
Chinese-LLaMA-Alpaca
中文LLaMA&Alpaca大语言模型+本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs)
Stars: 17169
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.
README:
🇨🇳中文 | 🌐English | 📖文档/Docs | ❓提问/Issues | 💬讨论/Discussions | ⚔️竞技场/Arena





本项目开源了中文LLaMA模型和指令精调的Alpaca大模型,以进一步促进大模型在中文NLP社区的开放研究。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
技术报告(V2):[Cui, Yang, and Yao] Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
本项目主要内容:
- 🚀 针对原版LLaMA模型扩充了中文词表,提升了中文编解码效率
- 🚀 开源了使用中文文本数据预训练的中文LLaMA以及经过指令精调的中文Alpaca
- 🚀 开源了预训练脚本、指令精调脚本,用户可根据需要进一步训练模型
- 🚀 快速使用笔记本电脑(个人PC)的CPU/GPU本地量化和部署体验大模型
- 🚀 支持🤗transformers, llama.cpp, text-generation-webui, LlamaChat, LangChain, privateGPT等生态
- 目前已开源的模型版本:7B(基础版、Plus版、Pro版)、13B(基础版、Plus版、Pro版)、33B(基础版、Plus版、Pro版)
💡 下图是中文Alpaca-Plus-7B模型在本地CPU量化部署后的实际体验速度和效果。

中文LLaMA-2&Alpaca-2大模型 | 多模态中文LLaMA&Alpaca大模型 | 多模态VLE | 中文MiniRBT | 中文LERT | 中英文PERT | 中文MacBERT | 中文ELECTRA | 中文XLNet | 中文BERT | 知识蒸馏工具TextBrewer | 模型裁剪工具TextPruner
[2024/03/27] 本项目已入驻机器之心SOTA!模型平台,欢迎关注:https://sota.jiqizhixin.com/project/chinese-llama-alpaca
[2023/08/14] Chinese-LLaMA-Alpaca-2 v2.0版本已正式发布,开源Chinese-LLaMA-2-13B和Chinese-Alpaca-2-13B,推荐所有一期用户升级至二代模型,请参阅:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
[2023/07/31] Chinese-LLaMA-Alpaca-2 v1.0版本已正式发布,请参阅:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
[2023/07/19] v5.0版本: 发布Alpaca-Pro系列模型,显著提升回复长度和质量;同时发布Plus-33B系列模型。
[2023/07/19] 🚀启动中文LLaMA-2、Alpaca-2开源大模型项目,欢迎关注了解最新信息。
[2023/07/10] Beta测试预览,提前了解即将到来的更新:详见讨论区
[2023/07/07] Chinese-LLaMA-Alpaca家族再添新成员,推出面向视觉问答与对话的多模态中文LLaMA&Alpaca大模型,发布了7B测试版本。
[2023/06/30] llama.cpp下8K context支持(无需对模型做出修改),相关方法和讨论见讨论区;transformers下支持4K+ context的代码请参考PR#705
[2023/06/16] v4.1版本: 发布新版技术报告、添加C-Eval解码脚本、添加低资源模型合并脚本等。
[2023/06/08] v4.0版本: 发布中文LLaMA/Alpaca-33B、添加privateGPT使用示例、添加C-Eval结果等。
| 章节 | 描述 |
|---|---|
| ⏬模型下载 | 中文LLaMA、Alpaca大模型下载地址 |
| 🈴合并模型 | (重要)介绍如何将下载的LoRA模型与原版LLaMA合并 |
| 💻本地推理与快速部署 | 介绍了如何对模型进行量化并使用个人电脑部署并体验大模型 |
| 💯系统效果 | 介绍了部分场景和任务下的使用体验效果 |
| 📝训练细节 | 介绍了中文LLaMA、Alpaca大模型的训练细节 |
| ❓FAQ | 一些常见问题的回复 |
| 本项目涉及模型的局限性 |
Facebook官方发布的LLaMA模型禁止商用,并且官方没有正式开源模型权重(虽然网上已经有很多第三方的下载地址)。为了遵循相应的许可,这里发布的是LoRA权重,可以理解为原LLaMA模型上的一个“补丁”,两者合并即可获得完整版权重。以下中文LLaMA/Alpaca LoRA模型无法单独使用,需要搭配原版LLaMA模型。请参考本项目给出的合并模型步骤重构模型。
下图展示了本项目以及二期项目推出的所有大模型之间的关系。

下面是中文LLaMA和Alpaca模型的基本对比以及建议使用场景(包括但不限于),更多内容见训练细节。
| 对比项 | 中文LLaMA | 中文Alpaca |
|---|---|---|
| 训练方式 | 传统CLM | 指令精调 |
| 模型类型 | 基座模型 | 指令理解模型(类ChatGPT) |
| 训练语料 | 无标注通用语料 | 有标注指令数据 |
| 词表大小[3] | 49953 | 49954=49953+1(pad token) |
| 输入模板 | 不需要 | 需要符合模板要求[1] |
| 适用场景 ✔️ | 文本续写:给定上文内容,让模型生成下文 | 指令理解(问答、写作、建议等);多轮上下文理解(聊天等) |
| 不适用场景 ❌ | 指令理解 、多轮聊天等 | 文本无限制自由生成 |
| llama.cpp | 使用-p参数指定上文 |
使用-ins参数启动指令理解+聊天模式 |
| text-generation-webui | 不适合chat模式 | 使用--cpu可在无显卡形式下运行 |
| LlamaChat | 加载模型时选择"LLaMA" | 加载模型时选择"Alpaca" |
| HF推理代码 | 无需添加额外启动参数 | 启动时添加参数 --with_prompt
|
| web-demo代码 | 不适用 | 直接提供Alpaca模型位置即可;支持多轮对话 |
| LangChain示例 / privateGPT | 不适用 | 直接提供Alpaca模型位置即可 |
| 已知问题 | 如果不控制终止,则会一直写下去,直到达到输出长度上限。[2] | 请使用Pro版,以避免Plus版回复过短的问题。 |
[1] llama.cpp/LlamaChat/HF推理代码/web-demo代码/LangChain示例等已内嵌,无需手动添加模板。
[2] 如果出现模型回答质量特别低、胡言乱语、不理解问题等情况,请检查是否使用了正确的模型和启动参数。
[3] 经过指令精调的Alpaca会比LLaMA多一个pad token,因此请勿混用LLaMA/Alpaca词表。
以下为本项目推荐使用的模型列表,通常使用了更多的训练数据和优化的模型训练方法和参数,请优先使用这些模型(其余模型请查看其他模型)。如希望体验类ChatGPT对话交互,请使用Alpaca模型,而不是LLaMA模型。 对于Alpaca模型,Pro版针对回复内容过短的问题进行改进,模型回复效果有明显提升;如果更偏好短回复,请选择Plus系列。
| 模型名称 | 类型 | 训练数据 | 重构模型[1] | 大小[2] | LoRA下载[3] |
|---|---|---|---|---|---|
| Chinese-LLaMA-Plus-7B | 基座模型 | 通用120G | 原版LLaMA-7B | 790M | [百度网盘][Google Drive] |
| Chinese-LLaMA-Plus-13B | 基座模型 | 通用120G | 原版LLaMA-13B | 1.0G |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-Plus-33B 🆕 | 基座模型 | 通用120G | 原版LLaMA-33B | 1.3G[6] |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-7B 🆕 | 指令模型 | 指令4.3M |
原版LLaMA-7B & LLaMA-Plus-7B[4] |
1.1G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-13B 🆕 | 指令模型 | 指令4.3M | 原版LLaMA-13B & LLaMA-Plus-13B[4] |
1.3G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Pro-33B 🆕 | 指令模型 | 指令4.3M | 原版LLaMA-33B & LLaMA-Plus-33B[4] |
2.1G |
[百度网盘] [Google Drive] |
[1] 重构需要原版LLaMA模型,去LLaMA项目申请使用或参考这个PR。因版权问题本项目无法提供下载链接。
[2] 经过重构后的模型大小比同等量级的原版LLaMA大一些(主要因为扩充了词表)。
[3] 下载后务必检查压缩包中模型文件的SHA256是否一致,请查看SHA256.md。
[4] Alpaca-Plus模型需要同时下载对应的LLaMA-Plus模型,请参考合并教程。
[5] 有些地方称为30B,实际上是Facebook在发布模型时写错了,论文里仍然写的是33B。
[6] 采用FP16存储,故模型体积较小。
压缩包内文件目录如下(以Chinese-LLaMA-7B为例):
chinese_llama_lora_7b/
- adapter_config.json # LoRA权重配置文件
- adapter_model.bin # LoRA权重文件
- special_tokens_map.json # special_tokens_map文件
- tokenizer_config.json # tokenizer配置文件
- tokenizer.model # tokenizer文件
由于训练方式和训练数据等因素影响,以下模型已不再推荐使用(特定场景下可能仍然有用),请优先使用上一节中的推荐模型。
| 模型名称 | 类型 | 训练数据 | 重构模型 | 大小 | LoRA下载 |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | 基座模型 | 通用20G | 原版LLaMA-7B | 770M | [百度网盘][Google Drive] |
| Chinese-LLaMA-13B | 基座模型 | 通用20G | 原版LLaMA-13B | 1.0G |
[百度网盘] [Google Drive] |
| Chinese-LLaMA-33B | 基座模型 | 通用20G | 原版LLaMA-33B | 2.7G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-7B | 指令模型 | 指令2M | 原版LLaMA-7B | 790M | [百度网盘][Google Drive] |
| Chinese-Alpaca-13B | 指令模型 | 指令3M | 原版LLaMA-13B | 1.1G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-33B | 指令模型 | 指令4.3M | 原版LLaMA-33B | 2.8G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Plus-7B | 指令模型 | 指令4M | 原版LLaMA-7B & LLaMA-Plus-7B |
1.1G | [百度网盘][Google Drive] |
| Chinese-Alpaca-Plus-13B | 指令模型 | 指令4.3M | 原版LLaMA-13B & LLaMA-Plus-13B |
1.3G |
[百度网盘] [Google Drive] |
| Chinese-Alpaca-Plus-33B | 指令模型 | 指令4.3M | 原版LLaMA-33B & LLaMA-Plus-33B |
2.1G |
[百度网盘] [Google Drive] |
可以在🤗Model Hub下载以上所有模型,并且使用transformers和PEFT调用中文LLaMA或Alpaca LoRA模型。以下模型调用名称指的是使用.from_pretrained()中指定的模型名称。
-
Pro版命名(只有Alpaca):
ziqingyang/chinese-alpaca-pro-lora-${model_size} -
Plus版命名:
ziqingyang/chinese-${model_name}-plus-lora-${model_size} -
基础版命名:
ziqingyang/chinese-${model_name}-lora-${model_size} -
$model_name:llama或者alpaca;$model_size:7b,13b,33b -
举例:Chinese-LLaMA-Plus-33B模型对应的调用名称是
ziqingyang/chinese-llama-plus-lora-33b
详细清单与模型下载地址:https://huggingface.co/ziqingyang
前面提到LoRA模型无法单独使用,必须与原版LLaMA进行合并才能转为完整模型,以便进行模型推理、量化或者进一步训练。请选择以下方法对模型进行转换合并。
| 方式 | 适用场景 | 教程 |
|---|---|---|
| 在线转换 | Colab用户可利用本项目提供的notebook进行在线转换并量化模型 | 链接 |
| 手动转换 | 离线方式转换,生成不同格式的模型,以便进行量化或进一步精调 | 链接 |
以下是合并模型后,FP16精度和4-bit量化后的大小,转换前确保本机有足够的内存和磁盘空间(最低要求):
| 模型版本 | 7B | 13B | 33B | 65B |
|---|---|---|---|---|
| 原模型大小(FP16) | 13 GB | 24 GB | 60 GB | 120 GB |
| 量化后大小(8-bit) | 7.8 GB | 14.9 GB | 32.4 GB | ~60 GB |
| 量化后大小(4-bit) | 3.9 GB | 7.8 GB | 17.2 GB | 38.5 GB |
具体内容请参考本项目 >>> 📚 GitHub Wiki
本项目中的模型主要支持以下量化、推理和部署方式。
| 推理和部署方式 | 特点 | 平台 | CPU | GPU | 量化加载 | 图形界面 | 教程 |
|---|---|---|---|---|---|---|---|
| llama.cpp | 丰富的量化选项和高效本地推理 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| 🤗Transformers | 原生transformers推理接口 | 通用 | ✅ | ✅ | ✅ | ✅ | link |
| text-generation-webui | 前端Web UI界面的部署方式 | 通用 | ✅ | ✅ | ✅ | ✅ | link |
| LlamaChat | macOS下的图形交互界面 | MacOS | ✅ | ❌ | ✅ | ✅ | link |
| LangChain | LLM应用开发框架,适用于进行二次开发 | 通用 | ✅† | ✅ | ✅† | ❌ | link |
| privateGPT | 基于LangChain的多文档本地问答框架 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| Colab Gradio Demo | Colab中启动基于Gradio的交互式Web服务 | 通用 | ✅ | ✅ | ✅ | ❌ | link |
| API调用 | 仿OpenAI API接口的服务器Demo | 通用 | ✅ | ✅ | ✅ | ❌ | link |
†: LangChain框架支持,但教程中未实现;详细说明请参考LangChain官方文档。
具体内容请参考本项目 >>> 📚 GitHub Wiki
为了快速评测相关模型的实际文本生成表现,本项目在给定相同的prompt的情况下,在一些常见任务上对比测试了本项目的中文Alpaca-7B、中文Alpaca-13B、中文Alpaca-33B、中文Alpaca-Plus-7B、中文Alpaca-Plus-13B的效果。生成回复具有随机性,受解码超参、随机种子等因素影响。以下相关评测并非绝对严谨,测试结果仅供晾晒参考,欢迎自行体验。
- 详细评测结果及生成样例请查看examples目录
- 📊 Alpaca模型在线对战:http://chinese-alpaca-arena.ymcui.com
本项目还在“NLU”类客观评测集合上对相关模型进行了测试。这类评测的结果不具有主观性,只需要输出给定标签(需要设计标签mapping策略),因此可以从另外一个侧面了解大模型的能力。本项目在近期推出的C-Eval评测数据集上测试了相关模型效果,其中测试集包含12.3K个选择题,涵盖52个学科。以下是部分模型的valid和test集评测结果(Average),完整结果请参考技术报告。
| 模型 | Valid (zero-shot) | Valid (5-shot) | Test (zero-shot) | Test (5-shot) |
|---|---|---|---|---|
| Chinese-Alpaca-Plus-33B | 46.5 | 46.3 | 44.9 | 43.5 |
| Chinese-Alpaca-33B | 43.3 | 42.6 | 41.6 | 40.4 |
| Chinese-Alpaca-Plus-13B | 43.3 | 42.4 | 41.5 | 39.9 |
| Chinese-Alpaca-Plus-7B | 36.7 | 32.9 | 36.4 | 32.3 |
| Chinese-LLaMA-Plus-33B | 37.4 | 40.0 | 35.7 | 38.3 |
| Chinese-LLaMA-33B | 34.9 | 38.4 | 34.6 | 39.5 |
| Chinese-LLaMA-Plus-13B | 27.3 | 34.0 | 27.8 | 33.3 |
| Chinese-LLaMA-Plus-7B | 27.3 | 28.3 | 26.9 | 28.4 |
需要注意的是,综合评估大模型能力仍然是亟待解决的重要课题,合理辩证地看待大模型相关各种评测结果有助于大模型技术的良性发展。推荐用户在自己关注的任务上进行测试,选择适配相关任务的模型。
C-Eval推理代码请参考本项目 >>> 📚 GitHub Wiki
整个训练流程包括词表扩充、预训练和指令精调三部分。
- 本项目的模型均在原LLaMA词表的基础上扩充了中文单词,代码请参考merge_tokenizers.py
- 预训练和指令精调代码参考了🤗transformers中的run_clm.py和Stanford Alpaca项目中数据集处理的相关部分
- 已开源用于预训练和指令精调的训练脚本:预训练脚本Wiki、指令精调脚本Wiki
具体内容请参考本项目 >>> 📚 GitHub Wiki
FAQ中给出了常见问题的解答,请在提Issue前务必先查看FAQ。
问题1:为什么不能放出完整版本权重?
问题2:后面会有33B、65B的版本吗?
问题3:一些任务上效果不好!
问题4:为什么要扩充词表?直接在原版LLaMA上用中文预训练不行吗?
问题5:回复内容很短
问题6:Windows下,模型无法理解中文、生成速度很慢等问题
问题7:Chinese-LLaMA 13B模型没法用llama.cpp启动,提示维度不一致
问题8:Chinese-Alpaca-Plus效果很差
问题9:模型在NLU类任务(文本分类等)上效果不好
问题10:为什么叫33B,不应该是30B吗?
问题11:模型合并之后SHA256不一致
具体问题和解答请参考本项目 >>> 📚 GitHub Wiki
虽然本项目中的模型具备一定的中文理解和生成能力,但也存在局限性,包括但不限于:
- 可能会产生不可预测的有害内容以及不符合人类偏好和价值观的内容
- 由于算力和数据问题,相关模型的训练并不充分,中文理解能力有待进一步提升
- 暂时没有在线可互动的demo(注:用户仍然可以自行在本地部署)
如果您觉得本项目对您的研究有所帮助或使用了本项目的代码或数据,请参考引用本项目的技术报告:https://arxiv.org/abs/2304.08177
@article{chinese-llama-alpaca,
title={Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca},
author={Cui, Yiming and Yang, Ziqing and Yao, Xin},
journal={arXiv preprint arXiv:2304.08177},
url={https://arxiv.org/abs/2304.08177},
year={2023}
}
| 项目名称 | 简介 | 类型 |
|---|---|---|
| Chinese-LLaMA-Alpaca-2(官方项目) | 中文LLaMA-2、Alpaca-2大模型 | 文本 |
| Visual-Chinese-LLaMA-Alpaca(官方项目) | 多模态中文LLaMA & Alpaca大模型 | 多模态 |
想要加入列表?>>> 提交申请
本项目基于以下开源项目二次开发,在此对相关项目和研究开发人员表示感谢。
本项目相关资源仅供学术研究之用,严禁用于商业用途。 使用涉及第三方代码的部分时,请严格遵循相应的开源协议。模型生成的内容受模型计算、随机性和量化精度损失等因素影响,本项目不对其准确性作出保证。对于模型输出的任何内容,本项目不承担任何法律责任,亦不对因使用相关资源和输出结果而可能产生的任何损失承担责任。本项目由个人及协作者业余时间发起并维护,因此无法保证能及时回复解决相应问题。
如有问题,请在GitHub Issue中提交。礼貌地提出问题,构建和谐的讨论社区。
- 在提交问题之前,请先查看FAQ能否解决问题,同时建议查阅以往的issue是否能解决你的问题。
- 提交问题请使用本项目设置的Issue模板,以帮助快速定位具体问题。
- 重复以及与本项目无关的issue会被stable-bot处理,敬请谅解。
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Chinese-LLaMA-Alpaca
Similar Open Source Tools
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.

Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.
sanic-web
Sanic-Web is a lightweight, end-to-end, and easily customizable large model application project built on technologies such as Dify, Ollama & Vllm, Sanic, and Text2SQL. It provides a one-stop solution for developing large model applications, supporting graphical data-driven Q&A using ECharts, handling table-based Q&A with CSV files, and integrating with third-party RAG systems for general knowledge Q&A. As a lightweight framework, Sanic-Web enables rapid iteration and extension to facilitate the quick implementation of large model projects.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.
teaching-boyfriend-llm
The 'teaching-boyfriend-llm' repository contains study notes on LLM (Large Language Models) for the purpose of advancing towards AGI (Artificial General Intelligence). The notes are a collaborative effort towards understanding and implementing LLM technology.

XiaoFeiShu
XiaoFeiShu is a specialized automation software developed closely following the quality user rules of Xiaohongshu. It provides a set of automation workflows for Xiaohongshu operations, avoiding the issues of traditional RPA being mechanical, rule-based, and easily detected. The software is easy to use, with simple operation and powerful functionality.
yudao-ui-admin-vue3
The yudao-ui-admin-vue3 repository is an open-source project focused on building a fast development platform for developers in China. It utilizes Vue3 and Element Plus to provide features such as configurable themes, internationalization, dynamic route permission generation, common component encapsulation, and rich examples. The project supports the latest front-end technologies like Vue3 and Vite4, and also includes tools like TypeScript, pinia, vueuse, vue-i18n, vue-router, unocss, iconify, and wangeditor. It offers a range of development tools and features for system functions, infrastructure, workflow management, payment systems, member centers, data reporting, e-commerce systems, WeChat public accounts, ERP systems, and CRM systems.

JiwuChat
JiwuChat is a lightweight multi-platform chat application built on Tauri2 and Nuxt3, with various real-time messaging features, AI group chat bots (such as 'iFlytek Spark', 'KimiAI' etc.), WebRTC audio-video calling, screen sharing, and AI shopping functions. It supports seamless cross-device communication, covering text, images, files, and voice messages, also supporting group chats and customizable settings. It provides light/dark mode for efficient social networking.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.
pmhub
PmHub is a smart project management system based on SpringCloud, SpringCloud Alibaba, and LLM. It aims to help students quickly grasp the architecture design and development process of microservices/distributed projects. PmHub provides a platform for students to experience the transformation from monolithic to microservices architecture, understand the pros and cons of both architectures, and prepare for job interviews. It offers popular technologies like SpringCloud-Gateway, Nacos, Sentinel, and provides high-quality code, continuous integration, product design documents, and an enterprise workflow system. PmHub is suitable for beginners and advanced learners who want to master core knowledge of microservices/distributed projects.
ai-app
The 'ai-app' repository is a comprehensive collection of tools and resources related to artificial intelligence, focusing on topics such as server environment setup, PyCharm and Anaconda installation, large model deployment and training, Transformer principles, RAG technology, vector databases, AI image, voice, and music generation, and AI Agent frameworks. It also includes practical guides and tutorials on implementing various AI applications. The repository serves as a valuable resource for individuals interested in exploring different aspects of AI technology.
For similar tasks
dbrx
DBRX is a large language model trained by Databricks and made available under an open license. It is a Mixture-of-Experts (MoE) model with 132B total parameters and 36B live parameters, using 16 experts, of which 4 are active during training or inference. DBRX was pre-trained for 12T tokens of text and has a context length of 32K tokens. The model is available in two versions: a base model and an Instruct model, which is finetuned for instruction following. DBRX can be used for a variety of tasks, including text generation, question answering, summarization, and translation.
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.
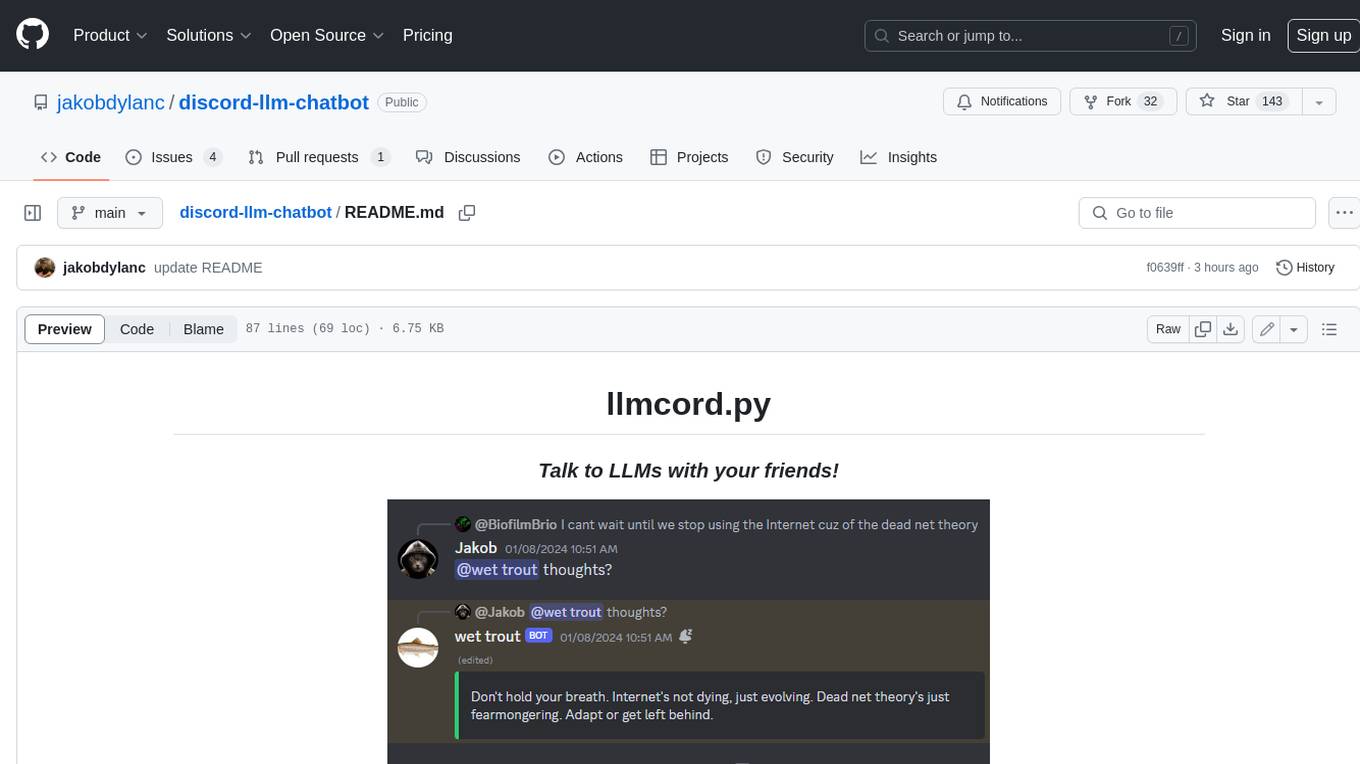
discord-llm-chatbot
llmcord.py enables collaborative LLM prompting in your Discord server. It works with practically any LLM, remote or locally hosted. ### Features ### Reply-based chat system Just @ the bot to start a conversation and reply to continue. Build conversations with reply chains! You can do things like: - Build conversations together with your friends - "Rewind" a conversation simply by replying to an older message - @ the bot while replying to any message in your server to ask a question about it Additionally: - Back-to-back messages from the same user are automatically chained together. Just reply to the latest one and the bot will see all of them. - You can seamlessly move any conversation into a thread. Just create a thread from any message and @ the bot inside to continue. ### Choose any LLM Supports remote models from OpenAI API, Mistral API, Anthropic API and many more thanks to LiteLLM. Or run a local model with ollama, oobabooga, Jan, LM Studio or any other OpenAI compatible API server. ### And more: - Supports image attachments when using a vision model - Customizable system prompt - DM for private access (no @ required) - User identity aware (OpenAI API only) - Streamed responses (turns green when complete, automatically splits into separate messages when too long, throttled to prevent Discord ratelimiting) - Displays helpful user warnings when appropriate (like "Only using last 20 messages", "Max 5 images per message", etc.) - Caches message data in a size-managed (no memory leaks) and per-message mutex-protected (no race conditions) global dictionary to maximize efficiency and minimize Discord API calls - Fully asynchronous - 1 Python file, ~200 lines of code
enchanted
Enchanted is an open-source, Ollama-compatible app for macOS and iOS that allows users to work with privately hosted models such as Llama 2, Mistral, Vicuna, Starling, and more. It provides a user-friendly interface for interacting with these models, making it easy to generate text, translate languages, write different kinds of creative content, and more. The app is designed to be secure and private, ensuring that user data is protected. It also offers a range of features such as dark/light mode, conversation history, markdown support, voice prompts, and image attachments.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.
For similar jobs

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.