awesome-pretrained-chinese-nlp-models
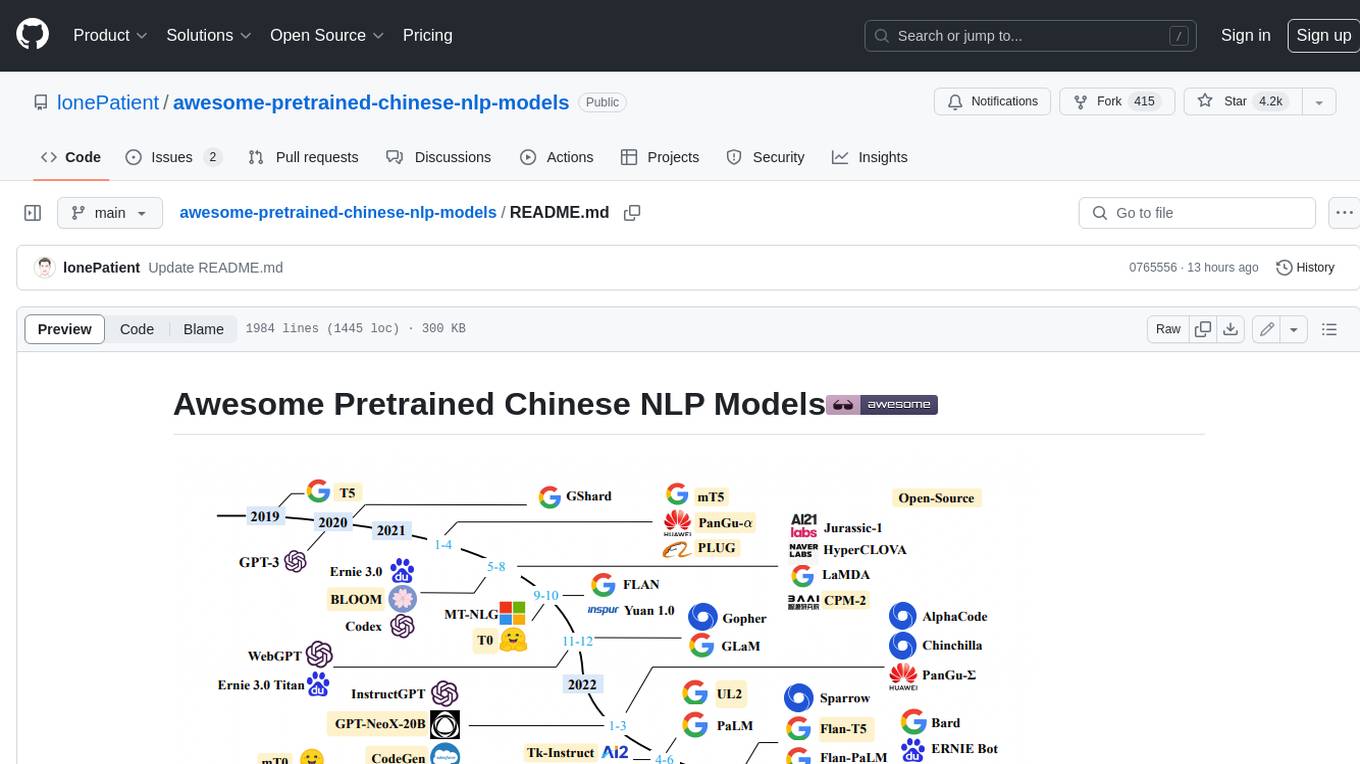
Awesome Pretrained Chinese NLP Models,高质量中文预训练模型&大模型&多模态模型&大语言模型集合
Stars: 5168
README:

在自然语言处理领域中,预训练语言模型(Pretrained Language Models)已成为非常重要的基础技术,本仓库主要收集目前网上公开的一些高质量中文预训练模型、中文多模态模型、中文大语言模型等内容(感谢分享资源的大佬),并将持续更新......
国内下载HuggingFace仓库模型推荐使用HuggingFace镜像地址: https://hf-mirror.com/
-
Table
备注
ND: Non-Causal Decoder or Prefix LM
CD: Causal Decoder
ED: Encoder-Decoder
大规模基础模型:表格中只罗列出参数量
大于7B以上模型。
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 架构 | 文献 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|
| XVERSE-MoE | 255B/A36B | 2024-09 | 中英 | 通用 | 🤗HF | XVERSE-MoE-A36B | xverse-ai | MoE | ||
| Qwen-2.5 | 0.5/1.5/3/7/14/32/72B | 2024-09 | 中英 | 通用 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog | |
| Tele-FLM | 52B/102B/1TB | 2024-07 | 多语 | 通用 | [🤗HF] | / | CofeAI | CD | Tele-FLM Technical Report | |
| meta-llama-3.1 | 8/70/405B | 2024-07 | 多语 | 通用 | [🤗HF] | llama3 | meta-llama | CD | ||
| internlm2.5-Base | 7B | 2024-07 | 中英 | 通用 | [🤗HF] |
InternLM |
InternLM | CD | 📜Technical Report | |
| MAP-NEO-Base | 2/7B | 2024-06 | 中英 | 通用 | 🤗HF | MAP-NEO | multimodal-art-projection | CD | Paper | |
| Nemotron-4-Base | 340B | 2024-06 | 多语 | 通用 | 🤗HF | / | NVIDIA | CD | technical report. | |
| Index-Base | 1.9B | 2024-06 | 中英 | 通用 | 🤗HF | Index-1.9B | bilibili | CD | Report | |
| Qwen2-Base | 0.5/2/5/7/72B | 2024-06 | 多语 | 通用 | 🤗HF | Qwen2 | QwenLM | CD | Blog | |
| GLM-4-Base | 9B | 2024-06 | 多语 | 通用 | 🤗HF | GLM-4 | THUDM | / | ||
| Yi-1.5-Base | 6/9/34B | 2024-05 | 中英 | 通用 | 🤗HF | Yi-1.5 | 01-ai | CD | Paper | |
| DeepSeek-V2-Base | A21B/236B | 2024-05 | 中英 | 通用 | 🤗HF | DeepSeek-V2 | deepseek-ai | MOE | Paper | |
| Llama-3-Base | 8/70B | 2024-04 | 多语 | 通用 | 🤗HF | llama3 | Meta Llama | CD | ||
| Zhinao-Base | 7B | 2024-04 | 中英 | 通用 | 🤗HF 🤖 | / | 奇虎科技 | CD | ||
| XVERSE-MoE | A4.2B/25.8B | 2024-04 | 中英 | 通用 | 🤗HF | XVERSE-MoE-A4.2B | xverse-ai | MoE | ||
| SoftTiger-Base | 13/70B | 2024-04 | 中英 | 通用 | 🤗HF | TigerBot | TigerResearch | CD | ||
| HammerLLM | 1.4b | 2024-04 | 中英 | 通用 | 🤗HF | HammerLLM | DataHammer | |||
| Mengzi3-Base | 13B | 2024-04 | 中英 | 通用 | 🤗HF |
Mengzi3 
|
Langboat | CD | ||
| Breeze-Base | 7B | 2024-02 | 中英 | 通用 | 🤗HF | / | MediaTek Research | |||
| TowerBase | 7/13B | 2024-02 | 多语 | 通用 | [🤗HF] | / | Unbabel | CD | ||
| Qwen1.5-Base | 0.5/1.8/4 7/14/32/72/110B |
2024-02 | 中英 | 通用 | [🤗HF] |
Qwen1.5
|
Qwen | / | Blog | |
| LongAlign-Base | 6/7/13B | 2024-02 | 中英 | 通用 | [🤗HF] |
LongAlign
|
THUDM | / | Paper | |
| Chinese-Mixtral-Base | 8x7B | 2024-02 | 中英 | 通用 | [Baidu] [🤗HF] |
Chinese-Mixtral
|
Yiming Cui | MOE | ||
| iFlytekSpark-Base | 13B | 2024-01 | 中英 | 通用 | mindspore | / | 科大讯飞 | CD | ||
| Orion-Base | 14B | 2024-01 | 多语 | 通用 | [🤗HF] |
Orion
|
OrionStarAI | CD | Paper | RAG Plugin |
| YaYi2-Base | 30B | 2023-12 | 多语 | 通用 | [🤗HF] |
YAYI2
|
wenge-research | CD | Paper | |
| Aquila2-Base | 7/34/70B | 2023-12 | 中英 | 通用 | [🤗HF] |
Aquila2 
|
FlagAI | CD | ||
| Alaya-Base | 7B | 2023-12 | 中英 | 通用 | [🤗HF] |
Alaya
|
DataCanvas | CD | ||
| Qwen-Base | 1.8/7 14/72B |
2023-12 | 中英 | 通用 | [🤗HF] |
Qwen 
|
阿里云 | CD | Paper Report Report2 | |
| DeepSeek-Base | 7/67B | 2023-11 | 中英 | 通用 | [🤗HF] |
DeepSeek-LLM
|
deepseek-ai | CD | ||
| Yuan-2.0 | 2/51 102B |
2023-11 | 中英 | 通用 | baidu [🤗HF] |
Yuan-2.0
|
IEIT-Yuan | CD | ||
| Alaya-Base | 7B | 2023-11 | 中英 | 通用 | [🤗HF] |
Alaya
|
DataCanvasIO | CD | ||
| Yi-Base | 6/9/34B | 2023-11 | 中英 | 通用 | [🤗HF] |
Yi
|
01.AI | CD | ||
| XVERSE-Base | 7/13 65B |
2023-11 | 多语 | 通用 | [🤗HF] |
XVERSE
|
元象科技 | CD | ||
| Nanbeige-Base | 16B | 2023-11 | 中英 | 通用 | [🤗HF] |
Nanbeige
|
Nanbeige LLM Lab | CD | ||
| LingoWhale | 8B | 2023-11 | 中英 | 通用 | [🤗HF] |
LingoWhale-8B
|
DeepLang AI | CD | ||
| Skywork-base | 13B | 2023-10 | 中文 | 通用 | [🤗HF] |
Skywork 
|
SkyworkAI | CD | Paper | |
| BlueLM-Base | 7B | 2023-11 | 中英 | 通用 | [🤗HF] |
BlueLM
|
vivo AI Lab | CD | ||
| Chatglm3-base | 6B | 2023-10 | 中英 | 通用 | [🤗HF] |
ChatGLM3
|
THUDM | ND | ||
| Ziya2-Base | 13B | 2023-10 | 中英 | 通用 | [🤗HF] |
Fengshenbang-LM 
|
IDEA研究院 | CD | ||
| OpenBA-LM | 15B | 2023-09 | 中英 | 通用 | [🤗HF] |
OpenBA
|
OpenNLG Group | ED | Paper | |
| TigerBot-Base-70B | 80B | 2023-09 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | Paper | |
| FLM | 101B | 2023-09 | 中英 | 通用 | [🤗HF] | / | CofeAI | CD | ||
| falcon | 7/40 180B |
2023-09 | 多语 | 通用 | [🤗HF] | / | Technology Innovation Institute | CD | ||
| Baichuan2 | 7/13B | 2023-09 | 中文 | 通用 | [🤗HF] |
Baichuan2
|
百川智能 | CD | ||
| Chinese-LLaMA-2-16K | 7/13B | 2023-08 | 中英 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca-2 
|
Yiming Cui | CD | ||
| YuLan-LLaMA-2 | 13B | 2023-08 | 中英 | 通用 | [🤗HF] |
YuLan-Chat 
|
中国人民大学 | CD | ||
| Aquila-Base-33B | 33B | 2023-08 | 中英 | 通用 | TODO |
Aquila
|
FlagAI | CD | ||
| TigerBot-Base-13B | 13B | 2023-08 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | ||
| Linly-Chinese-LLaMA-2 | 7/13B | 2023-07 | 中英 | 通用 | [🤗HF] |
Linly 
|
深圳大学计算机视觉研究所 | CD | ||
| Chinese-LLaMA-2 | 7B | 2023-07 | 中英 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca-2
|
Yiming Cui | CD | ||
| Jiang-base | 13B | 2023-07 | 中文 | 通用 | [🤗HF] | / | 知未智能 | CD | ||
| bwx | 7/13B | 2023-07 | 中文 | 通用 | [🤗HF] | / | 蓝鲸国数 | CD | ||
| Llama2 | 7/13 70B |
2023-07 | 多语 | 通用 | [🤗HF] |
llama
|
Meta | CD | Paper | |
| PolyLM | 13B | 2023-07 | 多语 | 通用 | [🤗HF] | PolyLM | 达摩院 | CD | Paper | |
| Baichuan-13B | 13B | 2023-07 | 中文 | 通用 | [🤗HF] |
Baichuan-13B
|
百川智能 | CD | ||
| TigerBot | 7B | 2023-07 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | ||
| InternLM-base | 7/20B | 2023-07 | 中文 | 通用 | [🤗HF] |
InternLM
|
上海人工智能实验室 | CD | report | |
| MPT | 7/30B | 2023-06 | 多语 | 通用 | [🤗HF] |
llm-foundry
|
MosaicML | CD | ||
| Baichuan | 7B | 2023-06 | 中英 | 通用 | [🤗HF] |
baichuan-7B
|
百川智能 | CD | ||
| Chinese-Falcon | 7B | 2023-06 | 中英 | 通用 | [🤗HF] |
Linly
|
深圳大学计算机视觉研究所 | CD | Blog | |
| AtomGPT | 13B | 2023-06 | 中英 | 通用 | [🤗HF] | / | 原子回声 | CD | ||
| Aquila | 7B | 2023-06 | 中英 | 通用 | [🤗HF] |
Aquila
|
FlagAI | CD | ||
| Chinese-LLaMA | 33B | 2023-06 | 中英 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca
|
Yiming Cui | CD | ||
| TigerBot | 7B | 2023-06 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | ||
| Panda-OpenLLaMA | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
pandallm
|
dandelionsllm | CD | ||
| Panda | 7/13B | 2023-05 | 中英 | 通用 | [🤗HF] |
pandallm
|
dandelionsllm | CD | ||
| OpenLLaMA | 13B | 2023-05 | 中英 | 通用 | [🤗HF] |
Linly
|
深圳大学计算机视觉研究所 | CD | ||
| BiLLa-LLM | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
BiLLa
|
Zhongli Li | CD | ||
| Ziya-LLaMA-Reward | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
Fengshenbang-LM
|
IDEA研究院 | CD | ||
| YuYan | 11B | 2023-04 | 中文 | 通用 | [🤗HF] | / | 网易伏羲 | CD | Paper | |
| Chinese-LLaMA | 7/13/33B | 2023-04 | 中文 | 通用 | [🤗HF] |
Linly
|
深圳大学计算机视觉研究所 | CD | Blog | |
| OpenChineseLLaMA | 7B | 2023-04 | 中英 | 通用 | [🤗HF] |
OpenChineseLLaMA
|
OpenLMLab | CD | ||
| MOSS-003 | 16B | 2023-04 | 中英 | 通用 | [🤗HF] |
MOSS
|
复旦大学 | CD | ||
| BBT-2-Text | 13B | 2023-04 | 中文 | 通用 | 申请 |
BBT-FinCUGE-Applications
|
超对称 | CD | Paper | |
| BBT-2-Text | 12B | 2023-04 | 中文 | 通用 | 申请 |
BBT-FinCUGE-Applications
|
超对称 | CD | Paper | |
| Chinese-LLaMA | 13B | 2023-04 | 中英 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca
|
Yiming Cui | CD | ||
| flan-ul2 | 20B | 2023-03 | 多语 | 通用 | [🤗HF] | ul2 | ED | Paper | ||
| CPM-Bee | 10B | 2023-01 | 中英 | 通用 | [🤗HF] |
CPM-Bee
|
OpenBMB | CD | ||
| BLOOM | 176B | 2022-11 | 多语 | 通用 | [🤗HF] |
Megatron-DeepSpeed 
|
BigScience | CD | Paper | |
| BLOOMZ | 176B | 2022-11 | 多语 | 通用 | [🤗HF] |
Megatron-DeepSpeed
|
BigScience | CD | Paper | |
| flan-t5-xxl | 11B | 2022-11 | 多语 | 通用 | [🤗HF] |
t5x 
|
ED | paper | ||
| CPM-Ant+ | 10B | 2022-10 | 中英 | 通用 | BMB |
CPM-Live 
|
OpenBMB | CD | blog | |
| GLM | 130B | 2022-10 | 中英 | 通用 | 申请 |
GLM-130B
|
清华大学 | ND | paper | |
| CPM-Ant | 10B | 2022-09 | 中文 | 通用 | [🤗HF] |
CPM-Live
|
OpenBMB | CD | blog | |
| GLM | 10B | 2022-09 | 中文 | 通用 | [🤗HF] |
GLM 
|
清华大学 | ND | paper | |
| 源1.0 | 245B | 2021-09 | 中文 | 通用 | API |
Yian-1.0 
|
浪潮 | CD | paper | |
| CPM-2 | 10/11/ 200B |
2021-06 | 中文 | 通用 | 申请 |
CPM
|
智源研究院 | ED | paper | |
| PanGu-Alpha | 13/200B | 2021-05 | 中文 | 通用 | [🤗HF] | PanGu-Alpha | 鹏城实验室 | CD | paper | |
| PLUG | 27B | 2021-04 | 中文 | 通用 | 申请 | AliceMind | 阿里巴巴 | ED | ||
| GPT-3 | 13/30B | 2021-04 | 中文 | 通用 | TODO | GPT-3 | 达摩院 | CD |
各个垂直领域开源基础模型
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 架构 | 文献 | 备注 |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-2.5 | 1.5/7B | 2024-09 | 中英 | 代码 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog | |
| Qwen-2.5 | 1.5/7/72B | 2024-09 | 中英 | 数学 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog | |
| Tongyi-Finance-Base | 14B | 2023-11 | 中文 | 金融 | ModelScope | 通义金融-14B | 通义金融大模型 | CD | ||
| ChiMed-GPT | 13B | 2023-10 | 中文 | 医疗 | [🤗HF] | ChiMed-GPT | 中国科学技术大学 | CD | Paper | |
| CodeShell-base | 7B | 2023-10 | 中英 | 代码 | [🤗HF] |
codeshell
|
WisdomShell | CD | ||
| WiNGPT-base | 7B | 2023-09 | 中文 | 医学 | [🤗HF] |
WiNGPT2
|
Winning Health AI Research | CD | ||
| XuanYuan | 70B | 2023-09 | 中文 | 金融 | [🤗HF] |
XuanYuan 
|
度小满 | CD | Report | |
| CodeLLAma | 7/13/ 34B |
2023-08 | 多语 | 代码 | [🤗HF] |
codellama
|
Meta Research | CD | Paper | |
| educhat-base-002 | 7/13B | 2023-06 | 中英 | 教育 | [🤗HF] |
EduChat
|
华东师范大学 | CD | ||
| AquilaCode-NV | 7B | 2023-06 | 中英 | 代码 | [🤗HF] |
Aquila
|
FlagAI | CD | ||
| AquilaCode-TS | 7B | 2023-06 | 中英 | 代码 | [🤗HF] |
Aquila
|
FlagAI | CD | ||
| LaWGPT | 7B | 2023-05 | 中英 | 法律 | [🤗HF] |
LawGPT
|
Pengxiao Song | CD | ||
| CodeGeeX | 13B | 2022-06 | 多语 | 代码 | 申请 | CodeGeeX | 清华大学 | CD | blog |
具备问答和对话等功能的大型语言模型。
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 架构 | 文献 |
|---|---|---|---|---|---|---|---|---|---|
| Moonlight | A3/16B | 2025-02 | 中英 | 通用 | 🤗HF | Moonlight | MoonshotAI | MoE | Tech Report |
| phi-4 | 14B | 2025--01 | 多语 | 通用 | 🤗HF | / | Microsoft | CD | Phi-4 Technical Report |
| InternLM3 | 8B | 2025--01 | 中英 | 通用 | 🤗HF | InternLM | InternLM | CD | Technical Report |
| deepseek-v3 | 671B | 2024-12 | 多语 | 通用 | 🤗HF | DeepSeek-V3 | deepseek-ai | MoE | Paper Link |
| Megrez-3B-Instruct | 3B | 2024-12 | 中英 | 通用 | 🤗HF | Infini-Megrez | infinigence | CD | |
| Athene-V2-Chat | 72B | 2024-11 | 中英 | 通用 | 🤗HF | / | Nexusflow | CD | Blog |
| Athene-V2-Agent | 72B | 2024-11 | 中英 | 工具调用 | 🤗HF | / | Nexusflow | CD | Blog |
| Hunyuan-Large | A52/389B | 2024-11 | 中英 | 通用 | 🤗HF | Tencent-Hunyuan-Large | Tencent | MoE | Paper |
| Aya-Expanse | 8/32B | 2024-10 | 多语 | 通用 | 🤗HF | / | Cohere For AI | CD | |
| Granite 3.0 | 1/2/3/8B | 2024-10 | 多语 | 通用 | 🤗HF | granite-3.0-language-models | ibm-granite | CD | Paper |
| Granite 3.0-MoE | 1B/3B/A400M | 2024-10 | 多语 | 通用 | 🤗HF | granite-3.0-language-models | ibm-granite | MoE | Paper |
| TeleChat2 | 115B | 2024-09 | 中英 | 通用 | 🤖 ModelScope | TeleChat2 | Tele-AI | CD | |
| Qwen-2.5 | 0.5/1.5/3/7/14/32/72B | 2024-09 | 中英 | 通用 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog |
| XVERSE-MoE | 255B/A36B | 2024-09 | 中英 | 通用 | 🤗HF | XVERSE-MoE-A36B | xverse-ai | MoE | |
| DeepSeek-V2.5 | 236B/A21B | 2024-09 | 中英 | 通用 | 🤗HF | DeepSeek-V2 | deepseek-ai | MOE | Paper |
| MiniCPM3 | 4B | 2024-09 | 中英 | 通用 | 🤗HF | MiniCPM | OpenBMB | CD | MiniCPM Paper |
| C4AI Command R+ 08-2024 | 104B | 2024-08 | 多语 | 通用 | 🤗HF | / | CohereForAI | CD | |
| JIUTIAN-Chat | 39/A13B | 2024-07 | 中英 | 通用 | 🤖MS | / | 中国移动JiuTian-AI | MOE | |
| meta-llama-3.1 | 8/70/405B | 2024-07 | 多语 | 通用 | [🤗HF] | llama3 | meta-llama | CD | |
| internlm2.5-chat | 7B | 2024-07 | 中英 | 通用 | [🤗HF] |
InternLM |
InternLM | CD | 📜Technical Report |
| Mistral-large-insruct-2407 | 123B | 2024-07 | 多语 | 通用 | 🤗HF | / | Mistral AI | blog post | |
| DeepSeek-V2-Chat-0628 | 236B | 2024-07 | 中英 | 通用 | 🤗HF | DeepSeek-V2 | deepseek-ai | MOE | Paper |
| C4ai-command-r-plus | 104B | 2024-07 | 多语 | 通用 | 🤗HF | / | CohereForAI | CD | |
| Gemma-2-chat | 9/27B | 2024-06 | 多语 | 通用 | 🤗HF | / | CD | ||
| MAP-NEO-Chat | 2/7B | 2024-06 | 中英 | 通用 | 🤗HF | MAP-NEO | multimodal-art-projection | CD | Paper |
| GEB-Chat | 1.3B | 2024-06 | 中英 | 通用 | 🤗HF | / | GEB-AGI | CD | Paper |
| Nemotron-4-Chat | 340B | 2024-06 | 多语 | 通用 | 🤗HF | / | NVIDIA | CD | technical report. |
| Index-Chat | 1.9B | 2024-06 | 中英 | 通用 | 🤗HF | Index-1.9B | bilibili | CD | Report |
| Qwen2-MoE | 57B/A14B | 2024-06 | 多语 | 通用 | 🤗HF | Qwen2 | QwenLM | MoE | Blog |
| Qwen2-Chat | 0.5/2/5/7/72B | 2024-06 | 多语 | 通用 | 🤗HF | Qwen2 | QwenLM | CD | Blog |
| GLM-4-Chat | 9B | 2024-06 | 多语 | 通用 | 🤗HF | GLM-4 | THUDM | / | |
| Skywork-MoE | 16/A22B/146B | 2024-06 | 中英 | 通用 | 🤗HF | Skywork-MoE | SkyworkAI | MoE | Tech Report |
| Yuan2.0 | 40/A3.7B | 2024-05 | 中英 | 通用 | 🤗HF | Yuan2.0-M32 | IEIT-Yuan | MOE | Paper |
| 星辰-Chat | 52B | 2024-05 | 中英 | 通用 | 🤗HF | TeleChat-52B | Tele-AI | CD | |
| LingLong | 317M | 2024-05 | 中英 | 通用 | 🤗HF | linglong | nkcs-iclab | CD | |
| Sailor | 14B | 2024-05 | 7语 | 通用 | 🤗HF | sailor-llm | sail-sg | CD | Paper |
| Nanbeige2 | 8/16B | 2024-05 | 中英 | 通用 | 🤗HF | Nanbeige | Nanbeige | CD | |
| Yi-1.5-Chat | 6/9/34B | 2024-05 | 中英 | 通用 | 🤗HF | Yi-1.5 | 01-ai | CD | Paper |
| DeepSeek-V2-Chat | A21B/236B | 2024-05 | 中英 | 通用 | 🤗HF | DeepSeek-V2 | deepseek-ai | MOE | Paper |
| XVERSE-MoE | A4.2B/25.8B | 2024-05 | 中英 | 通用 | 🤗HF | XVERSE-MoE-A4.2B | xverse-ai | MOE | |
| Llama3-zh | 8/70B | 2024-04 | 中英 | 通用 | 🤗HF | / | / | CD | llama3中文列表 |
| Llama3-Chinese-Chat | 8B | 2024-04 | 中英 | 通用 | 🤗HF | / | Shenzhi Wang | CD | |
| Llama-3-Chat | 8/70B | 2024-04 | 多语 | 通用 | 🤗HF | llama3 | Meta Llama | CD | |
| Zhinao-Chat | 7B | 2024-04 | 中英 | 通用 | 🤗HF 🤖 | / | 奇虎科技 | CD | |
| MiniCPM-MoE | 8x2B | 2024-04 | 中英 | 通用 | 🤗HF | MiniCPM | OpenBMB | MoE | |
| Nanbeige2-Chat | 8B | 2024-04 | 中英 | 通用 | 🤗HF | Nanbeige | Nanbeige LLM Lab | CD | |
| Sailor | 7B | 2024-04 | 多语 | 通用 | 🤗HF | sailor-llm | Sea AI Lab | CD | Paper |
| Mengzi3-Chat | 13B | 2024-04 | 中英 | 通用 | 🤗HF |
Mengzi3
|
Langboat | CD | |
| Qwen-MoE | 2.7B | 2024-03 | 中英 | 通用 | 🤗HF |
Qwen1.5
|
Qwen | MoE | Blog |
| Command-R | 35B | 2024-03 | 多语 | 通用 | 🤗HF | / | CohereForAI | CD | |
| Breeze-Instruct | 7B | 2024-02 | 中英 | 通用 | 🤗HF | / | MediaTek Research | ||
| aya-101 | 13B | 2024-02 | 多语 | 通用 | 🤗HF | / | Cohere For AI | CD | Paper |
| ChemLLM | 7B | 2024-02 | 多语 | 通用 | 🤗HF | / | AI4Chem | CD | Paper |
| TowerInstruct | 7/13B | 2024-02 | 多语 | 通用 | [🤗HF] | / | Unbabel | CD | |
| Qwen1.5-Chat | 0.5/1.8/4/ 7/14/32/72/110B |
2024-02 | 中英 | 通用 | [🤗HF] |
Qwen1.5
|
Qwen | / | Blog |
| MiniCPM | 2B | 2024-02 | 中英 | 通用 | [🤗HF] ModelScope |
MiniCPM
|
OpenBMB | / | Report |
| LongAlign-Chat | 6/7/13B | 2024-02 | 中英 | 通用 | [🤗HF] |
LongAlign
|
THUDM | / | Paper |
| Chinese-Mixtral-Chat | 8x7B | 2024-02 | 中英 | 通用 | [Baidu] [🤗HF] |
Chinese-Mixtral
|
Yiming Cui | MOE | |
| iFlytekSpark-Chat | 13B | 2024-01 | 中英 | 通用 | mindspore | / | 科大讯飞 | CD | |
| rwkv-5-world | 0.1/1/ 3/7B |
2023-01 | 多语 | 通用 | [🤗HF] |
RWKV-LM
|
BlinkDL | URL | |
| Orion-Chat | 14B | 2024-01 | 多语 | 通用 | [🤗HF] |
Orion
|
OrionStarAI | CD | Paper |
| internlm2-chat | 7/20B | 2024-01 | 中英 | 通用 | [🤗HF] |
InternLM
|
InternLM | CD | Report |
| Chinese-Mixtral | 8x7B | 2023-01 | 中英 | 通用 | [🤗HF] | / | HIT-SCIR | CD-MOE | |
| Telechat | 7/12B | 2024-01 | 中英 | 通用 | [🤗HF] |
Telechatx 
|
Tele-AI | CD | Report |
| kagentlms | 7/13B | 2024-01 | 中英 | 通用 | [🤗HF] |
KwaiAgents
|
KwaiKEG | ||
| YaYi2-Chat | 30B | 2023-12 | 多语 | 通用 | [🤗HF] |
YAYI2
|
wenge-research | CD | Paper |
| SUS-Chat | 34/72B | 2023-12 | 中英 | 通用 | [🤗HF] |
SUS-Chat
|
SUSTech-IDEA | CD | |
| Aquila2-Chat | 7/34/70B | 2023-12 | 中英 | 通用 | [🤗HF] |
Aquila2
|
FlagAI | CD | |
| Alaya-Chat | 7B | 2023-12 | 中英 | 通用 | [🤗HF] |
Alaya
|
DataCanvas | CD | |
| Qwen-Chat | 1.8/7/ 14/72B |
2023-12 | 中英 | 通用 | [🤗HF] |
Qwen
|
阿里云 | CD | Paper Report Report2 |
| DeepSeek-Chat | 7/67B | 2023-11 | 中英 | 通用 | [🤗HF] |
DeepSeek-LLM
|
deepseek-ai | CD | |
| Yi-Chat | 6/34B | 2023-11 | 中英 | 通用 | [🤗HF] |
Yi
|
01.AI | CD | |
| Alaya-Chat | 7B | 2023-11 | 中英 | 通用 | [🤗HF] |
Alaya
|
DataCanvasIO | CD | |
| OrionStar-Yi-Chat | 34B | 2023-11 | 中英 | 通用 | [🤗HF] |
OrionStar-Yi-34B-Chat
|
OrionStarAI | CD | |
| Nanbeige-Chat | 16B | 2023-11 | 中英 | 通用 | [🤗HF] |
Nanbeige
|
Nanbeige LLM Lab | CD | |
| OpenChat 3.5 | 7B | 2023-11 | 中英 | 通用 | [🤗HF] | openchat | OpenChat | CD | Paper |
| XVERSE-Chat | 7/13B | 2023-11 | 多语 | 通用 | [🤗HF] |
XVERSE
|
元象科技 | CD | |
| AndesGPT | 7B | 2023-11 | 中文 | 通用 | [🤗HF] | AndesGPT-7B | OPPO-Mente-Lab | CD | |
| SeaLLM-Chat | 13B | 2023-11 | 多语 | 通用 | [🤗HF] | SeaLLMs | SeaLLMs | CD | |
| BlueLM | 7B | 2023-11 | 中英 | 通用 | [🤗HF] |
BlueLM
|
vivo AI Lab | CD | |
| Skywork-chat | 13B | 2023-10 | 中文 | 通用 | [🤗HF] | Skywork | SkyworkAI | CD | Paper |
| Zephyr | 7B | 2023-10 | 多语 | 通用 | [🤗HF] |
alignment-handbook
|
Hugging Face H4 | CD | Paper |
| Mistral | 7B | 2023-10 | 多语 | 通用 | [🤗HF] |
mistral-src
|
Mistral AI | CD | Paper |
| chatglm3 | 6B | 2023-10 | 中英 | 通用 | [🤗HF] |
ChatGLM3
|
THUDM | ND | |
| Zhiyin-chat | 7B | 2023-10 | 中英 | 通用 | [🤗HF] |
Zhiyin
|
中科院声学所 | CD | |
| Ziya2-Chat | 13B | 2023-10 | 中英 | 通用 | [🤗HF] | Fengshenbang-LM | IDEA研究院 | CD | |
| Vulture | 40/180B | 2023-10 | 多语 | 通用 | [🤗HF] | / | VILM-AI | TODO | |
| Vulture | 3/7/ 40/180B |
2023-09 | 多语 | 通用 | [🤗HF] | / | VILM | CD | |
| Colossal-LLaMA-2 | 7B | 2023-09 | 中英 | 通用 | [🤗HF] |
ColossalAI
|
HPC-AI Tech | CD | Blog |
| OpenBA-chat | 15B | 2023-09 | 中英 | 通用 | TODO |
OpenBA
|
OpenNLG Group | ED | Paper |
| WeMix-LLaMA2 | 7/70B | 2023-09 | 中英 | 通用 | [🤗HF] |
WeMix-LLM
|
Alpha-VLLM | CD | |
| Stable Beluga | 7/13/70B | 2023-09 | 中英 | 通用 | [🤗HF] | / | Stability AI | CD | |
| TigerBot-chat | 70B | 2023-09 | 中英 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | Paper |
| Openbuddy_llama | 70B | 2023-09 | 多语 | 通用 | [🤗HF] |
OpenBuddy
|
OpenBuddy | CD | |
| falcon-180B-chat | 180B | 2023-09 | 多语 | 通用 | [🤗HF] | / | Technology Innovation Institute | CD | |
| Baichuan2 | 7/13B | 2023-09 | 中文 | 通用 | [🤗HF] |
Baichuan2
|
百川智能 | CD | |
| Chinese-Alpaca-2-16K | 7/13B | 2023-09 | 中英 | 通用 | [🤗HF] | Chinese-LLaMA-Alpaca-2 | Yiming Cui | CD | |
| InternLM-Chat-8k | 7B | 2023-08 | 中文 | 通用 | [🤗HF] |
InternLM
|
上海人工智能实验室 | CD | report |
| InternLM-Chat-v1.1 | 7B | 2023-08 | 中文 | 通用 | [🤗HF] |
InternLM
|
上海人工智能实验室 | CD | report |
| YuLan-Chat-2 | 13B | 2023-08 | 中英 | 通用 | [🤗HF] | YuLan-Chat | 中国人民大学 | CD | |
| falcon | 7/40B | 2023-06 | 多语 | 通用 | [🤗HF] | [🤗HF] | Technology Innovation Institute | CD | |
| Toucan | 7B | 2023-08 | 中英 | 通用 | [🤗HF] |
Toucan-LLM
|
Kendryte | CD | |
| Zhuzhi | 6B | 2023-08 | 中英 | 通用 | [🤗HF] |
Zhuzhi-6B
|
竹间智能 | ND | |
| Atom | 7B | 2023-08 | 中英 | 通用 | [🤗HF] |
Llama2-Chinese
|
FlagAlpha | CD | |
| openbuddy | 3/7/ 13/40B |
2023-08 | 多语 | 通用 | [🤗HF] |
OpenBuddy
|
OpenBuddy | CD | |
| Aquila-Chat-33B | 33B | 2023-08 | 中英 | 通用 | TODO |
Aquila
|
FlagAI | CD | |
| vicuna-V1.5-16K | 7/13B | 2023-08 | 多语 | 通用 | [🤗HF] |
FastChat
|
lm-sys | CD | Paper |
| vicuna-V1.5 | 7/13B | 2023-08 | 多语 | 通用 | [🤗HF] |
FastChat
|
lm-sys | CD | Paper |
| Chinese-Alpaca-2 | 13B | 2023-08 | 中英 | 通用 | [🤗HF] | Chinese-LLaMA-Alpaca-2 | Yiming Cui | CD | |
| WizardLM-V1.0 | 70B | 2023-08 | 多语 | 通用 | [🤗HF] |
WizardLM
|
operatorx | CD | |
| TigerBot-chat-13B | 13B | 2023-07 | 中英 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | |
| huozi | 7B | 2023-08 | 中英 | 通用 | [🤗HF] |
huozi
|
哈工大 | CD | |
| Chinese-Alpaca-2 | 7B | 2023-07 | 中英 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca-2
|
Yiming Cui | CD | |
| AntX | 7/13B | 2023-07 | 中文 | 通用 | [🤗HF] | / | AntX.ai | CD | |
| BatGPT | 15B | 2023-07 | 中英 | 通用 | [🤗HF] |
BatGPT
|
上海交通大学 | ND | Paper |
| WizardLM-V1.2 | 13B | 2023-07 | 多语 | 通用 | [🤗HF] |
WizardLM
|
operatorx | CD | Paper |
| llama2-Chinese-chat | 13B | 2023-07 | 中英 | 通用 | [🤗HF] |
llama2-Chinese-chat
|
Ke Bai | CD | |
| Jiang-chat | 13B | 2023-07 | 中文 | 通用 | [🤗HF] | / | 知未智能 | CD | |
| Llama2-chinese-chat | 7/13B | 2023-07 | 中英 | 通用 | [🤗HF] |
Llama2-Chinese
|
FlagAlpha | CD | |
| LL7M | 7B | 2023-07 | 多语 | 通用 | [🤗HF] | / | Joseph Cheung | CD | |
| Chinese-Llama-2 | 7B | 2023-07 | 中英 | 通用 | [🤗HF] |
Chinese-Llama-2-7b
|
LinkSoul-AI | CD | |
| Llama2-chat | 7/13/70B | 2023-07 | 多语 | 通用 | [🤗HF] |
llama
|
Meta | CD | Paper |
| PolyLM-chat | 13B | 2023-07 | 多语 | 通用 | [🤗HF] | PolyLM | 达摩院 | CD | Paper |
| Baichuan-13B-chat | 13B | 2023-07 | 中文 | 通用 | [🤗HF] |
Baichuan-13B
|
百川智能 | CD | |
| vicuna-V1.3 | 7/13/33B | 2023-07 | 多语 | 通用 | [🤗HF] |
FastChat
|
lm-sys | CD | Paper |
| WizardLM-V1.0 | 7/13/30B | 2023-07 | 多语 | 通用 | [🤗HF] |
WizardLM
|
operatorx | CD | Paper |
| TigerBot-v2-sft | 7B | 2023-07 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | |
| InternLM-chat | 7/20B | 2023-07 | 中文 | 通用 | [🤗HF] |
InternLM
|
上海人工智能实验室 | CD | report |
| vicuna汉化版 | 33B | 2023-07 | 中文 | 通用 | baidu-hiks |
chinese-StableVicuna
|
ziwang-com | CD | |
| CuteGPT | 13B | 2023-07 | 中英 | 通用 | [🤗HF] |
CuteGPT
|
复旦大学知识工场 | CD | |
| MPT-chat | 7/30B | 2023-06 | 多语 | 通用 | [🤗HF] |
llm-foundry
|
MosaicML | CD | |
| ChatGLM2 | 6B | 2023-06 | 中英 | 通用 | [🤗HF] |
ChatGLM2-6B
|
清华大学 | ND | |
| BayLing | 7/13B | 2023-06 | 中英 | 通用 | [🤗HF] |
BayLing
|
中国科学院 | CD | |
| ZhiXi-Diff | 13B | 2023-06 | 中英 | 通用 | [🤗HF] |
KnowLLM
|
浙江大学 | CD | |
| Anima | 33B | 2023-06 | 中文 | 通用 | [🤗HF] |
Anima
|
Gavin Li | CD | |
| OpenLLaMA-Chinese | 3/7/13B | 2023-06 | 中文 | 通用 | [🤗HF] |
OpenLLaMA-Chinese
|
FittenTech | CD | |
| openbuddy-falcon-7b-v1.5 | 7B | 2023-06 | 多语 | 通用 | [🤗HF] |
OpenBuddy
|
OpenBuddy | CD | |
| AtomGPT_chat | 13B | 2023-06 | 中英 | 通用 | [🤗HF] |
AtomGPT
|
原子回声 | CD | |
| AquilaChat | 7B | 2023-06 | 中英 | 通用 | [🤗HF] |
Aquila
|
FlagAI | CD | |
| YuLan-Chat | 13/65B | 2023-06 | 中英 | 通用 | [🤗HF] |
YuLan-Chat
|
中国人民大学 | CD | |
| Chinese-Alpaca | 33B | 2023-06 | 中文 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca
|
Yiming Cui | CD | |
| TigerBot-sft | 7/180B | 2023-06 | 多语 | 通用 | [🤗HF] |
TigerBot
|
虎博科技 | CD | |
| ChatYuan | 7B | 2023-06 | 中英 | 通用 | [🤗HF] |
ChatYuan-7B
|
ClueAI | CD | |
| Panda-Instruct | 13B | 2023-05 | 中英 | 通用 | [🤗HF] |
pandallm
|
dandelionsllm | CD | |
| Panda-Instruct | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
pandallm
|
dandelionsllm | CD | |
| BiLLa-SFT | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
BiLLa
|
Zhongli Li | CD | |
| Ziya-LLaMA-v1 | 13B | 2023-05 | 中英 | 通用 | [🤗HF] |
Fengshenbang-LM
|
IDEA研究院 | CD | Blog |
| BLOOMChat V1.0 | 176B | 2023-05 | 多语 | 通用 | [🤗HF] | bloomchat | SambaNova Systems | CD | Blog |
| BiLLa | 7B | 2023-05 | 中英 | 通用 | [🤗HF] |
BiLLa
|
Zhongli Li | CD | |
| Bactrian-X | 7/13B | 2023-05 | 多语 | 通用 | [🤗HF] |
bactrian-x
|
MBZUAI | CD | |
| Bactrian-ZH | 7B | 2023-05 | 中文 | 通用 | [🤗HF] |
bactrian-x
|
MBZUAI | CD | |
| ChatFlow | 7/13B | 2023-05 | 中英 | 通用 | [🤗HF] |
Linly
|
深圳大学计算机视觉研究所 | CD | |
| OpenBuddy | 7/13B | 2023-05 | 多语 | 通用 | [🤗HF] |
OpenBuddy
|
OpenBuddy | CD | |
| YuYan-dialogue | 11B | 2023-04 | 中文 | 通用 | [🤗HF] | / | 网易伏羲 | CD | paper |
| Moss-moon-003-sft-plugin | 16B | 2023-04 | 中英 | 通用 | [🤗HF] |
MOSS
|
复旦大学 | CD | |
| moss-moon-003-sft | 16B | 2023-04 | 中英 | 通用 | [🤗HF] |
MOSS
|
复旦大学 | CD | |
| RWKV-4-Raven | 3/7/14B | 2023-04 | 中英 | 通用 | [🤗HF] |
ChatRWKV
|
BlinkDL | RNN | Blog |
| Phoenix-inst-chat | 7B | 2023-04 | 中文 | 通用 | [🤗HF] |
LLMZoo
|
香港中文大学 | CD | |
| Phoenix-chat | 7B | 2023-04 | 中文 | 通用 | [🤗HF] |
LLMZoo
|
香港中文大学 | CD | |
| ChatPLUG | 3.7B | 2023-04 | 中文 | 通用 | [🤗HF] |
ChatPLUG
|
阿里巴巴 | ED | Paper |
| Chinese-Alpaca | 13B | 2023-04 | 中文 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca
|
Yiming Cui | CD | |
| BELLE-LLAMA | 13B | 2023-04 | 中文 | 通用 | [🤗HF] |
BELLE
|
贝壳 | CD | |
| LLaMA-tuned | 7/13/ 33/65B |
2023-04 | 中文 | 通用 | [🤗HF] |
LMFlow
|
香港科技大学 | CD | |
| Chinese-Vicuna | 7/13B | 2023-03 | 中文 | 通用 | [🤗HF] |
Chinese-Vicuna
|
Facico | CD | |
| ChatYuan-V2 | 0.7B | 2023-03 | 中英 | 通用 | [🤗HF] |
ChatYuan
|
元语智能 | ED | |
| Chinese-Alpaca | 7B | 2023-03 | 中文 | 通用 | [🤗HF] |
Chinese-LLaMA-Alpaca
|
Yiming Cui | CD | |
| Luotuo | 7B | 2023-03 | 中文 | 通用 | [🤗HF] | Chinese-alpaca-lora | 华中师范大学 | CD | |
| BELLE-LLAMA | 7B | 2023-03 | 中英 | 通用 | [🤗HF] |
BELLE
|
贝壳 | CD | |
| ChatGLM | 6B | 2023-03 | 中英 | 通用 | [🤗HF] |
ChatGLM-6B
|
清华大学 | ND |
开源的垂直领域对话大模型
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 架构 | 文献 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen-coder-2.5 | 0.5/1.5/14/32B | 2024-11 | 中英 | 代码 | 🤗HF | Qwen2.5-Coder | QwenLM | CD | Paper |
| OpenCoder-Instruct | 1.5/8B | 2024-11 | 中英 | 代码 | 🤗HF | OpenCoder-llm | OpenCoder-llm | CD | Paper |
| 珠算 | 2.7B | 2024-09 | 中英 | 代码 | 🤗HF | Abacus | HIT-SCIR | CD | |
| Qwen-2.5-code | 1.5/7B | 2024-09 | 中英 | 代码 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog |
| Qwen-2.5-math | 1.5/7/72B | 2024-09 | 中英 | 数学 | 🤗HF | Qwen2.5 | QwenLM | CD | Blog |
| Yi-Coder | 1.5/9B | 2024-09 | 中英 | 代码 | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel | Yi-Coder | 01-ai | CD | Paper Blog |
| CodeGeeX4 | 9B | 2024-07 | 多语 | 代码 | 🤗HF | CodeGeeX4 | THUDM | ||
| DeepSeek-Coder-V2 | A16B/236B | 2024-06 | 中英 | 代码 | 🤗HF | DeepSeek-V2 | deepseek-ai | MoE | Paper |
| AutoCoder | 6.7/33B | 2024-06 | / | 代码 | 🤗HF | AutoCoder | Bin Lei | CD | Paper |
| Codestral | 22B | 2024-05 | / | 代码 | 🤗HF | / | mistralai | / | Blog |
| CodeQwen1.5-Chat | 7B | 2024-04 | 中英 | 代码 | 🤗HF | Qwen1.5 | Qwen | CD | Blog |
| codegemma | 2/7B | 2024-04 | 多语 | 代码 | 🤗HF | / | |||
| WaveCoder | 6.7B | 2024-04 | 多语 | 代码 | 🤗HF | WaveCoder | microsoft | Paper | |
| ChemDFM | 13B | 2024-03 | 中英 | 化学 | 🤗HF | / | OpenDFM | CD | Paper |
| starcoder2 | 3/7/15B | 2024-02 | 中英 | 代码 | 🤗HF | starcoder2 | bigcode-project | CD | Paper |
| TuringMM-Chat | 34B | 2024-02 | 中英 | 教育 | 🤗HuggingFace 🤖ModelScope | / | 光年无限 | CD | |
| deepseek-moe | 16B | 2024-01 | 中英 | 代码 | [🤗HF] |
DeepSeekMoE
|
DeepSeek | CD-MOE | |
| Code Millenials | 1/3/ 13/34B |
2023-01 | 多语 | 代码 | [🤗HF] |
code-millenials
|
BudEcosystem | CD | |
| WizardCoder | 15/33B | 2024-01 | 多语 | 代码 | [🤗HF] |
WizardLM
|
operatorx | CD | Paper |
| DeepSeek-Coder | 1/7/33B | 2023-11 | 中英 | 代码 | [🤗HF] |
DeepSeek-Coder
|
deepseek-ai | Blog | |
| Phind | 34B | 2023-10 | 多语 | 代码 | [🤗HF] | / | Phind | CD | Blog zh |
| Tongyi-Finance-Chat | 14B | 2023-11 | 中文 | 金融 | ModelScope | 通义金融-14B-Chat | 通义金融大模型 | CD | |
| Skywork-math | 13B | 2023-10 | 中文 | 数学 | [🤗HF] |
Skywork
|
SkyworkAI | CD | Paper |
| XuanYuan-Chat | 70B | 2023-10 | 中英 | 金融 | [🤗HF] |
XuanYuan
|
Duxiaoman度小满 | CD | |
| zhilu | 13B | 2023-10 | 中英 | 金融 | [🤗HF] | / | SYSU-MUCFC-FinTech-Research-Center | CD | |
| TestGPT | 7B | 2023-10 | 中文 | 测试 | [🤗HF] |
Test-Agent
|
codefuse-ai | CD | |
| cross | 7/13B | 2023-10 | 多语 | 数学 | [🤗HF] | / | Mathoctopus | CD | |
| CodeFuse | 13/14/ 15/34B |
2023-10 | 中文 | 代码 | [🤗HF] |
MFTCoder
|
codefuse-ai | CD | |
| Taiyi | 7B | 2023-10 | 中英 | 医学 | [🤗HF] |
Taiyi-LLM
|
DUTIR-BioNLP | CD | |
| CodeShell-chat | 7B | 2023-10 | 中英 | 代码 | [🤗HF] |
codeshell
|
WisdomShell | CD | |
| DISC-LawLLM | 13B | 2023-09 | 中文 | 法律 | [🤗HF] | / | ShengbinYue | CD | Report |
| WiNGPT-chat | 7B | 2023-09 | 中文 | 医学 | [🤗HF] |
WiNGPT2
|
Winning Health AI Research | CD | |
| ziya-coding | 15/34B | 2023-09 | 中英 | 代码 | [🤗HF] | Fengshenbang-LM | IDEA研究院 | CD | |
| AgriGPT | 6/13b | 2023-09 | 中文 | 农业 | [🤗HF] |
AgriGPTs
|
AgriGPTs | ||
| XuanYuan-chat | 70B | 2023-09 | 中文 | 金融 | TODO | XuanYuan | 度小满 | CD | Report |
| 夫子•明察 | 6B | 2023-09 | 中文 | 司法 | [🤗HF] |
fuzi.mingcha
|
山东大学 | ND | |
| 仲景 | 13B | 2023-09 | 中文 | 医学 | [🤗HF] |
Zhongjing
|
Songhua Yang | CD | Paper |
| CodeFuse | 13/34B | 2023-09 | 中英 | 代码 | [🤗HF] |
MFTCoder
|
codefuse-ai | CD | |
| EcomGPT | 7B | 2023-09 | 中英 | 电商 | TODO |
EcomGPT
|
Alibaba | ||
| DISC-MedLLM | 13B | 2023-08 | 中文 | 医疗 | [🤗HF] |
DISC-MedLLM
|
FudanDISC | CD | Paper |
| K2 | 7B | 2023-08 | 中英 | 科学 | [🤗HF] |
k2
|
daven | CD | |
| CodeLLAma | 7/13/34B | 2023-08 | 多语 | 代码 | [🤗HF] |
codellama
|
Meta Research | CD | Paper |
| sqlcoder | 15B | 2023-08 | 中英 | 代码 | [🤗HF] |
sqlcoder
|
Defog.ai | CD | |
| 智海-录问 | 7B | 2023-08 | 中文 | 法律 | [🤗HF] |
wisdomInterrogatory
|
zhihaiLLM | CD | |
| WizardMath-V1.0 | 7/13/70B | 2023-08 | 多语 | 数学 | [🤗HF] |
WizardLM
|
operatorx | CD | |
| QiaoBan | 7B | 2023-08 | 中文 | 情感 | [🤗HF] |
QiaoBen
|
哈尔滨工业大学 | ||
| HuangDi | 13B | 2023-08 | 中文 | 中医 | [🤗HF] |
HuangDI
|
Zlasejd | CD | |
| ZhongJing | 2023-08 | 中文 | 中医 | TODO |
CMLM-ZhongJing
|
复旦大学 | |||
| TCMLLM | 6B | 2023-08 | 中文 | 中医 | [🤗HF] |
TCMLLM
|
2020MEAI | ND | |
| AutoAudit | 7B | 2023-07 | 中文 | 安全 | [🤗HF] |
AutoAudit
|
Jiaying Li | CD | |
| Lychee | 10B | 2023-07 | 中文 | 法律 | [🤗HF] |
lychee_law
|
davidpig | ND | |
| IvyGPT | 6B | 2023-07 | 中文 | 医学 | [🤗HF] |
IvyGPT
|
WangRongsheng | ||
| MING | 7B | 2023-07 | 中文 | 医学 | [🤗HF] |
MING
|
上海交通大学 | CD | |
| Mozi | 7B | 2023-07 | 中英 | 科技 | [🤗HF] |
science-llm
|
GMFTBY | CD | |
| StarGLM | 6B | 2023-07 | 中文 | 天文 | [🤗HF] |
StarGLM
|
LI YUYANG | ND | |
| TransGPT | 7B | 2023-07 | 中英 | 交通 | [🤗HF] |
TransGPT |
北京交通大学 | CD | |
| CodeGeeX2 | 6B | 2023-07 | 中英 | 代码 | [🤗HF] |
CodeGeeX2
|
清华大学 | ND | |
| Yayi-llama2 | 7/13B | 2023-07 | 中英 | 舆情 | [🤗HF] |
Yayi
|
中科闻歌 | CD | |
| Ziya-Writing | 13B | 2023-07 | 中英 | 写作 | [🤗HF] | Fengshenbang-LM | IDEA研究院 | CD | |
| MindChat | 13B | 2023-07 | 中文 | 心理 | [🤗HF] |
MindChat
|
华东理工大学 | CD | |
| ShenNong-TCM-LLM | 7B | 2023-07 | 中英 | 医学 | [🤗HF] |
ShenNong-TCM-LLM
|
michael-wzhu | CD | |
| ailawyer | 13B | 2023-07 | 中英 | 法律 | [🤗HF] |
JurisLMs
|
openkg | CD | |
| educhat | 7B/13B | 2023-06 | 中英 | 教育 | [🤗HF] |
EduChat
|
华东师范大学 | CD | |
| Sunsimiao | 7B | 2023-06 | 中英 | 医学 | [🤗HF] |
Sunsimiao
|
华东理工大学 | CD | |
| Media LLaMA | 7B | 2023-06 | 中文 | 媒体 | baidu |
Media-LLaMA
|
智媒开源研究院 | CD | |
| PULSE | 7/14B | 2023-06 | 中文 | 医学 | [🤗HF] |
PULSE
|
OpenMEDLab | CD | |
| ChatLaw | 13/33B | 2023-06 | 中文 | 法律 | [🤗HF] |
ChatLaw
|
北京大学 | CD | |
| BaoLuo | 6B | 2023-06 | 中文 | 法律 | [🤗HF] |
BaoLuo-LawAssisant
|
LeiZi | ND | |
| CoLLaMA | 7B | 2023-06 | 中英 | 代码 | [🤗HF] |
CoLLaMA
|
Denilah | CD | |
| TechGPT | 7B | 2023-06 | 中英 | 教育 | [🤗HF] |
TechGPT
|
东北大学 | CD | |
| Yayi | 7B | 2023-06 | 中英 | 舆情 | [🤗HF] |
Yayi
|
中科闻歌 | CD | |
| MeChat | 6B | 2023-06 | 中文 | 医学 | [🤗HF] |
smile
|
qiuhuachuan | ND | |
| ziya-medical | 13b | 2023-06 | 中英 | 医学 | [🤗HF] |
MedicalGPT
|
Ming Xu | CD | |
| Taoli | 7B | 2023-06 | 中英 | 教育 | 待开源 |
taoli
|
北京语言大学 | CD | |
| Lawyer-llama | 13B | 2023-06 | 中英 | 法律 | [🤗HF] |
lawyer-llama
|
Quzhe Huang | CD | |
| QiZhen-CaMA | 13B | 2023-06 | 中英 | 医学 | [🤗HF] |
QiZhenGPT
|
浙江大学 | CD | |
| 扁鹊-2.0 | 6B | 2023-06 | 中文 | 医学 | [🤗HF] |
BianQue
|
华南理工大学 | ND | |
| SoulChat | 6B | 2023-06 | 中文 | 心理 | [🤗HF] |
SoulChat
|
华南理工大学 | ND | |
| HanFei | 7B | 2023-05 | 中文 | 法律 | baidu-d6t5 |
HanFei
|
中国科学院深圳先进院 | CD | |
| QiZhen | 6B | 2023-05 | 中英 | 医学 | [baidu] |
QiZhenGPT
|
浙江大学 | CD | |
| ChatMed-Consult | 7B | 2023-05 | 中英 | 医学 | [🤗HF] |
ChatMed
|
michael-wzhu | CD | |
| LaWGPT-beta1.1 | 7B | 2023-05 | 中英 | 法律 | [🤗HF] |
LawGPT
|
Pengxiao Song | CD | |
| Cornucopia | 7B | 2023-05 | 中英 | 金融 | [🤗HF] |
Cornucopia-LLaMA-Fin-Chinese
|
yuyangmu | CD | |
| HuatuoGPT | 7B | 2023-05 | 中文 | 医学 | [🤗HF] | HuatuoGPT | 香港中文大学 | CD | Paper |
| LexiLaw | 6B | 2023-05 | 中文 | 法律 | [🤗HF] | LexiLaw | Haitao Li | ND | Paper |
| XuanYuan | 176B | 2023-05 | 中文 | 金融 | 申请 |
XuanYuan
|
度小满 | CD | Paper |
| LawGPT | 6B | 2023-05 | 中文 | 法律 | [🤗HF] |
LAW-GPT
|
hongchengliu | N | |
| 扁鹊-1.0 | 0.7B | 2023-04 | 中文 | 医学 | [🤗HF] | BianQue | scutcyr | ED | |
| ChatGLM-Med | 6B | 2023-04 | 中文 | 医学 | [🤗HF] |
Med-ChatGLM
|
哈尔滨工业大学 | ED | |
| BenTsao | 7B | 2023-04 | 中文 | 医学 | [🤗HF] |
Huatuo-Llama-Med-Chinese
|
哈尔滨工业大学 | CD | |
| DoctorGLM | 6B | 2023-04 | 中文 | 医学 | TODO |
DoctorGLM
|
xionghonglin | ND | |
| Firefly | 1/2/7B | 2023-04 | 中文 | 文化 | [🤗HF] |
Firefly
|
Yang JianXin | CD | |
| ChatRWKV | 7B | 2023-01 | 中英 | 小说 | [🤗HF] |
ChatRWKV
|
BlinkDL | RNN | Blog |
收集包含中文的多模态大模型,具备对话等功能。
| 模型 | 大小 | 时间 | 语言模型 | 非语言模型 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 文献 |
|---|---|---|---|---|---|---|---|---|---|---|
| Aya Vision | 8/32B | 2025-03 | C4AI Command R7B | SigLIP2-patch14-384 | 多语 | 文图 | 🤗 HF | / | Cohere For AI | |
| Phi-4-multimodal-instruct | 5.6B | 2025-03 | / | / | 多语 | 文图 | 🤗 HF | / | Microsoft | Phi-4-multimodal Technical Report |
| CogView4 | 6B | 2025-03 | GLM-4-9B | / | 中英 | 文图 | 🤗 HF | CogView4 | THUDM | arxiv |
| Wan2.1 | 1.3/14B | 2025-02 | / | / | 中英 | 文视图 | 🤗 HF | Wan2.1 | Wan-Video | / |
| Step-Audio-Chat | 130B | 2025-02 | Step-1 | / | 多语 | 文音 | 🤗 HF | Step-Audio | stepfun-ai | Paper |
| Ovis2 | 1/4/16/34B | 2025-02 | Qwen2.5 | aimv2-large | 中英 | 文图视 | 🤗 HF | Ovis | AIDC-AI | Paper |
| Janus-Pro | 1.5/7B | 2025-02 | deepseek-llm | SigLIP-L | 中英 | 文图 | 🤗 HF | Janus | deepseek-ai | paper |
| OuteTTS | 2025-01 | Qwen2.5-0.5B | OLMo-1B | 多语 | 文音 | 🤗 HF | OuteTTS | edwko | Blog | |
| MiniCPM-o | 8B | 2025-01 | Qwen2.5-7B | SigLip-400M、Whisper-medium-300M, ChatTTS-200M | 中英 | 文音图 | 🤗 HF | MiniCPM-o | OpenBMB | |
| Sa2VA | 1/4/8B | 2024-12 | Qwen2.5 | InternVL2.5 | 中英 | 文视图 | 🤗 HF | Sa2VA | magic-research/ Sa2VA | Paper |
| QVQ-72B-Preview | 72B | 2024-12 | / | / | 中英 | 文视图 | 🤗 HF | Qwen2-VL | QwenLM | Blog |
| Megrez-3B-Omni | 3B | 2024-12 | Megrez-3B-Instruct | SigLip-400M/Qwen2-Audio/whisper-large-v3 | 中英 | 文音图 | 🤗 HF | Infini-Megrez-Omni | infinigence | |
| DeepSeek-VL2 | 1/2.8/4.5B | 2024-12 | / | / | 文图 | 🤗 HF | DeepSeek-VL2 | deepseek-ai | Paper | |
| InternVL 2.5 | 2/4/8/26/38/78B | 2024-12 | Qwen-2.5 | InternVit | 多语 | 文图 | 🤗 HF | InternVL | OpenGVLab | blog |
| Pixtral-Large-Instruct | 124B | 2024-11 | Mistral-Large-Instruct-2407 | / | 多语 | 文图 | 🤗 Huggingface | / | mistralai | Pixtral Large blog post |
| fish-agent | 3B | 2024-11 | Qwen-2.5 | / | 多语 | 文音 | 🤗 Huggingface | fish-speech | fishaudio | |
| GLM-4-Voice | 9B | 2024-10 | GLM-4-9B | Whisper | 中英 | 文音 | 🤗 Huggingface | GLM-4-Voice | THUDM | |
| Pangea | 7B | 2024-10 | Qwen2-7B-Instruct | LLaVA-NeXT | 多语 | 图文 | 🤗HF | Pangea | neulab | Paper |
| GOT-OCR-2.0 | / | 2024-09 | Qwen | / | 中英 | 图文 | 🤗HF | GOT-OCR2.0 | StepFun-AI | Paper |
| Ovis-1.6 | 9B | 2024-09 | Gemma2-9B-It | Siglip-400M | 中英 | 图文 | 🤗 | Ovis | AIDC-AI | Paper |
| Qwen2-VL | 2/7/72B | 2024-08 | / | / | 多语 | 图文视 | 🤗 🤖 | Qwen2-VL | QwenLM | |
| CogVideoX | 2/5B | 2024-08 | / | / | 中英 | 文视 | 🤗 link | CogVideo | THUDM | |
| MiniCPM-V 2.6 | 8B | 2024-08 | Qwen2-7B | SigLip-400M | 中英 | 文图视 | 🤗 link | MiniCPM-V | OpenBMB | |
| InternVL2 | 1/2/4/8/26/40/76B | 2024-07 | Qwen2/internlm2/llama3 | InternViT | 中英 | 文图 | 🤗 link 🤖 link | InternVL | OpenGVLab | report |
| Qwen2-Audio | 8.2B | 2024-07 | Qwen2 | Whisper-large-V3 | 中英 | 文音 | 🤗HF | Qwen2-Audio | QwenLM | report |
| Kolors | / | 2024-07 | ChatGLM3-Base | / | 中英 | 文图 | 🤗HF | Kolors | Kwai-Kolors | Paper |
| ChatTTS | / | 2024-06 | / | / | 中英 | 文音 | 🤗HF | ChatTTS | 2noise | / |
| GLM-4V | 9B | 2024-06 | GLM-4 | / | 多语 | 文图 | 🤗HF | GLM-4 | THUDM | / |
| HunyuanDiT | 1.5B | 2024-05 | multilingual T5 encoder | CLIP | 中英 | 文图 | 🤗 | HunyuanDiT | Tencent | Paper |
| CogVLM2 | 2024-05 | Meta-Llama-3-8B-Instruct | / | 中英 | 文图 | 🤗 | CogVLM | Skip to content | ||
| 360VL | 8/70B | 2024-05 | LLama3 | CLIP-ViT | 中英 | 文图 | 🤗 | 360VL | 360CVGroup | |
| XVERSE-V | 13B | 2024-05 | XVERSE-13B-Chat | clip-vit-large-patch14-224 | 中英 | 文图 | 🤖 | XVERSE-V-13B | xverse-ai | |
| MiniCPM-V 2.0 | 2.8B | 2024-04 | MiniCPM-2.4B | SigLip-400M | 中英 | 文图 | 🤗 🤖 | MiniCPM-V | OpenBMB | Blog |
| Qwen-Audio | 7B | 2024-03 | Qwen-7B | Whisper-large-v2 | 中英 | 文音 | 🤗HF |
Qwen-Audio 
|
Qwen | Paper |
| DeepSeek-VL | 1.3/7B | 2024-03 | DeepSeek | SigLip/SAM | 中英 | 图文 | 🤗HF |
DeepSeek-VL
|
deepseek-ai | Paper |
| OmniLMM | 3/12B | 2024-02 | MiniCPM | SigLip | 中英 | 图文 | 🤗HF |
OmniLMM
|
[OpenBMB](https://github.com/01-ai) | |
| MiniCPM-V | 3B | 2024-02 | MiniCPM-2.4B | SigLip-400M | 中英 | 图文 | 🤗HF |
OmniLMM
|
[OpenBMB](https://github.com/01-ai) | |
| Yi-VL | 6/34B | 2024-01 | Yi | CLIP-VIT | 中英 | 图文 | [🤗HF] |
Yi
|
01-ai | |
| Lyrics | 14B | 2023-12 | / | / | 中英 | 图文 | [🤗HF] | Fengshenbang-LM | IDEA研究院 | |
| Qwen-Audio | 7B | 2023-12 | Qwen-7B | Whisper-large-v2 | 中英 | 文音 | [🤗HF] |
Qwen-Audio
|
Qwen | Paper |
| SPHINX | 13B | 2023-10 | / | / | 中英 | 图文 | [🤗HF] |
LLaMA2-Accessory
|
Alpha-VLLM | |
| Skywork-MM | 13B | 2023-10 | / | / | 中英 | 图文 | [🤗HF] | Skywork | SkyworkAI | Paper |
| CogVLM | 7/14B | 2023-10 | Qwen | ViT | 中英 | 图文 | [🤗HF] | / | CausalLM | |
| fuyu | 8B | 2023-10 | / | / | 中英 | 图文 | [🤗HF] | / | Adept AI Labs | Blog |
| Ziya-Visual | 14B | 2023-10 | LLaMA | InstructBLIP | 中英 | 图文 | [🤗HF] |
Fengshenbang-LM
|
IDEA研究院 | Paper |
| CogVLM | 17B | 2023-10 | EVA2-CLIP-E | Vicuna-v1.5 | 中英 | 图文 | TODO |
CogVLM
|
THUDM | Paper |
| idefics | 9/80B | 2023-10 | LLaMA | CLIP-ViT | 中英 | 图文 | [🤗HF] | / | HuggingFaceM4 | log |
| InternLM-XComposer | 7B | 2023-10 | InternLM | EVA-CLIP | 中英 | 图文 | [🤗HF] |
InternLM-XComposer
|
InternLM | Report |
| WeMix-LLM | 13B | 2023-09 | LLama2 | / | 中英 | 图文 | [🤗HF] |
WeMix-LLM
|
Alpha-VLLM | |
| Vally | 7/13B | 2023-08 | BelleGroup/BELLE-LLaMA-EXT | OFA-Sys/chinese-clip-vit-large-patch14 | 中英 | 图文 | [🤗HF] [🤗HF] |
Valley
|
罗瑞璞 | Paper |
| SALMONN | / | 2023-08 | / | / | 中英 | 语音 | TODO |
SALMONN
|
Bytedance | |
| IDEFICS | 9/80B | 2023-08 | llama | CLIP-ViT | 中英 | 图文-通用 | [🤗HF] |
m4-logs
|
HuggingFaceM4 | Paper |
| Qwen-VL | 7B | 2023-08 | Qwen-7B | Openclip ViT-bigG | 中英 | 通用 | [🤗HF] |
Qwen-VL
|
阿里云 | |
| Qwen-VL-chat | 7B | 2023-08 | Qwen-7B | Openclip ViT-bigG | 中英 | 通用 | [🤗HF] |
Qwen-VL
|
阿里云 | |
| LLasM | 7B | 2023-07 | Chinese-Llama2 | whisper-large-v2 | 中英 | 语音 | [🤗HF] |
LLaSM
|
北京灵琐 | |
| Chinese-LLaVA | 7B | 2023-07 | Chinese-Llama2 | Clip-vit | 中英 | 视觉 | [🤗HF] |
Chinese-LLaVA
|
北京灵琐 | |
| RemoteGLM | 6B | 2023-07 | VisualGLM-6B | VisualGLM-6B | 中文 | 遥感 | TODO |
RemoteGLM
|
lzw-lzw | |
| VisualCLA | 7B | 2023-07 | Chinese-Alpaca-Plus | CLIP-ViT-L/14 | 中文 | 视觉 | [🤗HF] |
Visual-Chinese-LLaMA-Alpaca
|
Ziqing Yang | |
| yuren | 7B | 2023-07 | baichuan-7B | CLIP | 中英 | 视觉 | [🤗HF] |
yuren-baichuan-7b
|
Pleisto | |
| VisCPM-Chat | 10B | 2023-06 | CPM-Bee | Q-Former | 中英 | 视觉 | [🤗HF] |
VisCPM
|
OpenBMB | |
| VisCPM-Paint | 10B | 2023-06 | CPM-Bee | Stable Diffusion 2.1 | 中英 | 视觉 | [🤗HF] |
VisCPM
|
OpenBMB | |
| XrayPULSE | 7B | 2023-06 | PULSE | MedCLIP | 中文 | 医学 | [🤗HF] |
XrayPULSE
|
OpenMEDLab | |
| SEEChat | 6B | 2023-06 | ChatGLM | CLIP-ViT | 中文 | / | [🤗HF] |
SEEChat
|
360 | |
| Ziya-BLIP2-14B-Visual-v1 | 14B | 2023-06 | LLaMA-13B | BLIP2 | 中英 | 通用 | [🤗HF] |
Fengshenbang-LM
|
IDEA研究院 | |
| Video-LLaMA-BiLLA | 7B | 2023-05 | BiLLa-7B | MiniGPT-4 | 中英 | 通用 | [🤗HF] |
Video-LLaMA
|
达摩院多语言NLP | Paper |
| Video-LLaMA-Ziya | 13B | 2023-05 | Ziya-13B | MiniGPT-4 | 中英 | 通用 | [🤗HF] |
Video-LLaMA
|
达摩院多语言NLP | Paper |
| XrayGLM | 6B | 2023-05 | ChatGLM-6B | BLIP2-Qformer | 中英 | 医学 | [🤗HF] |
XrayGLM
|
澳门理工大学 | |
| X-LLM | 2023-05 | ChatGLM | ViT-g | 中文 | / | TODO |
X-LLM
|
中科院自动化所 | Paper | |
| VisualGLM | 6B | 2023-05 | ChatGLM-6B | BLIP2-Qformer | 中英 | 视觉 | [🤗HF] |
VisualGLM-6B
|
清华大学 |
收集推理能力比较突出的中文大模型
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 结构 | 文 |
|---|---|---|---|---|---|---|---|---|---|
| Skywork-R1V | 38B | 2025-03 | 中英 | 多模态 | 🤗HF | Skywork-R1V | SkyworkAI | CD | Paper |
| Fin-R1 | 7B | 2025-03 | 中英 | 金融 | 🤗HF | Fin-R1 | SUFE-AIFLM-Lab | CD | Paper |
| QwQ-32B | 32B | 2025-03 | 中英 | 通用 | 🤗HF | / | QwenLM | CD | 📑 blog |
| DeepSeek-R1 | A37/671B | 2025-01 | 中英 | 通用 | 🤗HF | DeepSeek-R1 | deepseek-ai | MoE | Paper Link👁️ |
| DeepSeek-R1-Zero | A37/671B | 2025-01 | 中英 | 通用 | 🤗HF | DeepSeek-R1 | deepseek-ai | MoE | Paper Link👁️ |
| DeepSeek-R1-Distill-Qwen | 1.5/7/14/32B | 2025-01 | 中英 | 通用 | 🤗HF | DeepSeek-R1 | deepseek-ai | MoE | Paper Link👁️ |
| MiniMax-Text-01 | A46/456B | 2025-01 | 中英 | 通用 | 🤗HF | MiniMax-01 | MiniMax-AI | MoE | Paper |
| MiniMax-VL-01 | A46/456B | 2025-01 | 中英 | 多模态 | 🤗HF | MiniMax-01 | MiniMax-AI | MoE | Paper |
| Sky-T1 | 32B | 2025-01 | 中英 | 通用 | 🤗HF | SkyThought | NovaSky-AI | CD | Blog |
| Search-O1 | 2025-01 | 中英 | 通用 | / | Search-o1 | sunnynexus | CD | Paper | |
| HuatuoGPT-o1 | 7/8/70/72B | 2025-01 | 中英 | 医疗 | 🤗HF | HuatuoGPT-o1 | FreedomIntelligence/ | CD | Paper |
| QwQ-32B-Preview | 32B | 2024-11 | 中英 | 通用 | 🤗HF | / | QwenLM | CD | |
| Marco-o1 | 7B | 2024-11 | 中英 | 通用 | 🤗HF | Marco-o1 | AIDC-AI | CD | Paper |
| Skywork-01-Open | 8B | 2024-11 | 中英 | 通用 | 🤗HF | skywork-o1-prm-inference | SkyworkAI | CD | Blog |
| HK-01aw | 8B | 2024-11 | 中文 | 法律 | 🤗HF | HK-O1aw | HKAIR-Lab | CD | |
| QVQ-72B-Preview | 72B | 2024-12 | 中英 | 多模 | 🤗 HF | Qwen2-VL | QwenLM | Blog |
收集包含中文的指令数据集,用于微调语言模型。
| 名称 | 大小 | 时间 | 语言 | 下载 | 项目地址 | 作者 | 备注 |
|---|---|---|---|---|---|---|---|
| FinCorpus | 50G | 2023-09 | 中文 | dataset | XuanYuan | 度小满 | 金融领域 |
| TransGPT-sft | 346k | 2023-07 | 中文 | dataset | TransGPT | 北京交通大学 | |
| TransGPT-pt | 58k | 2023-07 | 中文 | dataset | TransGPT | 北京交通大学 | |
| ShareGPT-Chinese-English | 90K | 2023-07 | 中英 | dataset |
llama2-Chinese-chat
|
Ke Bai | |
| educhat-sft-002-data-osm | 400w | 2023-06 | 中英 | dataset | EduChat | 华东师范大学 | 教育 |
| chatgpt-corpus | 3M | 2023-06 | 中文 | dataset | chatgpt-corpus | plex | |
| Simle | 350k | 2023-06 | 中文 | dataset | smile | qiuhuachuan | 心理健康 |
| QiZhen | 20k | 2023-06 | 中文 | dataset | QiZhenGPT | 浙江大学 | 医学 |
| BayLing-80 | 80 | 2023-06 | 中英 | dataset | BayLing | 中国科学院 | 多轮指令 |
| Tigerbot-dataset | 120k | 2023-06 | 中英 | dataset | TigerBot | 虎博科技 | |
| lawyer-llama | / | 2023-05 | 中文 | dataset | lawyer-llama | Quzhe Huang | 法律 |
| Bactrian-X | 67K | 2023-05 | 多语 | dataset | bactrian-x | MBZUAI | |
| CrimeKgAssitant | 52k | 2023-05 | 中文 | dataset | LAW-GPT | hongchengliu | 法律 |
| moss-002-sft-data | 1.1M | 2023-04 | 中英 | dataset | MOSS | 复旦大学 | |
| moss-003-sft-data | 1.1M | 2023-04 | 中英 | dataset | MOSS | 复旦大学 | |
| moss-003-sft-plugin-data | 300K | 2023-04 | 中英 | dataset | MOSS | 复旦大学 | |
| Safety-Prompts | 100K | 2023-04 | 中文 | dataset | Safety-Prompts | 清华大学 | 评测平台 |
| OASST1 | / | 2023-04 | 多语 | dataset | Open-Assistant | OpenAssistant | |
| ShareChat | 90K | 2023-04 | 中英 | dataset | ShareChat | czhko | |
| GPT-4-LLM | 52K | 2023-04 | 中文 | dataset | GPT-4-LLM | Instruction-Tuning-with-GPT-4 | paper |
| COIG | 200K | 2023-04 | 中文 | dataset | FlagInstruct | BAAI | paper |
| RedGPT | 50k | 2023-04 | 中文 | dataset | RedGPT | MiniGPT | |
| shareGPT_cn | 20k | 2023-04 | 中文 | dataset | shareGPT_cn | shareAI | |
| generated_chat_0.4M | 0.4M | 2023-04 | 中文 | dataset | BELLE | Ke Technologies | 角色对话 |
| multiturn_chat_0.8M | 0.8M | 2023-04 | 中文 | dataset | BELLE | Ke Technologies | 多轮任务 |
| school_math_0.25M | 0.25M | 2023-04 | 中文 | dataset | BELLE | Ke Technologies | 数学题 |
| Zhihu-KOL | / | 2023-03 | 中文 | dataset | Zhihu-KOL | Rui Wang | |
| InstructionWild | 104k | 2023-03 | 中英 | dataset | InstructionWild | Xue Fuzhao | |
| Alpaca-CoT | /. | 2023-03 | 中英 | dataset | Alpaca-CoT | Qingyi Si | |
| GuanacoDataset | / | 2023-03 | 多语 | dataset | guanaco-model | Guanaco | |
| Traditional-Chinese-alpaca | 52K | 2023-03 | 中文 | dataset | Traditional-Chinese Alpaca | NTU NLP Lab | gpt翻译 |
| alpaca_chinese_dataset | / | 2023-03 | 中文 | dataset | alpaca_chinese_dataset | akou | 人工校验 |
| alpaca-chinese-dataset | / | 2023-03 | 中文 | dataset | alpaca-chinese-dataset | carbonz | 机器翻译 |
| train_2M_CN | 2M | 2023-03 | 中文 | dataset | BELLE | Ke Technologies | |
| train_1M_CN | 1M | 2023-03 | 中文 | dataset | BELLE | Ke Technologies | |
| train_0.5M_CN | 0.5M | 2023-03 | 中文 | dataset | BELLE | Ke Technologies | |
| HC3 人类-ChatGPT 问答 | / | 2023-03 | 中文 | dataset | chatgpt-comparison-detection | SimpleAI | |
| firefly-train-1.1M | 1.1M | 2023-03 | 中文 | dataset | Firefly | Jianxin Yang |
| 模型 | 大小 | 时间 | 语言 | 领域 | 下载 | 项目地址 | 机构/个人 | 文 |
|---|---|---|---|---|---|---|---|---|
| JinaColBERT V2 | large | 2024-08 | 多语 | 通用 | [🤗HF] | / | Jina AI | Paper |
| Conan-embedding-v1 | large | 2024-08 | 中文 | 通用 | [🤗HF] | / | TencentABC | Paper |
| xiaobu-v2 | large | 2024-07 | 中文 | 通用 | [🤗HF] | / | lier007 | |
| zpoint_large | Large | 2024-06 | 中文 | 通用 | [🤗HF] | / | yang | |
| BCE | 279M | 2024-01 | 多语 | 通用 | [🤗HF] | BCEmbedding | netease-youdao | |
| Cohere | Base | 2023-09 | 多语 | 通用 | [🤗HF] | / | Cohere | Blog |
| jina | Base | 2023-10 | 中英 | 通用 | [🤗HF] | / | Jina AI | |
| Dmeta | 400MB | 2024-02 | 中文 | 通用 | [🤗HF] | / | DMetaSoul | |
| bge-m3 | 2024-02 | 中文 | 通用 | [🤗HF] | / | BAAI | Paper | |
| tao-8k | 2023-11 | 中文 | 通用 | [🤗HF] | amu | |||
| bge | s/b/l | 2023-10 | 中文 | 通用 | [🤗HF] | / | BAAI | |
| gte-zh | s/b/l | 2023-08 | 中文 | 通用 | [🤗HF] | / | Alibaba DAMO | Paper |
| m3e | s/b/l | 2023-06 | 中文 | 通用 | [🤗HF] | / | Moka-AI | |
| LaBSE | 多语 | 通用 | [🤗HF] | / | Sentence Transformers |

C-Eval 是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,查看论文了解更多细节。

FlagEval是一个面向AI基础模型的评测工具包。我们的目标是探索和集合科学、公正、开放的基础模型评测基准、方法及工具,对多领域(如语言、语音、视觉及多模态)的基础模型进行多维度(如准确性、效率、鲁棒性等)的评测。我们希望通过对基础模型的评测,加深对基础模型的理解,促进相关的技术创新及产业应用。

SuperCLUE琅琊榜,这是一个中文通用大模型对战评价基准,它以众包的方式提供匿名、随机的对战。在本文中,我们发布了初步的结果和基于Elo评级系统的排行榜,Elo评级是国际象棋和其他竞技游戏中广泛使用的评级系统。我们邀请整个社区加入这项工作,贡献新的模型,并通过提问和投票选出你最喜欢的答案来评估它们。

该基准包括来自13个不同学科的516个学科的220,000个多项选择题,以及15,000个来自单一学科和多个学科的问题。我们对47个最新的大型语言模型在Xiezhi上进行了评估,结果表明在科学、工程、农学、医学和艺术等领域,大型语言模型的表现超过了人类的平均水平,但在经济学、法学、教育学、文学、历史和管理学等领域,人类的表现仍然远远超过了大型语言模型。
由HuggingFace组织的一个LLM评测榜单,目前已评估了较多主流的开源LLM模型,以英文为主。主要目标是跟踪、排名和评估最新的大语言模型和聊天机器人,让所有人方便的观察到开源社区的进展和评估这些模型。这个排行榜有一个关键优势,社区中的任何成员都可以提交模型,并在 Hugging Face 的 GPU 集群上自动评估。
[官方网站]

大模型安全测评依托于一套系统的安全评测框架,涵盖了仇恨言论、偏见歧视言论、犯罪违法、隐私、伦理道德等八大类别,包括细粒度划分的40余个二级安全类别。

OpenCompass 是一款开源、高效、全面的评测大模型体系及开放平台。我们提供完整开源可复现的评测框架,支持大语言模型、多模态模型各类模型的一站式评测。利用分布式技术,即使面对千亿参数模型也能在数小时内完成评测。基于多个不同维度的高认可度数据集开放多样化的评测方式,包括零样本评测、小样本评测和思维链评测,全方位量化模型各个维度能力。
注:需要申请或者注册方可体验,更多见Github
OpenAI所提出的GPT相关模型,也是目前最火的大语言模型,发布版本已经到了4.0.
[官方网站]
NewBing是微软在2023年3月推出的一款全新的搜索引擎,它基于OpenAI的大型语言模型(LLM),并结合了ChatGPT和DALL·E的技术,为用户提供了一个AI驱动的网络助手。
[官方网站]
百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
[官方网站]
阿里大模型统一品牌,覆盖语言、听觉、多模态等领域致力于实现接近人类智慧的通用智能,让AI从“单一感官”到“五官全开”
[官方网站]
科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。从海量数据和大规模知识中持续进化,实现从提出、规划到解决问题的全流程闭环。
[官方网站]
Claude,是人工智能初创公司Anthropic 发布的一款类似ChatGPT的产品。
[官方网站]
基于千亿基座模型 GLM-130B,注入代码预训练,通过有监督微调等技术实现人类意图对齐,具备问答、多轮对话、代码生成功能的中英双语大模型。
[官方网站]
天工作为一款大型语言模型,拥有强大的自然语言处理和智能交互能力,能够实现智能问答、聊天互动、文本生成等多种应用场景,并且具有丰富的知识储备,涵盖科学、技术、文化、艺术、历史等领域。
[官方网站]
序列猴子大模型是一个具有长序列、多模态、单模型、大数据等特点的超大规模语言模型,基于其通用的表示能力与推理能力,能够进行多轮交互,打造更便捷流畅的用户体验,极大地提高了生产效率和数据处理能力,被广泛应用于问答系统、自然语言处理、机器翻译、文本摘要等领域。
[官方网站]
MOSS是复旦大学自然语言处理实验室发布的国内第一个对话式大型语言模型
[官方网站]
360智脑的生成与创作、多轮对话、代码能力、阅读理解、逻辑与推理、多模态等十大核心能力可覆盖大模型全部应用场景。
[官方网站]
达观数据积极探索大语言模型LLM的实践,研发国产版GPT“曹植”系统,作为垂直、专用、自主可控的国产版ChatGPT模型,不仅实现专业领域的AIGC智能化应用,且可内置在客户各类业务系统中提供专用服务
[官方网站]
商汤“日日新SenseNova”大模型体系,正式问世
不仅展示了大模型体系下的语言大模型,还展示了AI文生图创作、2D/3D数字人生成、大场景/小物体生成等一系列生成式AI模型及应用,还揭开了依托商汤AI大装置SenseCore实现“大模型+大算力”融合创新的研发体系。
[官方网站]
天燕大模型是APUS公司自研的多模态大模型(LMM),具备对文本、图像、视频、音频的理解和生成能力(视频和音频的能力即将推出)。
[官方网站]
图文机器人
[官方网站]
[官方网站]
AI多模态搜索引擎
[官方网站]
只需一次对话即可获取信息、知识和灵感,解决需求。是每个人身边的助理、朋友和专家。
[官方网站]
MiniMax 最新一代的中文大语言模型帮助人类高效写作、激发创意、获取知识、做出决策现已对企业开放API体验
[官方网站]
- 🤗HuggingFace: The AI community building the future.
- 模型下载地址: https://huggingface.co/models
- ModelScope: ModelScope平台是以模型为中心的模型开源社区
- 模型下载地址:https://modelscope.cn/models
- flagopen: flagopen飞智大模型技术开源体系
- 模型下载地址: https://model.baai.ac.cn/models
- 始智AI: 中国AI开源创新社区
- 模型下载地址: https://wisemodel.cn/models
- huggfaceing数据集仓库: https://huggingface.co/datasets
- 包含了自然语言处理、计算机视觉、语音、多模态等数据集,内置100多个多语言公共数据集下载
- ModelScope数据集仓库:https://modelscope.cn/datasets
- 提供了覆盖自然语言处理、计算机视觉、语音、多模态等数据集,更有阿里巴巴集团贡献的专业领域数据集,
- flagopen数据集仓库: https://data.baai.ac.cn/data
- 内置公共数据集下载,可下200G大规模预训练语料WuDaoCorpora
- cluebenchmarks数据集仓库:https://www.cluebenchmarks.com/dataSet_search.html
- 多个中英文NLP数据集,并可申请下载100GB的高质量中文预训练语料CLUECorpus2020
- MNBVC: Massive Never-ending BT Vast Chinese corpus
- 超大规模中文语料集
- OpenDataLab数据集仓库: https://opendatalab.com/
- OpenDataLab 是有影响力的数据开源开放平台,公开数据集触手可及。
- OSCAR: Open Super-large Crawled Aggregated coRpus, 多语言数据集
- 最新版本包含1.4T的中文语言数据集
1. Awesome-Chatgpt  github
github

本项目旨在收集关于ChatGPT 的资源、工具、应用和用法等。
2. Awesome-ChatGPT-Prompts  github
github

本项目旨在收集关于ChatGPT 模型使用的Prompts示例集。
3. Awesome-LLM  github
github

本项目旨在收集有关大型语言模型相关资料,尤其是 ChatGPT 的论文的精选列表。它还包含 LLM 训练框架、部署 LLM 的工具、有关 LLM 的课程和教程以及所有公开可用的 LLM 模型和 API。
4. Awesome-LangChain  github
github

本项目旨在收集与LangChain有关应用列表。LangChain是一个惊人的框架,可以在短时间内完成相关LLM应用开发。
5. Awesome-Open-Gpt  github
github

本项目旨在收集关于GPT开源精选项目的合集(170+全网最全),其中包括了一些GPT镜像、GPT增强、GPT插件、GPT工具、GPT平替的聊天机器人、开源大语言模型等等。
6. Awesome-Multimodal-Large-Language-Models  github
github

本项目是关于多模态大语言模型(MLLM)的精选列表,包括数据集、多模态模型、多模态语境学习、多模态思维链、llm 辅助视觉推理、基础模型等。此列表将实时更新。✨
7. Awesome-Transformer-Attention  github
github
此 repo 包含 Vision Transformer & Attention 的综合论文列表,包括论文、代码和相关网站。
8. Awesome-Prompt-Engineering  github
github

This repository contains a hand-curated resources for Prompt Engineering with a focus on Generative Pre-trained Transformer (GPT), ChatGPT, PaLM etc
9. Awesome-AITools  github
github

这个仓库整理AI相关的实用工具。
10. Awesome-Chinese-LLM  github
github

本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个!
11. Awesome-LLM4Tool  github
github

Awesome-LLM4Tool is a curated list of the papers, repositories, tutorials, and anythings related to the large language models for tools.
12. Awesome LLM Security  github
github

A curation of awesome tools, documents and projects about LLM Security.
13. Awesome AI Agents  github
github

Welcome to our list of AI agents. We structured the list into two parts: Open source projects and Closed-source projects and companies
14. Awesome-LLM-Large-Language-Models-Notes  github
github

LLM-Large-Language-Models-Notes
15. Awesome-Efficient-LLM  github
github

A curated list for Efficient Large Language Models。
16. Awesome Datasets for LLM Training  github
github

A quick guide (especially) for trending instruction finetuning datasets。
17. Awesome-Align-LLM-Human  github
github

A collection of papers and resources about aligning large language models (LLMs) with human.
18. Awesome RLHF (RL with Human Feedback)  github
github

This is a collection of research papers for Reinforcement Learning with Human Feedback (RLHF). And the repository will be continuously updated to track the frontier of RLHF.
19. Prompt-in-context-learning  github
github

An Open-Source Engineering Guide for Prompt-in-context-learning from EgoAlpha Lab.
20. Awesome Instruction Learning  github
github

An awesome reading list of Instruction Tuning (or, put it more comprehensively, Instruction Learning), including papers and datasets.
21. Awesome-Foundation-Models  github
github

A foundation model is a large-scale pretrained model (e.g., BERT, DALL-E, GPT-3) that can be adapted to a wide range of downstream applications. This term was first popularized by the Stanford Institute for Human-Centered Artificial Intelligence. This repository maintains a curated list of foundation models for vision and language tasks. Research papers without code are not included.
22. Awesome-AI-Devtools  github
github

This is a curated list of AI-powered developer tools. These tools leverage AI to assist developers in tasks such as code completion, refactoring, debugging, documentation, and more.
23. Awesome-Autonomous-GPT  github
github

A curated list of awesome projects and resources related to autonomous AI agents.
24. Awesome-Papers-Autonomous-Agent  github
github

This is a collection of recent papers focusing on autonomous agent.
25. Awesome-Code-LLM  github
github

a comprehensive review of LLM researches for code.
26. Awesome-LLM-Compression  github
github

Awesome LLM compression research papers and tools to accelerate LLM training and inference.
27. Autonomous-Agents  github
github

Autonomous Agents (LLMs). Updated daily.
28. Awesome-Large-Multimodal-Agents  github
github

Awesome Large Multimodal Agents.
29. Awesome-LLM-Prompt-Optimization  github
github

This repo aims to record advanced papers of LLM prompt tuning and automatic optimization (after 2022).
30. Awesome-LLMs-Datasets  github
github

代表性LLM文本数据集大列表,包括预训练语料库、微调指令数据集、偏好数据集、评估数据集和传统NLP数据集.
30. Awesome-RAG-Survey  github
github

This repo is constructed for collecting and categorizing papers about RAG according to our survey paper: Retrieval-Augmented Generation for AI-Generated Content: A Survey. Considering the rapid growth of this field, we will continue to update both paper and this repo.
31. Awesome-Tool-LLM  github
github

Language models (LMs) are powerful yet mostly for text-generation tasks. Tools have substantially enhanced their performance for tasks that require complex skills.
32. LLM-Tool-Survey  github
github

Recently, tool learning with large language models~(LLMs) has emerged as a promising paradigm for augmenting the capabilities of LLMs to tackle highly complex problems.
This is the collection of papers related to tool learning with LLMs. These papers are organized according to our survey paper "Tool Learning with Large Language Models: A Survey".
33. Awesome-Foundation-Model-Leaderboards  github
github

Awesome Foundation Model Leaderboard is a curated list of awesome foundation model leaderboards (for an explanation of what a leaderboard is, please refer to this post), along with various development tools and evaluation organizations according to our survey:.
34. Awesome-LLM-KV-Cache  github
github

Awesome-LLM-KV-Cache: A curated list of 📙Awesome LLM KV Cache Papers with Codes. This repository is for personal use of learning and classifying the burning KV Cache related papers!
35. Awesome-LLM-Strawberry  github
github

This is a collection of research papers & blogs for OpenAI Strawberry(o1) and Reasoning.
And the repository will be continuously updated to track the frontier of LLM Reasoning.
36. Awesome-LLM-Resourses  github
github

🧑🚀 全世界最好的LLM资料总结 | Summary of the world's best LLM resources.
37. Awesome-LLM-Reasoning-Openai-o1-Survey  github
github

The related works and background techniques about OpenAI o1, including LLM reasoning, self-play reinforcement learning, complex logic reasoning, scaling law, etc.
38. Awesome-LLM-Reasoning  github
github

Curated collection of papers and resources on how to unlock the reasoning ability of LLMs and MLLMs.
39. Awesome-Computer-Use-Agents  github
github

This is a collection of resources for computer-use agents, including papers and blogs. The repository is currently under construction and will be continuously updated. We welcome contributions and feedback as we continue expanding this collection!
40. LLM_MultiAgents_Survey_Papers  github
github

Our survey about LLM based Multi-Agents is available at: https://arxiv.org/abs/2402.01680
- 2018 | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | Jacob Devlin, et al. | arXiv |
PDF - 2019 | Pre-Training with Whole Word Masking for Chinese BERT | Yiming Cui, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| BERT-Base | base | Google Drive | Google Research | github | 通用 | |
| BERT-wwm | base | Google Drive | Yiming Cui | github | 通用 | |
| BERT-wwm-ext | base | Google Drive | Yiming Cui | github | 通用 | |
| bert-base-民事 | base | 阿里云 | THUNLP | github | 司法 | |
| bert-base-刑事 | base | 阿里云 | THUNLP | github | 司法 | |
| BAAI-JDAI-BERT | base | 京东云 | JDAI | github | 电商客服对话 | |
| FinBERT | base | Value Simplex | github | 金融科技领域 | ||
| EduBERT | base | 好未来AI | 好未来AI | tal-tech | github | 教育领域 |
| guwenbert-base | base | Ethan | github | 古文领域 | ||
| guwenbert-large | large | Ethan | github | 古文领域 | ||
| BERT-CCPoem | small | thunlp | THUNLP-AIPoet | github | 古典诗歌 |
备注:
wwm全称为**Whole Word Masking **,一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask
ext表示在更多数据集下训练
- 2021 | ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information | Zijun Sun, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| ChineseBERT | base | [🤗HF] | ShannonAI | github | 通用 | |
| ChineseBERT | large | [🤗HF] | ShannonAI | github | 通用 |
- 2019 | RoBERTa: A Robustly Optimized BERT Pretraining Approach | Yinhan Liu, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| RoBERTa-tiny-clue | tiny | Google Drive | 百度网盘-8qvb | CLUE | github | 通用 |
| RoBERTa-tiny-pair | tiny | google drive | 百度网盘-8qvb | CLUE | github | 通用 |
| RoBERTa-tiny3L768-clue | tiny | Google Drive | CLUE | github | 通用 | |
| RoBERTa-tiny3L312-clue | tiny | google drive | 百度网盘-8qvb | CLUE | github | 通用 |
| RoBERTa-large-pair | large | Google Drive | 百度网盘-8qvb | CLUE | github | 通用 |
| RoBERTa-large-clue | large | google drive | 百度网盘-8qvb | CLUE | github | 通用 |
| RBT3 | 3层base | Google Drive | Yiming Cui | github | 通用 | |
| RBTL3 | 3层large | Google Drive | Yiming Cui | github | 通用 | |
| RBTL4 | 4层large | 讯飞云-e8dN | Yiming Cui | github | 通用 | |
| RBTL6 | 6层large | 讯飞云-XNMA | Yiming Cui | github | 通用 | |
| RoBERTa-wwm-ext | base | Google Drive | Yiming Cui | github | 通用 | |
| RoBERTa-wwm-ext-large | large | Google Drive | Yiming Cui | github | 通用 | |
| RoBERTa-base | base | brightmart | github | 通用 | ||
| RoBERTa-Large | large | Google Drive | brightmart | github | 通用 | |
| RoBERTa-tiny | tiny | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
| RoBERTa-mini | mini | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
| RoBERTa-small | small | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
| RoBERTa-medium | medium | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
| RoBERTa-base | base | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
- 2019 | ALBERT: A Lite BERT For Self-Supervised Learning Of Language Representations | Zhenzhong Lan, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Albert_tiny | tiny | Google Drive | Google Drive | brightmart | github | 通用 |
| Albert_base_zh | base | Google Drive | Google Drive | brightmart | github | 通用 |
| Albert_large_zh | large | Google Drive | Google Drive | brightmart | github | 通用 |
| Albert_xlarge_zh | xlarge | Google Drive | Google Drive | brightmart | github | 通用 |
| Albert_base | base | Google Drive | Google Research | github | 通用 | |
| Albert_large | large | Google Drive | Google Research | github | 通用 | |
| Albert_xlarge | xlarge | Google Drive | Google Research | github | 通用 | |
| Albert_xxlarge | xxlarge | Google Drive | Google Research | github | 通用 |
- 2019 | NEZHA: Neural Contextualized Representation for Chinese Language Understanding | Junqiu Wei, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| NEZHA-base | base | lonePatient | HUAWEI | github | 通用 | |
| NEZHA-base-wwm | base | lonePatient | HUAWEI | github | 通用 | |
| NEZHA-large | large | lonePatient | HUAWEI | github | 通用 | |
| NEZHA-large-wwm | large | lonePatient | HUAWEI | github | 通用 | |
WoNEZHA(word-base) |
base | 百度网盘-qgkq | ZhuiyiTechnology | github | 通用 |
- 2020 | Revisiting Pre-Trained Models for Chinese Natural Language Processing | Yiming Cui, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| MacBERT-base | base | Yiming Cui | github | 通用 | ||
| MacBERT-large | large | Yiming Cui | github | 通用 |
- 2020 | 提速不掉点:基于词颗粒度的中文WoBERT | 苏剑林. | spaces |
Blog post
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| WoBERT | base | 百度网盘-kim2 | ZhuiyiTechnology | github | 通用 | |
| WoBERT-plus | base | 百度网盘-aedw | ZhuiyiTechnology | github | 通用 |
- 2019 | XLNet: Generalized Autoregressive Pretraining for Language Understanding | Zhilin Yang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| XLNet-base | base | Google Drive | Yiming Cui | github | 通用 | |
| XLNet-mid | middle | Google Drive | Yiming Cui | github | 通用 | |
| XLNet_zh_Large | large | 百度网盘 | brightmart | github | 通用 |
- 2020 | ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators | Kevin Clark, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| ELECTRA-180g-large | large | Yiming Cui | github | 通用 | ||
| ELECTRA-180g-small-ex | small | Yiming Cui | github | 通用 | ||
| ELECTRA-180g-base | base | Yiming Cui | github | 通用 | ||
| ELECTRA-180g-small | small | Yiming Cui | github | 通用 | ||
| legal-ELECTRA-large | large | Yiming Cui | github | 司法领域 | ||
| legal-ELECTRA-base | base | Yiming Cui | github | 司法领域 | ||
| legal-ELECTRA-small | small | Yiming Cui | github | 司法领域 | ||
| ELECTRA-tiny | tiny | CLUE | github | 通用 |
- 2019 | ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations | Shizhe Diao, et al. | arXiv |
PDF - 2021 | ZEN 2.0: Continue Training and Adaption for N-gram Enhanced Text Encoders | Yan Song, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| ZEN-Base | base | Sinovation Ventures AI Institute | github | 通用 | ||
| Erlangshen-ZEN2 | large | [🤗HF] | IDEA-CCNL | github | 通用 |
-
2019 | ERNIE: Enhanced Representation through Knowledge Integration | Yu Sun, et al. | arXiv |
PDF -
2020 | SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis | Hao Tian, et al. | arXiv |
PDF -
2020 | ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding | Dongling Xiao, et al. | arXiv |
PDF
| 模型 | 版本 | PaddlePaddle | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| ernie-1.0-base | base | link | PaddlePaddle | github | 通用 | |
| ernie_1.0_skep_large | large | link | Baidu | github | 情感分析 | |
| ernie-gram | base | link | Baidu | github | 通用 |
备注:
PaddlePaddle转TensorFlow可参考: tensorflow_ernie
PaddlePaddle转PyTorch可参考: ERNIE-Pytorch
-
2021 | ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation | Yu Sun, et al. | arXiv |
PDF -
2021 | ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation | Shuohuan Wang, et al. | arXiv |
PDF
| 模型 | 版本 | PaddlePaddle | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| ernie-3.0-base | 12-layer, 768-hidden, 12-heads | link | [🤗HF] | PaddlePaddle | github | 通用 |
| ernie-3.0-medium | 6-layer, 768-hidden, 12-heads | link | [🤗HF] | PaddlePaddle | github | 通用 |
| ernie-3.0-mini | 6-layer, 384-hidden, 12-heads | link | [🤗HF] | PaddlePaddle | github | 通用 |
| ernie-3.0-micro | 4-layer, 384-hidden, 12-heads | link | [🤗HF] | PaddlePaddle | github | 通用 |
| ernie-3.0-nano | 4-layer, 312-hidden, 12-heads | link | [🤗HF] | PaddlePaddle | github | 通用 |
PaddlePaddle转PyTorch可参考: ERNIE-Pytorch
-
2021 | RoFormer: Enhanced Transformer with Rotary Position Embedding | Jianlin Su, et al. | arXiv |
PDF -
2021 | Transformer升级之路:2、博采众长的旋转式位置编码 | 苏剑林. | spaces |
Blog post
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| roformer | base(L12) | 百度网盘-xy9x | ZhuiyiTechnology | github | 通用 | |
| roformer | small(L6) | 百度网盘-gy97 | ZhuiyiTechnology | github | 通用 | |
| roformer-char | base(L12) | 百度网盘-bt94 | ZhuiyiTechnology | github | 通用 | |
| roformerV2 | small(L6) | 百度网盘-ttn4追一 | ZhuiyiTechnology | github | 通用 | |
| roformerV2 | base(L12) | 百度网盘-pfoh追一 | ZhuiyiTechnology | github | 通用 | |
| roformerV2 | large(L24) | 百度网盘-npfv追一 | ZhuiyiTechnology | github | 通用 |
- 2019 | StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding | Wei Wang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| StructBERT | large(L24) | 阿里云 | Alibaba | github | 通用 |
- 2021 | Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models | Yuxuan Lai, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| LatticeBERT | tiny(L4) | 阿里云 | Alibaba | github | 通用 | |
| LatticeBERT | small(L6) | 阿里云 | Alibaba | github | 通用 | |
| LatticeBERT | base(L12) | 阿里云 | Alibaba | github | 通用 |
- 2021 | Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese | Zhuosheng Zhang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Mengzi-BERT | base(L12) | [🤗HF] | Langboat | github | 通用 | |
| Mengzi-BERT-fin | base(L12) | [🤗HF] | Langboat | github | 金融财经 |
- 2022 | Bloom: BigScience Large Open-science Open-access Multilingual Language Model | huggingface bigscience | - |
BLOG
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| bloom-6b4-zh | 6B(L30) | [🤗HF] | Langboat | github | 通用 |
注:作者另有bloom-389m-zh到bloom-2b5-zh等多个中文模型
- 2021 | TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning | Yixuan Su, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| TaCL | base(L12) | [🤗HF] | yxuansu | github | 通用 |
- 2021 | MC-BERT: Conceptualized Representation Learning for Chinese Biomedical Text Mining | alibaba-research | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| MC-BERT | base(L12) | link | alibaba-research | github | 生物医疗 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| Erlangshen | large(L24) | bert | [🤗HF] | IDEA-CCNL | github | 中文通用 |
- 2022 | PERT: Pre-Training BERT with Permuted Language Model | Yiming Cui, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| PERT-base | base(12L) | 百度网盘-rcsw | [🤗HF] | Yiming Cui | github | 通用 |
| PERT-large | large(24L) | 百度网盘-e9hs | [🤗HF] | Yiming Cui | github | 通用 |
- 2020 | MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices | Zhiqing Sun, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Chinese-MobileBERT-base-f2 | base | 百度网盘-56bj | Yiming Cui | github | 通用 | |
| Chinese-MobileBERT-base-f4 | base | 百度网盘-v2v7 | Yiming Cui | github | 通用 | |
| Chinese-MobileBERT-large-f2 | large | 百度网盘-6m5a | Yiming Cui | github | 通用 | |
| Chinese-MobileBERT-large-f4 | large | 百度网盘-3h9b | Yiming Cui | github | 通用 |
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| chinese_GAU-alpha-char_L-24_H-768 | base | 下载 | ZhuiyiTechnology | github | 通用 |
- 2020 | DeBERTa: Decoding-enhanced BERT with Disentangled Attention | Pengcheng He, et al. | arXiv |
PDF|
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| DeBERTa-v2-Large | large | [🤗HF] | IDEA-CCNL | github | 通用 | |
| DeBERTa-v2-xLarge | xlarge | [🤗HF] | IDEA-CCNL | github | 通用 | |
| DeBERTa-v2 | base | [🤗HF] | IDEA-CCNL | github | 通用 |
- 2021 | GlyphCRM: Bidirectional Encoder Representation for Chinese Character with its Glyph | Yuxin li, et al. | arXiv |
PDF|
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| GlyphCRM-base | base | [🤗HF] | HITsz-TMG | github | 通用 |
- 2022 | Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training | Zhang, Taolin, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| pai-ckbert-base-zh | base | [🤗HF] | Alibaba | github | 通用 | |
| pai-ckbert-large-zh | large | [🤗HF] | Alibaba | github | 通用 | |
| pai-ckbert-huge-zh | huge | [🤗HF] | Alibaba | github | 通用 |
- 2022 | LERT: A Linguistically-motivated Pre-trained Language Model | Yiming Cui et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Chinese-LERT-small | 15m | 百度网盘-4vuy | [🤗HF] | Yiming Cui | github | 通用 |
| Chinese-LERT-base | 400m | 百度网盘-9jgi | [🤗HF] | Yiming Cui | github | 通用 |
| Chinese-LERT-large | 1.2G | 百度网盘-s82t | [🤗HF] | Yiming Cui | github | 通用 |
- 2022 | RoCBert: Robust Chinese Bert with Multimodal Contrastive Pretraining | Hui Su et al. | ACL |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| rocbert | base | [🤗HF] | Weiwe Shi | github | 通用 |
| 模型 | 版本 | PyTorch | 作者 | 源地址 | 备注 |
|---|---|---|---|---|---|
| m3e-base | base | m3e-base | Moka-AI |
uniem
|
文本嵌入模型 |
| M3e-small | Small | m3e-small | Moka-AI |
uniem
|
文本嵌入模型 |
- 2023 | LEALLA: Learning Lightweight Language-agnostic Sentence Embeddings with Knowledge Distillation | Zhuoyuan Mao et al. | EACL |
PDF
| 模型 | 版本 | PyTorch | 作者 | 源地址 | 备注 |
|---|---|---|---|---|---|
| LEALLA-base | base | LEALLA-base | Google Research | / | 文本嵌入模型 |
| LEALLA-large | large | LEALLA-large | Google Research | / | 文本嵌入模型 |
-
2019 | Improving Language Understandingby Generative Pre-Training | Alec Radford, et al. | arXiv |
PDF -
2019 | Language Models are Unsupervised Multitask Learners | Alec Radford, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| GPT2 | 30亿语料 | Caspar ZHANG | gpt2-ml | 通用 | ||
| GPT2 | 15亿语料 | Caspar ZHANG | gpt2-ml | 通用 | ||
| CDial-GPTLCCC-base | base | [🤗HF] | thu-coai | CDial-GPT | 中文对话 | |
| CDial-GPT2LCCC-base | base | [🤗HF] | thu-coai | CDial-GPT | 中文对话 | |
| CDial-GPTLCCC-large | large | [🤗HF] | thu-coai | CDial-GPT | 中文对话 | |
| GPT2-dialogue | base | yangjianxin1 | GPT2-chitchat | 闲聊对话 | ||
| GPT2-mmi | base | yangjianxin1 | GPT2-chitchat | 闲聊对话 | ||
| GPT2-散文模型 | base | Zeyao Du | GPT2-Chinese | 散文 | ||
| GPT2-诗词模型 | base | Zeyao Du | GPT2-Chinese | 诗词 | ||
| GPT2-对联模型 | base | Zeyao Du | GPT2-Chinese | 对联 | ||
| roformer-gpt | base(L12) | 百度网盘-2nnn | ZhuiyiTechnology | github | 通用 |
-
2019 | Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context | Zihang Dai, et al. | arXiv |
PDF -
2020 | Language Models are Few-Shot Learners | Tom B. Brown, et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Chinese-Transformer-XL | 29亿参数(GPT-3) | 项目首页 | 模型下载 | THUDM | github | 通用 |
-
2019 | NEZHA: Neural Contextualized Representation for Chinese Language Understanding | Junqiu Wei, et al. | arXiv |
PDF -
2019 | Improving Language Understandingby Generative Pre-Training | Alec Radford, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| NEZHA-Gen | base | HUAWEI | github | 通用 | ||
| NEZHA-Gen | base | HUAWEI | github | 诗歌 |
- 2020 | CPM: A Large-scale Generative Chinese Pre-trained Language Model | Zhengyan Zhang, et al. | arXiv |
PDF
| 模型 | 版本 | 资源 | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| CPM | 26亿参数 | 项目首页 | 模型下载 | Tsinghua AI | github | 通用 |
备注:
PyTorch转TensorFlow可参考: CPM-LM-TF2
PyTorch转PaddlePaddle可参考: CPM-Generate-Paddle
- 2019 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Colin Raffel, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| T5 | small | [🤗HF] | [🤗HF] | DBIIR @ RUC | UER | 通用 |
-
2019 | Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer | Colin Raffel, et al. | arXiv |
PDF -
2019 | PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization | Jingqing Zhang, et al. | arXiv |
PDF -
2021 | T5 PEGASUS:开源一个中文生成式预训练模型 | 苏剑林. | spaces |
Blog post
| 模型 | 版本 | Keras | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| T5 PEGASUS | base | 百度网盘-3sfn | ZhuiyiTechnology | github | 通用 | |
| T5 PEGASUS | small | 百度网盘-qguk | ZhuiyiTechnology | github | 通用 |
Keras转PyTorch可参考: t5-pegasus-pytorch
- 2021 | Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese | Zhuosheng Zhang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Mengzi-T5 | base(L12) | [🤗HF] | Langboat | github | 通用 |
- 2021 | PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation | Wei Zeng, et al. | arXiv |
PDF
| 模型 | 版本 | 资源 | 下载地址 | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| 盘古α-2.6B | 2.6G | 项目首页 | 模型下载 | PCL-Platform.Intelligence | github | 通用 |
| 盘古α-13B | 12G | 项目首页 | 模型下载 | PCL-Platform.Intelligence | github | 通用 |
| 盘古α-2.6B pytorch版本 | 2.6G | 项目首页 | 模型下载 | PCL-Platform.Intelligence | github | 通用 |
| 盘古α-13B pytorch版本 | 12G | 项目首页 | 模型下载 | PCL-Platform.Intelligence | github | 通用 |
- 2021 | EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training | Hao Zhou, et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| EVA | 28亿参数 | 项目首页 | 模型下载 | thu-coai | github | 中文开放域对话 | 需要登陆才能下载 |
| EVA2.0-xLarge | xlarge | 项目首页 | [🤗HF] | thu-coai | github | 中文开放域对话 | |
| EVA2.0-large | large | 项目首页 | [🤗HF] | thu-coai | github | 中文开放域对话 | |
| EVA2.0-base | base | 项目首页 | [🤗HF] | thu-coai | github | 中文开放域对话 |
- 2019 | BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension | Mike Lewis, et al. | arxiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| BART-base | base | [🤗HF] | fastNLP | github | 中文通用 | |
| BART-large | large | [🤗HF] | fastNLP | github | 中文通用 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| Wenzhong | large(L24) | GPT2 | [🤗HF] | IDEA-CCNL | github | 中文通用 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| Yuyuan | large(L24) | GPT2 | [🤗HF] | IDEA-CCNL | github | 医学领域 |
- 2021 | An Attention Free Transformer | Shuangfei Zhai, et al. | arxiv |
PDF - 2022 | The RWKV Language Model . | github
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| RWKV | base(L12) | github | PENG Bo | github | 小说 | ||
| RWKV | 7B | [🤗HF] | PENG Bo | github | 小说 | ||
| RWKV | 14B | [🤗HF] | PENG Bo | github | 小说 |
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| PromptCLUE | base(L12) | [🤗HF] | ClueAI | github | 通用 | |
| PromptCLUE-v1-5 | base(L12) | [🤗HF] | ClueAI | github | 通用 | |
| PromptCLUE-large | large | API在线调用 | ClueAI | github | 通用 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| ChatYuan | large | T5 | [🤗HF] | ClueAI | github | 功能型对话 | |
| ChatYuan-large-v2 | large | T5 | [🤗HF] | ClueAI | github | 功能型对话 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| SkyText | large | GPT3 | [🤗HF] | SkyWorkAIGC | github | 通用 |
- 2020 | Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training | Qi, Weizhen, et al. | arxiv |
PDF - 2021 | ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation | Qi, Weizhen, et al. | arxiv |
PDF
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| ProphetNet-Zh | link | microsoft | github | 通用 | |||
| ProphetNet-Dialog-Zh | link | microsoft | github | 对话 |
- 2019 | Unified Language Model Pre-training for Natural Language Understanding and Generation | Li Dong, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Unilm | base | 百度网盘-tblr | 百度网盘-etwf | YunwenTechnology | github | 通用 |
- 2020 | 鱼与熊掌兼得:融合检索和生成的SimBERT模型 | 苏剑林. | spaces |
Blog post
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| SimBERT Tiny | tiny | 百度网盘-1tp7 | ZhuiyiTechnology | github | 通用 | |
| SimBERT Small | small | 百度网盘-nu67 | ZhuiyiTechnology | github | 通用 | |
| SimBERT Base | base | 百度网盘-6xhq | ZhuiyiTechnology | github | 通用 |
- 2021 | SimBERTv2来了!融合检索和生成的RoFormer-Sim模型 | 苏剑林. | spaces |
Blog post
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| roformer-sim | base(L12) | 百度网盘-2cgz | ZhuiyiTechnology | github | 通用 | |
| roformer-sim | small(L6) | 百度网盘-h68q | ZhuiyiTechnology | github | 通用 | |
| roformer-sim-v2 | base(L12) | 百度网盘-w15n | ZhuiyiTechnology | github | 通用 |
| 模型 | 版本 | 类型 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|---|
| Zhouwenwang | base(L12) | roformer | [🤗HF] | IDEA-CCNL | github | 中文通用 | |
| Zhouwenwang | large(L24) | roformer | [🤗HF] | IDEA-CCNL | github | 中文通用 |
- 2021 | CPM-2: Large-scale Cost-effective Pre-trained Language Models | Zhengyan Zhang, et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| CPM-2 | 110亿参数 | 项目首页 | 模型下载 | BAAI-WuDao | github | 通用 | 需要申请才能下载 |
| CPM-2 | 100亿参数 | 项目首页 | 模型下载 | BAAI-WuDao | github | 中英 | 需要申请才能下载 |
| CPM-2 | 1980亿参数 | 项目首页 | 模型下载 | BAAI-WuDao | github | 中英 | 需要申请才能下载 |
- 2021 | CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation | Yunfan Shao, et al. | arxiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| CPT-base | base(L12) | [🤗HF] | fastNLP | github | 通用 | |
| CPT-large | large(L24) | [🤗HF] | fastNLP | github | 通用 |
- 2022 | GLM: General Language Model Pretraining with Autoregressive Blank Infilling | Zhengxiao Du, et al. | arXiv |
PDF - 2022 | GLM-130B: An Open Bilingual Pre-trained Model | Aohan Zeng, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| GLM | large | [🤗HF] | THUDM | github | 通用 | |
| GLM | xxlarge | [🤗HF] | THUDM | github | 通用 | |
| GLM-130B | 130B | 申请地址1申请地址2 | THUDM | github | 通用 |
- 2019 | StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding | Wei Wang, et al. | arXiv |
PDF - 2020 | PALM: Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation | Bin Bi, et al. | ACL|
PDF
| 模型 | 版本 | 模型下载 | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|
| PLUG | 27B | AliceMind-需要申请 | Alibaba | github | 通用 |
- 2022 | 待定 | , et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| OPD | 6.3B | 项目首页 | 模型下载 | thu-coai | github | 中文开放域对话 | 需要申请才能下载 |
- 2021 | WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training | Yuqi Huo, et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| BriVL(WenLan) | 10亿参数 | 项目首页 | 模型下载 | BAAI-WuDao | github | 中文通用图文 | 需要登陆才能下载 |
- 2021 | CogView: Mastering Text-to-Image Generation via Transformers | Ming Ding, et al. | arXiv |
PDF
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| CogView | 40亿参数 | 项目首页 | 模型下载 | THUDM | github | 中文多模态生成模型 | 需要登陆才能下载 |
| 模型 | 版本 | 介绍 | 模型下载 | 作者 | 源地址 | 应用领域 | 备注 |
|---|---|---|---|---|---|---|---|
| 紫东太初- light_vision_text | 项目首页 | 模型下载 | 中科院自动化所 | github | 中文图像-文本领域 | 紫东太初多模态大模型中的图像-文本预训练模型 | |
| 紫东太初-text[GPT] | 32亿参数 | 项目首页 | 百度网盘-nos5 | 中科院自动化所 | github | 中文通用 | 紫东太初多模态大模型中的文本预训练模型 |
| 紫东太初-vision | 项目首页 | 模型下载 | 中科院自动化所 | github | 视觉领域 | 紫东太初多模态大模型中的视觉预训练模型 | |
| 紫东太初-speech | 项目首页 | 模型下载 | 中科院自动化所 | github | 语音领域 | 紫东太初多模态大模型中的语音检测与识别多任务模型 |
- 2021 | Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese | Zhuosheng Zhang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Mengzi-oscar | base(L12) | [🤗HF] | Langboat | github | 中文多模态-图文 |
- 2022 | Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework | Chunyu Xie, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 首页 | 应用领域 |
|---|---|---|---|---|---|---|---|
| R2D2ViT-L | large | yuxie11 | github | zero | 中文多模态-图文 | ||
| PRD2ViT-L | large | yuxie11 | github | zero | 中文多模态-图文 |
- 2021 | Learning Transferable Visual Models From Natural Language Supervision | Alec Radford, et al. | arXiv |
PDF - 2022 | Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese | An Yang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| CN-CLIPRN50 | 77M | aliyuncs | OFA-Sys | github | 中文多模态-图文 | |
| CN-CLIPViT-B/16 | 188M | aliyuncs | OFA-Sys | github | 中文多模态-图文 | |
| CN-CLIPViT-L/14 | 406M | aliyuncs | OFA-Sys | github | 中文多模态-图文 | |
| CN-CLIPViT-L/14@336px | 407M | aliyuncs | OFA-Sys | github | 中文多模态-图文 | |
| CN-CLIPViT-H/14 | 958M | aliyuncs | OFA-Sys | github | 中文多模态-图文 |
- 2021 | Learning Transferable Visual Models From Natural Language Supervision | Alec Radford, et al. | arXiv |
PDF - 2022 | Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence | Junjie Wang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Taiyi-CLIP-Roberta-large-326M-Chinese | base | [🤗HF] | IDEA-CCNL | github | 中文多模态-图文 |
- 2022 | AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities | Chen, Zhongzhi, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| AltCLIP | 3.22G | [🤗HF] | FlagAI | github | 中文多模态-图文 |
- 2022 | AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities | Chen, Zhongzhi, et al. | arXiv |
PDF - 2022 | High-Resolution Image Synthesis With Latent Diffusion Models | Rombach, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| AltDiffusion | 8.0G | [🤗HF] | FlagAI | github | 中文多模态-图文 |
- 2022 | Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence | Junjie Wang, et al. | arXiv |
PDF - 2022 | High-Resolution Image Synthesis With Latent Diffusion Models | Rombach, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| Taiyi-Stable-Diffusion | 1B | [🤗HF] | IDEA-CCNL | github | 中文多模态-图文 |
- 2022 | Wukong: A 100 Million Large-scale Chinese Cross-modal Pre-training Benchmark | Jiaxi Gu, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| CLIP | url | HUAWEI | github | 中文多模态-图文 | ||
| FILIP | url | HUAWEI | github | 中文多模态-图文 | ||
| wukong | url | HUAWEI | github | 中文多模态-图文 |
- 2022 | OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework | Peng Wang, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| OFA | link | OFA-Sys | github | 中文多模态-图文 | ||
| OFA-Chinese | [🤗HF] | Yang JianXin | github | 中文多模态-图文 |
| 模型 | 版本 | 视觉架构 | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| QA-CLIPRN50 | 77M | ResNet50 | [🤗HF] | 腾讯 |
QA-CLIP
|
中文多模态-图文 |
| QA-CLIPViT-B/16 | 188M | ViT-B/16 | [🤗HF] | 腾讯 |
QA-CLIP
|
中文多模态-图文 |
| QA-CLIPViT-L/14 | 406M | ViT-L/14 | [🤗HF] | 腾讯 |
QA-CLIP
|
中文多模态-图文 |
- 2021 | Improving Text-to-SQL with Schema Dependency Learning | Binyuan Hui, et al. | arXiv |
PDF
| 模型 | 版本 | TensorFlow | PyTorch | 作者 | 源地址 | 应用领域 |
|---|---|---|---|---|---|---|
| sdcup | base | 阿里云 | Alibaba | github | 中文表格 | |
| sdcup | large | 阿里云 | Alibaba | github | 中文表格 |
- 2025.03.22 增加[Skywork-R1V,FIN-R1]
- 2025.03.09 增加[QwQ-32B, Aya Vision,CogView4]
- 2025.02.26 增加[Moonlight、Wan2.1、Step-Audio-Chat]
- 2025.02.15 增加[Ovis2]
- 2025.01.19 增加[MiniMax-01, miniCPM-O, OuteTTS]
- 2025.01.12 增加Sky-T1,search-o1
- 2025.01.02 增加Huatuo-o1
- 2024.12.25 增加[QVQ-72B]
- 2024.12.16 增加[Megrez-3B-Omni, DeepSeek-VL2]
- 2024.11.29 增加QwQ-32B-Preview,Marco-o1 ,Skywork-01-Open,HK-01aw
- 2024.11.15 增加Qwen-2.5-coder, OpenCoder
- 2024.11.05 增加Hunyuan-Large
- 2024.10.26 增加GLM-4-Voice,Pangea,Aya-Expanse
- 2024.10.22 增加Granite 3.0,一套全新的轻量级、多语种支持的语言模型,专为推理、编程和工具使用设计,可在计算资源受限的环境中运行,适合企业使用和定制
- 2024.09.19 增加Qwen2.5
- 2024.09.08 增加DeepSeekV2.5, MiniCPM3, Yi-Coder
- 2024.08.30 增加C4AI Command R+ 08-2024,Qwen2-VL
- 2024.07.26 增加JIUTIAN-Chat,Tele-FLM
- 2024.07.24 增加Meta-llama3.1
- 2024.07.05 增加CodeGeeX4
- 2024.07.04 增加internlm2.5
- 2024.06.19 增加MAP-NEO-Chat,MAP-NEO is a fully open-sourced Large Language Model that includes the pretraining data, a data processing pipeline (Matrix), pretraining scripts, and alignment code.
- 2024.06.18 增加DeepSeek-Coder-V2、Nemotron-4
- 2024.06.14 增加Index-Chat
- 2024.06.08 增加Qwen2,ChatTTS
- 2024.06.03 增加GLM-4、Skywork-MoE
- 2024.05.30 增加Yuan2.0-M32: Mixture of Experts with Attention Router
- 2024.05.20 增加[CogVLM2,360VL,HunyuanDiT,星辰-Chat]
- 2024.05.13 增加[Yi-1.5]
- 2024.05.07 增加[XVERSE-V,DeepSeek-V2,XVERSE-MoE]
- 2024.04.27 增加Qwen1.5-110B, Llama3-zh
- 2024.04.14 增加MiniCPM-V2、WaveCoder、codegemma、Sailor、Nanbeige2-Chat、MiniCPM-MoE、Zhinao-Chat
- 2024.04.12 增加XVERSE-MoE
- 2024.04.08 增加SoftTiger、HammerLLM
- 2024.04.06 增加Qwen1.5-32B
- 2024.04.04 增加Mengzi3
- 2024.03.29 增加Qwen-Audio、Qwen-MoE
- 2024.03.13 增加Command-R
- 2024.03.01 增加Breeze-Instruct, starcoder2
- 2024.02.18 增加aya-101、chemLLM
- 2024.02.06 增加Qwen1.5
- 2024.02.02 增加MiniCPM, TuringMM-Chat
- 2024.02.01 增加LongAlign-Chat,Chinese-Mixtral-Chat
- 2024.01.31 增加iFlytekSpark-Chat,rwkv-5-world
- 2024.01.23 增加Yi-VL-6/34B
- 2024.01.22 增加orion-4B
- 2024.01.19 增加internlm2-chat,Chinese-Mixtral
- 2024.01.10 增加Telechat,Code Millenials
- 2024.01.09 增加kagentlms,具有Agents的规划、反思、工具使用等能力的系列大模型
- 2024.01.05 增加WizardCoder-33B-V1.1
- 2023.12.27 增加YaYi-30B-Chat
- 2023.12.05 增加SUS-Chat-34B、Aquila2-Chat-70B、Alaya-Chat-7B
- 2023.12.01 增加Qwen-Base-1.8/72B,Qwen-Chat-1.8/72B,Qwen-Audio
- 2023.11.30 增加Yuan-2.0、DeepSeek-Base,DeepSeek-Chat
- 2023.11.20 增加Alaya-Chat-7B、OrionStar-Yi-Chat-34B
- 2023.11.11 增加XVERSE-65B、Nanbeige-Chat-16B、OpenChat 3.5
- 2023.11.03 增加SPHINX、Tongyi-Finance、Phind、DeepSeek-Coder
- 2023.11.02 增加AndesGPT-7B、SeaLLM、BlueLM
- 2023.10.31 增加Zephyr-7B、Mistral-7b
- 2023.10.25 增加zhiyin、zhilu
- 2023.10.20 增加cross、taiyi、fuyu、Ziya-visual、CodeShell、CogVLM
- 2023.10.17 增加Ziya2-13B-Base、Ziya2-13B-Chat
- 2023.10.12 增加AquilaChat2-7/13B、AquilaChat2-16K、Vulture-180B
- 2023.10.04 增加DISC-LawLLM、WiNGPT、ziya-coding、Vulture、AgriGPT
- 2023.09.25 增加Colossal-LLaMA-2-7B,相较于原始LLaMA-2,在成功提升中文能力的基础上,进一步提升其英文能力,性能可与开源社区同规模预训练SOTA模型媲美。
- 2023.09.20 增加InternLM-20B、OpenBA,InternLM-20B已发布,包括基础版和对话版。OpenBA是一个从头开始预训练的开源15B双语非对称端到端模型。
- 2023.09.08 增加FLM-101B、falcon-180B、Openbuddy-70B、TigerBot-70B
- 2023.09.06 增加Baichuan2,Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
- 2023.09.01 增加DISC-MedLLM、YuLan-Chat-2、Chinese-Alpaca-2-16K,Vally
- 2023.08.29 增加CodeLLAma、Atom,IDEFICS
- 2023.08.25 增加sqlcoder,一个 SOTA 大型语言模型, SQLCoder 将自然语言问题转换为 SQL 查询。在开发者的开源评估框架 SQLEval 中,SQLCoder 的性能明显优于所有主要的开源模型,并且优于 OpenAI 的 GPT-3.5。
- 2023.08.23 增加Qwen-VL,Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。
- 2023.08.21 增加智海-录问,智海-录问(wisdomInterrogatory)是由浙江大学、阿里巴巴达摩院以及华院计算三家单位共同设计研发的法律大模型。
- 2023.08.15 增加WizardMath,
- 2023.08.09 增加TigerBot-13B,在Llama-2的基础上以虎博积累的技术和数据继续训练,不但保持了Llama-2出色的英文能力,更是在中文能力上填补了Llama-2的不足,各项主流中文任务中超过Llama-2的49%,在开源同类模型中具有竞争力。
- 2023.08.07 增加XVERSE-13B,XVERSE-13B,它支持40多种语言、8192上下文长度。在多项中英文测评中,性能超过了同尺寸(130亿参数)的LLama2、Baichuan等。
- 2023.08.03 增加通义千问,通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模的模型。
- 2023.07.31 增加LLasM、Chinese-LLaVA多模态大模型
- 2023.07.31 增加Chinese-Llama-2.原版Llama-2的基础上扩充并优化了中文词表,使用了120G大规模中文数据进行增量预训练,相关模型支持4K上下文并可通过NTK方法最高扩展至18K+
- 2023.07.29 增加BatGPT,Mozi,StarGLM.
- 2023.07.27 增加WizardLM-v1.2.
- 2023.07.25 增加相关Awesome列表
- 2023.07.24 增加Llama2-chinese-chat、Jiang-chat等对话语言模型。
- 2023.07.19 增加LLaMA2,Meta 发布了大家期待已久的免费可商用版本 Llama 2。
- 2023.07.16 增加PolyLM,PolyLM是一个通晓多语言语言的大规模语言模型,该模型可以应用于对话问答、文本生成、机器翻译和情感分析等领域,能够自动生成高质量的多语言文本。
- 2023.07.11 增加Baichuan-13B,baichuan-13B是由百川智能开发的一个开源可商用的大规模预训练语言模型。
- 2023.07.10 增加WizardLM-13B-V1.1
- 2023.07.09 增加VisualCLA多模态大模型
- 2023.07.04 增加书生·浦语,书生·浦语大模型,包含面向实用场景的70亿参数基础模型与对话模型.
- 2023.07.04 增加yuren,vicuna,CuteGPT,ailawyer
- 2023.06.30 增加VisCPM,VisCPM 是一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型),在中文多模态开源模型中达到最佳水平。
- 2023.06.28 增加PULSE,PULSE-中文医疗大语言模型。
- 2023.06.26 增加CoLLaMA,CoLLaMA是基于代码的多语言大模型。
- 2023.06.25 增加ChatGLM2-6B,ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本。
- 2023.06.24 增加TechGPT,TechGPT是“东北大学知识图谱研究组”发布的垂直领域大语言模型。
- 2023.06.20 增加Yayi、BayLing,百聆(BayLing)是一个强化了语言对齐的指令跟随大规模语言模型;Yayi大模型 在百万级人工构造的高质量领域数据上进行指令微调得到,训练数据覆盖媒体宣传、舆情分析、公共安全、金融风控、城市治理等五大领域。
- 2023.06.19 增加panda,Panda是海外中文开源大语言模型。
- 2023.06.18 增加ZhiXi,ZhiXi基于Llama的针对知识抽取的大模型。
- 2023.06.15 增加Baichuan-7B,baichuan-7B是由百川智能开发的一个开源可商用的大规模预训练语言模型。
- 2023.06.14 增加Chinese-Falcon,Chinese-Falcon 模型在 Falcon 基础上扩充中文词表,在中英文数据上增量预训练。 模型以 Apache License 2.0 协议开源,支持商业用途。。
- 2023.06.13 增加OpenLLaMA-Chinese,OpenLLaMA-Chinese是免费的中文大型语言模型,基于OpenLLaMA,可用于非商业和商业目的。
- 2023.06.09 增加QA-CLIP,M3E,Aquila,QA-CLIP是中文CLIP模型,M3E是文本嵌入模型,Aquila是语言大模型。
- 2023.06.08 增加YuLan,YuLan是由中国人名大学开源的双语言任务大模型,开源13B和65B大小。
- 2023.06.08 增加Chinese-Alpaca-33B,Chinese-LLaMA-33B,中文LLaMA/Alpaca-33B。
- 2023.06.07 增加Tigerbot,TigerBot是一款国产自研的多语言任务大模型,开源7B和180B大小。
- 2023.06.06 增加Video-LLaMA,BiLLa,Video-LLaMA是一个用于视频理解的指令调整的视觉语言模型,BiLLa是开源的推理能力增强的中英双语LLaMA模型。
- 2023.05.26 增加XuanYuan,XrayGLM,XuanYuan是国内首个开源的千亿级中文对话大模型,XrayGLM是中文医学领域多模态大语言模型。
- 2023.05.21 增加ziya,BLOOMChat,Ziya-LLaMA-13B-v1拥有130亿参数,从LLaMA-13B开始重新构建中文词表,进行千亿token量级的已知的最大规模继续预训练,使模型具备原生中文能力.
- 2023.05.18 增加VisualGLM-6B,VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型。
- 2023.05.16 增加BiLLa,开源中英文双语大模型。
- 2023.05.12 增加Bactrian-X,开源多语言大模型。
- 2023.05.08 增加OpenBuddy,一款强大的开源多语言聊天机器人模型。
- 2023.04.26 更新LLaMA-zh、YuYan,增加LLama-zh、Yuyan、扁鹊等LLM和chatLLm模型
- 2023.04.25 增加BBT,基于Transformer和Decoder-Only的架构开发了BigBang Transformer「乾元」大规模预训练语言模型。
- 2023.04.21 增加MOSS,更新复旦大学开源的MOSS模型以及对应的数据集。
- 2023.04.20 增加Phoenix,基于BLOOMZ-mt模型微调得到的大语言模型。
- 2023.04.19 增加ChatPLUG,该模型基于PLUG,使用亿级互联网社交数据、百科数据预训练和百万级高质量对话数据进行instruction微调得到。
- 2023.04.18 增加COIG数据集,用不同方法构建中文指令数据集的项目,收集了大约20万个中文指令样本。
- 2023.04.13 更新ChatLLM,增加HuaTuo,Med_ChatGLM两个医学模型。
- 2023.04.09 更新中文指令数据集ChatLLM,增加个性角色对话数据集、chinese-alpaca-13b模型。
- 2023.04.03 更新中文指令数据集ChatLLM,增加BELLE-13b模型,math-0.25,multiturn-0.8数据集。
- 2023.04.02 更新ChatLLM列表,增加由香港科技大学开源的7B/13B/33B/65B中文大型语言模型
- 2023.03.30 增加Chinese-Vicuna模型,Traditional-Chinese-alpaca数据集
- 2023.03.29 增加OFA,中文多模态统一预训练模型,OFA是阿里巴巴发布的多模态统一预训练模型.
- 2023.03.29 更新中文指令数据集,增加InstructionWild数据集。
- 2023.03.23 增加中文指令数据集,并初始化三个已公开数据集。
- 2023.03.20 增加BELLE,开源中文对话大模型-70亿参数,基于Stanford Alpaca,对中文做了优化,模型调优仅使用由ChatGPT生产的数据.
- 2023.03.14 增加ChatLLM列表,主要收集具备问答跟对话等功能的大型语言模型,并增加ChatGLM模型。
- 2023.03.11 增加ProphetNet,提出了一种新的自监督学习目标——同时预测多个未来字符,在序列到序列的多个自然语言生成任务都取得了优异性能。
- 2023.03.10 增加RoCBert,利用对抗学习生成更多噪声数据,用来进行中文BERT模型的训练,得到鲁棒性更强的中文BERT模型。
- 2023.03.03 更新LLM,新增多语言模型
Flan-ul2和Flan-t5-xxl - 2023.02.21 增加LLM,大规模语言模型列表,只罗列出参数量大于10B以上模型,其余量级模型,可参考对应的项目地址。
- 2023.01.14 增加SkyText,SkyText是由奇点智源发布的中文GPT3预训练大模型,可以进行聊天、问答、中英互译等不同的任务.
- 2023.01.14 增加ChatYuan,ChatYuan模型可以用于问答、结合上下文做对话、做各种生成任务,包括创意性写作,也能回答一些像法律、新冠等领域问题。
- 2022.12.10 增加PromptCLUE,全中文任务零样本学习模型,基于1000亿token中文语料上预训练,并且在数百种任务上进行Prompt任务式训练。
- 2022.12.01 增加wukong,基于一个名为「悟空」的大型中文跨模态数据集,其中包含来自网络的 1 亿个图文对,预训练的多模态模型。
- 2022.11.30 增加AltDiffusion,使用 AltCLIP 作为text encoder,基于 Stable Diffusion 训练了中英双语Diffusion模型(AltDiffusion)
- 2022.11.30 增加AltCLIP,一个简单高效的方法去训练更加优秀的双语CLIP模型,名为AltCLIP。AltCLIP基于 OpenAI CLIP 训练。
- 2022.11.30 增加Taiyi-Stable-Diffusion,首个开源的中英双语Stable Diffusion模型,基于0.2亿筛选过的中文图文对训练。
- 2022.11.9 增加OPD,OPD是一个中文开放域对话预训练模型,拥有63亿参数,在70GB高质量对话数据上进行训练而成.
大规模&高性能 - 2022.11.8 更新Chinese-CLIP,Chinese-CLIP是中文多模态图文表征模型,更新后Chinese-CLIP扩充到5个模型规模,同时增加了技术报告论文以及检索demo,同时在达摩院ModelScope平台同步集成。
- 2022.10.31 增加LERT,为了验证通过显式注入语言学知识预训练模型能否获得进一步性能提升,HFL提出了一种语言学信息增强的预训练模型LERT,融合了多种语言学知识。大量实验结果表明,在同等训练数据规模下,LERT能够带来显著性能提升。
- 2022.10.14 增加CKBERT,中文知识库增强BERT预训练语言模型。
- 2022.10.01 增加GlyphBERT, GlyphBERT是一个包含了汉字字形特征中文预训练模型。它通过将输入的字符渲染成图像并设计成多通道位置特征图的形式,并设计了一个两层 残差卷积神经网络模块来提取字符的图像特征进行训练。
- 2022.09.30 增加DeBERTa,一个中文版的DeBERTa-v2,我们用悟道语料库(180G版本)进行预训练,在预训练阶段中使用了封神框架。
- 2022.09.30 增加TaiYi-CLIP,首个开源的中文CLIP模型,1.23亿图文对上进行预训练的文本端RoBERTa-large。
- 2022.09.27 增加PLUG,PLUG集语言理解与生成能力于一身,支持文本生成、问答、语义理解等多类下游任务,PLUG开源将助力开发者在语言理解和语言生成上做出更多延拓。
- 2022.09.11 增加bloom-6b4,多语言预训练bloom系列生成模型7b1参数(https://huggingface.co/bigscience/bloom-7b1 )的中文vocab提取,bloom系列另有最大176B模型(https://huggingface.co/bigscience/bloom).
- 2022.09.11 增加GLM-130B,提出了开源的双语预训练生成模型 GLM(General Language Model)。
- 2022.09.11 增加PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation 2.6B和13B 生成模型pytorch版
- 2022.06.29 增加ERNIE 3.0,大规模知识增强预训练语言理解和生成.
- 2022.06.22 增加Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework,基于大规模中文跨模态基准数据集Zero,训练视觉语言预训练框架 R2D2,用于大规模跨模态学习。
- 2022.06.15 增加GLM: General Language Model Pretraining with Autoregressive Blank Infilling,提出了一种新的通用语言模型 GLM(General Language Model)。 使用自回归填空目标进行预训练,可以针对各种自然语言理解和生成任务进行微调。
- 2022.05.16 增加GAU-α,主要提出了一个融合了Attention层和FFN层的新设计GAU(Gated Attention Unit,门控注意力单元),它是新模型更快、更省、更好的关键,此外它使得整个模型只有一种层,也显得更为优雅。
- 2022.03.27 增加RoFormer-V2,RoFormer升级版,主要通过结构的简化来提升速度,并通过无监督预训练和有监督预训练的结合来提升效果,从而达到了速度与效果的“双赢”。
- 2022.03.02 增加MobileBERT,MobileBERT是BERT-large模型更“苗条”的版本,使用了瓶颈结构(bottleneck)并且对自注意力和前馈神经网络之间的平衡做了细致的设计。
- 2022.02.24 增加PERT: Pre-Training BERT with Permuted Language Model,一种基于乱序语言模型的预训练模型(PERT),在不引入掩码标记[MASK]的情况下自监督地学习文本语义信息。
- 2021.12.06 增加SDCUP: Improving Text-to-SQL with Schema Dependency Learning,达摩院深度语言模型体系 AliceMind 发布中文社区首个表格预训练模型 SDCUP。
- 2021.11.27 增加RWKV中文预训练生成模型,类似 GPT-2,模型参考地址:RWKV-LM
- 2021.11.27 增加IDEA研究院开源的封神榜系列语言模型,包含二郎神、周文王、闻仲、余元。
- 2021.11.25 增加MC-BERT: Conceptualized Representation Learning for Chinese Biomedical Text Mining, 生物医学领域的中文预训练模型.
- 2021.11.24 增加TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning, Token-aware对比学习预训练模型.
- 2021.10.18 增加Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese,基于语言学信息融入和训练加速等方法研发了 Mengzi 系列模型.
- 2021.10.14 增加中文版BART,训练比较可靠的中文版BART,为中文生成类任务如摘要等提供Baseline.
- 2021.10.14 增加CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation,CPT:兼顾理解和生成的中文预训练模型.
- 2021.10.13 增加紫东太初多模态大模型: 全球首个多模态图文音预训练模型,实现了视觉-文本-语音三模态统一表示,构建了三模态预训练大模型。
- 2021.09.19 增加CogView: Mastering Text-to-Image Generation via Transformers,世界最大的中文多模态生成模型,模型支持文生成图为基础的多领域下游任务.
- 2021.09.10 增加WenLan: Bridging Vision and Language by Large-Scale Multi-Modal Pre-Training,首个中文通用图文多模态大规模预训练模型。
- 2021.09.10 增加EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training,一个开放领域的中文对话预训练模型。
- 2021.08.19 增加Chinese-Transformer-XL:基于中文预训练语料WuDaoCorpus(290G)训练的GPT-3模型。
- 2021.08.16 增加CPM-2: Large-scale Cost-effective Pre-trained Language Models
- 2021.08.16 增加Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models
- 2021.07.19 增加roformer-sim-v2:利用标注数据增强版本
- 2021.07.15 增加BERT-CCPoem:古典诗歌语料训练的BERT
- 2021.07.06 增加ChineseBERT:Chinese Pretraining Enhanced by Glyph and Pinyin Information
- 2021.06.22 增加StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
- 2021.06.14 增加RoFormer:Enhanced Transformer with Rotary Position Embedding
- 2021.05.25 增加ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding
- 2021.04.28 增加PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
- 2021.03.16 增加T5-PEGASUS: 开源一个中文生成式预训练模型
- 2021.03.09 增加UER系列模型
- 2021.03.04 增加WoBERT: 基于词颗粒度的中文
- 2020.11.11 初始化BERT系列模型BERT

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-pretrained-chinese-nlp-models
Similar Open Source Tools
yudao-ui-admin-vue3
The yudao-ui-admin-vue3 repository is an open-source project focused on building a fast development platform for developers in China. It utilizes Vue3 and Element Plus to provide features such as configurable themes, internationalization, dynamic route permission generation, common component encapsulation, and rich examples. The project supports the latest front-end technologies like Vue3 and Vite4, and also includes tools like TypeScript, pinia, vueuse, vue-i18n, vue-router, unocss, iconify, and wangeditor. It offers a range of development tools and features for system functions, infrastructure, workflow management, payment systems, member centers, data reporting, e-commerce systems, WeChat public accounts, ERP systems, and CRM systems.
yudao-cloud
Yudao-cloud is an open-source project designed to provide a fast development platform for developers in China. It includes various system functions, infrastructure, member center, data reports, workflow, mall system, WeChat public account, CRM, ERP, etc. The project is based on Java backend with Spring Boot and Spring Cloud Alibaba microservices architecture. It supports multiple databases, message queues, authentication systems, dynamic menu loading, SaaS multi-tenant system, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and more. The project is well-documented and follows the Alibaba Java development guidelines, ensuring clean code and architecture.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.
yudao-boot-mini
yudao-boot-mini is an open-source project focused on developing a rapid development platform for developers in China. It includes features like system functions, infrastructure, member center, data reports, workflow, mall system, WeChat official account, CRM, ERP, etc. The project is based on Spring Boot with Java backend and Vue for frontend. It offers various functionalities such as user management, role management, menu management, department management, workflow management, payment system, code generation, API documentation, database documentation, file service, WebSocket integration, message queue, Java monitoring, and more. The project is licensed under the MIT License, allowing both individuals and enterprises to use it freely without restrictions.
ruoyi-vue-pro
The ruoyi-vue-pro repository is an open-source project that provides a comprehensive development platform with various functionalities such as system features, infrastructure, member center, data reports, workflow, payment system, mall system, ERP system, CRM system, and AI big model. It is built using Java backend with Spring Boot framework and Vue frontend with different versions like Vue3 with element-plus, Vue3 with vben(ant-design-vue), and Vue2 with element-ui. The project aims to offer a fast development platform for developers and enterprises, supporting features like dynamic menu loading, button-level access control, SaaS multi-tenancy, code generator, real-time communication, integration with third-party services like WeChat, Alipay, and cloud services, and more.
PaddleScience
PaddleScience is a scientific computing suite developed based on the deep learning framework PaddlePaddle. It utilizes the learning ability of deep neural networks and the automatic (higher-order) differentiation mechanism of PaddlePaddle to solve problems in physics, chemistry, meteorology, and other fields. It supports three solving methods: physics mechanism-driven, data-driven, and mathematical fusion, and provides basic APIs and detailed documentation for users to use and further develop.
sanic-web
Sanic-Web is a lightweight, end-to-end, and easily customizable large model application project built on technologies such as Dify, Ollama & Vllm, Sanic, and Text2SQL. It provides a one-stop solution for developing large model applications, supporting graphical data-driven Q&A using ECharts, handling table-based Q&A with CSV files, and integrating with third-party RAG systems for general knowledge Q&A. As a lightweight framework, Sanic-Web enables rapid iteration and extension to facilitate the quick implementation of large model projects.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.
Awesome-AGI
Awesome-AGI is a curated list of resources related to Artificial General Intelligence (AGI), including models, pipelines, applications, and concepts. It provides a comprehensive overview of the current state of AGI research and development, covering various aspects such as model training, fine-tuning, deployment, and applications in different domains. The repository also includes resources on prompt engineering, RLHF, LLM vocabulary expansion, long text generation, hallucination mitigation, controllability and safety, and text detection. It serves as a valuable resource for researchers, practitioners, and anyone interested in the field of AGI.
Chinese-LLaMA-Alpaca-3
Chinese-LLaMA-Alpaca-3 is a project based on Meta's latest release of the new generation open-source large model Llama-3. It is the third phase of the Chinese-LLaMA-Alpaca open-source large model series projects (Phase 1, Phase 2). This project open-sources the Chinese Llama-3 base model and the Chinese Llama-3-Instruct instruction fine-tuned large model. These models incrementally pre-train with a large amount of Chinese data on the basis of the original Llama-3 and further fine-tune using selected instruction data, enhancing Chinese basic semantics and instruction understanding capabilities. Compared to the second-generation related models, significant performance improvements have been achieved.
indie-hacker-tools-plus
Indie Hacker Tools Plus is a curated repository of essential tools and technology stacks for independent developers. The repository aims to help developers enhance efficiency, save costs, and mitigate risks by using popular and validated tools. It provides a collection of tools recognized by the industry to empower developers with the most refined technical support. Developers can contribute by submitting articles, software, or resources through issues or pull requests.

Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.
linktre-tools
The 'linktre-tools' repository is a collection of tools and resources for independent developers, AI products, cross-border e-commerce, and self-media office assistance. It aims to provide a curated list of tools and products in these areas. Users are encouraged to contribute by submitting pull requests and raising issues for continuous updates. The repository covers a wide range of topics including AI tools, independent development tools, popular AI products, tools for web development, online tools, media operations, and cross-border e-commerce resources.
Chinese-LLaMA-Alpaca
This project open sources the **Chinese LLaMA model and the Alpaca large model fine-tuned with instructions**, to further promote the open research of large models in the Chinese NLP community. These models **extend the Chinese vocabulary based on the original LLaMA** and use Chinese data for secondary pre-training, further enhancing the basic Chinese semantic understanding ability. At the same time, the Chinese Alpaca model further uses Chinese instruction data for fine-tuning, significantly improving the model's understanding and execution of instructions.