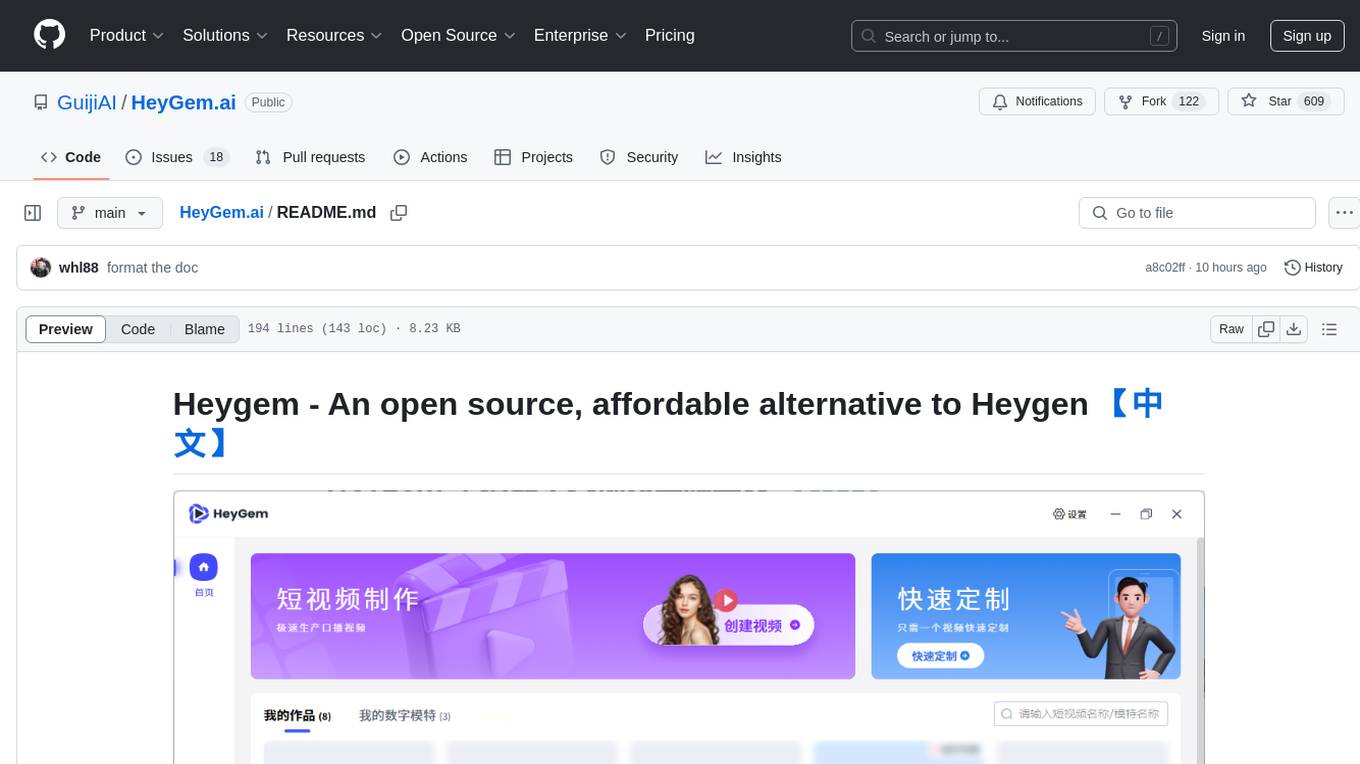
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
README:
Heygem - Open Source Alternative to Heygen 【切换中文】
Dear Heygem Open Source Community Members:
We sincerely thank you for your enthusiastic attention and active participation in the Heygem digital human open source project! We have noticed that some developers face challenges during local deployment. To better meet the needs of different scenarios, we are now announcing two parallel service solutions:
| Project | HeyGem Open Source Local Deployment | Digital Human/Clone Voice API Service |
|---|---|---|
| Usage | Open Source Local Deployment | Rapid Clone API Service |
| Recommended | Technical Users | Business Users |
| Technical Threshold | Developers with deep learning framework experience/pursuing deep customization/wishing to participate in community co-construction | Quick business integration/focus on upper-level application development/need enterprise-level SLA assurance for commercial scenarios |
| Hardware Requirements | Need to purchase GPU server | No need to purchase GPU server |
| Customization | Can modify and extend the code according to your needs, fully controlling the software's functions and behavior | Cannot directly modify the source code, can only extend functions through API-provided interfaces, less flexible than open source projects |
| Technical Support | Community Support | Dynamic expansion support + professional technical response team |
| Maintenance Cost | High maintenance cost | Simple maintenance |
| Lip Sync Effect | Usable effect | Stunning and higher definition effect |
| Commercial Authorization | Commercial use in Mainland China, Hong Kong, and Macau requires prior application, while other countries are unrestricted. | Commercial use allowed |
| Iteration Speed | Slow updates, bug fixes depend on the community | Latest models/algorithms are prioritized, fast problem resolution |
We always adhere to the open source spirit, and the launch of the API service aims to provide a more complete solution matrix for developers with different needs. No matter which method you choose, you can always obtain technical support documents through [email protected]. We look forward to working with you to promote the inclusive development of digital human technology!
Silicon-based Intelligent Developer Team
Rapid Clone API | API Documentation Center
Real-time Interaction SDK | SDK Documentation Center


Heygem is a fully offline video synthesis tool designed for Windows systems that can precisely clone your appearance and voice, digitalizing your image. You can create videos by driving virtual avatars through text and voice. No internet connection is required, protecting your privacy while enjoying convenient and efficient digital experiences.
- Core Features
- Precise Appearance and Voice Cloning: Using advanced AI algorithms to capture human facial features with high precision, including facial features, contours, etc., to build realistic virtual models. It can also precisely clone voices, capturing and reproducing subtle characteristics of human voices, supporting various voice parameter settings to create highly similar cloning effects.
- Text and Voice-Driven Virtual Avatars: Understanding text content through natural language processing technology, converting text into natural and fluent speech to drive virtual avatars. Voice input can also be used directly, allowing virtual avatars to perform corresponding actions and facial expressions based on the rhythm and intonation of the voice, making the virtual avatar's performance more natural and vivid.
- Efficient Video Synthesis: Highly synchronizing digital human video images with sound, achieving natural and smooth lip-syncing, intelligently optimizing audio-video synchronization effects.
- Multi-language Support: Scripts support eight languages - English, Japanese, Korean, Chinese, French, German, Arabic, and Spanish.
- Key Advantages
- Fully Offline Operation: No internet connection required, effectively protecting user privacy, allowing users to create in a secure, independent environment, avoiding potential data leaks during network transmission.
- User-Friendly: Clean and intuitive interface, easy to use even for beginners with no technical background, quickly mastering the software's usage to start their digital human creation journey.
- Multiple Model Support: Supports importing multiple models and managing them through one-click startup packages, making it convenient for users to choose suitable models based on different creative needs and application scenarios.
- Technical Support
- Voice Cloning Technology: Using advanced technologies like artificial intelligence to generate similar or identical voices based on given voice samples, covering context, intonation, speed, and other aspects of speech.
- Automatic Speech Recognition: Technology that converts human speech vocabulary content into computer-readable input (text format), enabling computers to "understand" human speech.
- Computer Vision Technology: Used in video synthesis for visual processing, including facial recognition and lip movement analysis, ensuring virtual avatar lip movements match voice and text content.
- Nodejs 18
- Docker Images
- docker pull guiji2025/fun-asr
- docker pull guiji2025/fish-speech-ziming
- docker pull guiji2025/heygem.ai
-
Must have D Drive: Mainly used for storing digital human and project data
- Free space requirement: More than 30GB
-
C Drive: Used for storing service image files
-
Free space requirement: More than 100GB
-
If less than 100GB is available, after installing Docker, you can choose a different disk folder with more than 100GB of remaining space at the location shown below.

-
-
System Requirements:
- Currently supports Windows 10 19042.1526 or higher
-
Recommended Configuration:
- CPU: 13th Gen Intel Core i5-13400F
- Memory: 32GB
- Graphics Card: RTX 4070
-
Ensure you have an NVIDIA graphics card with properly installed drivers
NVIDIA driver download link: https://www.nvidia.cn/drivers/lookup/

-
Use the command
wsl --list --verboseto check if WSL is installed. If it shows as below, it's already installed and no further installation is needed.
- WSL installation command:
wsl --install- May fail due to network issues, try multiple times
- During installation, you'll need to set and remember a new username and password
-
Update WSL using
wsl --update.
-
Download Docker for Windows, choose the appropriate installation package based on your CPU architecture.
-
When you see this interface, installation is successful.

-
Run Docker

-
Accept the agreement and skip login on first run



Installation using Docker, docker-compose as follows:
-
The
docker-compose.ymlfile is in the/deploydirectory. -
Execute
docker-compose up -din the/deploydirectory -
Wait patiently (about half an hour, speed depends on network), download will consume about 70GB of traffic, make sure to use WiFi
-
When you see three services in Docker, it indicates success

- Directly download the officially built installation package
- Double-click
HeyGem-x.x.x-setup.exeto install
We have opened APIs for model training and video synthesis. After Docker starts, several ports will be exposed locally, accessible through http://127.0.0.1.
For specific code, refer to:
- src/main/service/model.js
- src/main/service/video.js
- src/main/service/voice.js
- Separate video into silent video + audio
- Place audio in
D:\heygem_data\voice\dataD:\heygem_data\voice\datais agreed with theguiji2025/fish-speech-zimingservice, can be modified in docker-compose - Call the
http://127.0.0.1:18180/v1/preprocess_and_traninterfaceParameter example:
{ "format": ".wav", "reference_audio": "xxxxxx/xxxxx.wav", "lang": "zh" }Response example:
{ "asr_format_audio_url": "xxxx/x/xxx/xxx.wav", "reference_audio_text": "xxxxxxxxxxxx" }Record the response results as they will be needed for subsequent audio synthesis
Interface: http://127.0.0.1:18180/v1/invoke
// Request parameters
{
"speaker": "{uuid}", // A unique UUID
"text": "xxxxxxxxxx", // Text content to synthesize
"format": "wav", // Fixed parameter
"topP": 0.7, // Fixed parameter
"max_new_tokens": 1024, // Fixed parameter
"chunk_length": 100, // Fixed parameter
"repetition_penalty": 1.2, // Fixed parameter
"temperature": 0.7, // Fixed parameter
"need_asr": false, // Fixed parameter
"streaming": false, // Fixed parameter
"is_fixed_seed": 0, // Fixed parameter
"is_norm": 0, // Fixed parameter
"reference_audio": "{voice.asr_format_audio_url}", // Return value from previous "Model Training" step
"reference_text": "{voice.reference_audio_text}" // Return value from previous "Model Training" step
}-
Synthesis interface:
http://127.0.0.1:8383/easy/submit// Request parameters { "audio_url": "{audioPath}", // Audio path "video_url": "{videoPath}", // Video path "code": "{uuid}", // Unique key "chaofen": 0, // Fixed value "watermark_switch": 0, // Fixed value "pn": 1 // Fixed value }
-
Progress query:
http://127.0.0.1:8383/easy/query?code=${taskCode}GET request, parameter
taskCodeis the return value from the above synthesis interface
-
Check if all three services are in Running status

-
Confirm that your machine has an NVIDIA graphics card and drivers are correctly installed.
All computing power for this project is local. The three services won't start without an NVIDIA graphics card or proper drivers.
-
Ensure both server and client are updated to the latest version. The project is newly open-sourced, the community is very active, and updates are frequent. Your issue might have been resolved in a new version.
- Server: Go to
/deploydirectory and re-executedocker-compose up -d - Client:
pullcode and re-build
- Server: Go to
-
GitHub Issues are continuously updated, issues are being resolved and closed daily. Check frequently, your issue might already be resolved.
-
Problem Description
Describe the reproduction steps in detail, with screenshots if possible.
-
Provide Error Logs
-
How to get client logs:

-
Server logs:
Find the key location, or click on our three Docker services, and "Copy" as shown below.

-
[email protected]
- ASR based on fun-asr
- TTS based on fish-speech-ziming
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for HeyGem.ai
Similar Open Source Tools
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
yomo
YoMo is an open-source LLM Function Calling Framework for building Geo-distributed AI applications. It is built atop QUIC Transport Protocol and Stateful Serverless architecture, making AI applications low-latency, reliable, secure, and easy. The framework focuses on providing low-latency, secure, stateful serverless functions that can be distributed geographically to bring AI inference closer to end users. It offers features such as low-latency communication, security with TLS v1.3, stateful serverless functions for faster GPU processing, geo-distributed architecture, and a faster-than-real-time codec called Y3. YoMo enables developers to create and deploy stateful serverless functions for AI inference in a distributed manner, ensuring quick responses to user queries from various locations worldwide.
mcp-server
The Strands Agents MCP Server is a model-driven approach to building AI agents in just a few lines of code. It provides curated documentation access to GenAI tools via llms.txt files, enabling AI coding assistants to search and retrieve relevant documentation with intelligent ranking. Features include smart document search, curated content indexing, on-demand fetching, snippet generation, and real URL support. The server can be used with various applications that support MCP servers, such as Amazon Q Developer CLI, Anthropic Claude Code, Cline, and Cursor. Users can quickly test the MCP server using the MCP Inspector and follow the provided steps to configure their MCP client and start using the documentation tools. The project welcomes contributions and is licensed under the Apache License 2.0.

kaito
KAITO is an operator that automates the AI/ML model inference or tuning workload in a Kubernetes cluster. It manages large model files using container images, provides preset configurations to avoid adjusting workload parameters based on GPU hardware, supports popular open-sourced inference runtimes, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry. Using KAITO simplifies the workflow of onboarding large AI inference models in Kubernetes.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.

arbigent
Arbigent (Arbiter-Agent) is an AI agent testing framework designed to make AI agent testing practical for modern applications. It addresses challenges faced by traditional UI testing frameworks and AI agents by breaking down complex tasks into smaller, dependent scenarios. The framework is customizable for various AI providers, operating systems, and form factors, empowering users with extensive customization capabilities. Arbigent offers an intuitive UI for scenario creation and a powerful code interface for seamless test execution. It supports multiple form factors, optimizes UI for AI interaction, and is cost-effective by utilizing models like GPT-4o mini. With a flexible code interface and open-source nature, Arbigent aims to revolutionize AI agent testing in modern applications.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
archgw
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize AI agents with APIs. It handles tasks related to prompts, including detecting jailbreak attempts, calling backend APIs, routing between LLMs, and managing observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and observability. Users can build fast, observable, and personalized AI agents using Arch to improve speed, security, and personalization of GenAI apps.

LightAgent
LightAgent is a lightweight, open-source Agentic AI development framework with memory, tools, and a tree of thought. It supports multi-agent collaboration, autonomous learning, tool integration, complex task handling, and multi-model support. It also features a streaming API, tool generator, agent self-learning, adaptive tool mechanism, and more. LightAgent is designed for intelligent customer service, data analysis, automated tools, and educational assistance.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.
evidently
Evidently is an open-source Python library designed for evaluating, testing, and monitoring machine learning (ML) and large language model (LLM) powered systems. It offers a wide range of functionalities, including working with tabular, text data, and embeddings, supporting predictive and generative systems, providing over 100 built-in metrics for data drift detection and LLM evaluation, allowing for custom metrics and tests, enabling both offline evaluations and live monitoring, and offering an open architecture for easy data export and integration with existing tools. Users can utilize Evidently for one-off evaluations using Reports or Test Suites in Python, or opt for real-time monitoring through the Dashboard service.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.

KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
For similar tasks

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

Pandrator
Pandrator is a GUI tool for generating audiobooks and dubbing using voice cloning and AI. It transforms text, PDF, EPUB, and SRT files into spoken audio in multiple languages. It leverages XTTS, Silero, and VoiceCraft models for text-to-speech conversion and voice cloning, with additional features like LLM-based text preprocessing and NISQA for audio quality evaluation. The tool aims to be user-friendly with a one-click installer and a graphical interface.
ruoyi-ai
ruoyi-ai is a platform built on top of ruoyi-plus to implement AI chat and drawing functionalities on the backend. The project is completely open source and free. The backend management interface uses elementUI, while the server side is built using Java 17 and SpringBoot 3.X. It supports various AI models such as ChatGPT4, Dall-E-3, ChatGPT-4-All, voice cloning based on GPT-SoVITS, GPTS, and MidJourney. Additionally, it supports WeChat mini programs, personal QR code real-time payments, monitoring and AI auto-reply in live streaming rooms like Douyu and Bilibili, and personal WeChat integration with ChatGPT. The platform also includes features like private knowledge base management and provides various demo interfaces for different platforms such as mobile, web, and PC.
viitor-voice
ViiTor-Voice is an LLM based TTS Engine that offers a lightweight design with 0.5B parameters for efficient deployment on various platforms. It provides real-time streaming output with low latency experience, a rich voice library with over 300 voice options, flexible speech rate adjustment, and zero-shot voice cloning capabilities. The tool supports both Chinese and English languages and is suitable for applications requiring quick response and natural speech fluency.

ebook2audiobook
ebook2audiobook is a CPU/GPU converter tool that converts eBooks to audiobooks with chapters and metadata using tools like Calibre, ffmpeg, XTTSv2, and Fairseq. It supports voice cloning and a wide range of languages. The tool is designed to run on 4GB RAM and provides a new v2.0 Web GUI interface for user-friendly interaction. Users can convert eBooks to text format, split eBooks into chapters, and utilize high-quality text-to-speech functionalities. Supported languages include Arabic, Chinese, English, French, German, Hindi, and many more. The tool can be used for legal, non-DRM eBooks only and should be used responsibly in compliance with applicable laws.
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
KlicStudio
Klic Studio is a versatile audio and video localization and enhancement solution developed by Krillin AI. This minimalist yet powerful tool integrates video translation, dubbing, and voice cloning, supporting both landscape and portrait formats. With an end-to-end workflow, users can transform raw materials into beautifully ready-to-use cross-platform content with just a few clicks. The tool offers features like video acquisition, accurate speech recognition, intelligent segmentation, terminology replacement, professional translation, voice cloning, video composition, and cross-platform support. It also supports various speech recognition services, large language models, and TTS text-to-speech services. Users can easily deploy the tool using Docker and configure it for different tasks like subtitle translation, large model translation, and optional voice services.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.